
- 1Spring Boot | Spring Boot “整合JPA“
- 2java面试100题(应届生必备)_java应届生面试题
- 3ubuntu/centos vim配置golang开发环境_ubuntu安装vim-go插件
- 4支持中文的Rasa NLU训练服务部署---Rasa_NLU_Chi_rasa训练中文模型
- 5为什么人工智能和Python要一起学?两者有何联系?_人工智能的底层是python吗
- 6CHATGLM3应用指南——本地部署_chatglm3-ggml-q4_0.bin 部署
- 7毕业设计:基于深度学习的电影推荐算法 -- 以豆瓣为例 大数据
- 8Elasticsearch:使用向量搜索来搜索图片及文字_elasticsearch 向量检索
- 9libsvm java 情感分类_自然语言处理系列篇——情感分类
- 10pytorch实战---IMDB情感分析_pytorch imdb
2023年的深度学习入门指南(7) - HuggingFace Transformers库_transformers_cache
赞
踩
2023年的深度学习入门指南(7) - HuggingFace Transformers库
这一节我们来学习下预训练模型的封装库,Hugging Face的Transformers库的使用。Hugging Face的库非常活跃,比如支持LLaDA大规型的类,是在本文开始写作的前一天发布的。
库新到这种程度,而且相应配套的库也在不停修改中,这个时候进入这个领域一定要做好要花时间完善还不成熟的功能,尤其是花较多时间debug问题的思想准备。
另外,还是再提醒大家,大模型算法不是普通编程。模型规模和思维链仍然非常重要。

Pipeline编程
Pipeline是transformers库中面向任务的编程方式。比如我们最常用的任务就是文本生成。
我们只需要指定"text-generation"任务,再选择一种模型,就可以了。比如下面这样,我们选择使用gpt2来进行文本生成:
text_generator = pipeline("text-generation", model="gpt2")
- 1
我们来个完整版,除去引用包和设置一个结束符,基本上就是两句话,一句生成pipeline,一句打印结果。
from transformers import pipeline
text_generator = pipeline("text-generation", model="gpt2", max_new_tokens=250)
text_generator.model.config.pad_token_id = text_generator.model.config.eos_token_id
text = text_generator("I have a dream ")[0]["generated_text"]
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这是其中一次我运行的结果:
I have a dream " The young man's lips parted under a wave of laughter. "My dream!" Bagel said that "My dream!" The young man jumped back the moment he got off the train. "Good, good!" On the other hand, the boy had gotten off. "My dream!" There he was again in that black and white moment that his soul couldn't shake. In this youth, the only thing that could stop him from reaching his dream was this. "Dad, we're here now!" Bagel didn't know how to react, at his level of maturity, he had to show up before the others to ask him something, if that wasn't his right, then his first duty had always been to save Gung-hye's life. But even so, he didn't understand why Bamboo was being so careful and so slow to respond to him. It turned out that she hadn't sent him one word to the authorities, she had simply told them not to respond. Of course they wouldn't listen to the question, it was even worse after realizing it, Bamboo had to understand when his next

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
GPT2是openai的第二代GPT模型。我们可以看到在你个人目录下的.cache\huggingface\hub\models–gpt2目录下面,会有500多M的数据,这就是gpt2模型的大小。
如果觉得gpt2的效果不够好,我们可以换一个更大的gpt-large模型:
text_generator = pipeline("text-generation", model="gpt2-large", max_new_tokens=250)
text_generator.model.config.pad_token_id = text_generator.model.config.eos_token_id
text = text_generator("I have a dream ")[0]["generated_text"]
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
.cache\huggingface\hub\models–gpt2-large这个大小就有3G多了。
还不过瘾的话可以使用gpt2-xl,这下子模型大小就有6个G了。
如果C盘空间有限,可以通过指定TRANSFORMERS_CACHE环境变量将其指向D盘或者其它盘。
除了文本生成之外,pipeline支持很多其它的基于文本、语音、图像等任务。
虽然不推荐,不指定模型的时候,系统其实也会给我们默认配一个模型。
比如我们写一个情感分析的pipeline:
from transformers import pipeline
pipe = pipeline("text-classification")
result = pipe("这个游戏不错")
print(result)
- 1
- 2
- 3
- 4
- 5
系统就默认给我们找了distilbert-base-uncased-finetuned-sst-2-english模型。

同样,我们也可以搞一个对话的pipeline。唯一的区别是我们需要用Conversation把输入信息包装一下,获取的结果也从Conversation对象中读取。
比如我们使用facebook的blenderbot模型:
from transformers import pipeline, Conversation
pipe = pipeline('conversational', model='facebook/blenderbot-1B-distill')
conversation_1 = Conversation("What's your favorite moive?") # 创建一个对话对象
pipe([conversation_1]) # 传入一个对话对象列表,得到模型的回复
print(conversation_1.generated_responses) # 打印模型的回复
conversation_1.add_user_input("Avatar") # 添加用户的输入
pipe([conversation_1]) # 再次传入对话对象列表,得到模型的回复
print(conversation_1.generated_responses) # 打印模型的回复
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
使用分词器和模型
除了使用pipeline之外,我们有更传统一点的用法,就是显示使用分词器和模型的方法。
语言字符串,尤其是像中文和日文这样不使用拉丁字母或者西里尔字母的语言,不方便直接被语言模型所使用,所以我们要先用分词器Tokenizer来编码字符串,推理完成后再用分词器来进行解码。
一般来说,我们不需要指定分词器的类型,通过AutoTokenizer就可以了:
tokenizer = AutoTokenizer.from_pretrained("gpt2")
- 1
我们来个例子来看一下:
import torch from transformers import GPT2LMHeadModel, AutoTokenizer # 加载预训练模型及对应的分词器 tokenizer = AutoTokenizer.from_pretrained("gpt2") model = GPT2LMHeadModel.from_pretrained("gpt2") # 使用分词器将文本转换为tokens input_tokens = tokenizer.encode("I have a dream ", return_tensors="pt") model.config.pad_token_id = model.config.eos_token_id # 使用模型生成文本 output = model.generate(input_tokens, max_length=250, num_return_sequences=1, no_repeat_ngram_size=2) # 将生成的tokens转换回文本 generated_text = tokenizer.decode(output[0], skip_special_tokens=True) print(generated_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
我们还可以更抽象一下,使用语言模型的通用抽象类AutoModelForCausalLM:
import torch from transformers import AutoModelForCausalLM, AutoTokenizer model = AutoModelForCausalLM.from_pretrained("gpt2") # 加载预训练模型及对应的分词器 tokenizer = AutoTokenizer.from_pretrained("gpt2", cache_dir='e:/xulun/models/') tokenizer.pad_token_id = tokenizer.eos_token_id model = AutoModelForCausalLM.from_pretrained("gpt2", cache_dir='e:/xulun/models/') # 使用分词器将文本转换为tokens input_tokens = tokenizer.encode("I have a dream ", return_tensors="pt") # 使用模型生成文本 output = model.generate(input_tokens, max_length=250, num_return_sequences=1, no_repeat_ngram_size=2) # 将生成的tokens转换回文本 generated_text = tokenizer.decode(output[0], skip_special_tokens=True) print(generated_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
有了上面的抽象层,我们使用其他大模型就可以照方抓药了。
不过,LlaMA的模型目前还没有完全能支持,比如LlamaTokenizerFast还处于测试阶段。将来随着更新,我再回来更新本文吧。
from transformers import LlamaTokenizerFast
tokenizer = LlamaTokenizerFast.from_pretrained("hf-internal-testing/llama-tokenizer")
print(tokenizer.encode("Hello this is a test"))
- 1
- 2
- 3
- 4
执行其它任务的大模型
有了上面的框架之后,我们只要知道有什么模型可以用,我们得来介绍一些预训练模型。
首先第一个肯定是我们已经多次熟悉过的GPT模型了,gpt2我们刚学习过,gpt3的API我们在第二篇中openai API部分介绍过。
第二个值得一提的是Google的T5模型。它的核心思想是基于迁移学习,能够将各种文本任务统一起来。我们可以看下表了解T5在各个子任务上取得的成果。
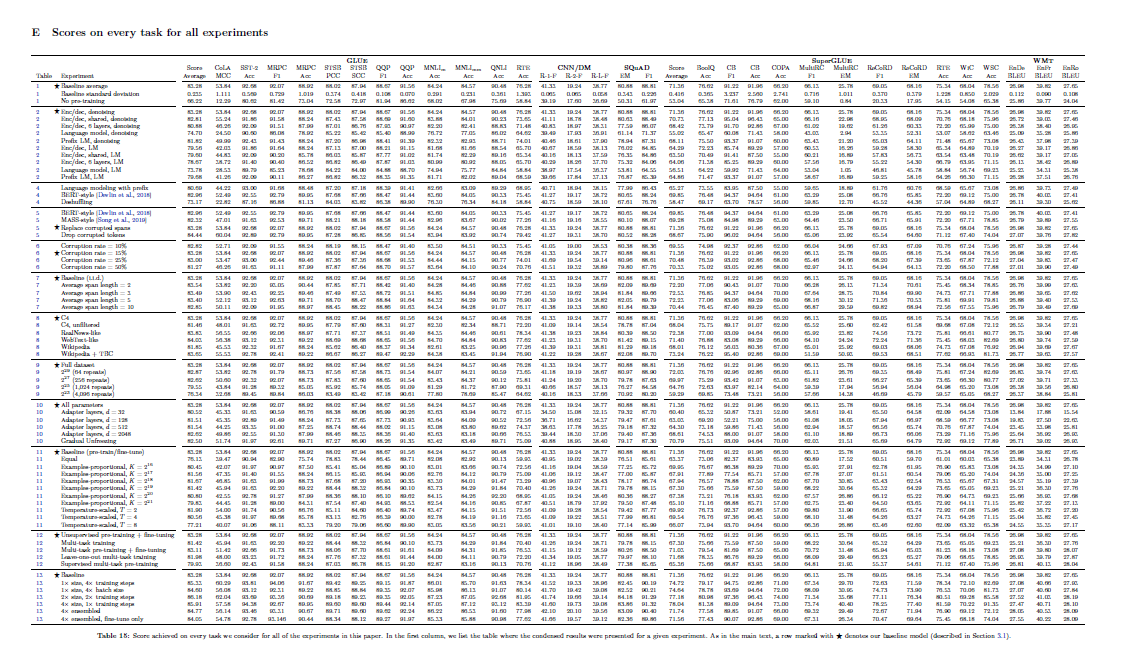
另外,T5的训练已经使用了1024和TPU v3的加速器。
我们使用large的T5 1.1模型来尝试去写个摘要:
from transformers import T5Tokenizer, T5ForConditionalGeneration tokenizer = T5Tokenizer.from_pretrained("google/t5-v1_1-large") model = T5ForConditionalGeneration.from_pretrained("google/t5-v1_1-base",max_length=250) str1 = """ Summarize: We have explored chain-of-thought prompting as a simple and broadly applicable method for enhancing reasoning in language models. Through experiments on arithmetic, symbolic, and commonsense reasoning, we find that chain-of-thought reasoning is an emergent property of model scale that allows sufficiently large language models to perform reasoning tasks that otherwise have flat scaling curves. Broadening the range of reasoning tasks that language models can perform will hopefully inspire further work on language-based approaches to reasoning. """ input_ids = tokenizer(str1, return_tensors="pt").input_ids outputs = model.generate(input_ids) print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
GPT来自openai,BERT来自Google. Facebook的团队尝试集合二者之所长,推出了BART模型。
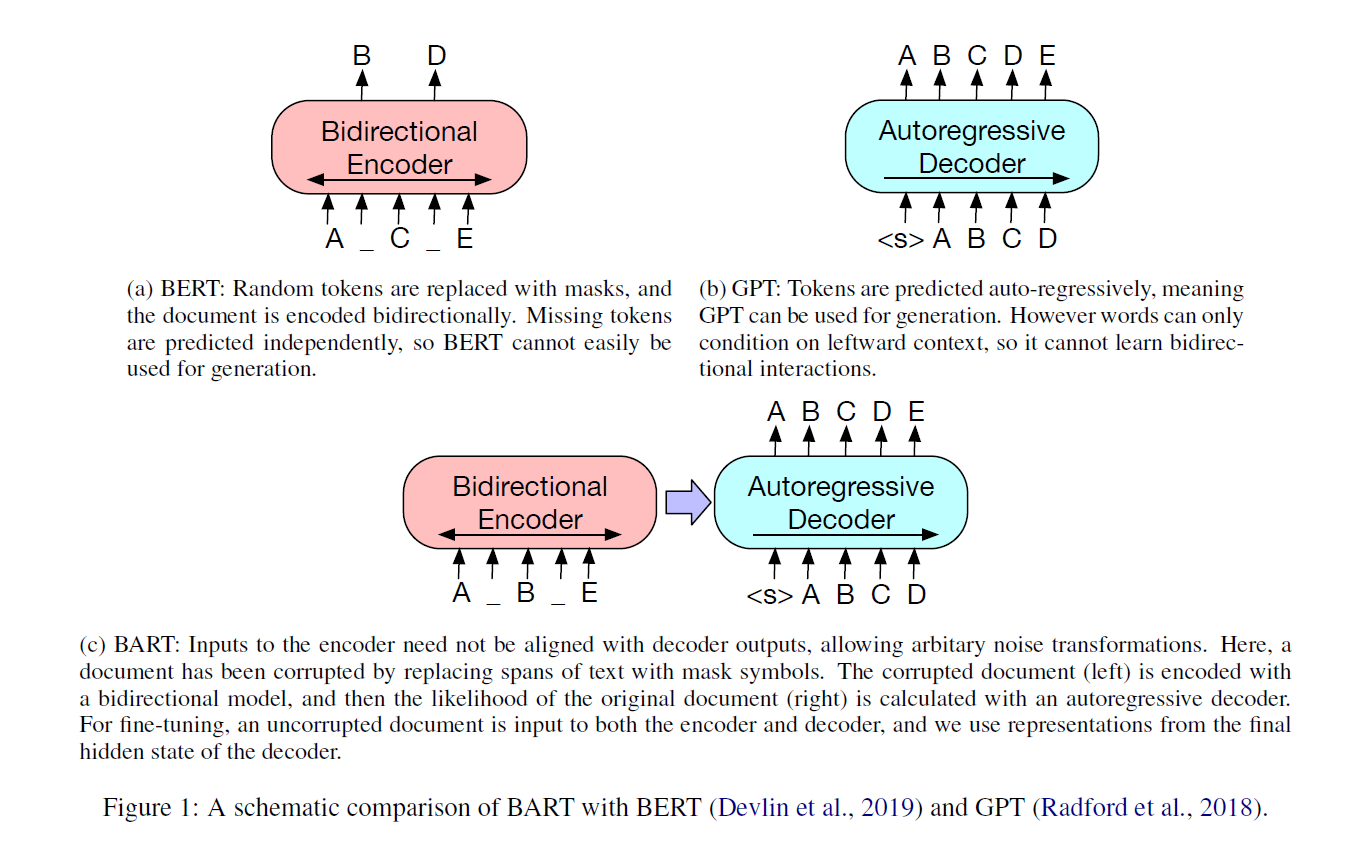
BART的预训练过程包括两个步骤:(1)使用任意的去噪函数对文本进行损坏,例如随机打乱句子顺序或用掩码符号替换文本片段;(2)学习一个模型来重建原始文本。BART使用了一个标准的基于Transformer的神经机器翻译架构,它可以看作是泛化了BERT(由于双向编码器)、GPT(由于左到右解码器)和其他更多最近的预训练方案。
下面我们来个用bart-large-cnn来写摘要的例子:
from transformers import AutoTokenizer, BartForConditionalGeneration model = BartForConditionalGeneration.from_pretrained("facebook/bart-large-cnn") tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-cnn") ARTICLE_TO_SUMMARIZE = ( """ We have explored chain-of-thought prompting as a simple and broadly applicable method for enhancing reasoning in language models. Through experiments on arithmetic, symbolic, and commonsense reasoning, we find that chain-of-thought reasoning is an emergent property of model scale that allows sufficiently large language models to perform reasoning tasks that otherwise have flat scaling curves. Broadening the range of reasoning tasks that language models can perform will hopefully inspire further work on language-based approaches to reasoning. """ ) inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors="pt") # Generate Summary summary_ids = model.generate( inputs["input_ids"], num_beams=2, min_length=0, max_length=100) print(tokenizer.batch_decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
生成的结果如下:
We find that chain-of-thought reasoning is an emergent property of model scale that allows large language models to perform reasoning tasks. Broadening the range of reasoning tasks that language models can perform will hopefully inspire further work.
- 1
小结
学习了基本框架编程之后,大家就可以基于各种模型进行尝试了。

