
- 1Pytorch基础及实战(3)——深入浅出PyTorch数据读取机制_继承dataset类__len__
- 2人工智能-聚类算法、误差评估、算法优化、特征降维
- 3实不相瞒,字节跳动的大模型、推荐、特效算法……都是在这里跑出来的
- 4Pytorch中Dataset类的继承使用方法(创建自己的图片数据集)(自己记录加强印象的,大家别喷我)_怎样继承自torch中的dataset
- 5易感-感染-易感(SIS)模型的实现方式_sis模型
- 6机器学习实战教程(二):线性回归_线性回归实战 这是一个关于初创企业的小数据集,由51行和5列组成。我们的目标是根
- 7springcloud异常:org.springframework.web.client.HttpClientErrorException$BadRequest: 400 null_nested exception is org.springframework.web.client
- 8王咏刚《AI的产品化和工程化挑战》_人工智能工程化挑战
- 9在线SM2验签工具_sm2在线验签
- 10基于ChatGPT函数调用来实现C#本地函数逻辑链式调用助力大模型落地_chatgpt vb代码转c#
基于hadoop的协同过滤就业推荐系统推荐原理:以用户对岗位的评分和用户的收藏行为作为基础数据集_基于hadoop的就业推荐系统
赞
踩
基于hadoop的协同过滤就业推荐系统
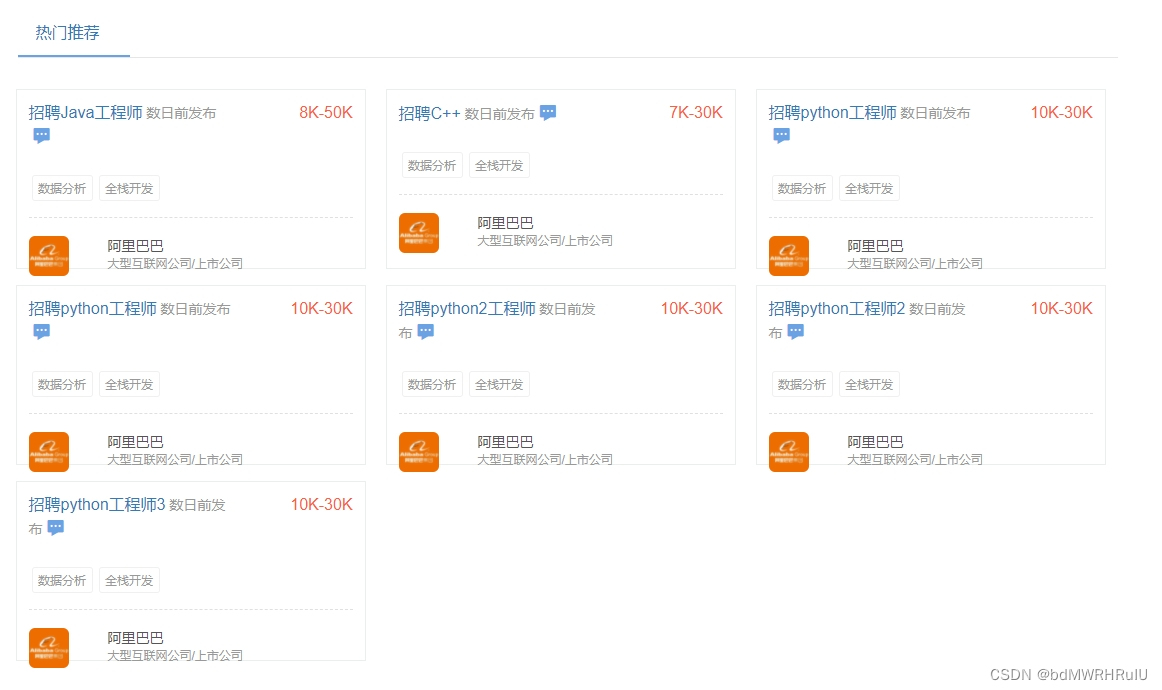
推荐原理:以用户对岗位的评分和用户的收藏行为作为基础数据集,应用hadoop通过mapreduce程序进行协同过滤计算,得出用户对岗位的预测评分,根据评分高低对岗位进行评分排序,进而进而推荐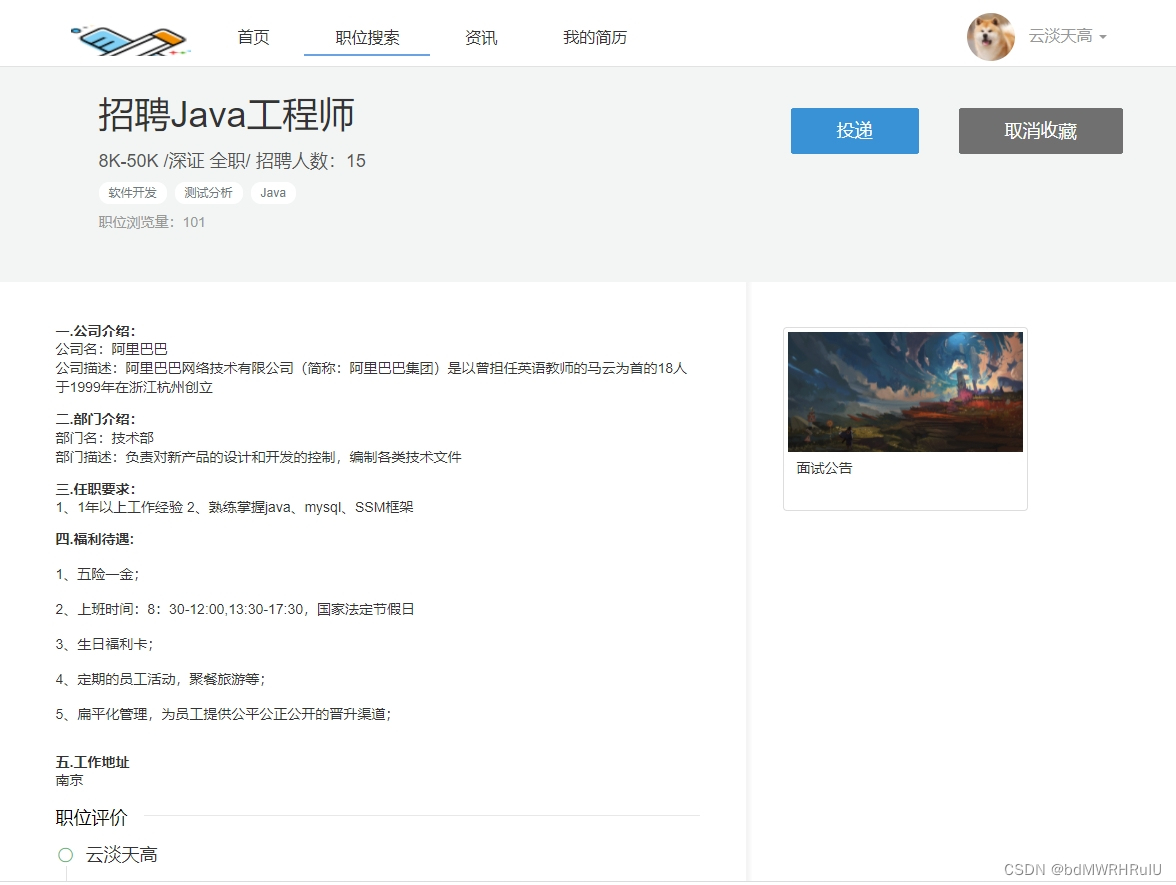

基于Hadoop的协同过滤就业推荐系统
随着互联网的发展,人们的信息获取渠道越来越多元化,越来越依赖于网上信息。而作为一个工作或者求职的人来说,如何获取到自己喜欢的工作,或者如何找到自己喜欢的人才,成为了一个很重要的话题。而基于数据的推荐系统应运而生,越来越多人选择利用推荐系统来寻求自己的合适职位或者合适人才。
其中,协同过滤算法是一种经典的推荐算法。协同过滤算法基于用户的历史行为数据,如用户的评分和收藏行为,将用户分组,或者将物品分组,以此来推荐相似的物品或者用户。但是,这种算法需要大量的数据支持,而且计算过程比较耗时。为了解决这个问题,我们可以使用Hadoop进行分布式计算。
基于Hadoop的协同过滤就业推荐系统,其推荐原理如下:以用户对岗位的评分和用户的收藏行为作为基础数据集,应用Hadoop通过MapReduce程序进行协同过滤计算,得出用户对岗位的预测评分。根据预测评分高低对岗位进行排序,进而推荐给用户。
在具体实现中,我们需要将用户对于岗位的评分和收藏行为数据进行处理,将其转化成Hadoop的输入格式。接着,我们需要利用MapReduce程序对数据进行分析。Map阶段,我们将数据分成小块,每一块都分别处理,并输出键值对。Reduce阶段,我们将相同键的值集合到一起,并对这些值进行计算。最后,我们得到用户对岗位的预测评分,根据评分高低对岗位进行排序,推荐给用户。
当然,要想实现一个高效、准确的基于Hadoop的协同过滤就业推荐系统,还需要考虑一些细节问题。比如,如何处理数据倾斜的问题?如何优化程序性能?如何保证推荐结果的准确性?
总的来说,基于Hadoop的协同过滤就业推荐系统,是一种很有前景的推荐系统。它可以实现分布式计算,可以处理大规模的数据,可以提高推荐的准确性和效率。在未来的工作和研究中,我们还可以结合更多的技术手段和算法,来不断完善和优化这种推荐系统,为用户提供更好的服务。
相关代码,程序地址:http://lanzouw.top/671683045254.html

