
- 1如何自己的医疗图像分割数据集 使用NNunet进行训练_nnunet处理nii图像
- 2llama.cpp部署通义千问Qwen-14B_llama.cpp qwen
- 3轻松实现微信、QQ防撤回、多开工具_微信防撤回github
- 4napi系列学习基础篇——NAPI数据类型转换与同步调用
- 5用五一最简单的板做一个智能循迹小车_制作一个智能小车,前期有哪些检查工作
- 6干货:用好VSCode这13款插件,工作效率提升10倍_vscode design
- 7Sentence-Transformer的使用及fine-tune教程_distiluse-base-multilingual-cased
- 8一招解决从GItHub下载文件过慢问题_python下载github慢
- 9宇信科技:强势行业加速融入AIGC,同时做深做细
- 10用云手机运营TikTok有什么好处?
Win11平台下OCR开源项目实践之Tesseract OCR(一)
赞
踩
目录
一、OCR简介
1. OCR名词解释
OCR ,英文全称Optical Character Recognition,中文“光学字符识别”,是指针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
2. OCR应用场景
卡片证件识别类:身份证、通行证、护照识别,卡类识别,车辆类驾驶证识别、行驶证识别,执照识类识别,企业证件类识别。
文字信息结构化视频类识别:字幕识别和文字检测,表格。
票据类识别:增值税发票识别、全电发票识别、银行支票识别、承兑汇票识别、银行票据识别、物流快递识别。
其他识别:二维码识别、一维码识别、车牌识别、数学公式识别、物理化学符号识别、音乐符号识别、工程图识别、流程图识别、古迹文献识别、手写输入识别,文字识别、菜单识别、横幅检测识别、图章检测识别、广告类图文识别等围绕审核相关的业务应用。
业内有顶尖公司提供的可直接调用的API、SDK,这些方式面临着定制化场景泛化效果不好、价格昂贵、黑盒可控性低、无法离线使用等,所以推荐离线场景采用开源项目二次开发。
3. OCR开源项目简介
本次分享众多OCR开源项目中的Tesseract OCR,本文主要介绍OCR基础知识、详解识别软件环境的搭建,以及介绍如何用Python代码完成图片文字识别提取测试。
Tesseract OCR:经典的开源OCR引擎。
①源码下载地址 GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository)Tesseract Open Source OCR Engine (main repository) - GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository)![]() https://github.com/tesseract-ocr/tesseract ②Windows版本下载地址:Home · UB-Mannheim/tesseract Wiki · GitHubTesseract Open Source OCR Engine (main repository) - Home · UB-Mannheim/tesseract Wiki
https://github.com/tesseract-ocr/tesseract ②Windows版本下载地址:Home · UB-Mannheim/tesseract Wiki · GitHubTesseract Open Source OCR Engine (main repository) - Home · UB-Mannheim/tesseract Wiki![]() https://github.com/UB-Mannheim/tesseract/wiki Tesseract.js:基于TesseractOCR的Web浏览器OCR软件。
https://github.com/UB-Mannheim/tesseract/wiki Tesseract.js:基于TesseractOCR的Web浏览器OCR软件。
Ocrad: 轻量级的OCR解决方案,主要以识别印刷文本而闻名。
Ocrad.js :基于Ocrad的浏览器的OCR软件。
GOCR:在GNU通用公共许可证下开发的开源OCR引擎。
OCRopus:由Google开发的OCR相关工具集合。
Capture2Text:基于命令行的Windows OCR软件。
GImage Reader:能够识别多种语言以及各种图像文件格式的文本。
OCRmyPDF:专门用于PDF的OCR识别软件。
PaddleClas:飞桨为工业界和学术界所准备的一个图像识别和图像分类任务的工具集。
kraken :由Python开发的OCR软件,主要用于非拉丁字符的识别。
EasyOCR:Python开发的,基于机器学习(CRNN)实现OCR功能。
二、Tesseract OCR的搭建
1. Tesseract OCR简介
Tesseract OCR是非常经典的开源OCR引擎,最初由Hewlett-Packard开发,现在由Google维护。它以准确性和多功能性闻名,可以提取数据并将扫描的文档、图像和手写文字转换为机器理解的文本。支持100多种语言,并兼容多种操作系统,并且提供了非常方便的命令行界面。它是Apache 2.0许可,可以直接使用,或者(对于程序员)使用API从图像中提取文本。
1)优势:
准确性:提供非常高OCR准确性,特别是在打印文本和扫描文档方面。
语言支持:支持广泛的语言,允许识别多种语言的文本,包括一些特殊语种,使其成为多语言应用的理想选择。
持续改进:开源社区非常活跃,能够及时地更新升级项目、修复Bug、完善用户反馈的性能需求等。
2)缺点
复杂布局文档识别:在简单布局的文档上表现非常好,但在布局比较复杂的文档上就需要额外的预处理或后续处理步骤。
手写识别准确度:在识别机器打印文本方面表现出色,但在手写文本上的表现并不尽如人意,有时还不如一些专用手写识别工具准确。
医疗领域:
①在识别病历照片时,患者上传的照片,经常出现折叠、扭曲、光影等问题,对识别的干扰较大,影响识别质量。
②化验单等等的识别,不仅要识别出化验单上的文字,而且还要把文字填入规范化的表单里面。
2.下载Windows版本Tesseract OCR
此处下载的是Windows 64位版本。
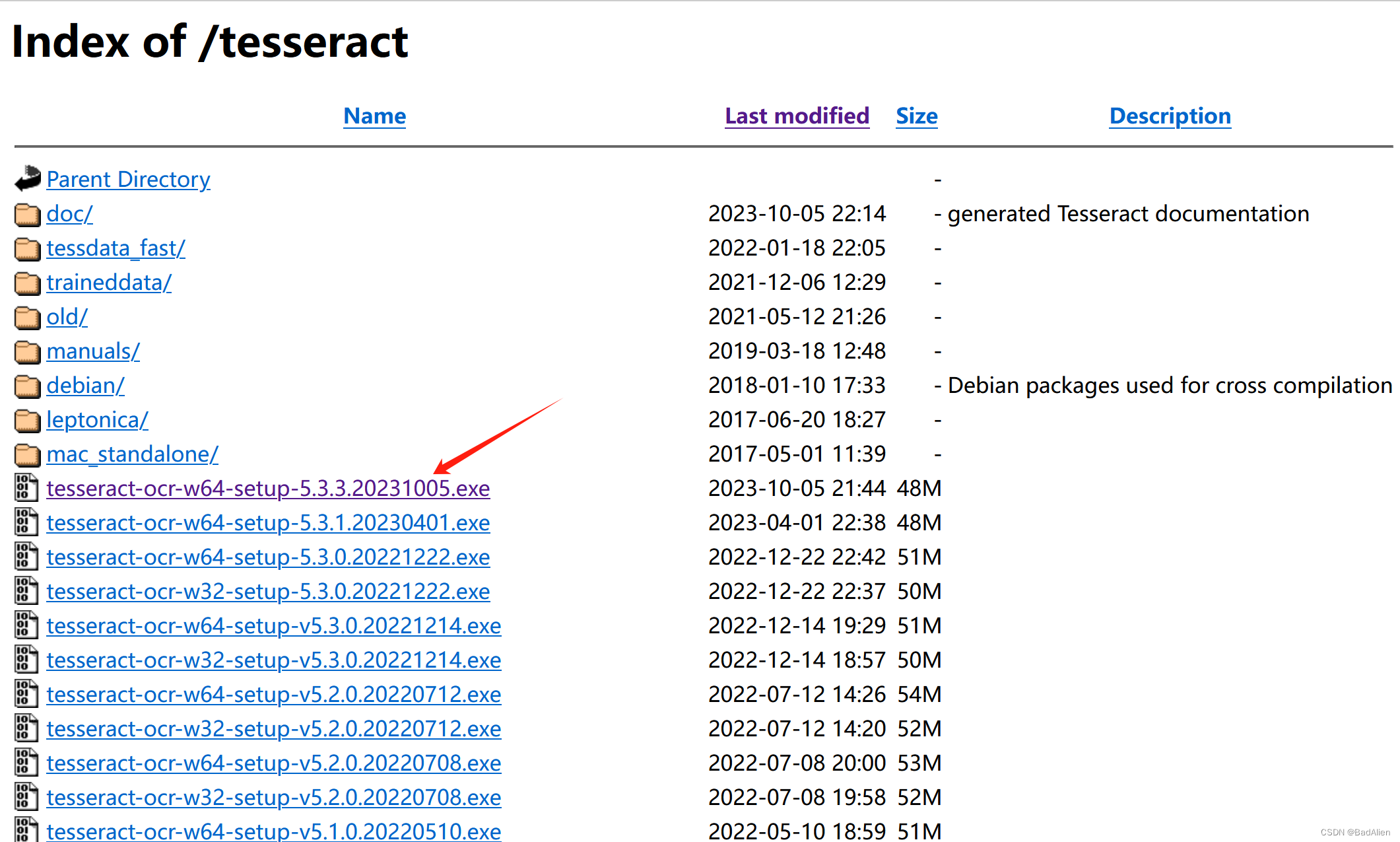
Index of /tesseract![]() https://digi.bib.uni-mannheim.de/tesseract/ 方式一:如下图红色箭头指示位置点击下载
https://digi.bib.uni-mannheim.de/tesseract/ 方式一:如下图红色箭头指示位置点击下载
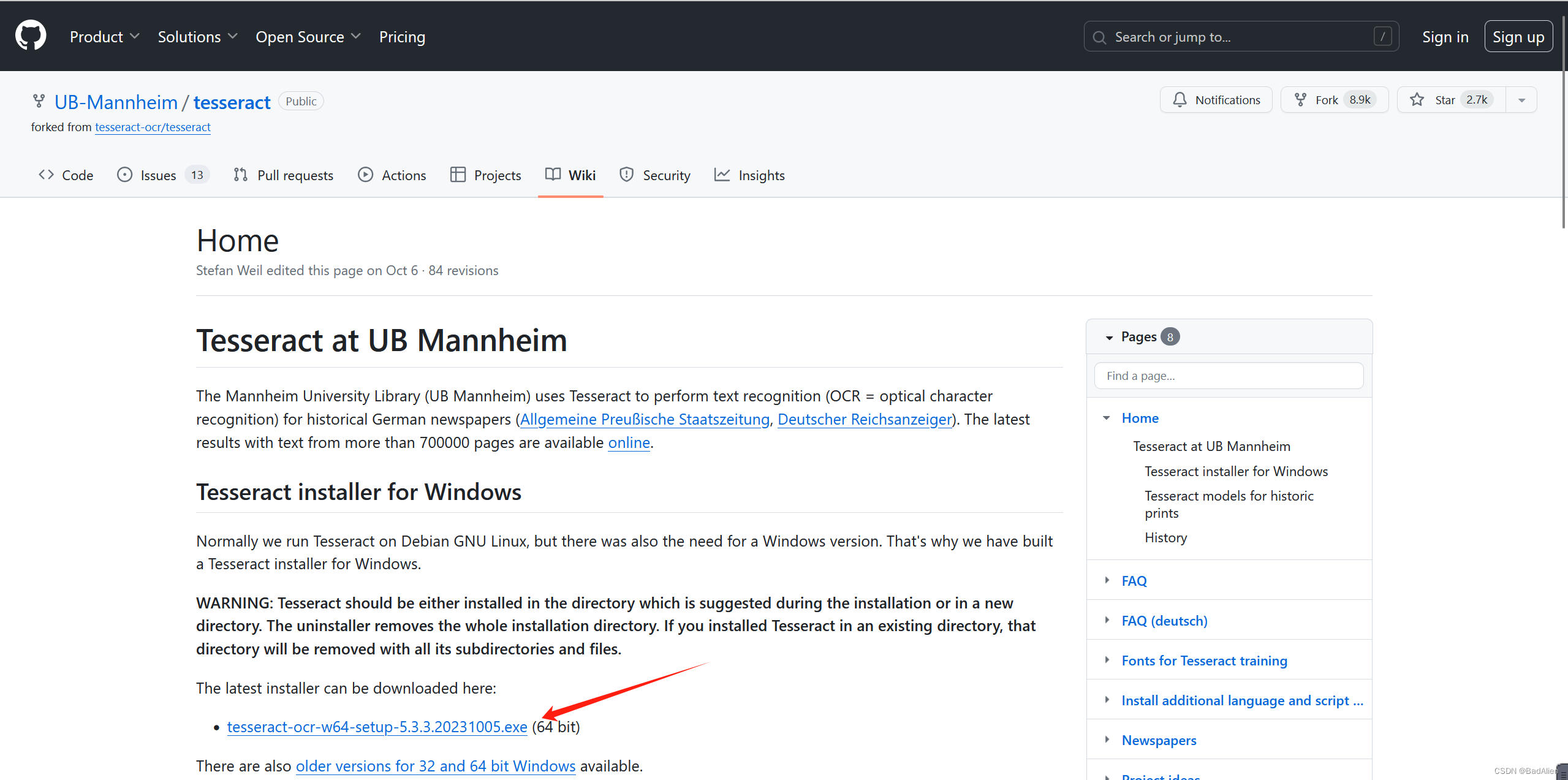
Home · UB-Mannheim/tesseract Wiki · GitHubTesseract Open Source OCR Engine (main repository) - Home · UB-Mannheim/tesseract Wiki![]() https://github.com/UB-Mannheim/tesseract/wiki 方式二:如下图红色箭头指示位置点击下载
https://github.com/UB-Mannheim/tesseract/wiki 方式二:如下图红色箭头指示位置点击下载
3.安装Tesseract OCR
1)软件需要安装引擎本身和语言的训练数据,双击“tesseract-ocr-w64-setup-5.3.3.20231005.exe”运行软件安装包,选择“English”,

2)上图最后两个设置,需要勾选安装相关的组件和语言数据,重点勾选简体中文支持组件及数据的下载,把Han开头的都勾选上。
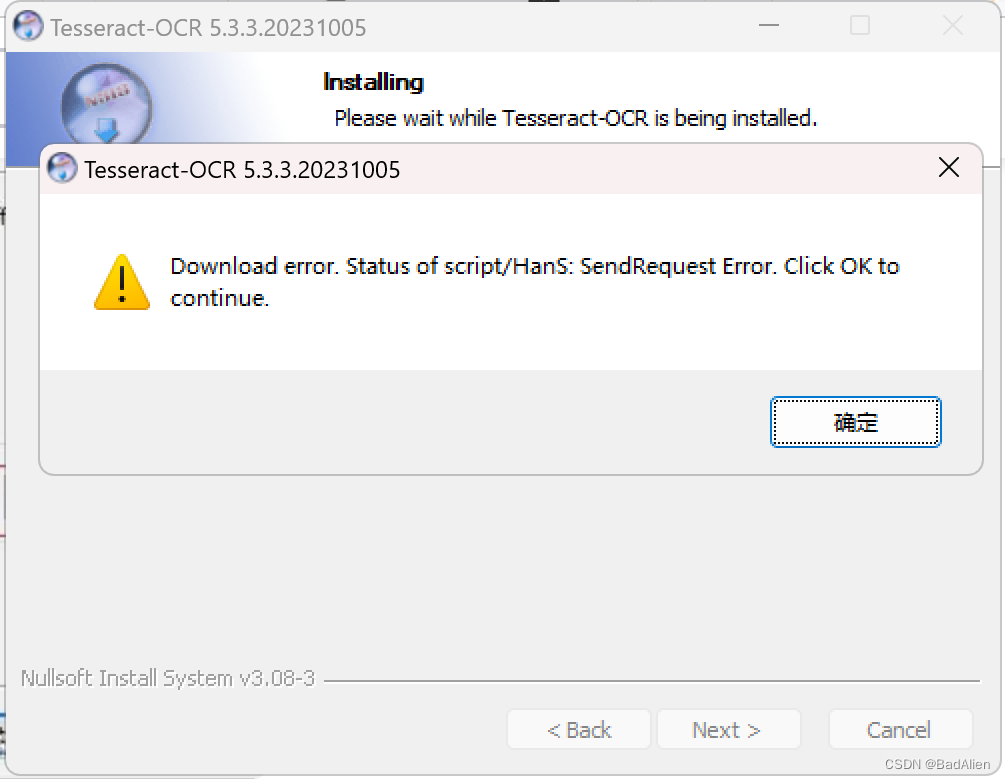
3)其他步骤根据提示自行选择直至软件安装完毕。期间可能弹出一些提示如下图的组件下载异常的提示对话框,直接单击“确定”即可。


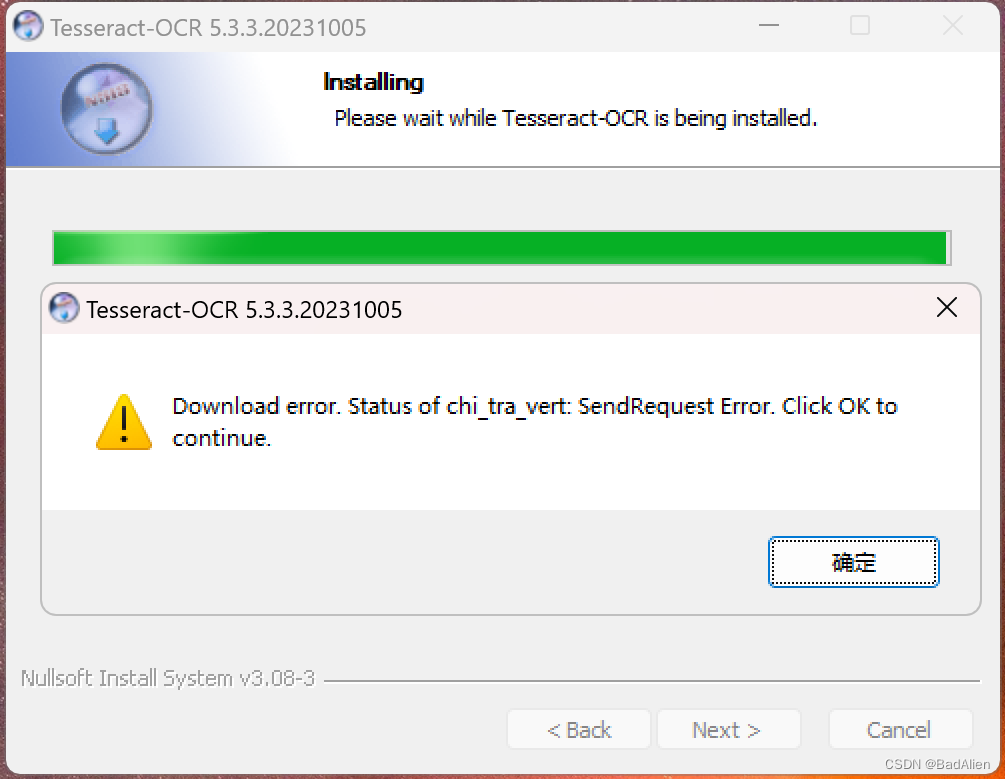
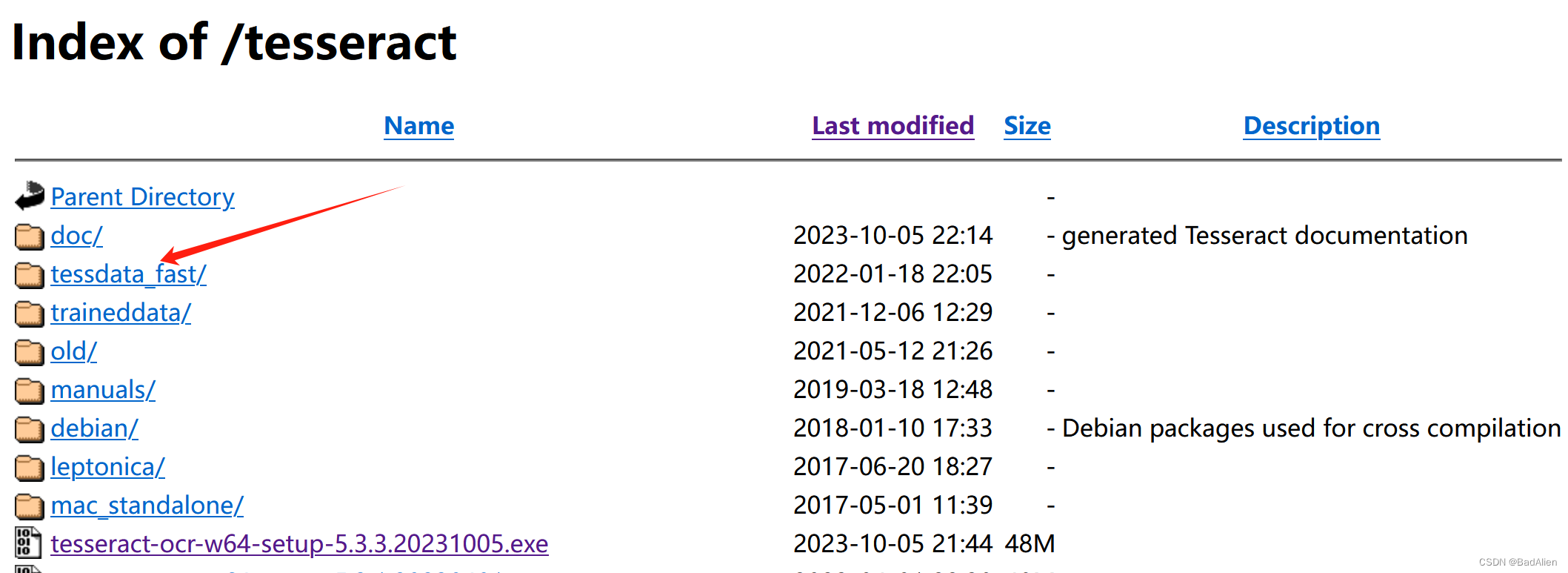
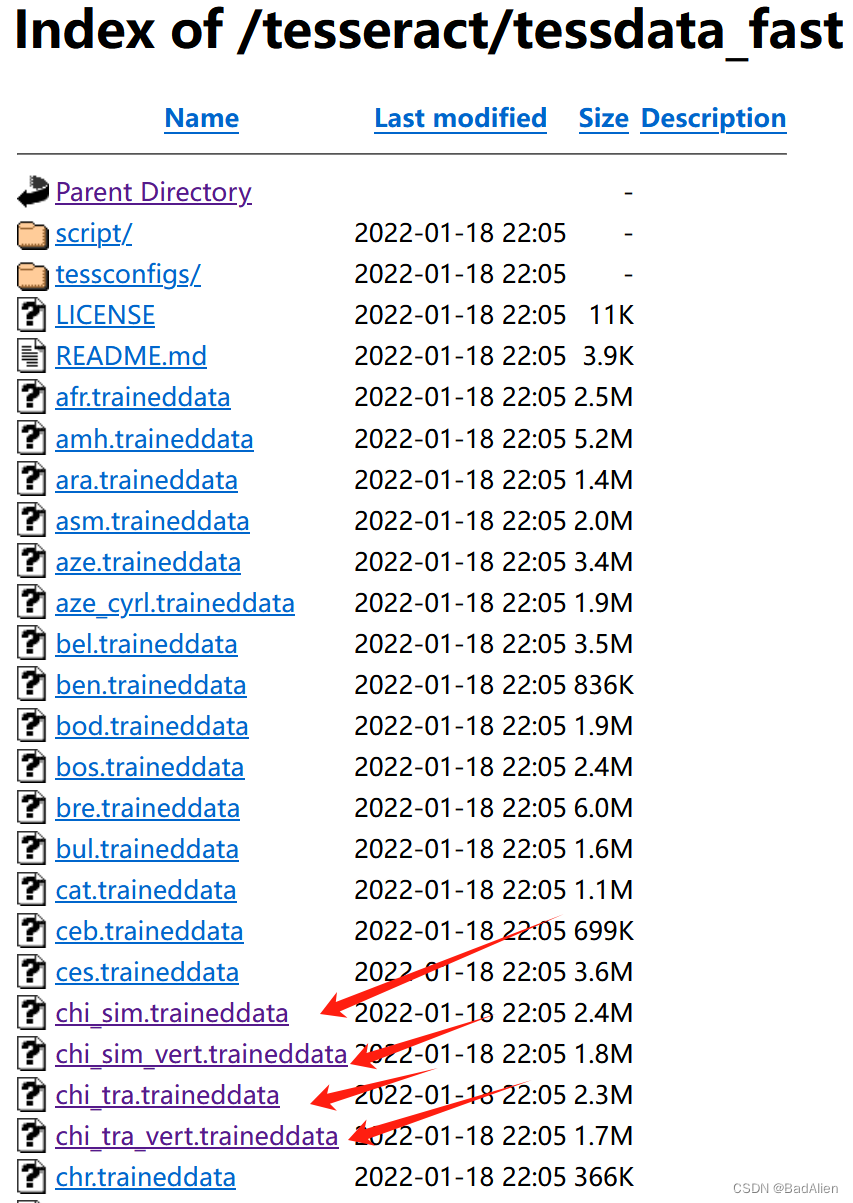
4)上面的图片提示语言包下载失败,接下来手动下载。 下载连接:Index of /tesseract,打开下载界面,进入文件夹“tessdata_fast”下载“chi_sim.traineddata、chi_sim_vert.traineddata、chi_tra.traineddata、chi_tra_vert.traineddata”。
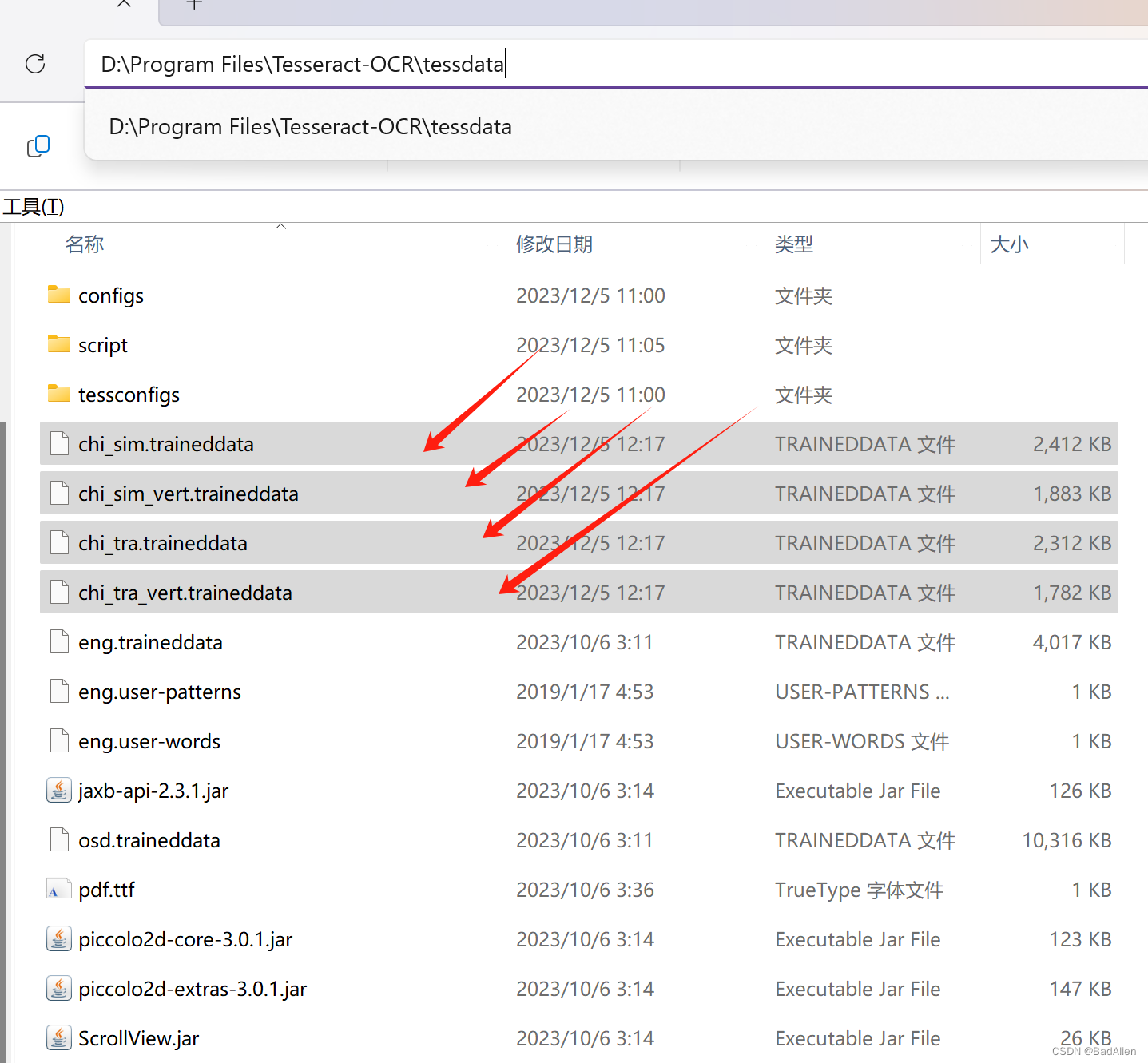
5)将下载下来的语言包直接放在tessdata文件夹下。
6)设置环境变量
右键桌面 “我的电脑”,选择“属性”,选择“高级系统设置”,点击“新建”弹出新“建用户变量”,依次填写:TESSDATA_PREFIX和D:\Program Files\Tesseract-OCR\tessdata
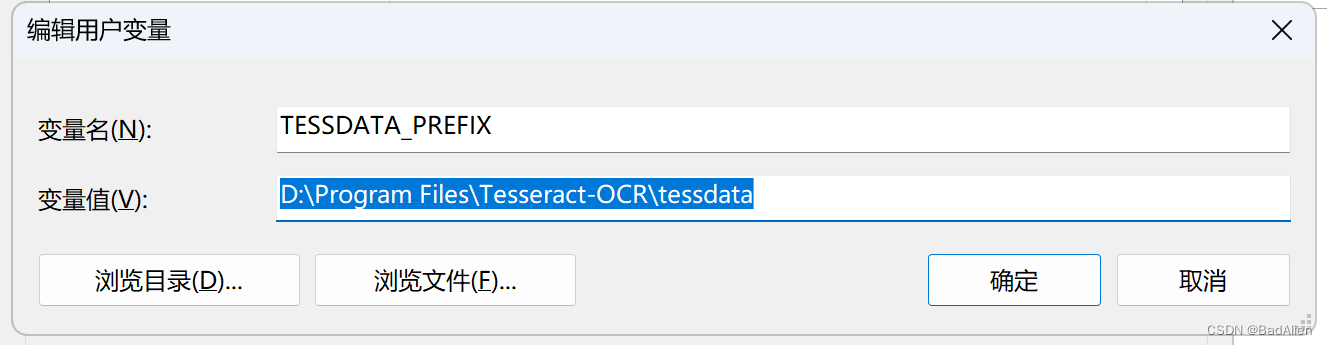
完成后点击“确定”,后返回“环境变量”设置界面,双击用户环境变量的Path,弹出“编辑环境变量”,单击“新建”然后把它的安装路径“D:\Program Files\Tesseract-OCR”粘贴到里边,单击“确定”完成设置。
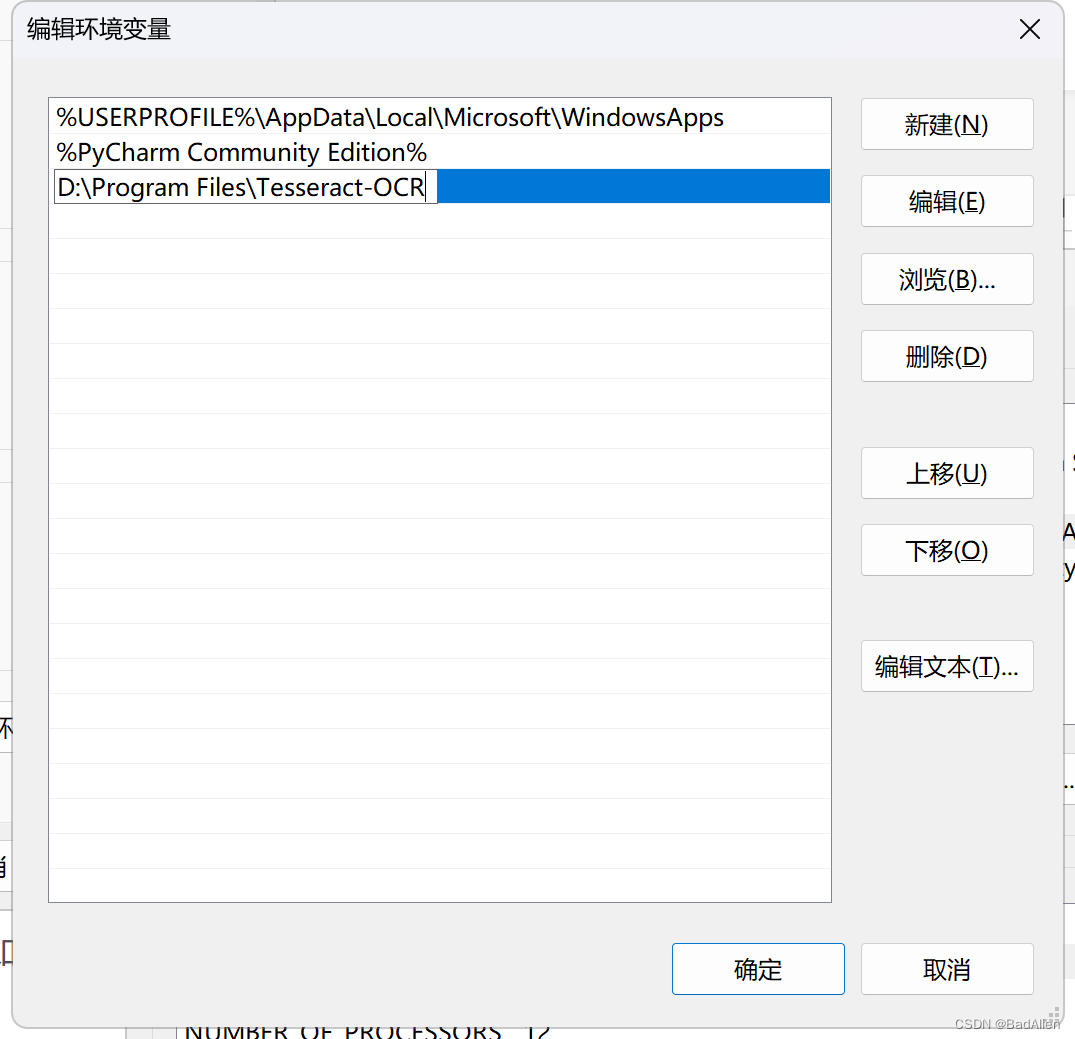
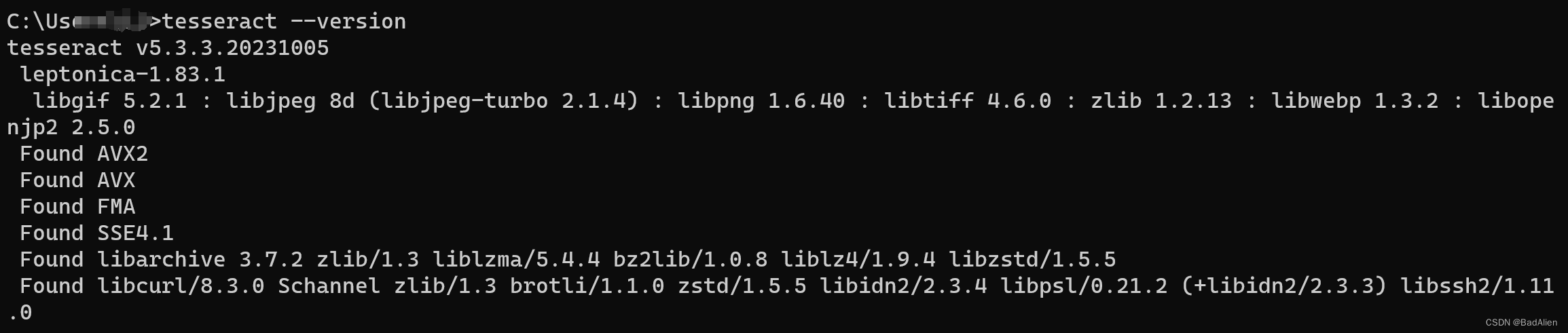
7)测试是否安装成功
CMD输入:tesseract --version
显示下图内容表示环境变量设置和软件安装完成。
4.测试Tesseract OCR识别效果
用如下图片测试软件安装是否成功。
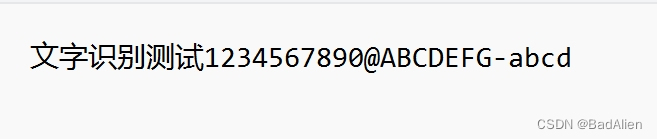
CMD输入:tesseract test.png test-result -l chi_sim

CMD查看文件识别内容:type test-result.txt
![]()
中文显示乱码,命令行运行“chcp 65001”将代码页设置为支持UTF-8字符集(重新打开CMD失效)。执行命令后中文字符显示正常,识别结果为1个字符(数字0误识别为6Q)识别失败。


5.安装Pytesseract
Pytesseract 是对 tesseract 命令行的简单的 python 封装。执行以下步骤,前提条件是Python环境已正常安装,否则会遇到如图我遇到的如下问题。
1)安装 Python Imaging Library (PIL) 工具包(Python 3.11.4 64位版本运行正常)
python -m pip install --upgrade PillowPython3.4版本发生如下错误:
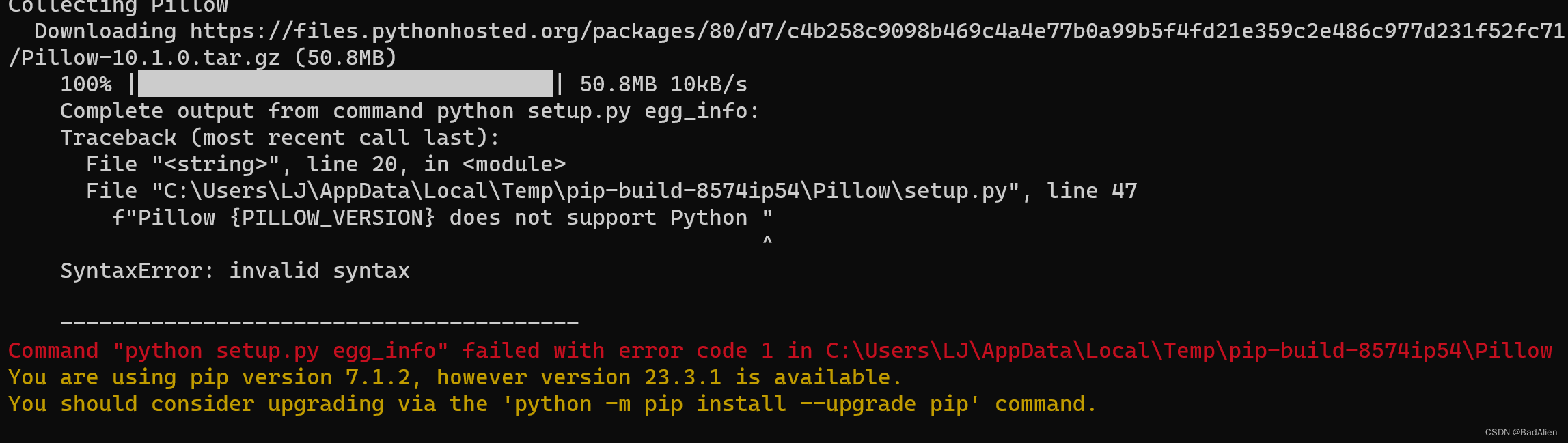
更换执行如下命令后正常更新。
python -m pip install --upgrade pip
执行安装出现如下错误:

需要重新安装pip,首先在Python安装目录“python\lib\site-packages”中删除pip文件。

然后重新安装和更新pip还是失败。
- #安装pip
- python -m ensurepip
-
- #更新pip
- python -m pip install --upgrade pip

更换Python版本为3.11.4 64位,安装Pillow正常。
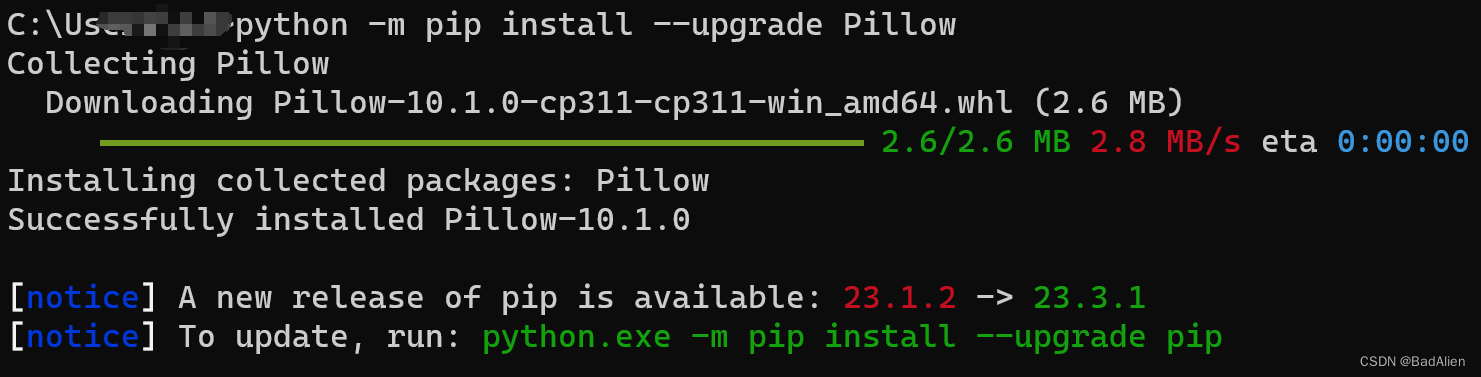
2)安装 Pytesseract 工具包
python -m pip install --upgrade pytesseract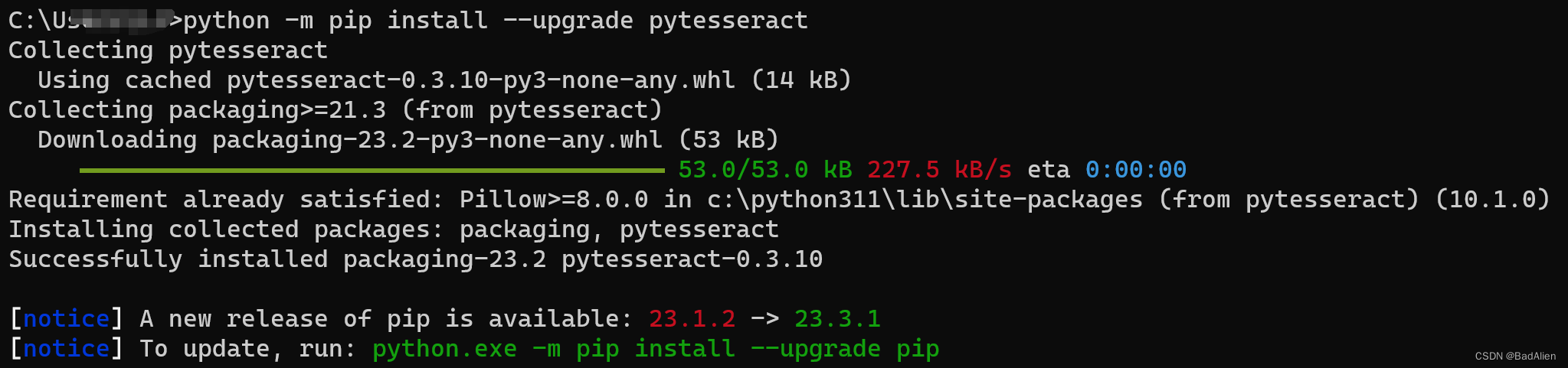
6.测试Pytesseract库识别效果
测试代码如下:
- import pytesseract
- import codecs
- from PIL import Image
-
-
- if __name__ == '__main__':
-
- im = Image.open('test.jpg')
- result = pytesseract.image_to_string(im, lang='chi_sim')
- print(result)
- # 首先导入codecs库,用codecs.open()方法创建并打开一个名为output.txt的文件,以utf-8编码模式写入result
- with codecs.open('output.txt', 'w', encoding='utf-8') as f:
- f.write(result)
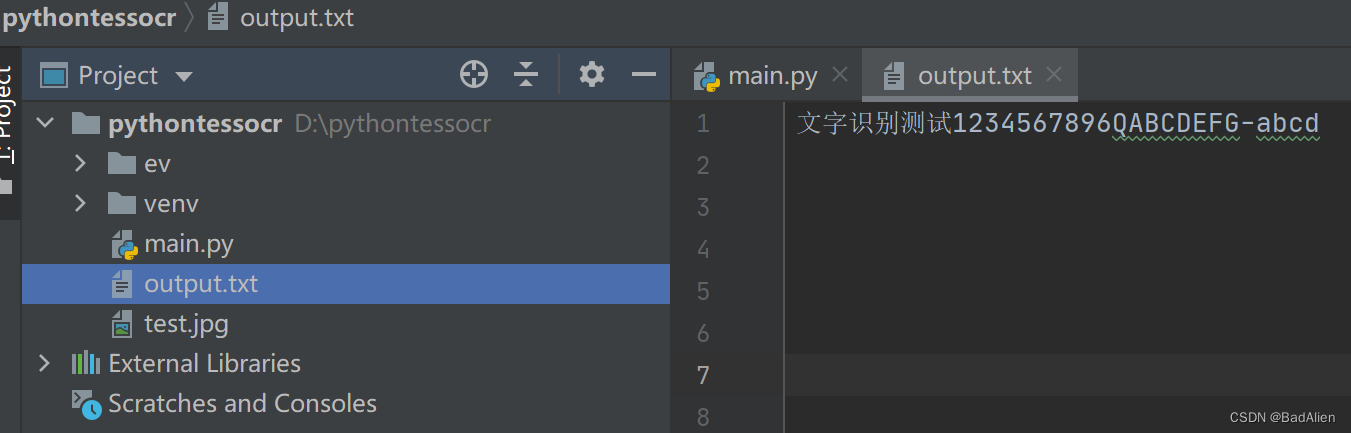
运行代码后识别结果如下图所示,与Tesseract OCR软件直接识别结果一致。

三、参考资料
3.9款文字识别(OCR)工具推荐!涵盖移动端、网页端、PC端,满足您的所有需求! - 知乎
4.基于Python的一个开源OCR工具,轻松实现批量图片转文字 - 知乎
6.基于Python的一个开源OCR工具,轻松实现批量图片转文字 - 知乎
7.Python开源文字识别,tesseract-ocr软件的安装配置“https://baijiahao.baidu.com/s?id=1729502402113148977&wfr=spider&for=pc”

