
- 12021-03-11 php 获取文件/上传文 是否是图片格式(与后缀无关,取文件实际内容)_--enable-exif
- 2如何把 Git 集成到 IntelliJ IDEA ?_已经安装好git,怎么绑定到idea上去
- 3Python笔记-Flask结合SQLAlchemy查询MySQL数据库_from flask_sqlalchemy import sqlalchemy
- 4自定义表单元素组件内容变化触发ElForm重新校验
- 5关于VScode切换、拉取、推送、合并分支,并解决冲突_vscode 切换分支
- 6Java面向对象程序设计_1. 创建一个ayyaylist,在其中加入三个职工。职工类employee属性为:姓名name,年
- 7详细讲解如何使用Java连接Kafka构建生产者和消费者(带测试样例)_java http 连接kafka
- 8AI芯片行业深度:发展现状、竞争格局、市场空间及相关公司深度梳理_人工智能芯片行业
- 9百度实习公司对考勤没有过多限制,稍微晚一点到也没有太大关系_太极股份 西安 加班
- 10【图像融合】融合算法综述(持续更新)_利用多通道的图像融合技术,实现图像的增强问题的设计方案
【PyTorch 实战3:YOLOv5检测模型】10min揭秘 YOLOv5 检测网络架构、工作原理以及pytorch代码实现(附代码实现!)
赞
踩
YOLOv5简介
YOLOv5(You Only Look Once, Version 5)是一种先进的目标检测模型,是YOLO系列的最新版本,由Ultralytics公司开发。该模型利用深度学习技术,能够在图像或视频中实时准确地检测出多个对象的位置及其类别,是计算机视觉领域的重要里程碑之一。下面将详细介绍YOLOv5的架构、性能、应用和未来发展方向。
一、与之前版本的对比
相较于YOLOv4和其他先前版本,YOLOv5在多个方面进行了改进和优化。首先,YOLOv5提供了更高的检测准确性,这得益于其新的模型架构以及对数据集和训练过程的细致调优。其次,YOLOv5在处理速度上也有所提升,这意味着它可以更快地对图像或视频进行检测和识别,使其在实时应用中更具竞争力。此外,YOLOv5还引入了一些新的特性,如自动批处理大小调整和更高效的图像处理流程,进一步提升了模型的性能和灵活性。
二、YOLOv5的架构
YOLOv5的架构基于深度卷积神经网络(CNN),采用了一种称为骨干网络(Backbone)的模块化设计。骨干网络通常由多个卷积层和池化层组成,用于从原始图像中提取特征。在YOLOv5中,采用了一种称为CSPDarknet的改进的骨干网络,它结合了Cross-Stage Partial连接(CSP)和Darknet53的优点,具有更好的特征提取能力和更快的训练速度。
除了骨干网络外,YOLOv5还包含了一系列用于检测和识别对象的头部(Head)模块。这些头部模块负责将从骨干网络中提取的特征映射转换为对象的边界框及其类别概率。YOLOv5采用了一种简单而有效的头部设计,包括多个卷积层和线性激活函数,以实现高效的对象检测。
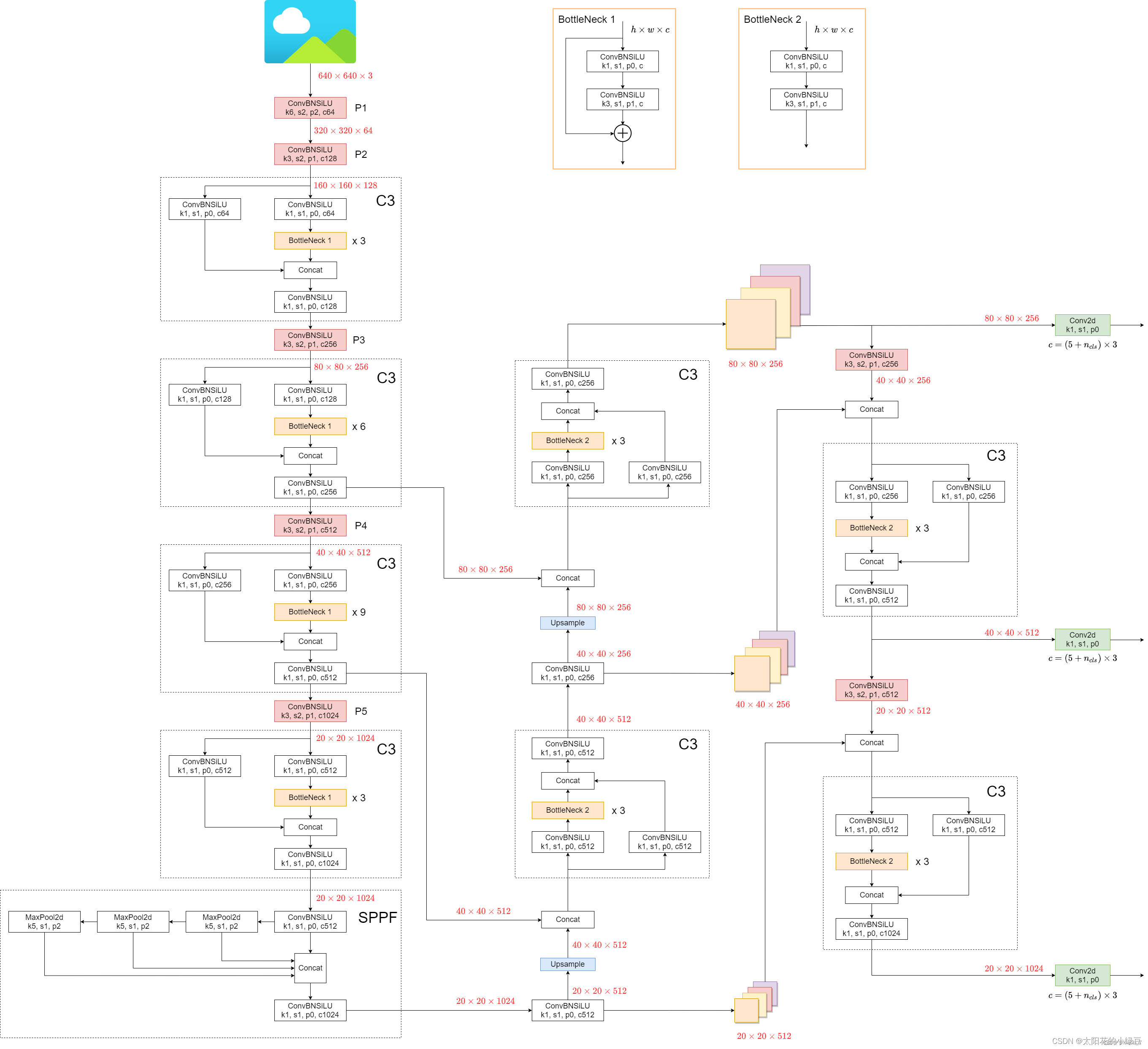
YOLOv5网络整体框架图(来自大佬的:博客)
SPPF模块
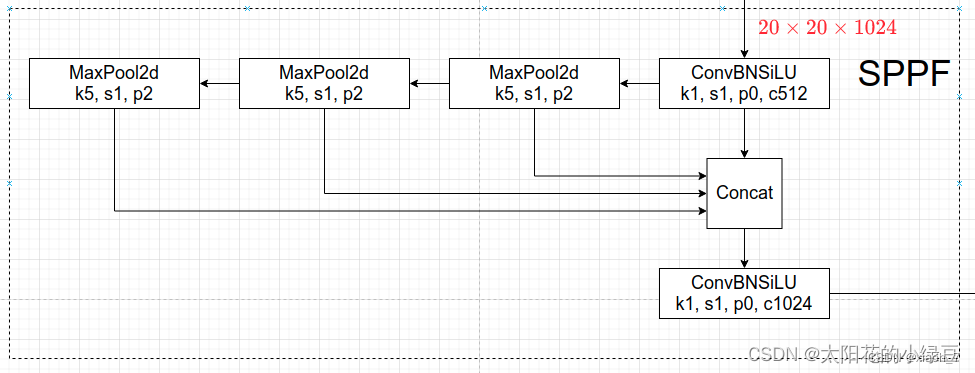
SPPF模块代码实现:
import time import torch import torch.nn as nn class SPP(nn.Module): def __init__(self): super().__init__() self.maxpool1 = nn.MaxPool2d(5, 1, padding=2) self.maxpool2 = nn.MaxPool2d(9, 1, padding=4) self.maxpool3 = nn.MaxPool2d(13, 1, padding=6) def forward(self, x): o1 = self.maxpool1(x) o2 = self.maxpool2(x) o3 = self.maxpool3(x) return torch.cat([x, o1, o2, o3], dim=1) class SPPF(nn.Module): def __init__(self): super().__init__() self.maxpool = nn.MaxPool2d(5, 1, padding=2) def forward(self, x): o1 = self.maxpool(x) o2 = self.maxpool(o1) o3 = self.maxpool(o2) return torch.cat([x, o1, o2, o3], dim=1) if __name__ == '__main__': input_tensor = torch.rand(8, 32, 16, 16) spp = SPP() sppf = SPPF() output1 = spp(input_tensor) output2 = sppf(input_tensor) print(torch.equal(output1, output2)) t_start = time.time() for _ in range(100): spp(input_tensor) print(f"spp time: {time.time() - t_start}") t_start = time.time() for _ in range(100): sppf(input_tensor) print(f"sppf time: {time.time() - t_start}")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
三、损失函数
这部分大佬的YOLOv5网络详解介绍得超级好,建议可以读读这篇博客。
四、代码实现
安装PyTorch和其他所需的Python库。具体可以看YOLOv5的仓库要求,然后按照以下步骤进行操作:
- 克隆YOLOv5仓库:
git clone https://github.com/ultralytics/yolov5.git
- 1
-
创建一个新的Python文件,比如
yolov5_custom.py。 -
编写以下代码,实现YOLOv5模型的加载和预测功能:
import torch from pathlib import Path from models.yolo import Model from utils.general import non_max_suppression, scale_coords # 定义YOLOv5模型类 class YOLOv5: def __init__(self, weights='yolov5s.pt', img_size=640): self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') self.model = Model(Path('yolov5s.yaml')).to(self.device) self.model.load_state_dict(torch.load(weights, map_location=self.device)['model']) self.model.eval() self.img_size = img_size # 预测函数 def predict(self, images): img_size = self.img_size img = images.copy() # 使用副本以防止原始图像被修改 img = torch.from_numpy(img).to(self.device) img = img.float() / 255.0 # 像素值归一化到[0,1] if img.ndimension() == 3: img = img.unsqueeze(0) # 添加batch维度 (1, H, W, C) -> (1, 1, H, W, C) img = img.permute(0, 3, 1, 2) # 调整维度顺序 (1, 1, H, W, C) -> (1, C, H, W) # 图像尺寸调整 img, _ = self.model.preprocess(img, img_size, img_size) # 预测 pred = self.model(img)[0] # 只获取第一个尺度的预测结果 pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45) # 将预测结果转换为图像上的坐标 pred[0][:, :4] = scale_coords(img.shape[2:], pred[0][:, :4], images.shape).round() return pred # 使用示例 if __name__ == "__main__": # 创建YOLOv5对象 yolov5 = YOLOv5() # 加载图像 image_path = 'example.jpg' image = torch.imread(image_path) # 进行预测 results = yolov5.predict(image) # 打印预测结果 for det in results[0]: xmin, ymin, xmax, ymax, conf, cls = det print(f"Class: {int(cls)}, Confidence: {conf:.2f}, BBox: [{xmin:.2f}, {ymin:.2f}, {xmax:.2f}, {ymax:.2f}]")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
这段代码首先定义了一个YOLOv5类,其中包含了模型的初始化和预测函数。然后,我们创建了一个YOLOv5对象,加载了预训练的权重,并使用示例图像进行了预测。最后,我们打印了预测结果,包括类别、置信度和边界框坐标。这样你就可以将示例图像替换为你自己的图像,并根据需要调整预测阈值和其他参数。
五、应用领域
虽然现在已经有很多后续的YOLO版本出现,但是YOLOv5还是最受欢迎的一个,YOLOv5的快速和准确的目标检测能力使其在各种应用领域中得到了广泛的应用。以下是一些常见的应用场景:
-
智能监控系统:YOLOv5可以用于实时监控摄像头图像或视频流,检测并识别出图中的人、车辆等对象,从而帮助监控中心及时发现异常情况。
-
自动驾驶技术:在自动驾驶车辆中,YOLOv5可以用于实时识别道路上的行人、车辆、交通标志等,帮助车辆做出及时的决策和规划。
-
工业生产:在工业生产中,YOLOv5可以用于检测和识别生产线上的产品或零部件,帮助企业提高生产效率和产品质量。
-
医学影像分析:在医学影像分析领域,YOLOv5可以用于自动识别X光片或MRI图像中的病灶或异常区域,帮助医生进行疾病诊断和治疗规划。
-
智能家居:在智能家居系统中,YOLOv5可以用于识别家庭成员的面部特征或动作姿态,实现智能门锁、智能灯光等功能。
六、未来发展
虽然YOLOv5在目标检测领域取得了显著的进展,但仍然存在一些挑战和改进空间。未来,我们可以期待以下方面的发展:
-
模型优化:继续改进和优化YOLOv5的模型架构和参数设置,以进一步提升检测准确性和速度。
-
多任务学习:探索多任务学习技术,将目标检测与其他相关任务(如语义分割、实例分割等)相结合,实现更全面的场景理解和分析。
-
跨域泛化:研究如何实现模型在不同领
域和场景中的泛化能力,使其能够适应更广泛的应用场景。 -
边缘计算:针对边缘计算场景,优化YOLOv5的模型大小和计算复杂度,以适应资源有限的边缘设备。
-
数据增强:进一步研究数据增强技术,以增加模型对不同场景和环境的适应能力,提高模型的泛化性能。

