
- 1使用Python和Pygame创建一个简单的游戏_```pythonimport pygameimport randompygame.init()#
- 2【Hadoop】Hadoop车辆数据存储_基于hadoop的公共自行车数据分布式存储和计算
- 3编译遇到 Could not determine the dependencies of task ‘:xxxxx:compileDebugAidl‘.
- 418个基础命令教你轻松拿捏华为设备的各种状态!-HCIA HCIP_default directory is flash:/
- 5Kaggle自然语言处理入门之推特灾难文本分类_natural language processing with disaster tweets
- 6实时Flink大数据分析平台的数据流时间窗口操作
- 7Anchor-based和Anchor-free优缺点对比_anchor free和anchor base优缺点
- 8李宏毅机器学习(二)自注意力机制_自注意力 相关性
- 9配置VS Code和Jupyter的Python环境_vscode jupyter
- 10如何生成SSH key_生成ssh-key
利用stable diffusion制作ai动画_stable diffusion + controlnet 生成动画
赞
踩
第一步,截取视频中最有代表性的一帧拖入Tagger界面。用反推命令推出图片的大致提示词,然后卸载模型(避免占用过多显存),最后复制提示词粘贴到图生图界面。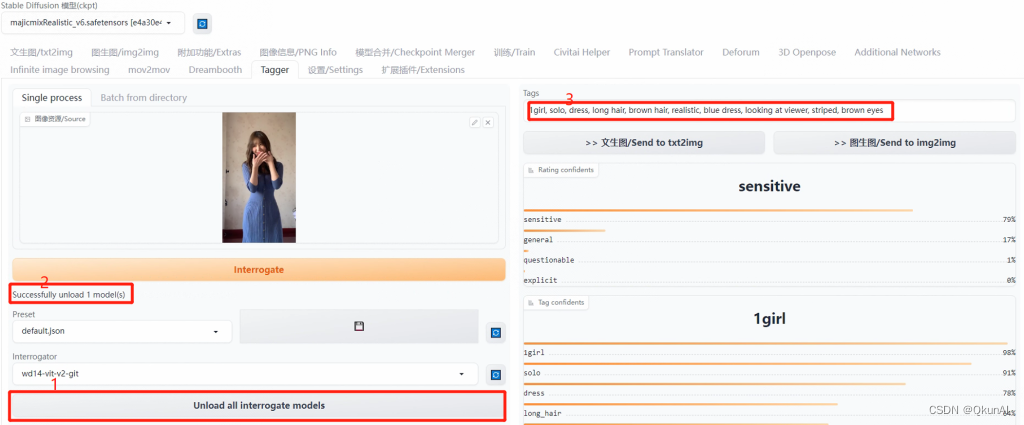
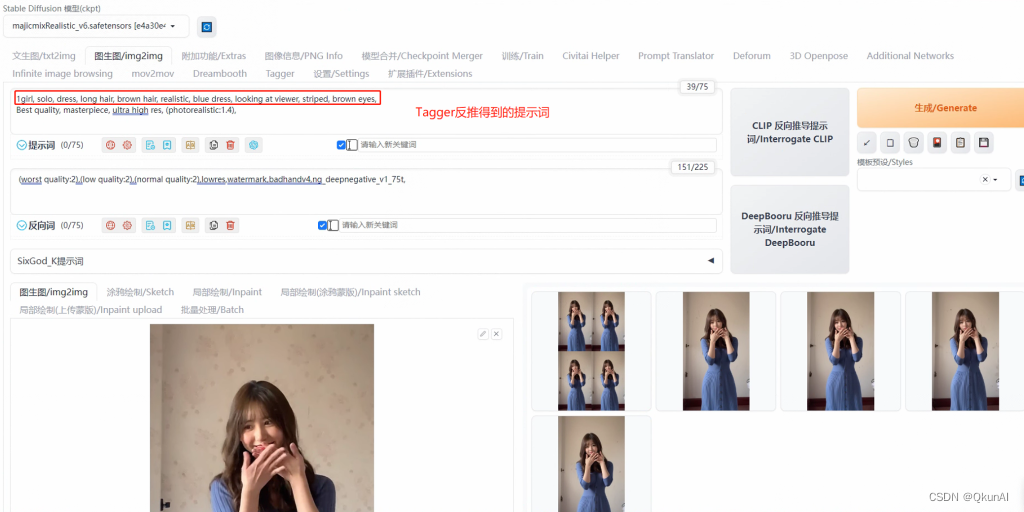
第二步,来到图生图界面。选择一个你喜欢的大模型,这里我还是以majicrealistic V6模型进行示范。由于这个提示词将在mov2mov界面对每一帧生效,所以正面提示词只需要书写一些质量词和人物的基本特征即可,也可以加入你喜欢的lora。接下来选择适合这个模型的采样器和采样步数(作者一般都会介绍),尺寸与原图保持一致,重绘幅度建议设置在0.5以下,以保持视频的相似度。
这里附上我的提示词方便大家复刻!
正面提示词:1girl, solo, dress, long hair, brown hair, solo, dress, long hair, brown hair, realistic, blue dress, looking at viewer, striped, brown eyesair, realistic, blue dress, looking at viewer, striped, brown eyes, (人物特征)
Best quality, masterpiece, ultra high res, (photorealistic:1.4) (质量词)
负面提示词:ng_deepnegative_v1_75t ,badhandv4
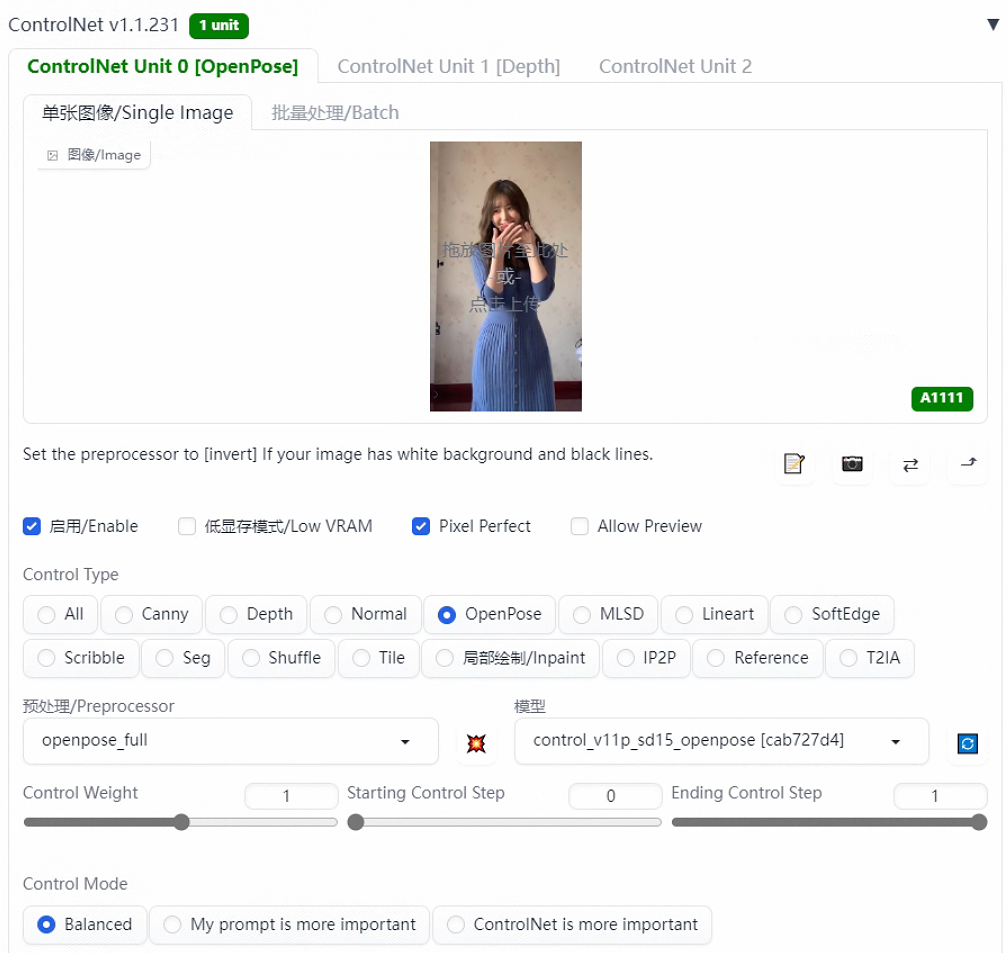
第三步,打开controlnet插件。预处理器选择openpose_full,模型默认来控制人物的姿势。勾选启用和完美像素(Pixel Perfect),8G及以下的显存建议勾选低显存模式,其他参数保持默认,最后点击生成即可。根据生成结果反复调试直到生成满意的结果。
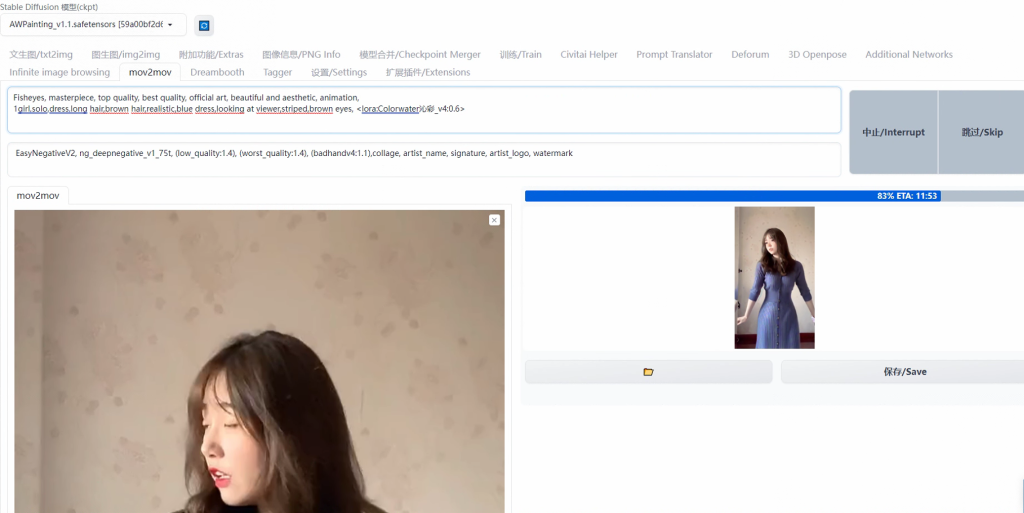
第四步,来到mov2mov界面,拖入需要处理的视频。
复制第三步图生图的参数,Noise multiplier(噪声乘数)可以设置在0.5左右。
Movie Frames代表帧率,这里需要与原视频保持一致
Max Frames代表最大帧率,默认-1不生效。如果视频帧率为30,你可以设置Max Frames为60,即先生成一个2秒的视频先测试一下大致效果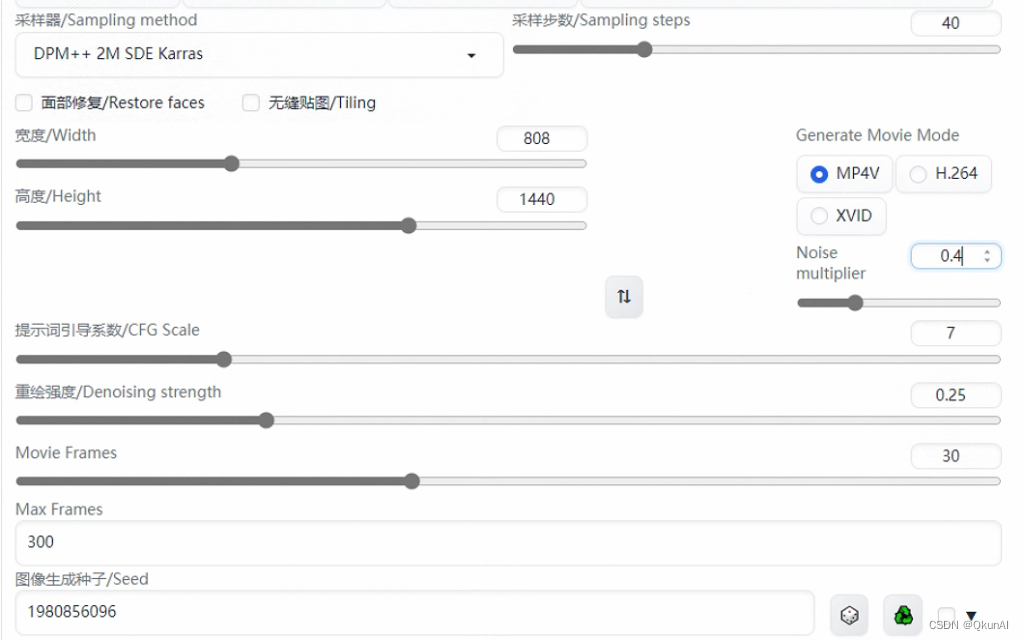
现存问题分析
1.ai生成的视频难以避免的存在闪烁的问题,并且对于人物的姿势和服饰难以完全控制
2.速度慢,绘制一个10秒30帧的视频花了将近半个小时(3090 24G显存),当你开启controlnet和添加了多个lora之后,生成时间还会成倍增加。
注:本文源自乾坤AI,作者:ai-worldai,更多内容请关注乾坤AI。
乾坤AI官网地址:https://qkunai.com

