
- 1音频录制(react)_recorder-core是否支持react
- 2银河麒麟操作系统添加新硬盘后流程_银河麒麟格式化硬盘
- 3前端和后端是如何交互的_前端和后端交互的方法
- 42023 安装 facebookresearch slowfast 自定义数据集训练 yolo数据集转ava数据集_slowfast数据集
- 5Android工具类整合_jsondp
- 6hive窗口函数rank()/dense_rank()/row_number()的区别
- 7PMBOK知识点整理【第四章项目整合管理】(49个子过程、输入、工具和技术、输出)_整合管理的七个过程
- 8RabbitMQ:Docker Compose部署RabbitMQ_docker compose rabbitmq
- 9linux(ubuntu) 系统修改/etc/fstab文件后无法进入系统的解决方法_ubuntu更改了fstab无法进入系统了
- 10python慕课版课后题答案,python123和中国大学慕课
【论文必用】Python绘制混淆矩阵_混淆矩阵图python
赞
踩
一、混淆矩阵介绍
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目。
以下图为例,第一行的数值总和为2+0+0=2,表示ant类别共有2个样本,其中,有2个样本被预测为ant类别,0个样本被预测为bird类别,0个样本被预测为cat类别,即ant类别的图像全预测正确了。其他行同理。
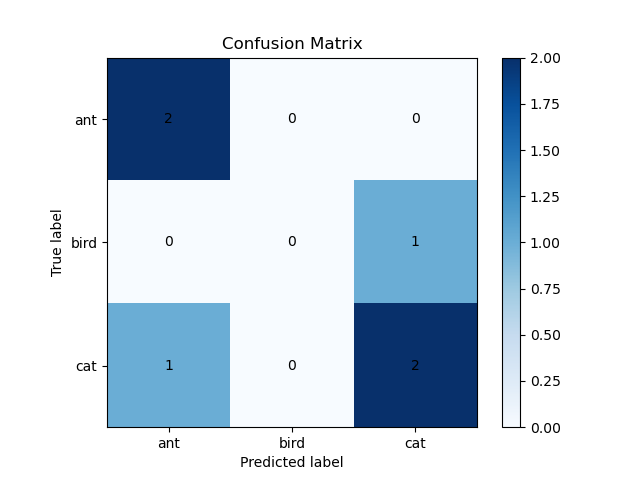
上面这个混淆矩阵并没有归一化,对其进行归一化后的结果如下。以第三行为例进行解释:0.33表示有33%的cat图像被预测为了ant,0%的cat图像被预测为bird,也即没有cat图像被预测为bird,67%的cat图像被预测为cat。
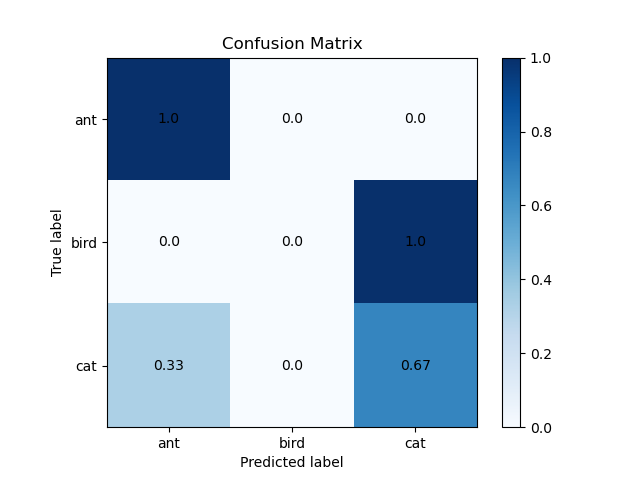
上面说这么多,主要是想让大家直观地理解混淆矩阵到底是怎么一回事。总是,混淆矩阵可以让我们清晰地看到网络的错分情况。
二、绘制混淆矩阵
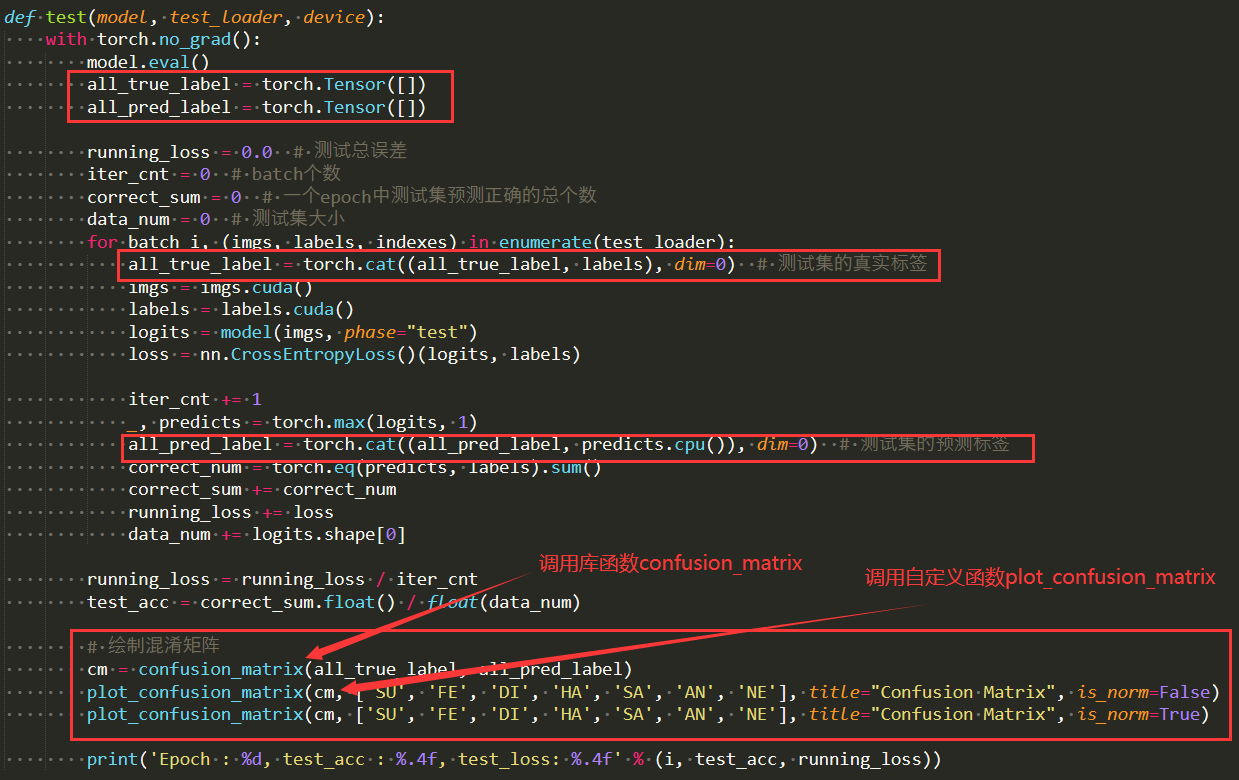
在下面这个代码中,主要用到的两个函数分别是:库函数confusion_matrix 和 自定义函数plot_confusion_matrix。其中,库函数只需要安装【scikit】包,具体安装命令如下。

自定义函数plot_confusion_matrix大家直接粘贴下面的代码就行。
实际应用时,大家只需要 改一下 下述代码中的 真实标签y_true 和 预测标签y_pred ,及 标签名称label_name 即可。需要注意的是 label_name的顺序是按0,1,2的顺序排的 ,即因为ant的数字标签为0,因此它在第一位,bird的数字标签为1,因此它在第二位,cat的数字标签为2,因此它在第三位。以此类推。
import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import confusion_matrix # 绘制混淆矩阵的函数 def plot_confusion_matrix(cm, labels_name, title="Confusion Matrix", is_norm=True, colorbar=True, cmap=plt.cm.Blues): if is_norm==True: cm = np.around(cm.astype('float') / cm.sum(axis=1)[:, np.newaxis],2) # 横轴归一化并保留2位小数 plt.imshow(cm, interpolation='nearest', cmap=cmap) # 在特定的窗口上显示图像 for i in range(len(cm)): for j in range(len(cm)): plt.annotate(cm[j, i], xy=(i, j), horizontalalignment='center', verticalalignment='center') # 默认所有值均为黑色 # plt.annotate(cm[j, i], xy=(i, j), horizontalalignment='center', color="white" if i==j else "black", verticalalignment='center') # 将对角线值设为白色 if colorbar: plt.colorbar() # 创建颜色条 num_local = np.array(range(len(labels_name))) plt.xticks(num_local, labels_name) # 将标签印在x轴坐标上 plt.yticks(num_local, labels_name) # 将标签印在y轴坐标上 plt.title(title) # 图像标题 plt.ylabel('True label') plt.xlabel('Predicted label') if is_norm==True: plt.savefig(r'.\cm_norm_' + '.png', format='png') else: plt.savefig(r'.\cm_' + '.png', format='png') plt.show() # plt.show()在plt.savefig()之后 plt.close() y_true = [2, 0, 2, 2, 0, 1] # 真实标签 y_pred = [0, 0, 2, 2, 0, 2] # 预测标签 label_name = ['ant', 'bird', 'cat'] cm = confusion_matrix(y_true, y_pred) # 调用库函数confusion_matrix plot_confusion_matrix(cm, label_name, "Confusion Matrix", is_norm=False) # 调用上面编写的自定义函数 plot_confusion_matrix(cm, label_name, "Confusion Matrix", is_norm=True) # 经过归一化的混淆矩阵

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
三、在深度学习代码中添加绘制混淆矩阵模块
在上述代码中,真实标签和预测标签都给定好了,那么如何在深度学习中根据图像真实标签和预测标签,从而对每个Epoch的错分情况进行绘制呢?具体做法如下,只需要在模型主函数的测试模块中,加入下述几行代码,即可。(注:笔者是做表情识别方向的,因此类别数总共有7种。)
至此,本博文就结束了。如果本文对你有所帮助的话,欢迎订阅本专栏。永远相信美好的事情即将发生。


