
- 1Modelsim do文件的自动化仿真及模板_modelsim 切换 到 目录 do 文件 仿真 vlib work vlib work
- 2Java还是要系统学习,阿里面试失败的经验总结,最终获字节offer_阿里一面答得不好
- 3AIGC 与游戏的深度融合:腾讯全链路解决方案
- 42023年 HCIP-Datacom(H12-831)最新题库_hcip-datacom题库
- 5天星数科以金融数字化转型为核心,提升服务实体经济质效
- 6在Linux系统下检测U盘是否已连接的方法_linux系统查看u盘识别到没有
- 7预测房价--基于python的线性回归模型_房价预测模型python
- 8数据集说明文档_nus_48e
- 9Centos离线手动安装gcc_gcc_rpm.tar.gz
- 10使用 Verilog HDL 在 FPGA 上进行图像处理_去图像坏点 verilog
视觉大模型--DAB-deter的深入理解
赞
踩
原理大家参考这篇文章,我主要是根据自己的理解和整个流程图以及代码进行对应,这样更有利于深入理解:
下图是解码器结构图,编码器没动和deter一样的
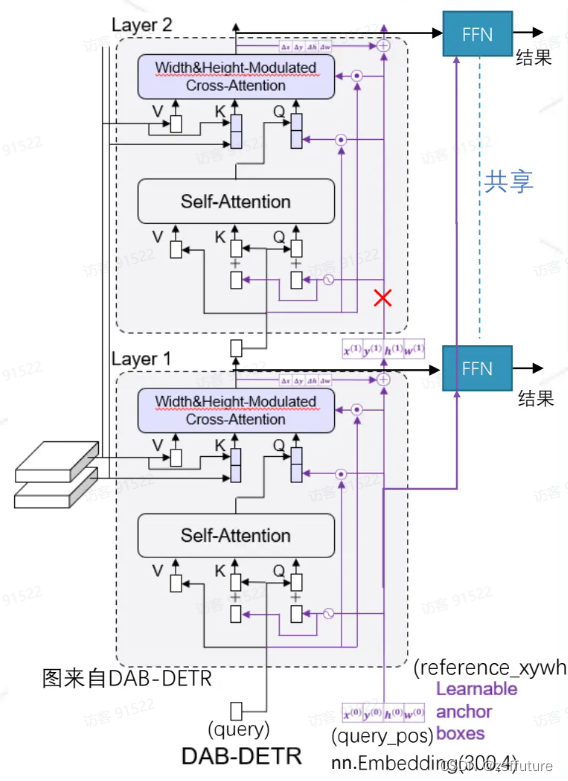
这张图片基本上说清了模型的结构和传递过程,红色×代表切断梯度反向传播,每层都会进行单独的反向传播,这里需要几点特别注意:
从下往上看
1. 解码器的自注意力层输入Q仍然有两部分构成query 和query_pose,正常的query的shape是[batch,300,256],query_pose的shape是[batch,300,4], 而且query初始化任然全为0向量,而query_pose是可学习的,因为作为输入都是向量,而query_pose是坐标,因此需要通过位置编码把坐标编码为向量即shape由[batch,300,4]->[batch,300,256],然后二者就可以相加作为Q了。

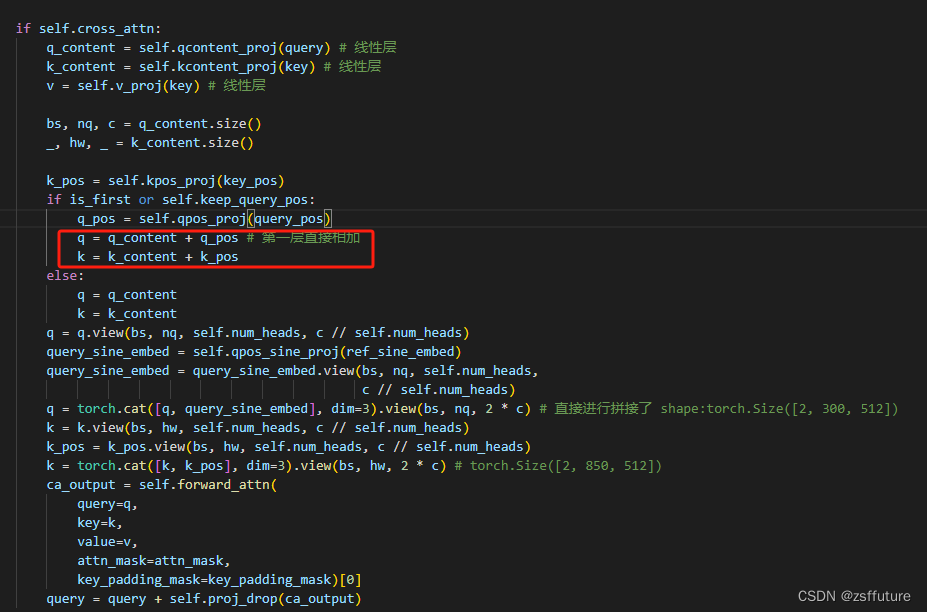
2. 解码器的交叉注意力层的Q也是由两部分组成即query和query_pose,自注意力层的输出作为内容query,shape为[batch,300,256],而位置query由两部分组成,输入的query(自注意力的输入)和可学习的query_pose进行相乘得到。shape仍然为[batch,300,256]


3. 使用宽高对解码器的注意力图进行调制,是通过对Q进行调制进行的,他是怎么做的呢?

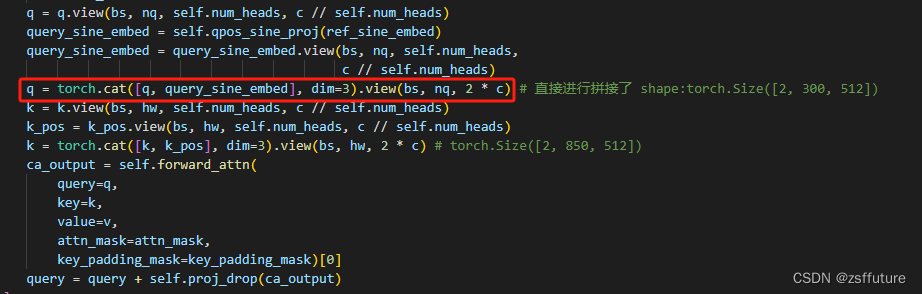
简单来说他是通过位置query即pose_query来达到调制的,使用位置query_pose(这是坐标)通过位置编码使得坐标转成位置向量记作pose_query_embeding,然后使用query(注意力层的输入)通过mlp回归出宽高这里起名叫self_query_pose,然后使用self_query_pose/query_pose,然后在乘上pose_query_embeding,得到的结果作为最终调制,然后直接进行拼接
4. 交叉注意力层输出的结果进行位置更新和切断位置梯度
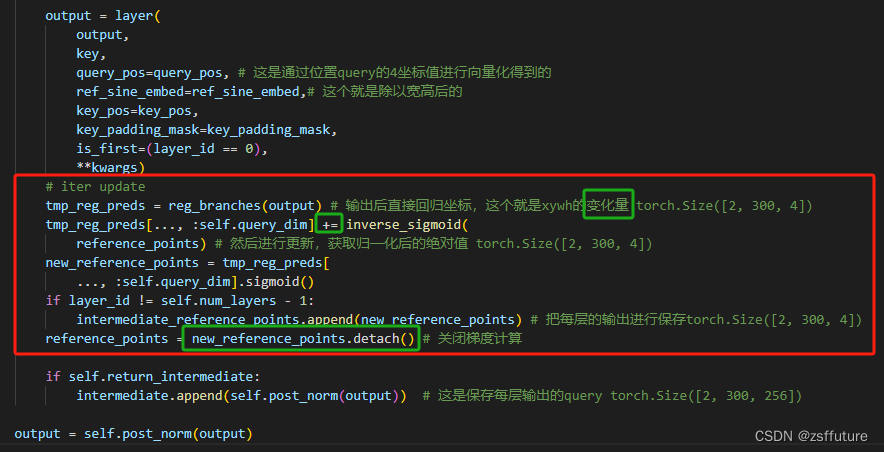
从代码可以看到输出后直接进行坐标回归计算变化量,然后对位置进行调整,同时关闭了梯度计算,这样每层都会单独的进行更新
下面这张图更清晰:
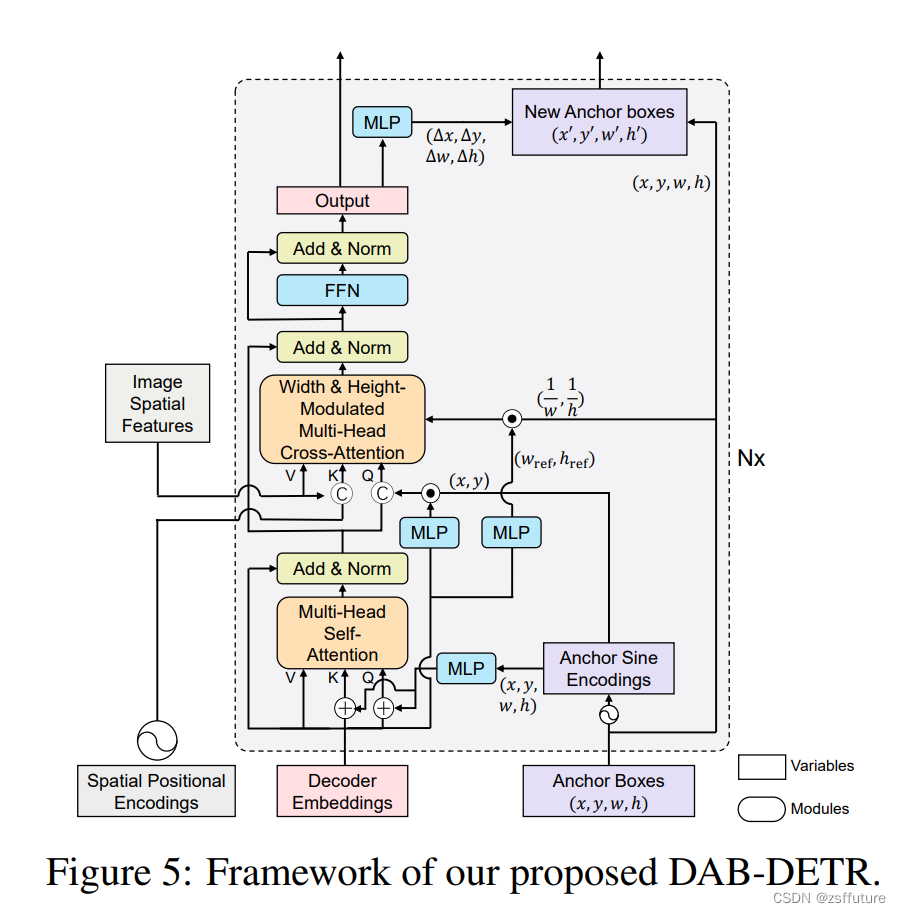
以上就是DAB的整体结构和思路,该模型给我的感觉在于,清晰的解释了pose_query的含义,同时对于位置的回归和融入进行了各种的转换,给我的感觉是,原来query可以这样用,而且使用wh对attention进行约束,他不是直接作用attention,而是通过输入的Q进行,而尺度的计算通过位置query和内容query对位置的回归进行规范化,然后作用embeding,最后和Q进行拼接形成最终的输入,这一套思路可以来上是神来之笔,很清晰,很明了,而且都是可学习的,这里后续就可以做很多操作了。最后跟新权重时,针对每层的输出回归的位置,进行梯度切断,这样每层只负责自己的跟新更有利于模型的针对当前层的学习,以上就是我的一些梳理,大家尽量跑跑代码

