
- 1强推5款办公工具,网页版免下载,拿来即用_好用的网页版软件
- 2windows sql server 如何卸载干净?_sql server卸载
- 3MATLAB计算投资组合的cVaR和VaR
- 4Aurora 和 ChipToChip IP(一)_aurora ip核
- 5【头歌-Python】Python第五章作业(初级)(1~6)_python头歌程序设计基础第五章答案
- 6【SpringBoot】从入门到精通的快速开发指南_spring boot从入门到精通
- 7【Docker】Docker的确保环境安全,Docker部署安全性,Sandbox,PaaS,Open Solution,Open Solution,Docker Datacenter的详解_在docker中部署 安全性
- 8数据库系统概念第七版(Database System Concepts 7th)课后习题答案英文版_数据库系统概念第七版课后答案
- 9基于Android Studio 实现计算器(简单易上手使用技术多)_安卓studio计算器
- 10数据结构9 - 常用的10种算法_数据结构算法
计算机视觉——基于深度学习检测监控视频发生异常事件的算法实现_视频监控异常事件分析算法
赞
踩
1. 简介
视频异常检测(VAD)是一门旨在自动化监控视频分析的技术,其核心目标是利用计算机视觉系统来监测监控摄像头的画面,并自动检测其中的异常或非常规活动。随着监控摄像头在各种场合的广泛应用,人工监视已经变得不切实际,因为这一任务既单调又耗时。此外,监控设备的快速增长使得用人工有效监视大量摄像头变得日益困难,因此迫切需要自动化的解决方案。
异常事件通常指的是在特定场景和时间下出现的不寻常活动,例如打斗、偷窃、纵火和事故等。这些事件是否被视为异常,很大程度上取决于它们发生的环境和上下文。例如,在高速公路上骑马会被视为异常行为,而在草原上则是正常现象。这种上下文依赖性增加了异常检测的复杂性。
图像异常检测可以识别图像中的不寻常物体或物体与场景之间的异常关系,但这种方法仅限于使用空间信息,而不考虑时间维度。对于需要同时考虑空间和时间信息的异常事件,如快速移动或徘徊行为,仅在图像级别上进行分析是不够的。VAD技术则通过分析视频中的时空信息来检测和定位异常事件,这包括识别物体的运动模式以及物体与场景之间关系的变化。
VAD系统的性能预期是能够输出一个包含所有检测到的异常事件的开始和结束时间的列表,从而让操作人员知道哪些帧包含异常内容。此外,一些先进的VAD系统甚至能够识别并与异常事件相关的物体的具体位置,这为操作人员提供了更准确的异常事件源头信息。通过这种方式,VAD技术不仅能够提高监控效率,还能够在必要时为人类工作人员提供及时的警报和有用的信息。
2.视频异常检测
视频异常检测(VAD)方法可以根据利用的学习技术分为两种主要方法:
1.单类分类方法
2.弱监督学习方法。不是由于大规模真实世界VAD数据集缺乏逐帧的注释,监督学习方法在该领域的研究人员中并未受到关注。
2.1. 单类分类方法
早期的视频异常检测(VAD)方法主要采用单类分类的策略,这意味着它们的预测模型主要针对正常视频进行训练。这些方法的核心目标是构建一个能够捕捉正常活动特征的字典,这样的特征字典可以通过手工设计的特征或者利用深度学习中的自编码器模型来学习。
在训练过程中,模型学习如何从正常视频中提取关键特征,并尝试重建这些视频,以便最小化重建误差。这个过程使得模型能够对正常的活动模式有一个深入的理解。当模型遇到新的、未知的视频输入时,它会尝试使用已经学到的正常特征来重建这个输入。如果重建的结果与实际输入有很大的偏差,并且这种偏差超过了一个预先设定的阈值,那么这个输入就会被标记为异常。
尽管这种方法在处理与训练数据相似的正常视频时表现良好,但它们在泛化到包含异常情况的新数据集上通常存在局限性。这是因为在训练阶段,模型没有接触到任何异常样本,因此缺乏处理这些情况的能力。这种局限性导致了单类分类方法在实际应用中的一些挑战,尤其是在需要处理多样化异常事件的复杂场景中。为了克服这些挑战,研究人员开始探索包括弱监督学习在内的其他方法,以便在训练过程中利用正常和异常视频的组合,并提高模型在实际环境中的泛化能力和检测性能。
2.2 弱监督学习方法
基于单类分类的视频异常检测(VAD)方法在训练时仅使用正常视频,这限制了它们在处理真实世界异常事件时的泛化能力。为了解决这个问题,研究者们转向了基于弱监督学习的VAD方法。这些方法在训练过程中同时使用正常和异常视频,并结合一定形式的监督信号。
与直接预测每一帧是否包含异常的监督学习不同,弱监督学习VAD中的监督信号通常来源于一个相关但更宏观的任务,例如判断整个视频是否存在异常。这种监督信号提供了视频层面的标签,而不是具体的帧级别信息,也就是说,它告诉我们视频中是否有异常发生,但没有指明异常发生的具体时间点。
尽管缺乏精确的时间定位信息,视频级标签比逐帧标签更容易获得,这使得研究者能够构建包含大量视频的数据集,用于弱监督VAD模型的训练。这种方法的优势在于,它可以利用更多的数据来训练模型,因为获取整个视频是否异常的标签通常比标注每个异常事件的具体时间戳要简单得多。
通过利用这些容易获得的视频级标签,研究者们能够训练出能够在帧级别上检测异常的模型。这些模型在处理视频数据时,能够更好地识别和定位异常事件,从而提高VAD系统的整体性能。弱监督学习VAD方法的发展,为处理大规模视频数据集和提高异常检测的准确性开辟了新的可能性。
2.2.1 多实例学习
在视频异常检测(VAD)的研究中,多实例学习(MIL)作为一种弱监督学习技术,因其在处理视频级标签时的潜力而受到广泛关注。MIL方法适用于那些只有视频级标签可用的情况,即知道某个视频整体是否包含异常,但不具体知道异常发生在哪一刻。
在MIL框架下,输入的长视频被切分成一系列短片段。深度学习模型,包含视频处理骨干和预测头,被用来分析这些片段,并为每个片段分配一个异常分数。这个分数反映了该片段异常的可能性。在MIL中,整个视频被视为一个“袋子”,如果视频中至少有一个片段是异常的,则该视频被标记为正样本(包含异常);如果视频中没有任何异常片段,则为负样本(不包含异常)。
由于缺乏具体的逐帧或逐段标签,传统的损失函数,如均方误差(MSE)或交叉熵损失,不适用于MIL。相反,MIL使用排名损失,这是一种特殊的损失函数,用于在训练过程中优化模型的性能。排名损失通过比较正样本袋子中最高异常分数片段与负样本袋子中最高异常分数片段的得分来工作。如果负样本袋子中的得分高于正样本袋子,模型就会受到惩罚。这种设计基于一个假设:即使在包含异常的视频里,也不是所有片段都是异常的,至少应该有一个异常片段的得分高于所有正常视频片段的得分。
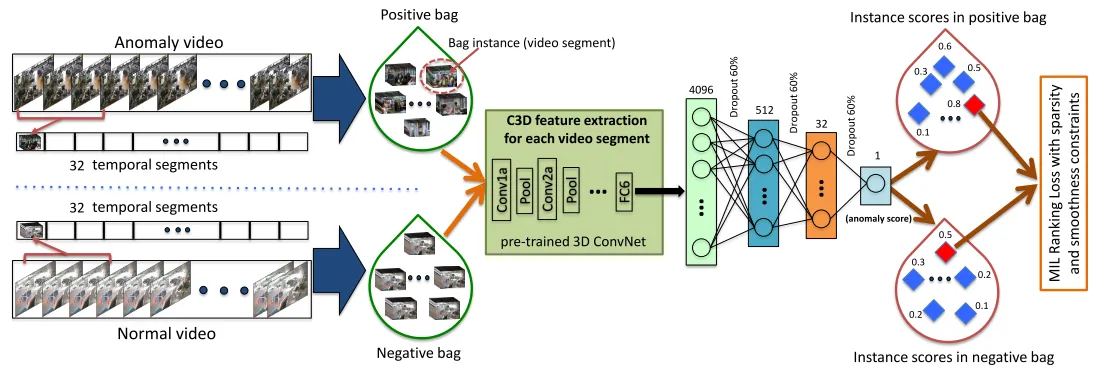
在推理阶段,训练好的VAD模型会独立处理每个视频片段,为它们生成异常分数,并将这些分数与预先设定的阈值进行比较,以判断片段是否异常。
尽管已经提出了多种基于MIL的VAD方法,但这些方法在保持Sultani等人提出的关键思想的同时,通过采用不同的模型架构和训练技巧来提升预测的准确性。这些方法的变体在处理视频异常检测任务时提供了不同的视角和改进,进一步推动了VAD技术的发展。
2.2.2排名损失和正则化项
在视频异常检测(VAD)的研究中,排名损失及其变体被广泛用于提升模型的性能。除了Sultani等人(2018)提出的顶级排名损失之外,还有其他几种排名损失的变化形式被应用于VAD研究中。例如,Dubey等人(2019)提出了一种比较异常视频的前三个异常分数与正常视频最大分数的方法,而Kamoona等人(2023)则计算了正常和异常视频袋子之间异常分数的平均差异,并尝试最大化这一差异。
为了引导模型学习到期望的特性,通常会在损失函数中加入正则化项。Sultani等人(2018)在他们的排名损失中引入了时间平滑和稀疏性两个正则化项。时间平滑项通过计算两个相邻视频片段异常分数的平方差之和来工作,这有助于减少分数在正常和异常之间的快速波动。稀疏性项基于异常事件在实际中发生频率较低的假设,通过对预测的异常分数进行惩罚,来避免模型将过多的片段错误地标记为异常。这两个正则化策略已经被其他基于多实例学习(MIL)的方法采用,如Dubey等人(2019)、Kamoona等人(2023)和Tain等人(2021)的研究。
2.2.3 模型架构
在基于多实例学习(MIL)的视频异常检测(VAD)模型中,通常包含两个关键模块:视频处理骨干和预测头。
-
视频处理骨干:这个模块负责将输入的视频片段转换为高维嵌入空间中的向量表示。视频片段由一系列的帧组成,每帧具有特定的空间分辨率(h×w)、通道数(c)和帧数(t)。视频处理骨干通常采用三维卷积神经网络(3D CNN),如C3D或I3D,这些网络能够同时处理视频的空间信息和时间信息。这些视频骨干可以在如Kinetics这样的大规模动作识别数据集上进行预训练,学习到丰富的时空特征,之后可以迁移到VAD任务中。尽管可以在VAD任务的训练阶段对视频骨干进行微调,但为了提高效率和减少计算资源的消耗,许多研究选择在预训练后冻结其参数。
-
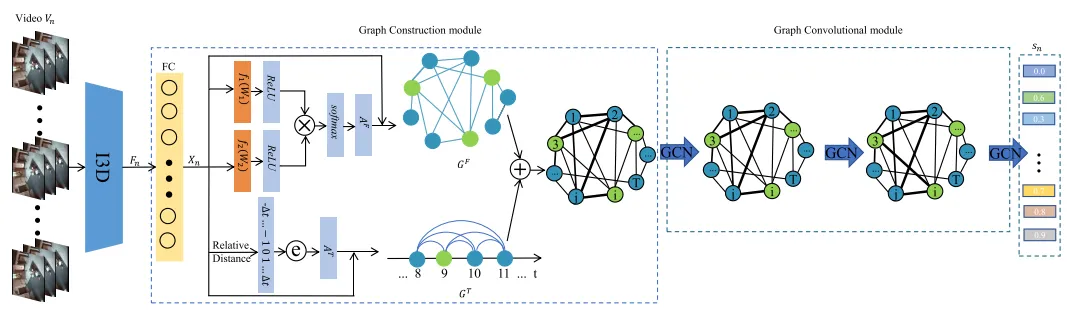
预测头:这个模块接收视频处理骨干输出的嵌入向量,并基于这些向量预测每个视频片段的异常分数。预测头的设计可以多种多样,Sultani等人(2018)设计的预测头是一个具有两个隐藏层的全连接网络。随着研究的发展,出现了许多其他的预测头设计,例如Cao等人(2022)提出的基于图卷积网络(GCN)的预测头,它能够模拟视频片段之间的上下文关系。他们的方法是首先使用I3D骨干将每个视频片段转换为嵌入向量,然后构建一个图,其中节点代表视频片段,节点之间的连接权重基于嵌入的相似性和时间接近度。通过将这个图输入到GCN中,模型能够预测每个片段的异常分数,从而利用片段之间的上下文信息。
除了GCN,其他网络架构也被用于提取视频片段之间的关系,例如一维卷积层、因果卷积层和注意力网络。这些网络能够捕捉视频片段之间的长期依赖关系和重要性分布。此外,为了减少误报,一些研究如Pu等人(2023)在推理流程中引入了分数平滑模块,以平滑视频帧之间的异常分数波动。这些方法的共同目标是提高VAD模型在检测视频中异常事件方面的准确性和鲁棒性。
2.2.4 数据增强
数据增强是深度学习中一种常用的技术,它通过在训练数据中引入人为的多样性来提高模型的泛化能力。在视频异常检测(VAD)的背景下,数据增强尤其重要,因为它可以帮助模型更好地理解和识别真实世界中可能出现的各种变化和干扰。
有的研究人员提出的噪声模拟策略是一种创新的数据增强方法,它通过向正常视频片段中添加不同类型的噪声,如运动模糊、抖动和画面中断,来模拟可能在实际监控场景中遇到的各种干扰。这种方法的关键在于,添加噪声后的片段仍然被标记为正常,这迫使VAD模型学会区分由真实异常事件和常见噪声引起的变化。
通过这种数据增强,模型能够在训练过程中接触到更多样化的视频内容,从而提高其在面对未见过的数据时的鲁棒性。这样的训练不仅有助于模型识别异常行为,还能够减少因常见噪声和干扰而产生的误报。这对于提高VAD系统在实际应用中的性能至关重要,尤其是在监控环境中,这些环境可能充满各种不可预测的变化和干扰。通过这种方式,数据增强技术为VAD研究提供了一种有效的工具,以提升模型在现实世界中的实用性和可靠性。
2.2.5 伪标签
另一种提高VAD模型性能的技术是使用伪标签,这些标签是用于训练的未标记数据的目标标签,就像它们是真实标签一样。伪标签可以从伪标签生成技术或训练过的模型的预测中获得。
Lv等人(2021)介绍了一种生成手工异常并带有片段级伪标签的技术。他们随机选择一对正常和异常视频,并将异常视频中的随机片段融合到正常视频中。在正常视频中融合片段的位置被标记为异常。这种技术使他们能够拥有片段级伪标签,以增强他们的多实例学习(MIL)框架,提高模型的异常定位能力。
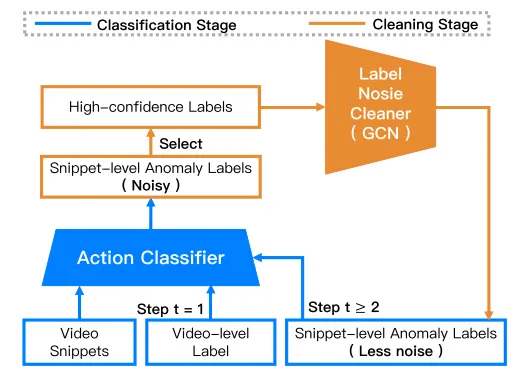
另一方面,Zhong等人(2019)提出了一个噪声清洁框架,如下图所示,以精炼和选择高置信度的预测作为伪标签。他们设计了一个图卷积网络(GCN),并将其添加到他们的训练流程中,以清除噪声预测。他们的行动分类器和标签噪声清洁器交替进行训练。一旦训练完成,只有行动分类器模块用于推理。通过来自高置信度预测的伪标签,他们将弱监督学习重新定义为带有噪声标签的监督学习,并使用常见的交叉熵损失训练他们的模型。
2.2.6 提示学习
CLIP(Contrastive Language-Image Pre-training)模型因其在视觉-语言任务中的卓越性能而受到广泛关注。CLIP由两个主要部分组成:一个视觉编码器和一个文本编码器,它们通过对比学习的方式共同训练,使得当输入的图像和文本描述相匹配时,两个编码器生成的嵌入向量能够相互对齐。
Pu等人在2023年提出了一种名为提示增强学习(Prompt-Enhanced Learning, PEL)的技术,该技术在多实例学习(MIL)框架下训练视频异常检测(VAD)模型时,有效地利用了CLIP模型。PEL的核心思想是使用异常类别的名称,比如“打斗”或“抢劫”,作为提示词,通过查询ConceptNet这样的知识图谱来找到与这些提示词相关的词汇,从而丰富模型对于异常情境的理解。
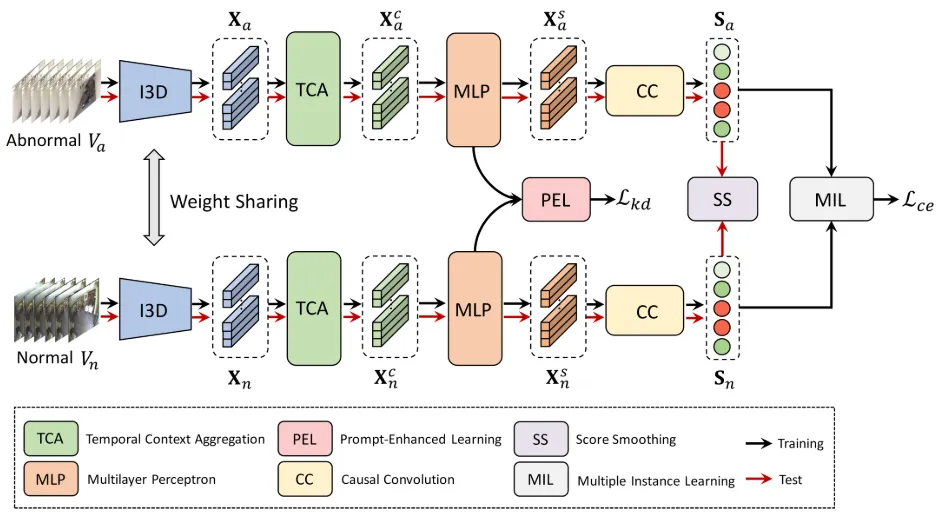
在训练VAD模型的过程中,PEL技术指导模型将可能是异常的视频片段的视觉嵌入与知识图中查询到的相关词汇的文本嵌入进行对齐,同时确保这些视觉嵌入与表示“正常”或“非暴力”情境的文本嵌入保持距离。这样的训练策略使得VAD模型能够更好地理解和识别视频中的异常行为,因为它不仅考虑了视频内容本身,还结合了丰富的上下文信息。
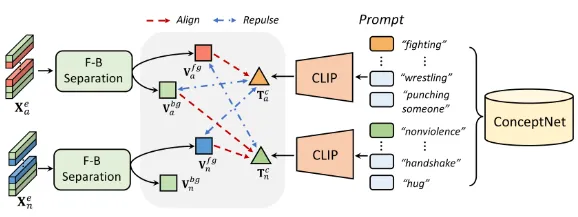
通过这种方式,PEL技术能够有效地提升VAD模型在复杂场景中检测异常事件的性能,尤其是在面对多样化和开放世界的异常类别时。这种方法的关键在于它能够利用自然语言描述中的丰富信息,为视频内容提供更深层次的语义理解,从而增强模型对于异常的识别和定位能力。
3.开源数据集
大规模的基准数据集对于训练强大的深度学习模型至关重要。对于VAD,迄今为止已经提出了几个公共基准数据集。这些大规模的VAD数据集通常提供一组只有相应视频级标签的训练视频,即正常或异常视频,使VAD模型能够使用弱监督学习进行训练。然而,仅对测试集提供逐帧的注释,允许研究人员使用逐帧评估指标对他们的模型进行基准测试。本节旨在介绍一些值得注意的公共数据集和VAD的评估指标。
3.1 UCF-Crime
UCF-Crime数据集(Sultani等人,2018)是一个早期的大规模VAD数据集,捕捉现实世界的异常。除了正常类别外,数据集中还有13类真实世界的异常,包括“虐待”、“逮捕”、“纵火”、“袭击”、“盗窃”、“爆炸”、“打斗”、“交通事故”、“抢劫”、“枪击”、“扒窃”、“偷窃”和“破坏”。它由来自现实世界监控摄像头的1,900个未修剪视频组成。所有视频总共长达128小时,每个视频平均有7,247帧。数据集分为一个训练集(1,610个视频,其中800个正常和810个异常视频)和具有视频级标签的测试集(290个视频,其中150个正常和140个异常视频),以及具有逐帧标签的测试集。
3.2 ShanghaiTech
ShanghaiTech数据集(Luo等人,2017)是在复杂的光照条件和摄像机角度下收集的(图7)。它包含13个真实世界场景,每个场景由多个视频组成。ShanghaiTech数据集最初被提出作为一个单类分类问题,因为它的训练集只包含正常视频。它包含270K帧正常视频用于训练,而测试集总共包含130个异常事件。它还提供了异常区域的像素级注释。后来,Zhong等人(2019)为ShanghaiTech提出了一个训练/测试划分,建立了一个新的协议来训练和评估该数据集上的模型。在这个训练/测试划分下,训练集包含238个视频(175个正常和63个异常视频),而测试集包含199个视频(155个正常和44个异常视频)。

3.3 XD-Violence
与其他数据集不同,XD-Violence(Wu等人,2020)是一个大规模的VAD数据集,提供4,754个未修剪的视频和音频信号,允许模型利用多模态信息进行异常检测。XD-Violence数据集包括六种身体暴力:‘虐待’、‘车祸’、‘爆炸’、‘打斗’、‘暴动’和’枪击’。数据集总共长217小时。它分为一个训练集(3,954个视频,其中2,049个正常和1,905个异常视频)和具有视频级注释的测试集(800个视频,其中300个正常和500个异常视频)。每个异常视频包含1-3个异常事件。
3.4 TAD
虽然几个VAD数据集主要关注与人类相关的异常事件,但交通异常检测或TAD数据集(Lv等人,2021)专注于交通场景中的异常检测。它由包含七种道路异常的长未修剪视频组成:‘车辆事故’、‘非法转弯’、‘非法占用’、‘逆行’、‘行人在道路上’、‘道路溢出’和’其他’。数据集中有500个交通监控视频,总共长达25小时。训练集包括400个视频,具有视频级注释,而测试集包括100个视频,具有逐帧注释。训练集和测试集都包含各种异常和正常视频。

3.5 Street Scene
Street Scene数据集(Ramachandra和Jones,2020)提供了鸟瞰两车道街道的视频。它包括17个在街道上发生的异常类别,如’乱穿马路’、‘自行车道外骑行者’、'非法停车的汽车’等。与其他几个只为测试集提供逐帧注释的数据集不同,Street Scene数据集提供了带有跟踪号码的异常事件周围的边界框。在这个数据集中,一个单一的帧可能包含多个标记的异常。

3.6 UBnormal
UBnormal(Acsintoae等人,2022)是最近用于监督开集VAD的基准数据集。然而,这些数据是通过使用Cinema4D,一个3D建模软件套件,在真实世界背景中放置动画角色/对象生成的虚拟数据集。由于它是生成的,因此为训练集和测试集都提供了像素级注释,允许研究人员以监督学习的方式训练VAD模型。数据集包括几个对象,如人、汽车、滑板、自行车和摩托车。以下事件被认为是正常的:‘行走’、‘打电话’、‘边走边发短信’、‘站立’、‘坐下’、‘大喊’和’与他人交谈’,而有22个异常事件,如’跑步’、‘摔倒’、‘打斗’、'睡觉’等。然而,这些异常事件的组织方式形成了一个开集VAD,即训练(六种类型)、验证(四种类型)和测试(12种类型)集中的异常事件类型不重叠。

4.评估指标
尽管存在多种具有不同特征的基准数据集,但视频异常检测(VAD)研究中最常见的评估指标是ROC-AUC和误报率。
ROC-AUC是接收者操作特征(ROC)曲线下的面积(AUC),该曲线是真正例率(TPR)与假正例率(FPR)的对比图。这个指标衡量了VAD模型在不同阈值下的整体性能。ROC-AUC值更高的VAD模型被认为比ROC-AUC值较低的模型更优秀。
误报率是在给定阈值下计算的,衡量VAD模型错误地将正常视频帧/片段预测为异常的次数。然后将这个数值除以VAD模型处理的正常帧/片段的总数进行归一化。通常使用的阈值为0.5,异常分数范围在0到1之间。
除了这些定量测量之外,许多研究人员还通过展示预测图来呈现VAD模型预测的定性结果。
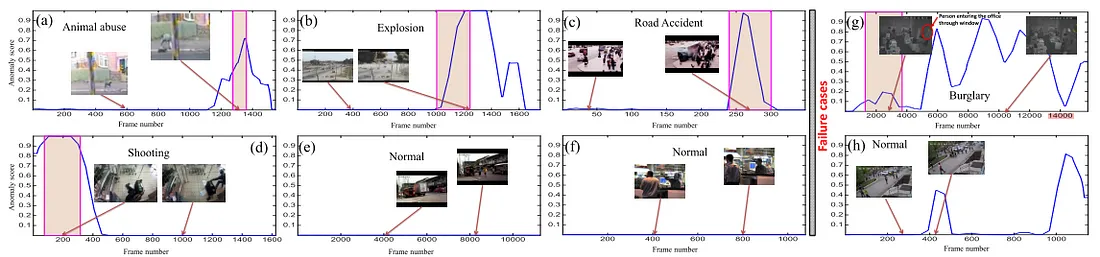
定性结果示例。每个图表都是预测的异常分数(蓝色曲线)与视频中的帧数对比图,而粉色曲线表示异常事件发生的时间,即真实情况(图片来自Sultani等人,2018年)。
5. 未解决的问题和挑战
尽管许多研究人员致力于开发更加健壮的VAD方法,但仍有改进的空间和未解决的挑战。首先,由于缺乏用于训练的逐帧注释,目前最先进的(SOTA)方法基于弱监督学习。尽管这些方法已被证明远优于基于单类分类的方法,但目前的SOTA性能尚未在大规模数据集上达到90%的ROC-AUC。例如,在UCF-Crime上的ROC-AUC约为86-87%,在XD-Violence上的AP约为85-86%,这还有进一步改进的空间。
其次,现实世界中发现的一些异常事件可能差异很大,与训练集中的事件截然不同。这将在实际环境中部署VAD模型时,特别是在环境和上下文差异很大的情况下,造成泛化性能问题。正如第3节所述,最近提出了一个名为UBnormal(Acsintoae等人,2022年)的数据集,用于训练和评估开集VAD。在开集设置中,测试集中出现的异常事件类型可能在训练集中不存在。Acsintoae等人(2022年)报告称,开集VAD比闭集VAD更具挑战性。
第三,正如第1节所讨论的,异常性高度依赖于上下文。虽然训练VAD模型能够在不同的场景和上下文中检测异常,即场景依赖型VAD,具有挑战性,但对于实际应用来说至关重要。最近,出现了一个名为NWPU Campus数据集(Cao等人,2023年),用于训练和评估VAD模型以识别场景依赖型异常。
最后但同样重要的是,开发一个可解释的VAD系统,使用户能够理解为什么预测某一帧/片段为异常,最近受到了研究人员的关注(Singh等人,2023年和Doshi和Yilmaz,2023年)。例如,Singh等人(2023年)包括一个模块来学习高级属性,如对象类型、移动方向和速度,这些属性可以解释为他们VAD流程中的一部分。一旦检测到异常,人类观察者将更容易理解异常事件中涉及的人物或物体。

