- 1嵌入式开发是不是越来越内卷了_嵌入式内卷
- 2C++CURL库的一个bug,CURLOPT_TIMEOUT_MS设置时间小于1s直接报错_c++容易curl崩溃
- 3解决stata安装外部命令报错cannot write in directory C:\Users\�ƿ���\ado\plus\_
- 4【一文看懂】python高级函数之 map_python map
- 5FFmpeg 硬件加速视频转码指南_ffmpeg cpu满载
- 6缺陷调研报告_实例!软件缺陷数据度量和分析
- 7Redis:Nosql数据库_redis 属于no sql
- 8流量显示服务器异常,怀疑服务器存在异常流量排查日记,使用ifconfig,nethogs等命令...
- 9uniapp 实现生成海报并分享给微信好友和保存到本地相册_uniapp生成海报分享到朋友圈
- 102021年终碎碎念
yolov5单目测距+速度测量+目标跟踪+YOLOv8界面-目标检测+语义分割+追踪+姿态识别(姿态估计)+界面DeepSort/ByteTrack-PyQt-GUI_yolo测速
赞
踩

YOLOv5是目前最先进的目标检测算法之一,在多个数据集上取得了优秀的表现。相较于YOLOv4,YOLOv5采用了更深的Backbone网络和更高的分辨率输入图像,以提高检测精度和速度。
1.单目测距实现方法
在目标检测的基础上,我们可以通过计算物体在图像中的像素大小来估计其距离。具体方法是,首先确定某个物体的实际尺寸,然后根据该物体在图像中的像素大小计算其距离。这个方法可以应用于各种不同的场景和物体,如车辆、行人等。
2.速度测量实现方法
通过目标跟踪,我们可以获取连续帧之间物体的位置信息,并计算出物体的速度。在实际应用中,我们可以使用多种方法来实现目标跟踪,如光流法、卡尔曼滤波等。
3.目标跟踪实现方法
目标跟踪是指在连续帧之间跟踪同一物体的过程。在YOLOv5模型中,可以利用预测框的位置信息和置信度来进行目标跟踪。具体方法是,首先在第一帧图像中检测出物体,并为每个物体分配一个唯一的ID。然后,在后续的帧中,根据预测框的位置和置信度信息以及上一帧的物体ID,来确定当前帧中物体的唯一ID。
4.实验结果与分析
通过实验,我们可以发现,使用YOLOv5模型进行目标检测和跟踪,在保证较高检测精度和实时性的前提下,能够实现单目测距和速度测量等应用。此外,不同的跟踪算法和参数设置对于跟踪效果有一定的影响,需要针对具体场景进行优化。
总之,本文针对YOLOv5单目测距、速度测量和目标跟踪这一问题,介绍了基本思路和实现方法,并进行了实验验证。这些技术可以应用于各种实际场景中,如交通监控、智能安防等。未来,我们可以进一步探索更加高效和准确的目标检测和跟踪算法,以实现更加智能化的应用。
要在YOLOv5中添加测距和测速功能,您需要了解以下两个部分的原理:
单目测距算法
单目测距是使用单个摄像头来估计场景中物体的距离。常见的单目测距算法包括基于视差的方法(如立体匹配)和基于深度学习的方法(如神经网络)。
基于深度学习的方法通常使用卷积神经网络(CNN)来学习从图像到深度图的映射关系。
传送门+代码链接:
yolov5单目测距+速度测量+目标跟踪(算法介绍和代码)_yolo实现测距-CSDN博客
YOLOv8界面-目标检测+语义分割+追踪+姿态识别(姿态估计)+界面DeepSort/ByteTrack-PyQt-GUI
YOLOv8界面集成了目标检测、语义分割、追踪以及姿态识别等多种前沿技术,同时采用了DeepSort/ByteTrack算法和PyQt-GUI界面设计,为用户提供了强大而便捷的视觉分析工具。通过YOLOv8算法,用户可以实现高效准确的目标检测,快速识别图像或视频中的各种物体。
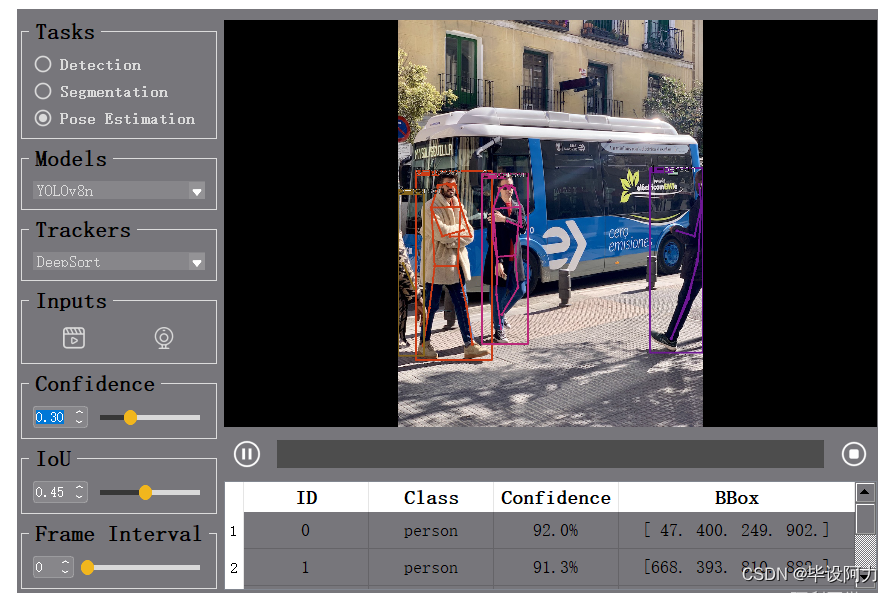
在语义分割方面,YOLOv8界面能够对图像进行精细的像素级别分割,帮助用户更好地理解图像内容,为后续分析提供更准确的数据支持。同时,界面还支持目标追踪功能,能够实时跟踪目标的运动轨迹,为用户提供全面的物体行为信息。
此外,YOLOv8界面的姿态识别功能也十分强大,可以准确识别人体姿势,为用户提供更深入的人体动作分析。结合了DeepSort/ByteTrack算法的界面设计使得操作更加直观简单,用户可以轻松地进行各项视觉分析任务。
总的来说,YOLOv8界面是一款功能全面且操作友好的视觉分析工具,适用于各种场景下的目标识别、分割、追踪和姿态识别需求,为用户提供了高效精准的视觉分析解决方案。
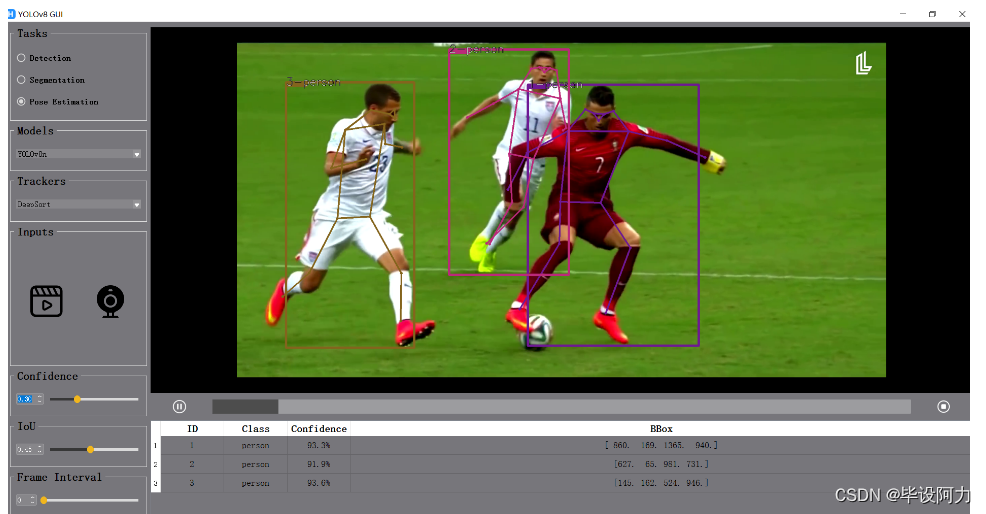
YOLOv8-DeepSort/ByteTrack-PyQt-GUI:全面解决方案,涵盖目标检测、跟踪和人体姿态估计
YOLOv8-DeepSort/ByteTrack-PyQt-GUI是一个多功能图形用户界面,旨在充分发挥YOLOv8在目标检测/跟踪和人体姿态估计/跟踪方面的能力,与图像、视频或实时摄像头流进行无缝集成。支持该应用的Python脚本使用ONNX格式的YOLOv8模型,确保各种人工智能(AI)任务的高效和准确执行。
全面的AI任务
该应用支持一系列AI任务,包括:
目标检测: 使用YOLOv8模型在图像或视频帧中准确检测和识别对象。
姿态估计: 估计和跟踪人体姿态,提供有关身体运动和配置的见解。
分割: 利用YOLOv8进行分割任务,区分并划定图像中的特定区域。
传送门+代码获取-链接 YOLOv8界面-目标检测+语义分割+追踪+姿态识别(姿态估计)+界面DeepSort/ByteTrack-PyQt-GUI-CSDN博客
代码获取
企鹅耗子:767172261