
热门标签
热门文章
- 1linux上安装配置vsftpd和和指定目录、操作权限_vsftpd指定访问目录
- 2美团前端一面总结《8月21》_美团前端外包面试
- 3【leetcode 5】最长回文子串, Manachers算法
- 4从4k到42k,软件测试工程师的涨薪史,给我看哭了_软件测试多久长薪资
- 5C++ 你想要的C++面经都在这(附答案 | 持续更新)
- 6Hystrix应用:如何在Spring Boot中使用Hystrix?
- 712.FastAPI响应状态码_python fastapi 定义 返回结果 code
- 8天龙八部资源提取源代码_tlbb资源提取
- 9git的下载与安装指南
- 10uos桌面专业版下载多架构软件安装包_统信应用商店安装包下载位置
当前位置: article > 正文
【Mathematical Model】基于Python实现随机森林回归算法&特征重要性评估&线性拟合_python 随机森林回归评价
作者:我家小花儿 | 2024-04-14 19:32:55
赞
踩
python 随机森林回归评价
前段时间在做遥感的定量反演,所以研究了一下回归算法,由于之前发的几篇博文都是定义好基础方程进行拟合的,不太满足我的需求。所以研究了一下随机森林回归的算法,之前使用随机森林都是做分类,这次做了回归算法也算是补全了RF算法的空缺了。今天抽空给大家分享一下使用Python实现随机森林回归算法,同时将特征重要性和拟合结果进行可视化。
原创作者:RS迷途小书童
1. 需要的库
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import mean_squared_error, r2_score
2. 代码主函数
这里其实还是调用sklearn里面的随机森林回归算法的函数,所以整体没什么难度,最后将结果使用matplotlib库进行绘制。
- # -*- coding: utf-8 -*-
- """
- @Time : 2023/4/2 11:31
- @Auth : RS迷途小书童
- @File :Random Forest Regression.py
- @IDE :PyCharm
- @Purpose:随机森林回归算法+特征重要性评估
- @Web:博客地址:https://blog.csdn.net/m0_56729804
- """
- import joblib
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import mean_squared_error, r2_score
- plt.rcParams['axes.unicode_minus'] = False
- plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
-
-
- def RF_Regression(path_excel):
- print("-----------------------------------随机森林回归分析-----------------------------------")
- print("【数据准备】正在导入数据......")
- df = pd.read_excel(path_excel) # 读取数据
- num_columns = df.shape[1]
- x = df.iloc[:, 0:num_columns-1] # 读取前18列为自变量
- y = df.iloc[:, num_columns-1] # 读取第19列为因变量
- print("【数据准备】正在分割训练集和测试集......")
- x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3) # 以7:3划分训练样本和测试样本
- model = RandomForestRegressor(n_estimators=100, random_state=42) # 创建模型
- # {'max_depth': None, 'max_features': 'log2', 'min_samples_leaf': 4, 'min_samples_split': 10, 'n_estimators': 200}
- print("【模型分析】正在训练回归模型......")
- model.fit(x_train, y_train) # 以训练样本训练模型
- print("【模型分析】正在验证模型精度......")
- y_predict = model.predict(x_test) # 用验证集预测
- mse = mean_squared_error(y_test, y_predict)
- r2 = r2_score(y_test, y_predict)
- # 计算MSE和R-squared
- print('【评估参数】MSE:', mse) # 线性回归的损失函数
- print('【评估参数】R-squared:', r2) # 确定系数的取值范围为[0 1].越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
- print("【模型参数】特征重要性:")
- feature_importance = model.feature_importances_ # 特征的重要性分数
- for i, feature in enumerate(x.columns):
- print(" {}: {}\n".format(feature, feature_importance[i]), end='')
- print("【结果可视化】正在绘制特征重要性......")
- feature_names = x.columns.tolist() # 获取特征的名称
- feature_importance_sort = feature_importance.argsort() # 按照特征重要性从小到大排序的索引
- plt.subplots(figsize=(8, 6))
- plt.barh(range(len(feature_importance)), feature_importance[feature_importance_sort]) # 绘制一个水平条形图
- plt.yticks(range(len(feature_importance)), [feature_names[i] for i in feature_importance_sort], fontsize=8)
- # 设置了y轴的刻度标签。根据排序后的索引feature_ids获取对应的特征名称。font size=8设置字体大小
- plt.xlabel('Features Importance')
- plt.ylabel('Features Name')
- plt.title('Random Forest Regression Feature Importance Evaluation')
- plt.show()
- # plt.savefig('Random Forest Regression Feature Importance Evaluation', dpi=500)
- print("【结果可视化】正在精度曲线......")
- plt.subplots(figsize=(8, 6))
- plt.scatter(y_predict, y_test, alpha=0.6)
- w = np.linspace(min(y_predict), max(y_predict), 100)
- plt.plot(w, w)
- plt.xlabel('Predicted Value')
- plt.ylabel('Actual Value')
- plt.title('Random Forest Prediction')
- plt.show()
- # joblib.dump(model, 'model_RF.pkl')
3. 结果展示
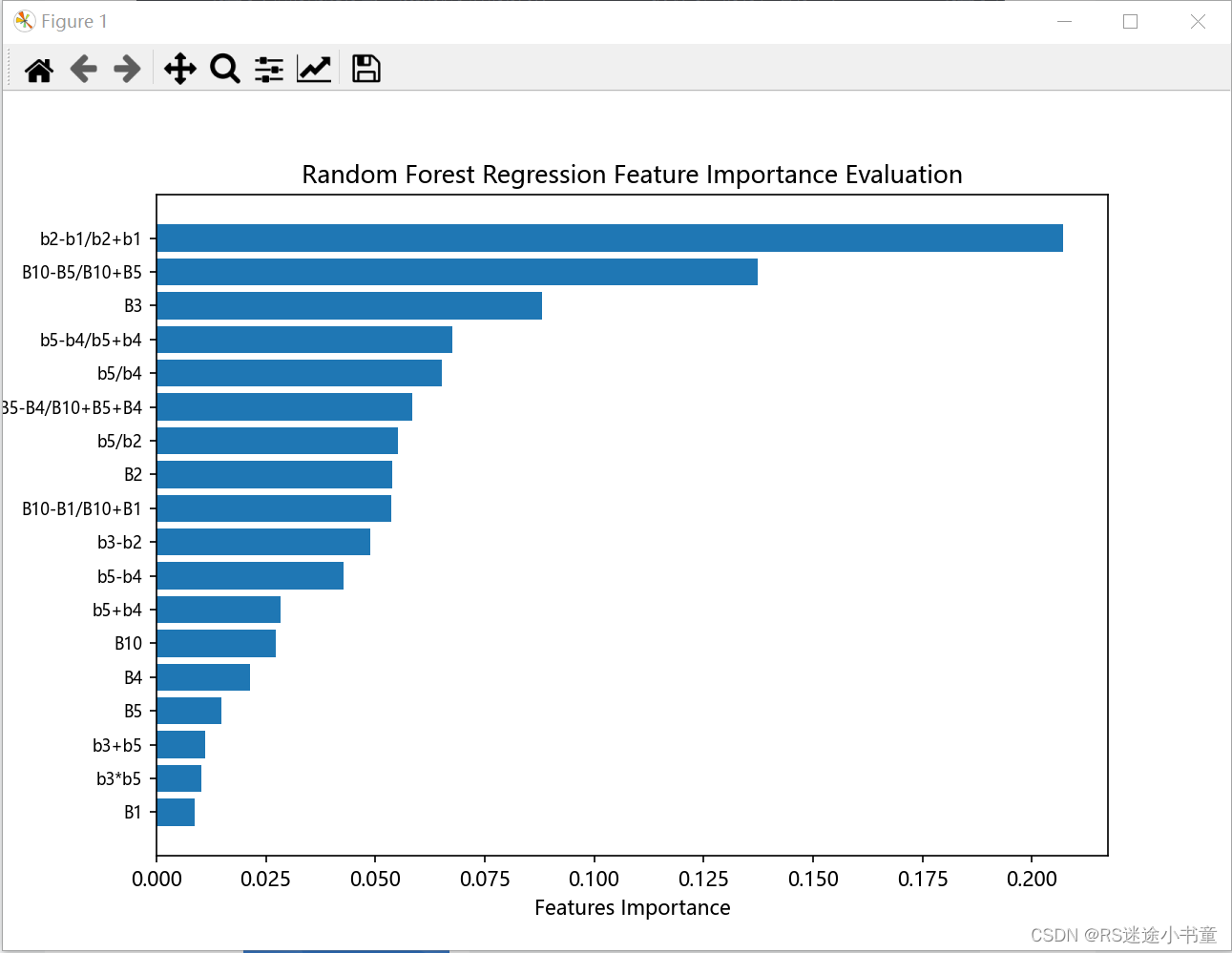

4. 总结
随机森林算法做分类和回归问题还是不错的,只不过有个缺点就是无法直接将拟合的方程展示出来,只能直接将预测结果输出。所以大家在使用时可以将训练的模型保存,这样后面分析数据的时候就又可以调用这个模型了,不然每次分析都需要将训练和预测放在一起。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/423766
推荐阅读
相关标签

