
- 1多省发布暴雨预警 城市需做好道路积水智能监测预警措施
- 2用Java将数组中的元素向右移动_给定一个数组,将数组中的元素向右
- 3Windows Server 2012 R2 WSUS-14:powershell管理WSUS
- 4使用GridView的auto_fit遇到的坑_autofit 未铺满
- 5考研经验分享
- 6neo4j community用neo4j.bat命令启动时遇到的困难_neo4j.bat文件启动服务器
- 7python3-python中的GUI,Tkinter的使用,抓取小米应用商店应用列表名称_python 获取安卓app界面名称
- 8Android ——JNI基本了解与使用_android jni调用
- 9演讲与口才_军职在线演讲与口才
- 10降压模块LM2596S的操作使用_lm2596 输出电压自动调整
【大数据】下载hadoop与jdk_hadoop下载
赞
踩
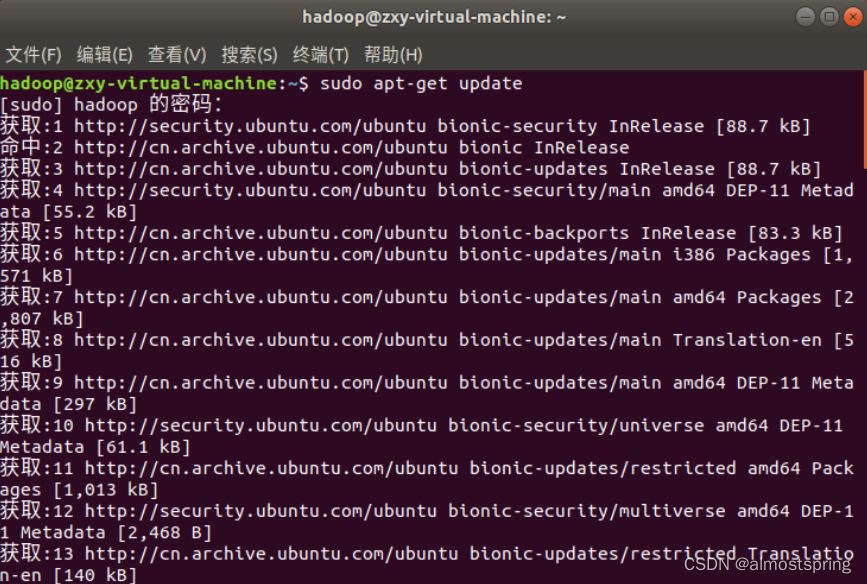
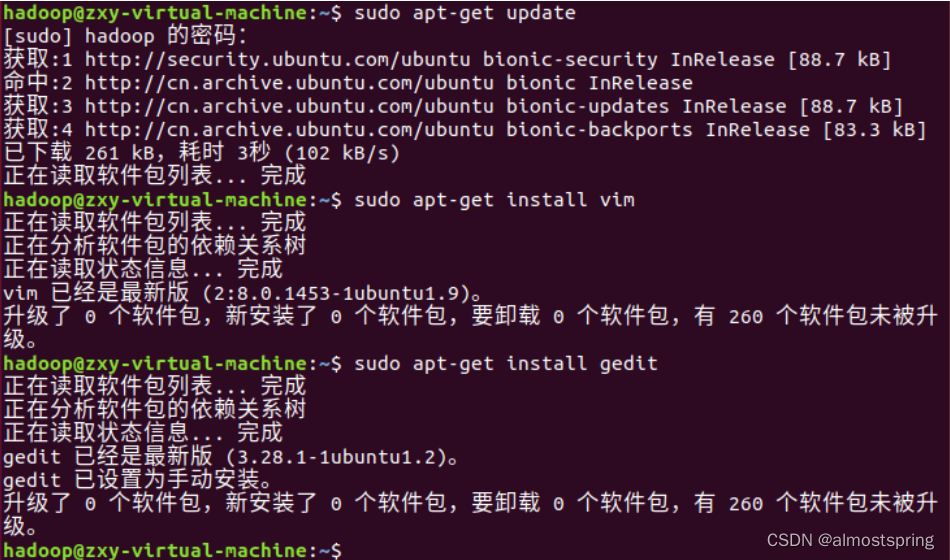
第一步,ctrl+alt+t 打开终端窗口,执行如下命令:
$ sudo apt-get update
- 1
第二步 安装SSH、配置SSH无密码登陆
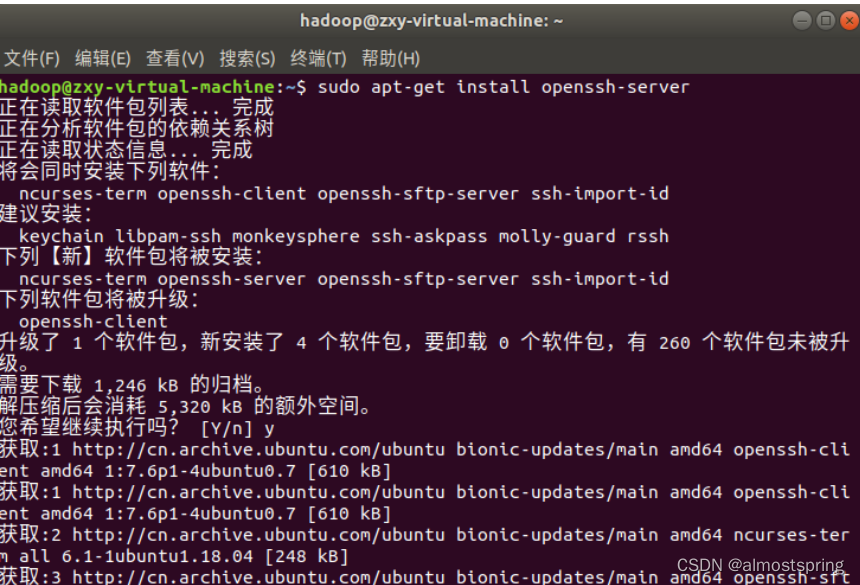
1)集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
$ sudo apt-get install openssh-server
- 1
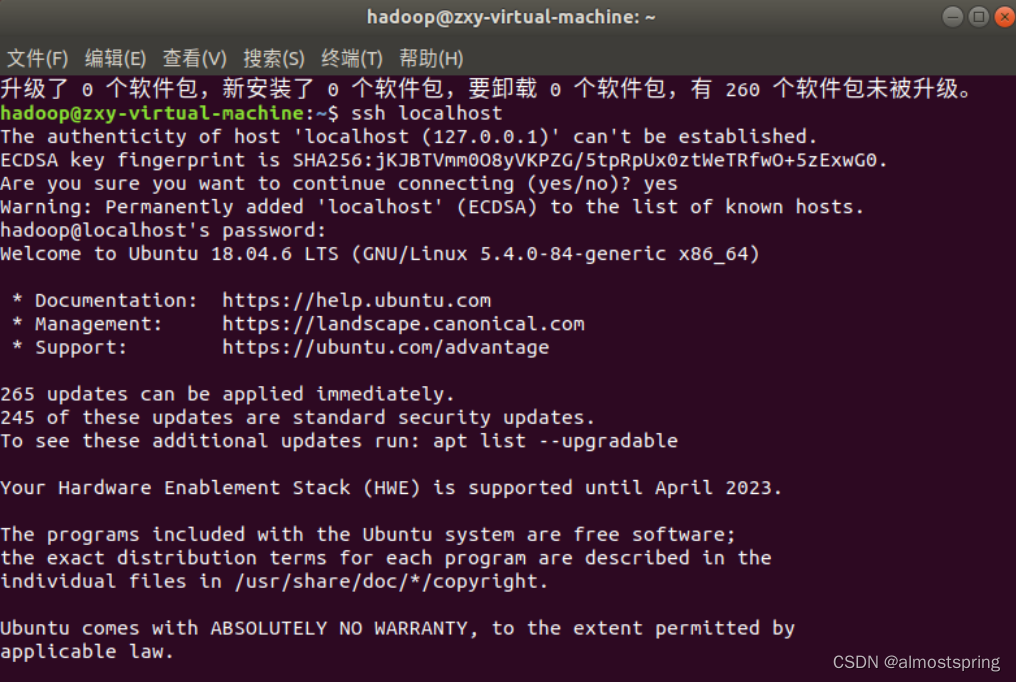
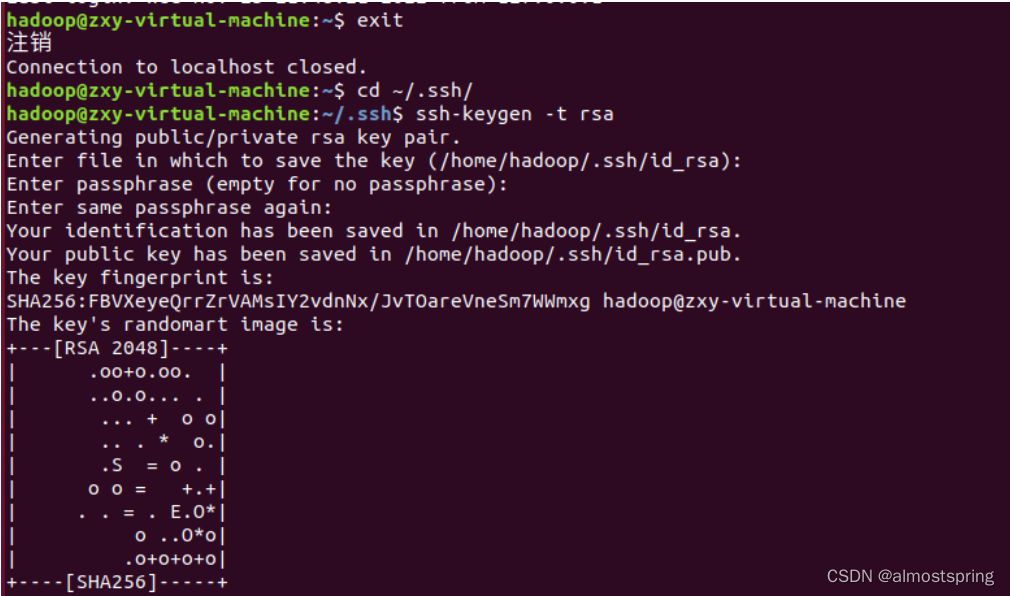
2)安装后,可以使用如下命令登陆本机:
$ssh localhost
- 1
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码,这样就登陆到本机了。
配置成SSH无密码登陆
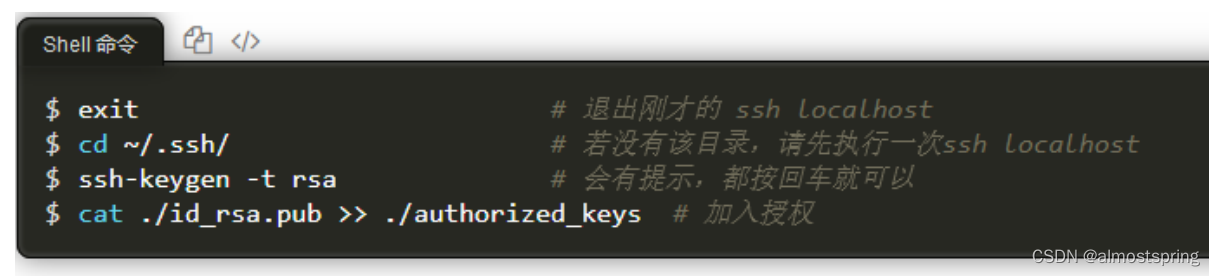
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
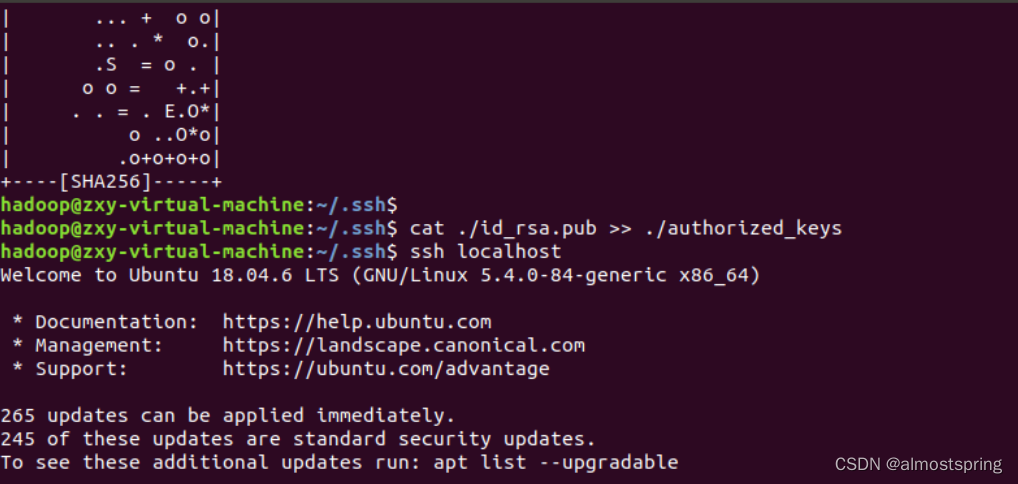
第三步 安装java
Hadoop3 需要JDK版本在1.8及以上。安装openjdk也可以。

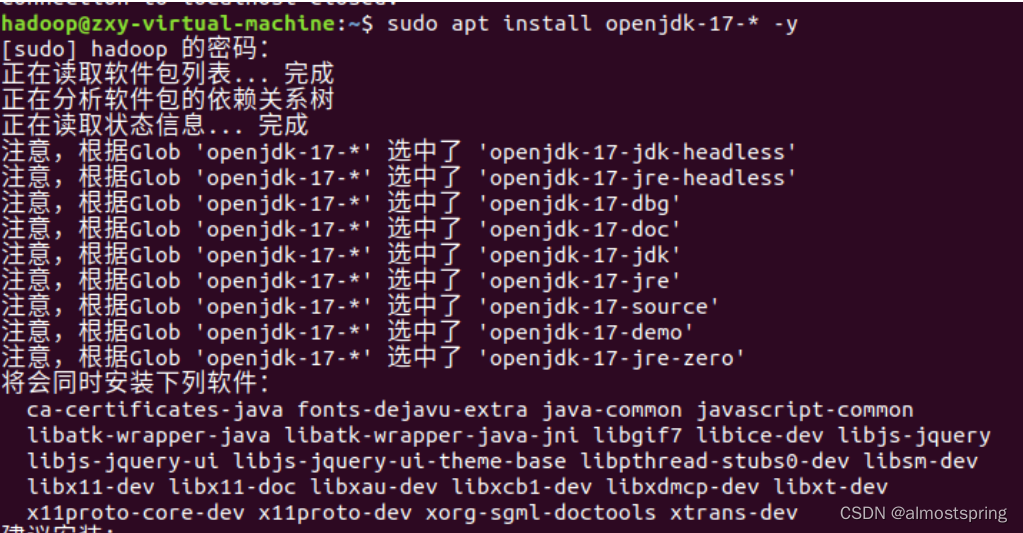
安装完成测试一下(出现问题)
安装JDK
由于hadoop底层是用java写的,所以安装hadoop前需要先安装JDK
安装之前有个小问题,就是之前我们安装软件,直接是apt-get install xxx
为什么JDK的安装不能这样呢?因为安装JDK之前hadoop需要寻找环境变量:JAVA_HOME,里面有很多的配置文件、可执行文件等等。如果使用apt-get install xxx这种方式安装的话,会把配置文件打散,可执行文件在/bin 目录,配置文件在/etc目录,这样的话hadoop找不到对应的文件,就无法运行。

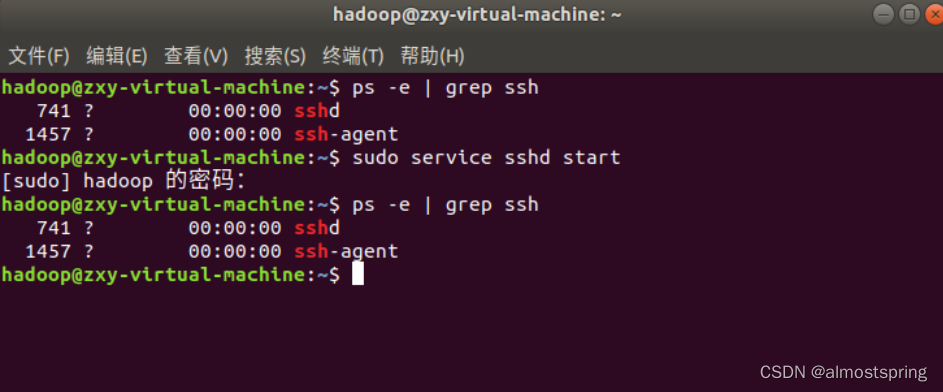
查看ssh是否启动,出现sshd即为启动成功.
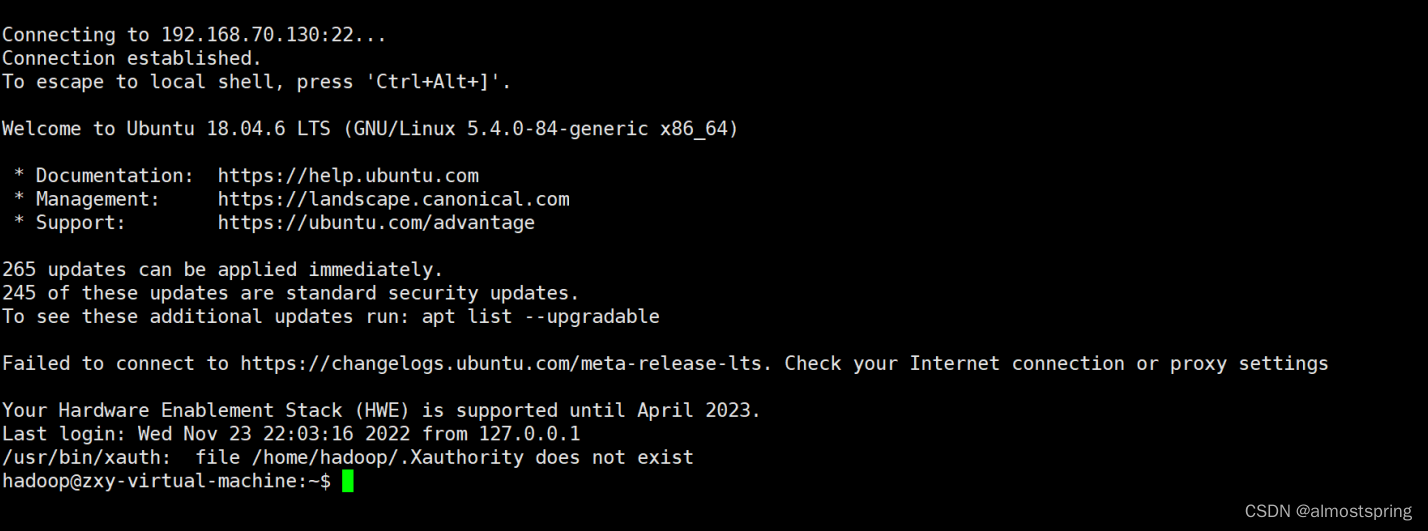
此时再次点击xhell连接虚拟机即可连接成功。连接成功后 shell页面与虚拟机终端页面格式一致。
使用了Xftp传输文件,直接拖拽就好。这里将jdk文件传输。
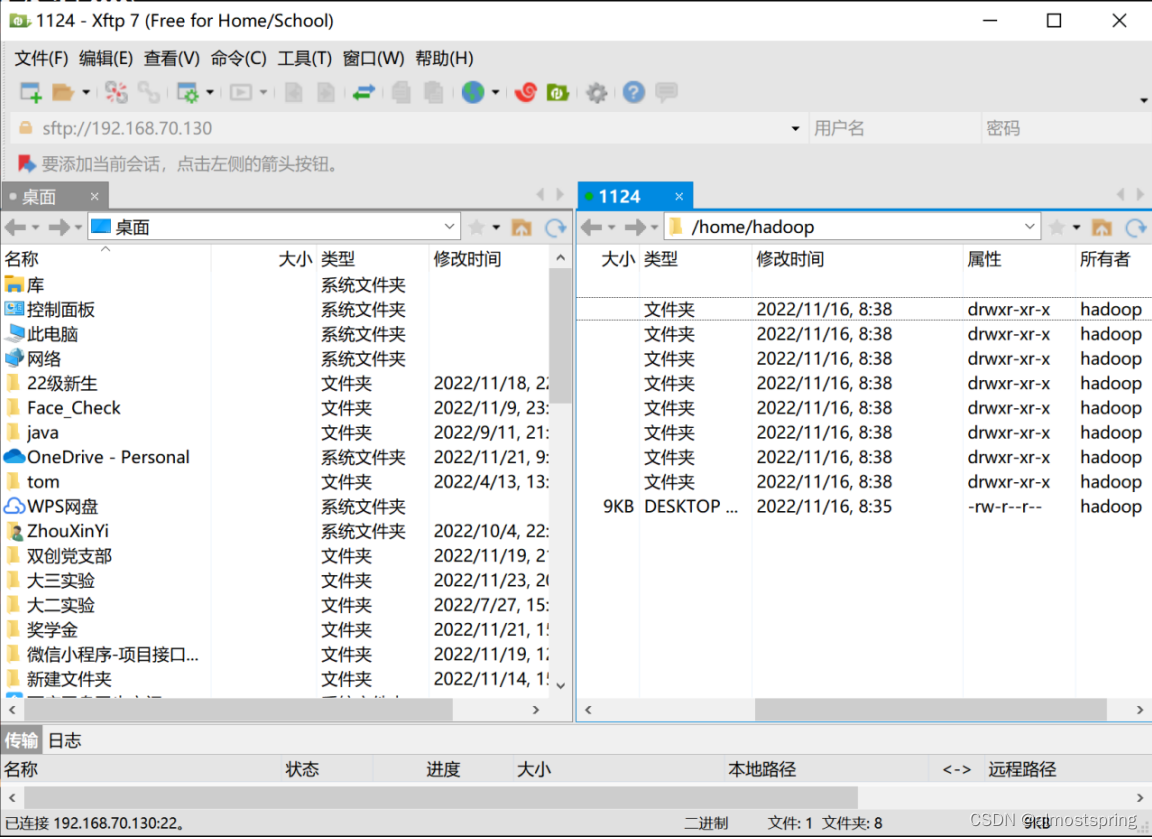
传输后可以直接在虚拟机中看到,将文件移动到到下载里面。(为了好利用指令处理)直接选中拖拽即可。打开终端执行以下指令。
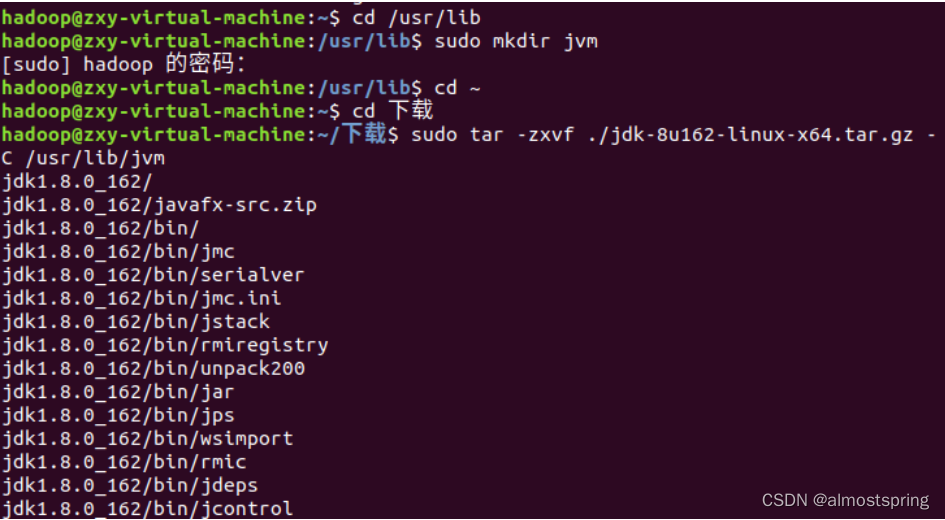
执行指令查看文件夹是否存在。文件夹存在。

接下来配置环境变量。
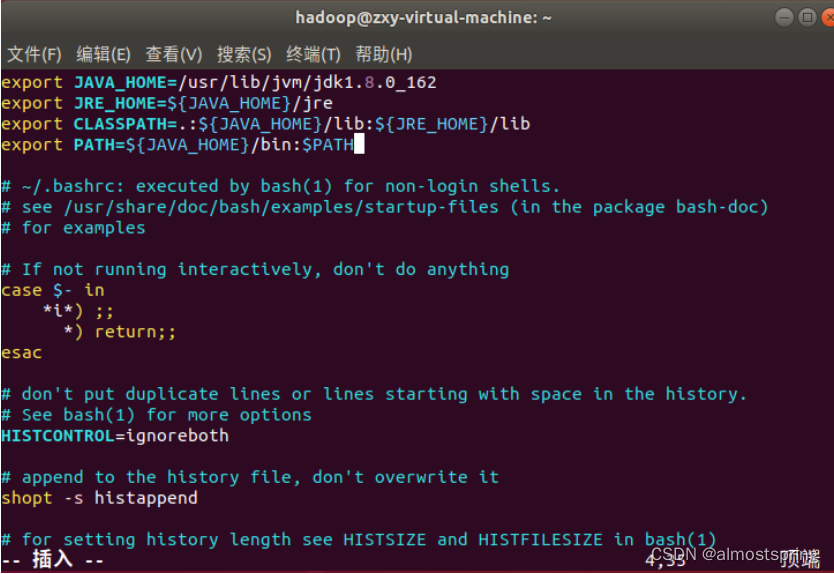
添加成功后输入source ~/.bashrc指令让修改生效。
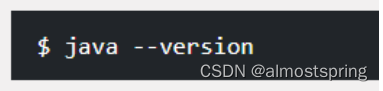
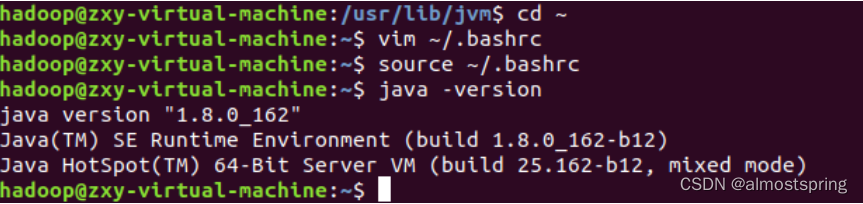
输入java -version指令查看jdk是否安装成功,也是查看jdk版本号的代码。
出现一下信息说明jdk安装成功。
安装 Hadoop3.1.3
之前已经将安装包放在下载里了,所以直接解压就可以。
$sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local
$cd /usr/local/
$sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
$sudo chown -R hadoop ./hadoop # 修改文件权限
- 1
- 2
- 3
- 4
hadoop解压后直接就可以使用。
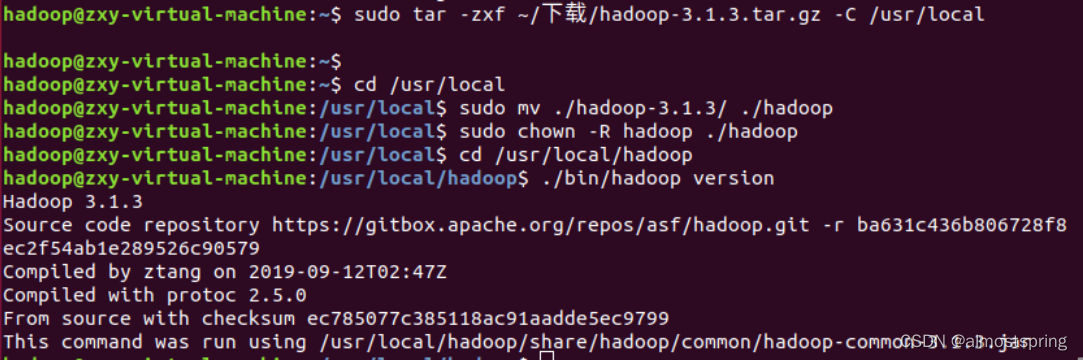
检查是否成功解压也是查看hadoop版本号的指令。
$cd /usr/local/hadoop
$./bin/hadoop version
- 1
- 2
出现以下信息即为成功。
Hadoop伪分布式配置
修改core-site.xml文件
$gedit ./etc/hadoop/core-site.xml
- 1
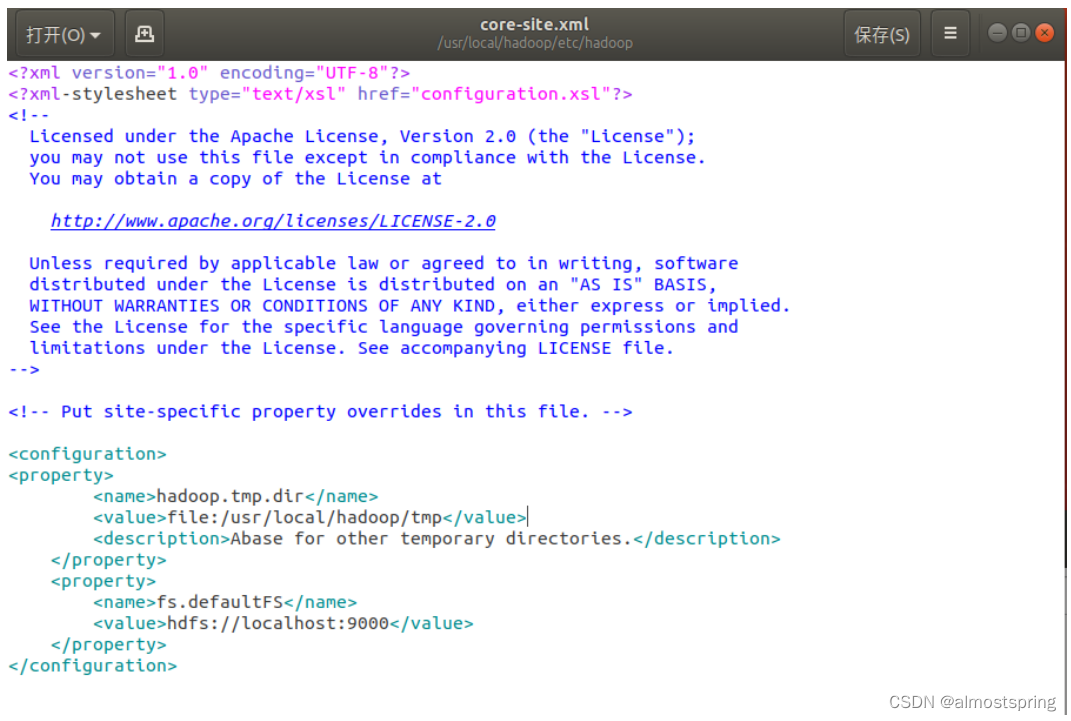
在<configuration> </configuration>中间添加代码
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
添加前:
添加后:
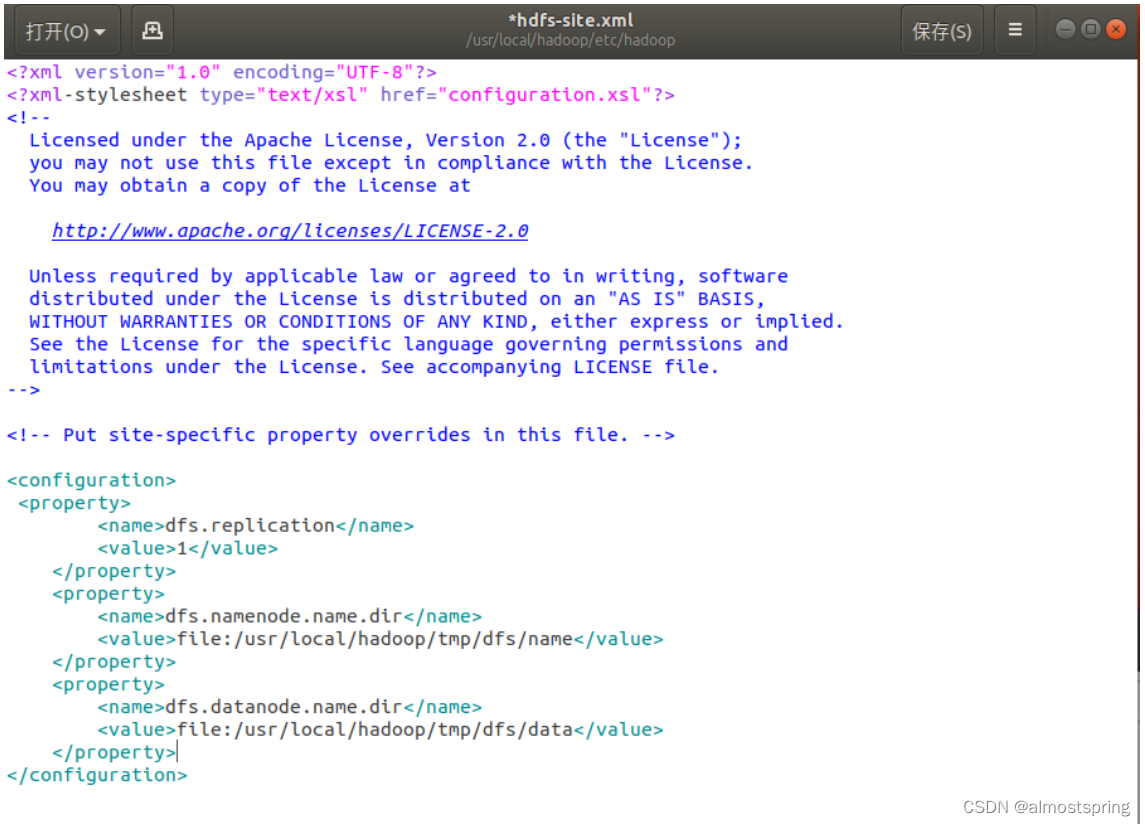
直接Ctrl+S保存。关闭后修改文件文件 hdfs-site.xml
$gedit ./etc/hadoop/hdfs-site.xml
- 1
同理,在<configuration> </configuration>中间添加代码
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
添加后:
配置完成后,执行 NameNode 的格式化
$cd /usr/local/hadoop./bin/hdfs namenode -format
- 1
下面是反馈信息的前部分和后部分:
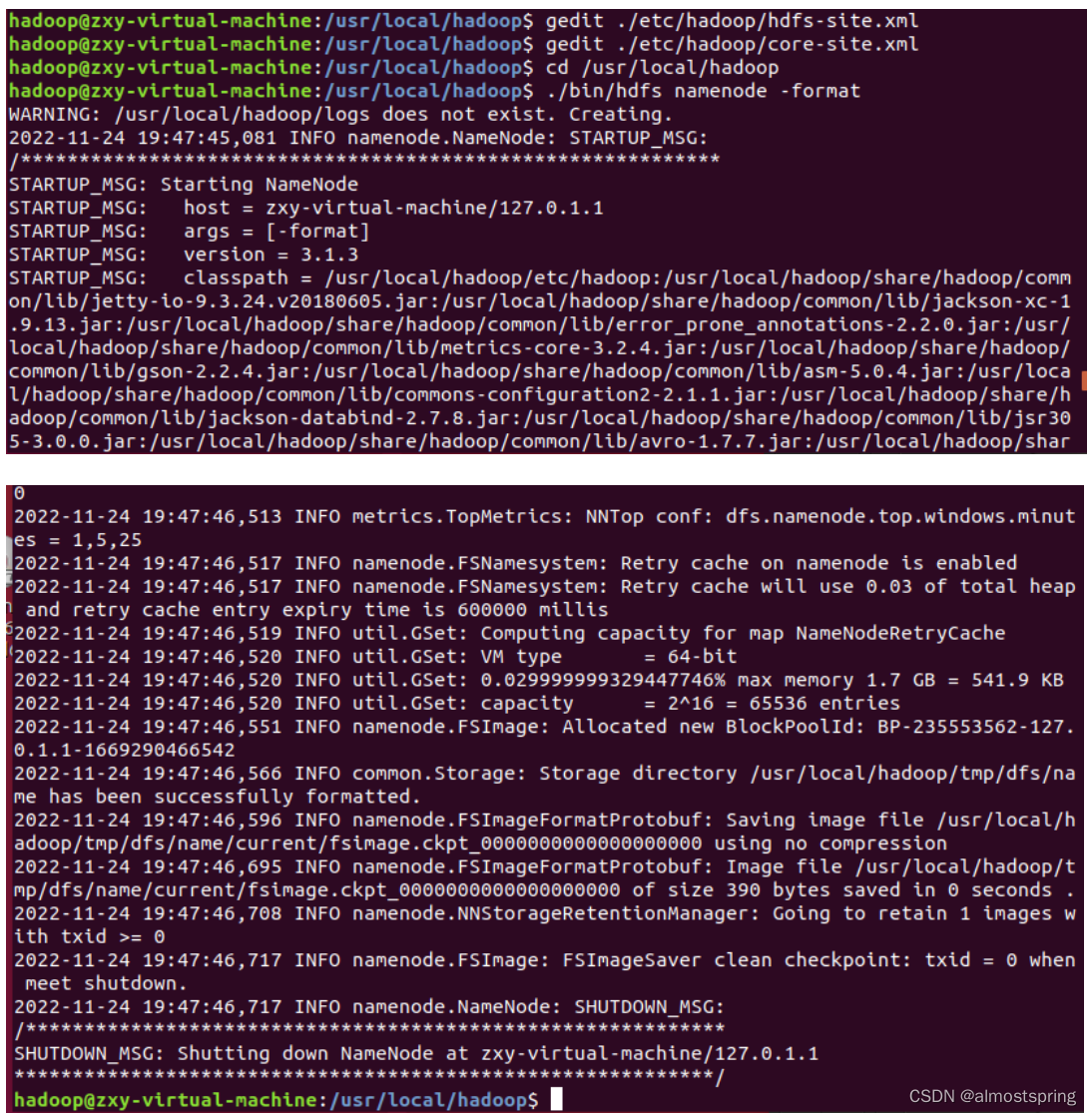
尝试启动hadoop,开启 NameNode 和 DataNode 进程。

输入jps查看进程。下图出现4个进程说明配置成功。

即伪分布式配置成功。
尝试运行实例
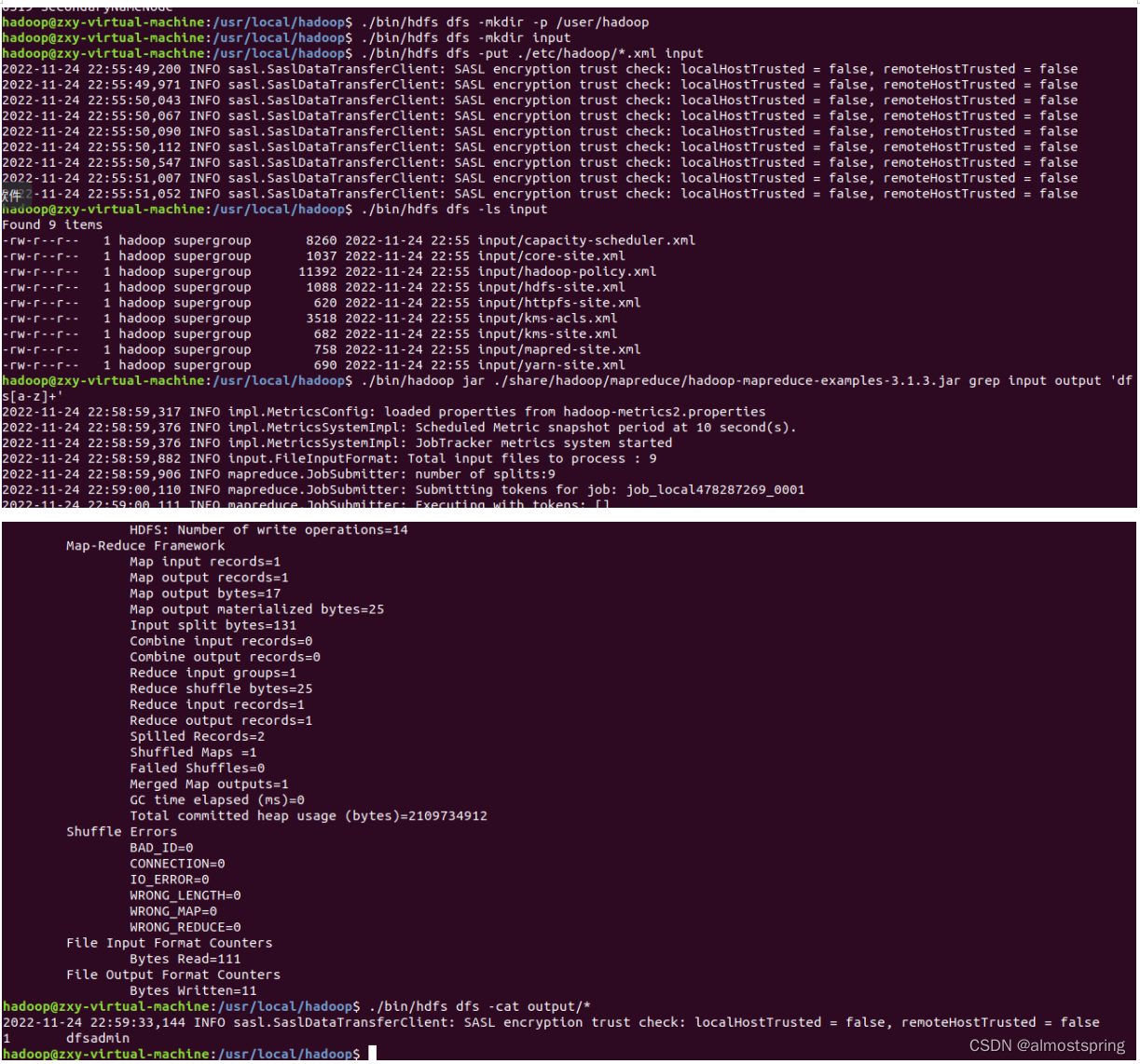
首先在 HDFS 中创建用户目录。
将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统。
复制完成后,可以通过./bin/hdfs dfs -ls input命令查看文件列表
伪分布式运行 MapReduce 作业的方式跟单机模式相同
查看运行结果。
实验心得:
由于是第一次接触hadoop,安装配置过程中都碰到了不少问题,在安装hadoop前,要先准备集群化环境,我准备了三个centos服务器作为节点(分别为node1,node2,node3),并配置他们相互之间的SSH免密登陆,然后开始安装Hadoop,在node1上通过wget命令安装hadoop,由于是外网,安装速度非常慢,于是我上网查询了国内hadoop镜像,然后将安装包下载下来放到node1中解压,然后修改了部分配置文件,最后,在node1中运行start-yarn.sh启动yarn集群,基本就完成了。这个时候就可以在浏览器中访问hadoop了。这个实验让我对linux命令更加熟悉,同时也了解到了hadoop的强大。

