
- 1邮箱投递简历注意哪些礼仪?
- 2STM32标准库FLASH读写_stm32 flash读写 库函数版
- 3程序媛的mac修炼手册-- 2024如何彻底卸载Python_mac系统如何清除python安装环境
- 4如何保证RabbitMQ消息的顺序性_rabbitmq如何保证消息的顺序性
- 5cuda9.1+torch0.4.0+torchvision.0.2.2+python3.6.x配置_wincuda9.1安装torch
- 6语言模型在新闻媒体中的应用
- 7Python数据可视化工具matpoltlib使用_python matpoltlab
- 8Pytorch-Lightning--v1.9中的训练器--Trainer
- 9必读!信息抽取(Information Extraction)【命名实体识别】_信息抽取作用
- 10flink NoSuchMethodException: org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy
Elasticsearch插件管理(ik分词器、附件文本抽取插件)_elasticsearch 攫取文件内容
赞
踩
倒排索引
Elasticsearch 使用一种称为倒排索引的结构,它适用于快速的全文搜索。见其名,知其意,有倒排索引,肯定会对应有正向索引。正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。
所谓的正向索引,就是搜索引擎会将待搜索的文件都对应一个文件 ID,搜索时将这个ID 和搜索关键字进行对应,形成 K-V 对,然后对关键字进行统计计数。
但是互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
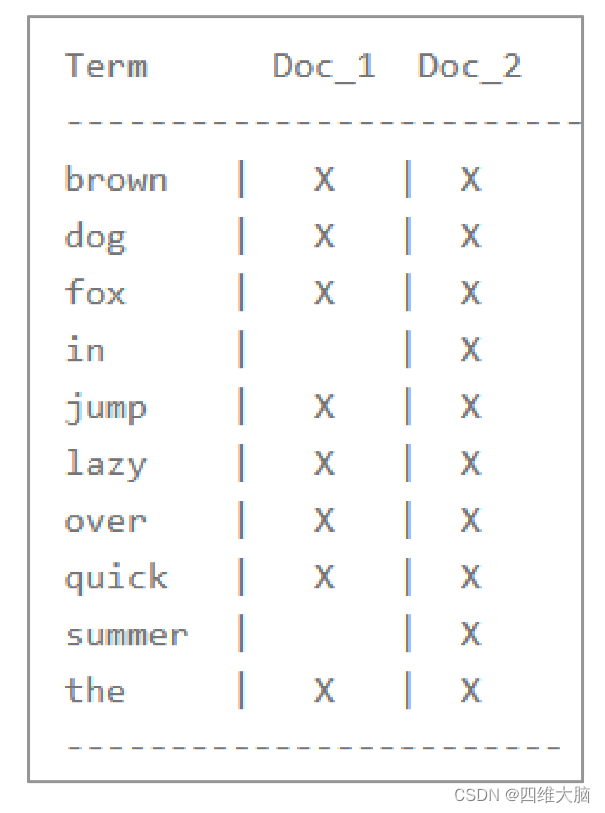
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,我们首先将每个文档的 content 域拆分成单独的 词(我们称它为 词条或 tokens ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:

现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单相似性算法,那么我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
但是,我们目前的倒排索引有一些问题:
- Quick 和 quick 以独立的词条出现,然而用户可能认为它们是相同的词
- fox 和 foxes 非常相似, 就像 dog 和 dogs ;他们有相同的词根
- jumped 和 leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词
使用前面的索引搜索 +Quick +fox 不会得到任何匹配文档。(记住,+ 前缀表明这个词必须存在。)只有同时出现 Quick 和 fox 的文档才满足这个查询条件,但是第一个文档包含quick fox ,第二个文档包含 Quick foxes 。
我们的用户可以合理的期望两个文档与查询匹配。我们可以做的更好。
如果我们将词条规范为标准模式,那么我们可以找到与用户搜索的词条不完全一致,但具有足够相关性的文档。例如
- Quick 可以小写化为 quick 。
- foxes 可以 词干提取 --变为词根的格式-- 为 fox 。类似的, dogs 可以为提取为 dog 。
- jumped 和 leap 是同义词,可以索引为相同的单词 jump 。
现在索引看上去像这样:
这还远远不够。我们搜索 +Quick +fox 仍然 会失败,因为在我们的索引中,已经没有 Quick 了。但是,如果我们对搜索的字符串使用与 content 域相同的标准化规则,会变成查询+quick +fox,这样两个文档都会匹配!分词和标准化的过程称为分析
这非常重要。你只能搜索在索引中出现的词条,所以索引文本和查询字符串必须标准化为相同的格式。
如何对文档进行分词,这里就需要ik分词器。
ik分词器
下载对应版本的ik分词器包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
- 1
在es的plugins目录下创建ik目录,将下载的zip包解压进去
cd /opt/module/es/plugins
mkdir ik
unzip elasticsearch-analysis-ik-7.17.5.zip -d /opt/module/es/plugins/ik
- 1
- 2
- 3
如果是多节点,每个节点都需要放入该分词器插件,重启所有节点,完成安装!!!
如果不使用分词器
GET _analyze
{
"text":"测试单词"
}
{
"tokens" : [
{
"token" : "测",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "试",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "单",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "词",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
使用分词器
GET _analyze
{
"text":"测试单词" ,
"analyzer":"ik_max_word"
}
{
"tokens" : [
{
"token" : "测试",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "单词",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
analyzer参数包括:
- ik_max_word:会将文本做最细粒度的拆分
- ik_smart:会将文本做最粗粒度的拆分
当然也可以自定义词典
进入到/opt/module/es/plugins/ik/config目录
将自定义的词典放入到该目录
修改 vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">mydict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
比如mydict.dic就是自定义词典。
附件文本抽取插件
通过定义pipeline流水线,在数据插入前进行处理,这时候把附件文本插曲插件定义在流水线中,就能实现在入库前对于word文档进行自动抽取入库。
定义 pipeline
pipeline 定义了一系列处理器。 每个处理器以某种方式转换文档。 每个处理器按照在 pipeline 中定义的顺序执行。 pipeline 由两个主要字段组成:description 和 processor 列表。
description 参数是一个非必需字段,用于存储一些描述/管道的用法;
processor 参数可以列出处理器以转换文档
ngest 节点有大约20个内置 processor,包括 gsub,grok,转换,删除,重命名等。 这些可以在构建管道时使用。 除了内置processor 外,还可以使用提取附件(如 ingest attachment,ingetst geo-ip 和 ingest user-agent)等提取插件,并可在构建 pipeline 时使用。 这些插件在默认情况下不可用,可以像任何其他 Elasticsearch 插件一样进行安装。
PUT _ingest/pipeline/attachment
{
"description": "Extract attachment information",
"processors": [
{
"attachment": {
"field": "file-contents",
"ignore_missing": true
}
},
{
"remove": {
"field": "file-contents"
}
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
以上,我们建立了 1 个命名 pipeline 即 “attachment”,其中定义了 2 个预处理器 “attachment” 和 “remove” ,它们按定义顺序对入库数据进行预处理。
“attachment” 预处理器即上文安装的插件 “Ingest Attachment Processor Plugin” 提供,将入库文档字段 “file-contents” 视为文档附件进行文本抽取。要求入库文档必须将文档附件进行 BASE64编码写入 “file-contents” 字段。
文本抽取后, 后续不再需要保留 BASE64 编码的文档附件,将其持久化到 ElasticSearch 中没有意义,“remove” 预处理器用于将其从源文档中删除。
常用配置项:
- field : 指定某个字段作为附件内容字段(需要用base64进行加密)
- target_field:指定某个字段作为附件信息字段(作者、时间、类型)
- indexed_chars : 指定解析文件管道流的最大大小,默认是100000。如果不想限制设置为-1(注意设置为-1的时候如果上传文件过大会而内存不够会导致文件上传不完全)
- indexed_chars_field:指定某个字段能覆盖index_chars字段属性,这样子可以通过文件的大小去指定indexed_chars值。
- properties: 选择需要存储附件的属性值可以为:content ,title, name, author, keyword, date, content_ type, content_length, language
- ignore_missing: 默认为false,如果设置为true表示,如果上面指定的field字段不存在这不对附件进行解析,文档还能继续保留
插入数据
POST /student/_doc/1001/?pipeline=attachment
{
"name":"zhangsan",
"nickname":"zhangsan",
"sex":"男",
"age":30,
"file-contents" :"aGVsbG8gd29ybGQ="
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
查看数据就可以看到file-contents不见了,取而代之的是attachment对象,内容存储在attachment.content中
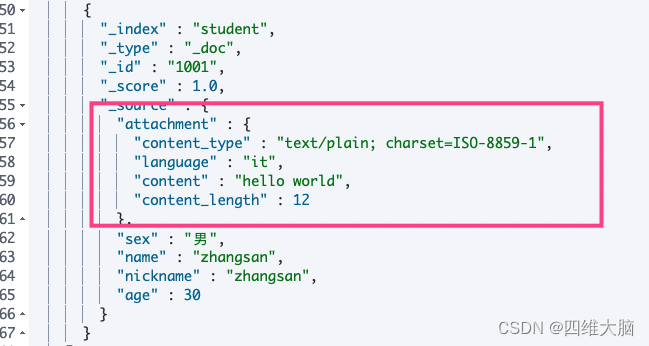
查看定义的pipeline
GET _ingest/pipeline
- 1

