
- 1C++初阶:7.vector
- 2requires API level 14 (current min is 8)解决办法_描述资源路径位置类型 view requires api level 14 (current min
- 3Vue前端代码高亮编辑器Ace_vue brace
- 4html盒子有哪些属性,css的盒子模型属性有哪些?
- 5在Ubuntu 14.04 64bit上安装redis 3.0.3_ubantu安装redis 3.0.7
- 6【git】【IDEA】在idea中使用git_idea查看git仓库内容
- 7蓝桥杯岛屿个数dfs(已找到bug)
- 8华为OD机试题:出勤奖的判断_公司用一个字符串来表示员工的出勤信息
- 9大学php实训总结1500字,实训报告1500字通用六篇
- 10Nacos-注册中心原理解析
开源 AI 编程助手 AutoDev 0.7 发布—— 生成规范化代码,深入开发者日常
赞
踩
几个月前,我们朝着探索:如何结合 AIGC 的研发效能提升的目标?开源了 AutoDev,如 GitHub 所介绍的:
AutoDev 是一款基于 JetBrains IDE 的 LLM/AI 辅助编程插件。AutoDev 能够与您的需求管理系统(例如 Jira、Trello、Github Issue 等)直接对接。在 IDE 中,您只需简单点击,AutoDev 会根据您的需求自动为您生成代码。您所需做的,仅仅是对生成的代码进行质量检查。
随着,我们对于 LLM 能力边界的探索,发现了一些更有意思的模式,这些探索的模式也融入了 AutoDev 中。
PS:在 JetBrains 插件中搜索 AutoDev 并安装,配置上你的 LLM,如 OpenAI 及其代理、Azure OpenAI 代理、开源 LLM 等即可使用。
WHY AutoDev?对于 GenAI + 软件研发结合的理解
于生成式 AI 来说,我们依旧保持先前分享时相似的观点:
GenAI 可以在研发流程的几乎每个环节产生提效作用。
对于标准化流程提效比较明显,不规范的小团队提升有限。
由于 prompt 编写需要耗费时间,提效需要落地到工具上。
所以,在设计 AutoDev 时,我们的目标是:
端到端集成,降低交互成本。即从 prompt 编写到与 LLM 交互,再复制回工具中。
自动收集 prompt 的上下文生成内容、代码
最后由人来修复 AI 生成的代码。
那么,手动整理规范、自动收集上下文,以提升生成内容的质量,便是我们做工具里所要探索的。
AutoDev 0.7 新特性
从四月份的大 DEMO,到如今的新版本里,我们持续研究了 GitHub Copilot、JetBrains AI Assistant、Cursor、Bloop 等 IDE/编辑器的代码、实现逻辑等。每个工具都有其独特的卖点,再结合我日常的一引起开发习惯,添加了一系列探索性的新功能。
详细见 GitHub:https://github.com/unit-mesh/auto-dev
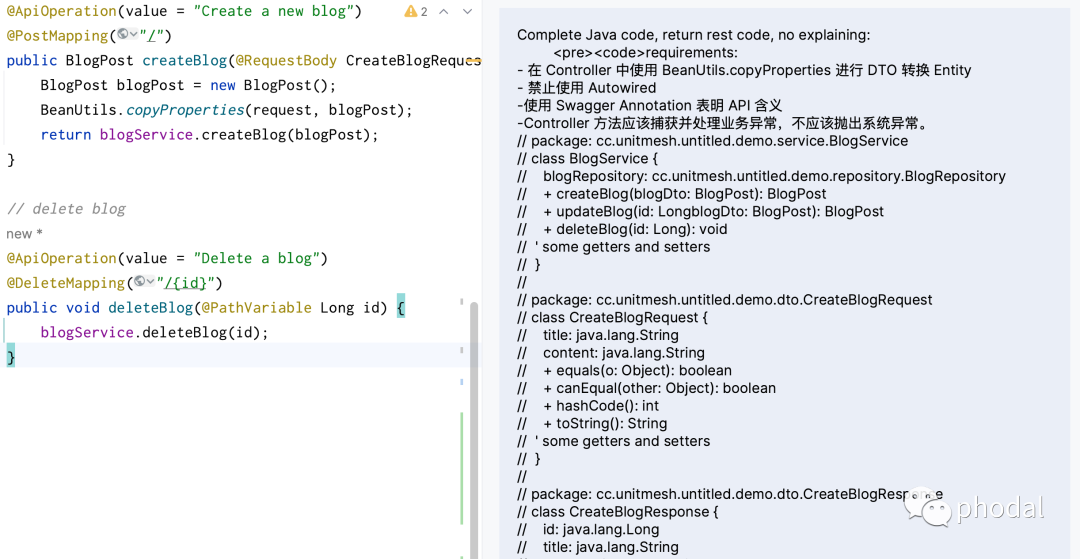
特性 1:架构规范与代码规范内建
LLM 的复读机模式(生成机机制),会根据当前上下文的编程习惯,复读出相似的代码。即在使用诸如 GitHub Copilot 这一类的 AI 代码生成功能时,它会根据我们如何处理 API,来生成新的 API 代码。如果我们的代码使用了 Swagger 注解生成 API 代码,那么在同一个 Controller 下也会生成相似的代码。
这也意味着问题:如果前人写的代码是不规范的,那么生成的代码亦是不规范的。因此,我们在 AutoDev 添加了配置 CRUD 模板代码的规范:
- {
- "spec": {
- "controller": "- 在 Controller 中使用 BeanUtils.copyProperties 进行 DTO 转换 Entity",
- "service": "- Service 层应该使用构造函数注入或者 setter 注入,不要使用 @Autowired 注解注入。",
- "entity": "- Entity 类应该使用 JPA 注解进行数据库映射",
- "repository": "- Repository 接口应该继承 JpaRepository 接口,以获得基本的 CRUD 操作",
- "ddl": "- 字段应该使用 NOT NULL 约束,确保数据的完整性"
- }
- }
在一些特殊的场景下,只有这个规范是不够的,还需要配置示例代码。在有了这个配置之后,当我们在生成 Controller、Service 等代码时,可以直接用上述的规范生成。
特性 2:深入开发者日常编程活动
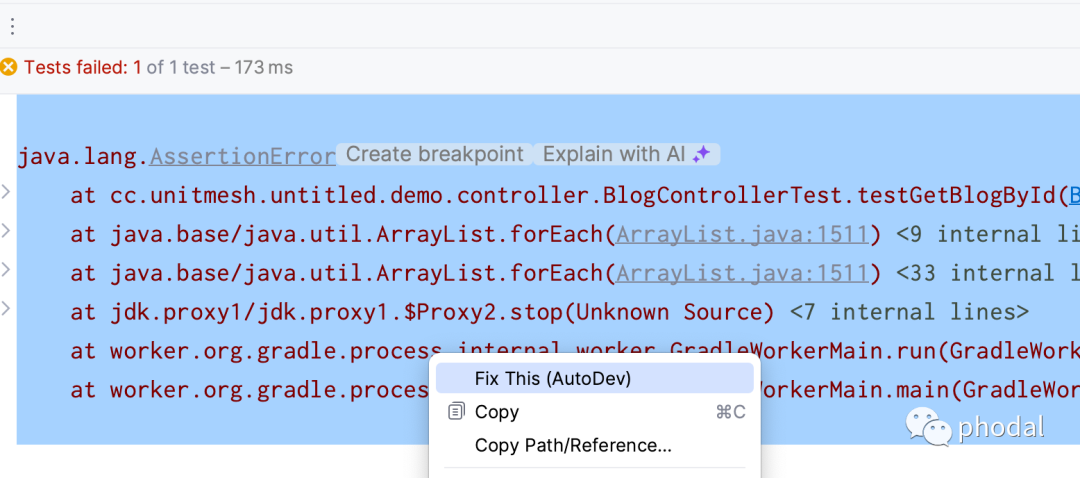
在四月份发布的时候 ,AutoDev 集成了基本的编程活动能力:AI 填充代码、添加代码注释、重构代码、解释代码等等。
而在开发 AutoDev 自身功能的时候,我们发现了一些更有意思的需求,也集成到了 IDE 中。
一键生成提交信息。在我们使用 IDEA 的 UI 功能写提交信息时,可以一键生成参考的提交信息。
一键生成发布日志。在提交历史中,选中多个 commit,根据提交信息,来生成 CHANGELOG。
错误信息一键分析。编写代码时,DEBUG 遇到错误,选中错误信息,可以自动结合错误代码,发送给 LLM 进行分析。
代码测试代码。
再加上,AutoDev 最擅长的拉取需求进行自动 CRUD 的功能,在功能上更加完备了。
特性 3:多语言的 AI 辅助支持
四月份,我们发现 LLM 非常擅长于 CRUD,所以选中了 Java 语言作为测试与场景,只构建了 Java 语言的自动 CRUD 功能。而像我最近几年经常用的 Kotlin、Rust、TypeScript,都没有支持,而这就对我不友好了。
于是,参考了 Intellij Rust 的模块化结构,重新组织了分层、模块,并以 Intellij Plugin 的扩展点 (XML + Java)重塑了整个应用的基础架构。
以下围绕新架构下产生的新扩展点:
语言数据结构扩展点。原先的设计中,这部分用于在 token 不够时,使用 UML 来表达原来的代码。随后,我们参考(抄袭)了 JetBrains AI Assistant 的语言扩展点功能,即不同的语言的数据结构在自身的扩展中实现。
语言 prompt 扩展点。不同语言也有自身的 prompt 差异,这些差异也被移到各自的模块中实现。
自定义 CRUD 工作流。现有的 CRUD 实现,绑定的是 Java 语言特性,而每个语言有自身的不同实现方式,也交由语言自身去实现。
当然了,当前依旧只有 Java/Kotlin 支持是最好的。
特征 4:更广泛的 LLM 支持
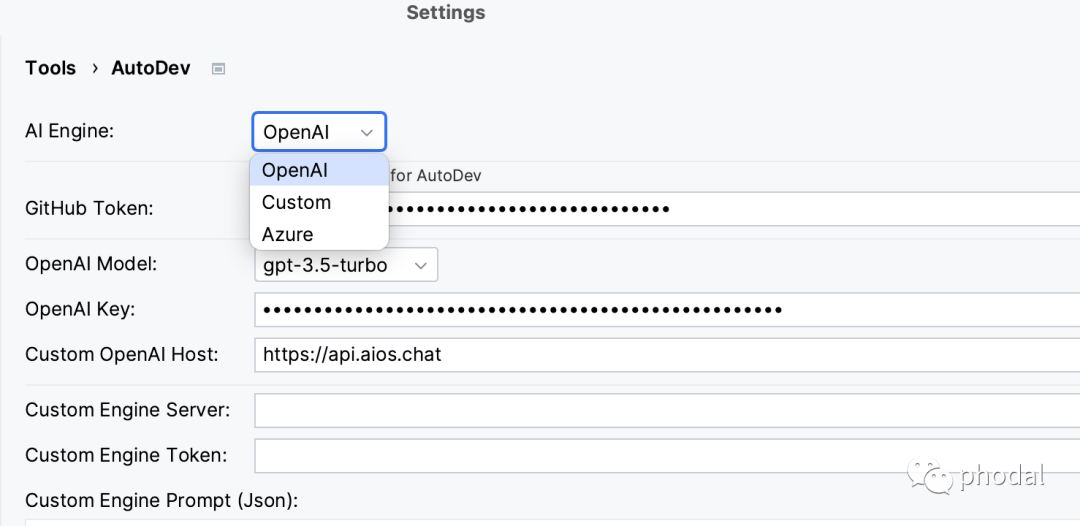
AutoDev 在设计初衷面向我们的第二个假设是:每个大公司都会推出自己的 LLM。每个 LLM 都有自身的特点,所以我们需要有更多的 LLM 支持。
OpenAI 及其代理。目前是测试最多的,也是最完整的。
Azure OpenAI。作为一个在国内合法使用 OpenAI 的渠道,我们也在先前的版本中进行了初步的支持,并逐步地完善了这个功能。
其它 LLM。虽然,还没有找到合适的国内 LLM API 进行适配,但是已经在接口上构建了这样的能力。
欢迎大家结合自己的 LLM 尝试。
特征 5:更智能的 prompt 策略
回到我们 5 月份的那篇《上下文工程:基于 Github Copilot 的实时能力分析与思考》里,我们详细分析了 GitHub Copilot 的 prompt 策略。围绕于这个策略,会有基本的 promptElements 诸如: BeforeCursor, AfterCursor, SimilarFile, ImportedFile, LanguageMarker, PathMarker, RetrievalSnippet 等。
在发现了 JetBrains AI Assistant 也在尝试使用类似的方式来构建其 prompt 策略时。我们也进一步参考,并完善了 AutoDev 的 prompt 策略,以让其更智能。
代码上下文策略。
Java 语言 + CRUD 模式下,会尝试按相关代码(BeforeCursor)、调用代码的所有方法、调用代码行、相关代码的 UML 等方式构建。
Java 语言其它模式下,会使用 DtModel 来构建类 UML 的注释,作为相关任务的参考。
Python 语言,会根据 import 来相似代码段来构建生成 prompt 作为注释,作为 LLM 的参考。
计算策略。剩下的则是根据 token 是否超限,来不分配适合的上下文。
作为一个所谓的 “智能上下文” 策略,现有的策略还需要进一步优化。
其它
有兴趣的话,欢迎来 GitHub 讨论代码:https://github.com/unit-mesh/auto-dev 。

