
- 1文件中台项目目录解析(完善中)_pd-apps-1.0.0.pom
- 2力扣45.跳跃游戏Ⅱ(贪心思路详解)_跳跃游戏 贪心
- 3WebUI自动化学习(Selenium+Python+Pytest框架)002_pyhton使用pytest框架写webui自动化
- 4PhotoShop一键修改4的倍数图片工具_图片尺寸修改4倍数
- 5【完美解决】应用程序无法正常启动(0xc000007b)请单击“确定”关闭应用程序_应用程序无法正常启动 0xc000
- 6@Component,@service,@autowired等注解的实现原理_@service原理
- 7【C++ | Python 八股文(备战秋招)】—— 日积月累
- 8PD协议的个人浅显的理解
- 9java呼叫中心-java语音机器人-java电销机器人源码-javaAI语音机器人源码-语音识别-ai机器人源码,语音机器人源码,电话机器人源码,电销机器人源码,ai电销机器人,语音机器人部署_电销外呼系统 java
- 10python科学计算之Dask库详解
【自然语言处理】InstructGPT、GPT-4 概述
赞
踩
InstructGPT官方论文地址:https://arxiv.org/pdf/2203.02155.pdf
GPT-4 Technical Report:https://arxiv.org/pdf/2303.08774.pdf
GPT-4:GPT-4

目录
1 InstructGPT
在了解ChatGPT之前,我们先看看InstructGPT。

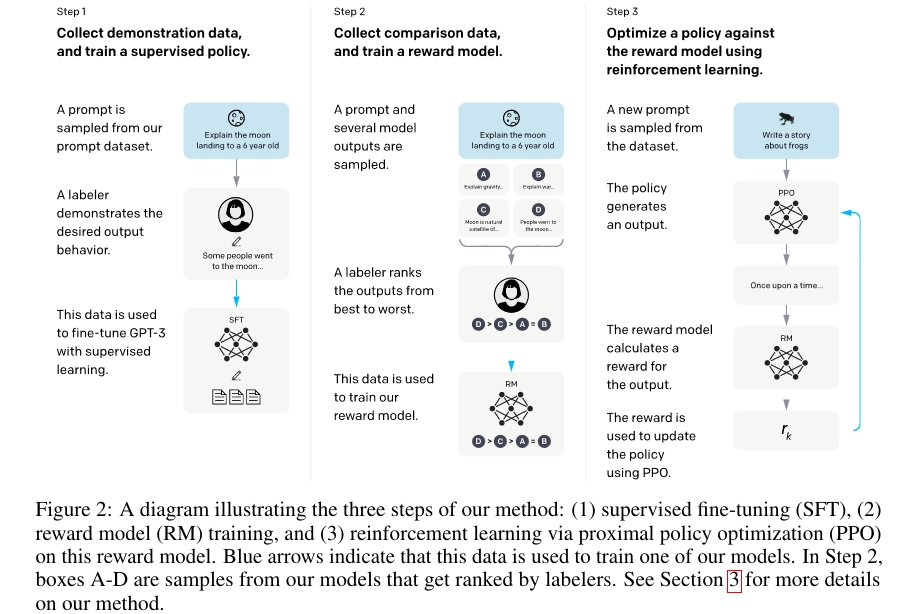
论文中的模型训练过程如下图:
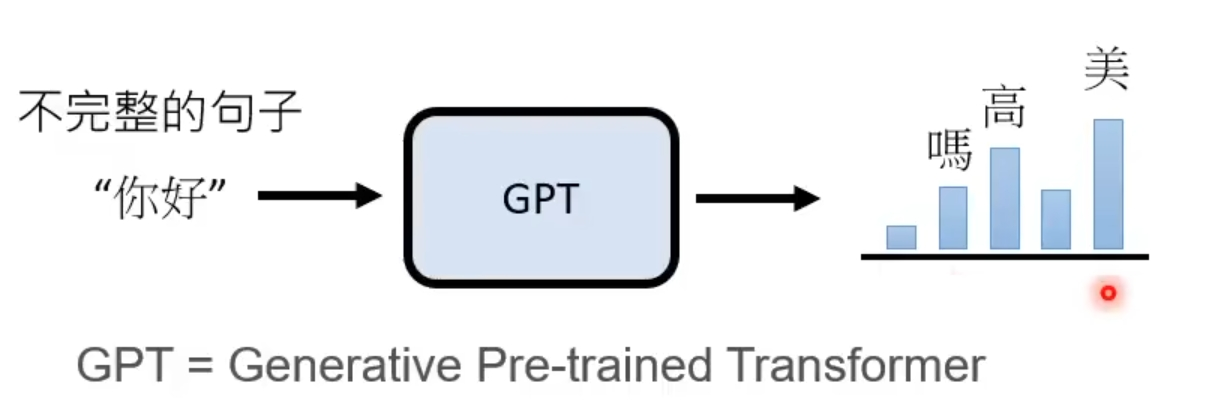
① 文字接龙
GPT (Generative Pre-trained Transformer) 模型就是在海量的文本数据上学习文字接龙,通过训练掌握基于前文内容生成后续文本的能力。这样的训练不需要人类标注数据(自监督学习),只需要给一段文字的上文同时把下文遮住,将 GPT 模型的回答与语料中下文的内容做对比,进行优化即可。
从下图中,输入“你好”让 GPT 做文字接龙,柱子的高低理解为输出概率的大小,GPT 的输出最有可能是“美”,当然也可能是“吗”或者“高”。
GPT 的输出通常是通过概率采样得到的。在生成文本时,模型根据前面的文本内容和当前的上下文,计算每个可能的输出单词的概率分布。概率越高,越有可能输出。然后,模型会根据这个概率分布对下一个单词进行采样,得到最终的输出单词。在采样的过程中,模型通常使用一种称为 “softmax” 的函数来转换概率分布,从而确保所有可能的输出单词的概率总和为1。由于采样的过程是基于随机性的,因此即使提供相同的输入和上下文,模型生成的文本输出也可能会有所不同。使用概率采样可以产生更有趣、更有意思的文本输出。这就是为什么 ChatGPT 对于相同的问题往往会有不一样的答案的原因。当然,概率采样也可能会导致一些质量较低的输出,例如语法错误、重复和不相关的单词。
② 人类参与(人类老师引导文字接龙的方向)
只是让 GPT 自己做自监督的文字接龙是有局限性的,因为机器是没有感情的,因为 GPT 不知道什么样的答案是有效的,所以需要人类的参与,引导 GPT 生成有用的我们想要的答案。首先,从问题数据集(prompt dataset)中挑出一些问题。让真正的人类(labeler)给出这些问题的正确答案。这样就形成了有标签的数据集,这些数据用于微调 GPT-3,这个过程也称作 supervised fine-tuning (SFT)。SFT,简言之,就是在GPT3的基础上进行有监督的微调得到的。
这样就有一个问题了,人类不可能给出所有问题的答案。但是,可以给 GPT 生成的答案进行评分,这就相对轻松很多。比如,我们让刚刚训练好的 SFT 模型回答相同的问题四次,这样就产生了四个不同的答案 A、B、C、D 。然后人工对这些答案进行评分或者说是评级(rank),比如 D > C > A = B 。因为判断式的标注与生成式的标注相比,更容易。所以采取这种方式标注数据。这样就又形成了一部分数据来训练 reward model(RM),就可以训练出一个符合人类评价标准的 Reward 模型。这个就类似于Teacher Model。这样之后 GPT 生成答案就不需要人工评分,直接把答案放到模型Reward 模型中去就可以自动判断答案的好坏。
如下图所示,对于相同问题的不同答案,Reward Model 学习到了在合理的答案上面打“高分”,在不合理的答案上打“低分”。

根据 Reward Model 的打分结果,继续优化 SFT 模型。使用强化学习的技术调整 GPT 模型参数,使 GPT 生成的答案通过 Reward Model 可以得到最高的 Reward,重复这个过程,InstructGPT就训练成啦。
③ RLHF
InstructGPT 是一种通过Reinforcement Learning from Human Feedback (RLHF)训练得到的语言模型, 是一种基于人类反馈的强化学习方法(PPO),它通过与人类交互来获得任务的奖励信号,从而实现任务的学习。与传统的强化学习方法相比,RLHF不需要为任务定义奖励函数,因此更具有实际应用的价值。RLHF的作用更多在于控制 ,使之输出我们期望的结果。

2 GPT-4

GPT-4 Technical Report中对于模型本身,训练的方式、如何提升模型和安全性都没有提及,没有任何技术细节。
GPT-4是一个大规模的多模态模型,可以接受图像和文本输入,并产生文本输出。虽然GPT-4在许多现实场景中的表现不如人类,但它在各种专业和学术基准上表现出了人类的水平,包括通过模拟律师考试,得分在前10%左右。GPT-4是一个基于transformer的预训练模型,用于预测文档中的下一个令牌。
可以用千分之一的计算量去预测 GPT-4 在一定计算规模下的性能,不用花时间训练大模型去探索,即 Predictable Scaling。
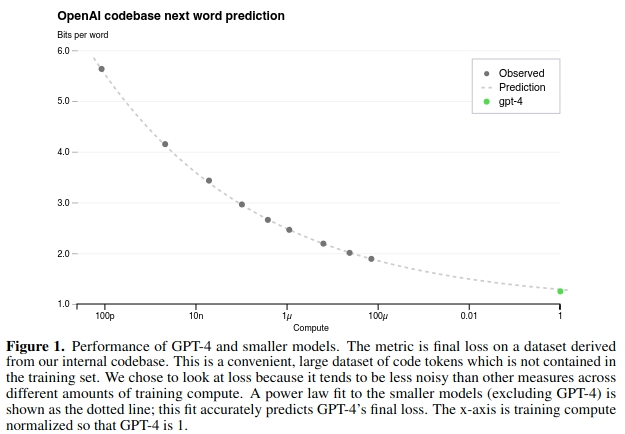
GPT-4的训练稳定性是史无前例的,这得益于对抗性测试计划和来自于ChatGPT的经验教训,对 GPT-4 进行迭代调整,从而在真实性、可控性等方面取得了有史以来最好的结果。在过去的两年里,OpenAI重建了整个深度学习栈,并与Azure共同设计了一台超级计算机以便于应付他们的工作负载。 将继续专注于可靠的扩展,进一步完善方法,以帮助其实现更强大的提前预测性能和规划未来的能力,这对安全至关重要。OpenAI还开源了OpenAI Evals,这是他们的自动化评估AI模型性能的框架,任何人都可以提交他们模型的缺陷以帮助改进。OpenAI 正在通过 ChatGPT 和 API(有候补名单)发布 GPT-4 的文本输入功能。图像输入功能方面,为了获得更广泛的可用性,OpenAI 正在与其他公司展开合作。OpenAI 还在为机器学习模型设计的传统基准上评估了 GPT-4。GPT-4 大大优于现有的大型语言模型,以及大多数 SOTA 模型。



说明:本文资料大部分来源于网络,仅作为学习用途,如有侵权,请联系作者删除。
参考资料:
【油管爆火】李宏毅大佬讲解Chat GPT是怎样练成的!_哔哩哔哩_bilibili
InstructGPT 论文精读【论文精读·48】_哔哩哔哩_bilibili
GPT-4论文精读【论文精读·53】_哔哩哔哩_bilibili

