
热门标签
热门文章
- 1多省发布暴雨预警 城市需做好道路积水智能监测预警措施
- 2用Java将数组中的元素向右移动_给定一个数组,将数组中的元素向右
- 3Windows Server 2012 R2 WSUS-14:powershell管理WSUS
- 4使用GridView的auto_fit遇到的坑_autofit 未铺满
- 5考研经验分享
- 6neo4j community用neo4j.bat命令启动时遇到的困难_neo4j.bat文件启动服务器
- 7python3-python中的GUI,Tkinter的使用,抓取小米应用商店应用列表名称_python 获取安卓app界面名称
- 8Android ——JNI基本了解与使用_android jni调用
- 9演讲与口才_军职在线演讲与口才
- 10降压模块LM2596S的操作使用_lm2596 输出电压自动调整
当前位置: article > 正文
LLM - 大语言模型的指令微调(Instruction Tuning) 概述_llm instruction
作者:我家小花儿 | 2024-05-15 09:31:03
赞
踩
llm instruction
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/137009993
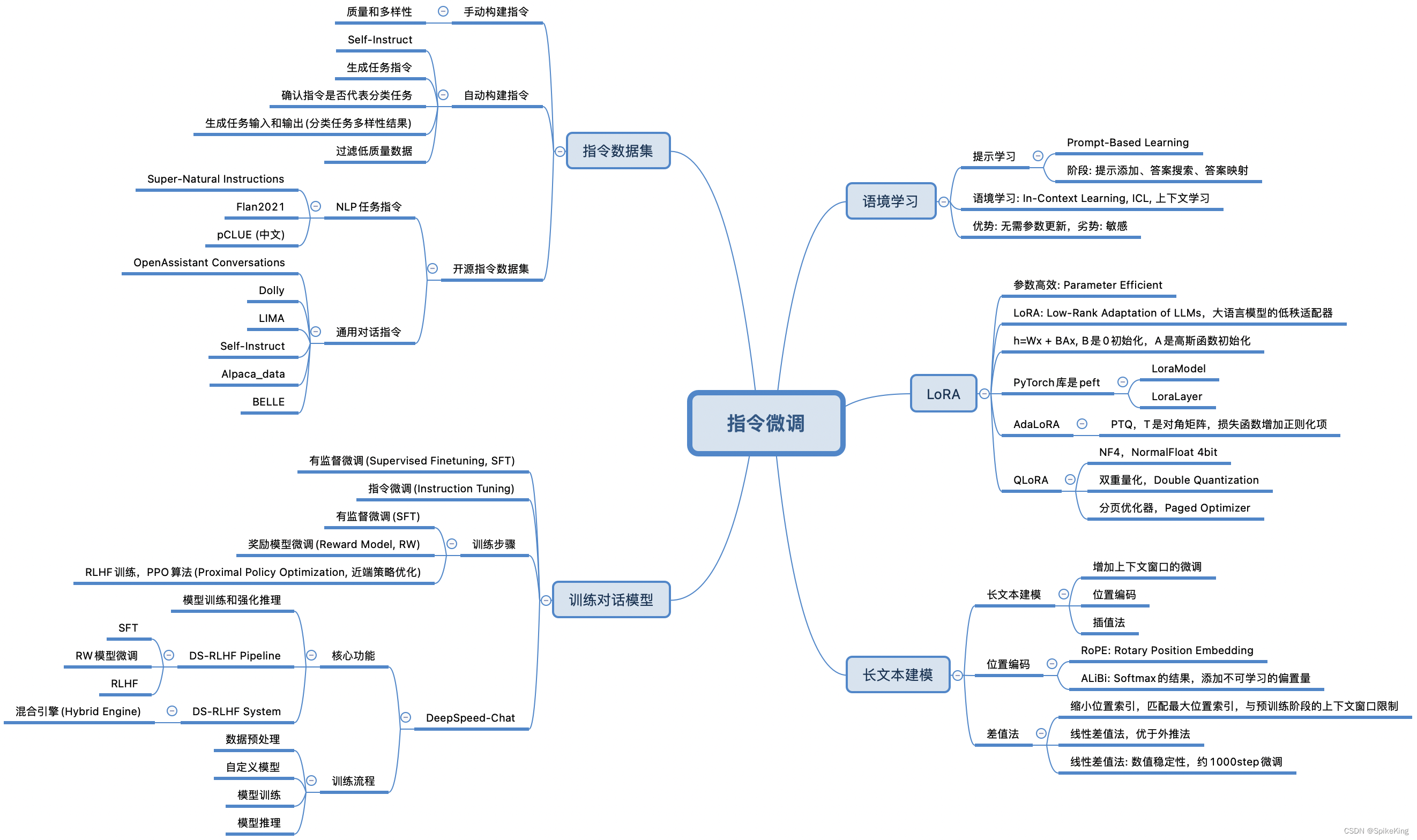
大语言模型的指令微调(Instruction Tuning)是一种优化技术,通过在特定的数据集上进一步训练大型语言模型(LLMs),使其能够更好地理解和遵循人类的指令。这个数据集通常由一系列的指令和相应的期望输出组成。指令微调的目的是提高模型的能力和可控性,使其在执行任务时能够更准确地响应用户的需求。
指令微调通常包含:
- 构建指令格式数据:这些实例包含任务描述、一对输入输出以及示例(可选)。
- 有监督微调(Supervised Finetuning, SFT):在这些指令格式的实例上对大型语言模型进行微调。
- 提高推理能力:通过指令微调,模型能够更好地利用其知识库,回答问题或完成任务。
- 泛化到未见过的任务:经过指令微调的模型能够在新任务上表现得更好,即使这些任务在微调过程中没有被直接训练过。
指令微调的效果是使得大型语言模型在理解复杂问题和执行多样化任务时更加精准和高效。
1. 语境学习
在大型语言模型中,**提示学
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/572180
推荐阅读

相关标签

