
- 1mac 终极教程,最全,最实用的教程_mac 命令行查看文件属性
- 2argsort和sort区别_sort和argsort的区别
- 3某麦网自动刷新抢票脚本——手机端(二)_大麦自动抢回流手机脚本
- 4AI大模型日报#0522:国产大模型首入全球总榜前10、、微软“Build 2024”大盘点、Hinton万字访谈、字节大模型团队揭秘_中科大项亮
- 5MySQL - 多表查询_mysql多表查询语句
- 6已解决redis.clients.jedis.exceptions.JedisClusterMaxRedirectionsException: Too many Cl异常的正确解决方法,亲测有效!!!
- 7【大数据】Hadoop概述_大数据hadoop
- 8Transformer的常见结构_transformer结构
- 9centos7.9源码安装mysql5.7.44_oracle mysql server 5.7.44
- 10ZYNQ开发中SDK输出串口选择以及打印函数print、printf、xil_printf的差别_zynq printf
上海AI lab发布MathBench,GPT-4o的数学能力有多强?
赞
踩
大模型数学能力哪家强?
最近,上海AI lab构建了一个全面的多语言数学基准——MathBench。与现有的基准不同的是,MathBench涵盖从小学、初中、高中、大学不同难度,从基础算术题到高阶微积分、统计学、概率论等丰富类别的数学题目,跨度大,难度设置呈阶梯状,可以多维度评估模型的数学能力。
本文测试了20+个开源或闭源不同规模的大模型,包括新秀GPT-4o、常胜将军GPT-4,还有开源模型里的扛把子通义千问和llama-3。
一起来看看各家大模型的数学真实水平到底如何吧~
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
论文标题:
MathBench: Evaluating the Theory and Application Proficiency of LLMs with a Hierarchical Mathematics Benchmark
论文链接:
https://arxiv.org/pdf/2405.12209
Github连接:
https://github.com/open-compass/MathBench
方法
1. 预定义知识框架
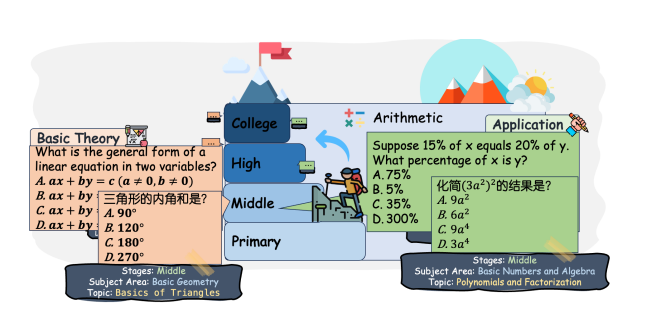
在MathBench中,作者首先将数学内容分为四个主要的教育阶段和一个基础算术阶段。四个阶段对应于基础教育阶段:小学、初中、高中和大学。“算术”阶段评估四种基本数学运算的能力:加、减、乘、除。每个阶段进一步细分为学科领域(如代数、几何、三角学、微积分、统计学、概率论等)和具体主题(如代数中的线性方程、二次方程、多项式和函数),如下图所示:

这种分类确保了广泛数学问题的覆盖,使数据集能够深入揭示模型在各数学领域的理解和熟练程度。每个问题都带有详细标签,包括所属阶段、学科领域和主题,便于分析模型性能并识别其数学理解上的优势与不足。算术阶段的强调也凸显了基础运算在数学学习中的核心地位。
2. 数据收集与统计
在预定义的知识框架下,作者主要收集两类问题:一是理论知识问题,旨在检验模型对基本公式、理论及其推论的理解;二是实际应用问题,考察将理论知识应用于实践的能力。
问题格式定义:由于在开放性问题上难以评估模型的的表现,作者将可能产生复杂答案的理论知识和实践应用问题重新设计为四选一的选择题形式,确保答案的唯一性和干扰项的高混淆度。
对于理论知识问题,从数学教科书和互联网中按主题搜集相关定义和推论,并转化为高质量的多选题。在选择实践应用问题时,遵循以下标准:匹配教育阶段、全面覆盖知识分类体系、问题表述清晰,主要关注如中考、高考、AMC和SAT等教育考试或竞赛的题目,并引入开源问题以丰富多样性。MathBench问题的来源在下表中列出。
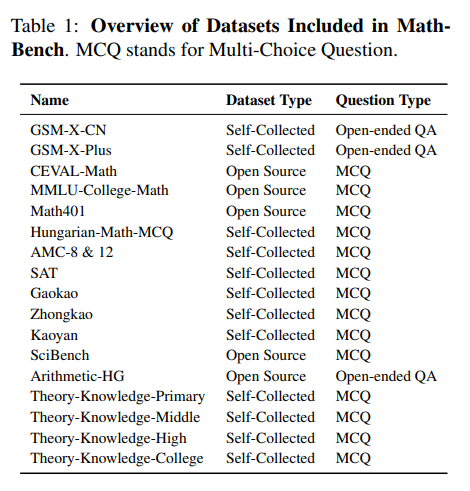
通过使用GPT-4半自动化过滤过程,最终MathBench共包含3709个问题,涵盖五个阶段和三个知识层级的中英文内容。数据集分为MathBench-T(含2,209个理论问题)和MathBench-A(含1,500个实践应用问题)两部分。
实验与分析
本文主要使用CircularEval (CE) 和 perplexity (PPL) 评估Chat模型和Base模型。CE通过系统性地评估包含N个选项的多选问题,每次改变选项顺序来进行评估。为确保评估一致性,统一设置最大输出长度为2048个Token,并采用贪心解码策略对所有LLMs进行评估。评估框架采用OpenCompass。评估模型涵盖了超20中开源与闭源模型,还有几个专门针对数学能力进行微调后的数学LLMs。
chat模型评估效果
下表展示了实验结果,分为面向应用的部分(MathBench-A), 以及理论构成的部分(MathBench-T)。
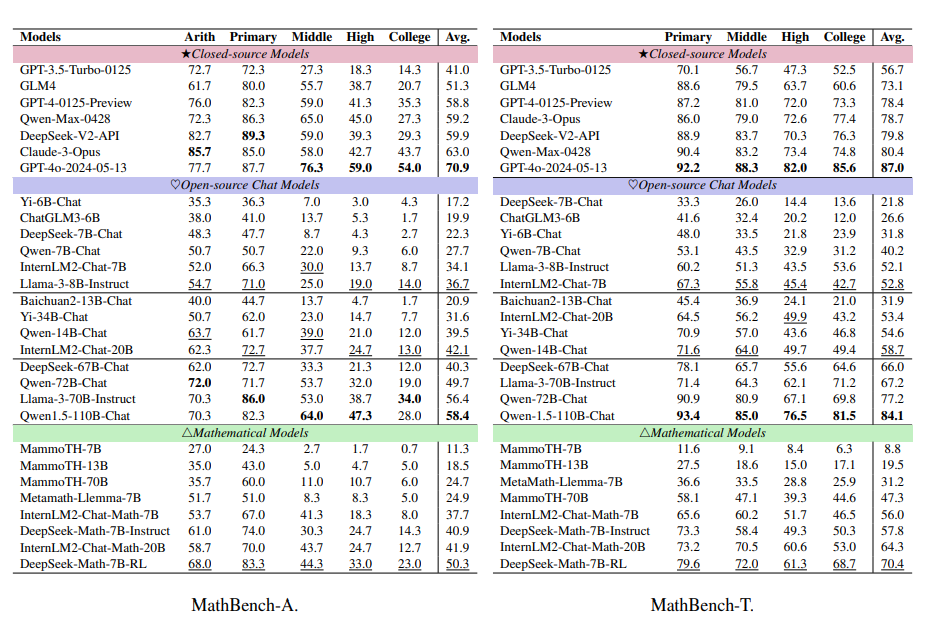
在MathBench-A中,GPT-4o(GPT-4o-2024-05-13)总体表现最佳,尤其在初中、高中和大学阶段数学试题测试中显著领先。开源模型中,Qwen1.5-110B-Chat表现最优,而DeepSeek-Math-7B-RL虽小但数学能力也很突出。
在开源的chat模型中,不同参数规模的模型表现出不同的能力:
约7B模型:InternLM2-Chat-7B和Llama-3-8B-Instruct在7亿规模模型中脱颖而出。Llama-3-8B-Instruct与ChatGLM3-6B相比,性能差距随难度递增,分别高出43.95%-723.53%。这表明高阶数学问题对模型的理解和推理能力提出更高要求,小型LLMs在解决复杂问题上仍面临挑战。
约20B模型:InternLM2-Chat-20B表现出色,其次是Qwen-14B-Chat。尽管Yi-34B-Chat参数量更大,但其性能却不及其他20B模型。这些模型在解决高中和大学复杂数学问题时也面临挑战。
约70B模型: Qwen1.5-110B-Chat在解决数学应用问题上尤为出色,不仅超越了其他开源聊天模型,还超越了多个专用数学模型,性能接近闭源模型GPT-4-0125-Preview。
专注数学任务模型: DeepSeek-Math-7B-RL在处理小学至大学数学应用问题时均表现优异,不仅超越了同类模型,还以仅十分之一的模型大小,在参数量大10倍的DeepSeek-67B-Chat上取得了24.8%的性能优势,这彰显了其在数学问题求解方面的高效性和针对性。
在MathBench-T中,GPT-4o同样在各阶段均表现出色,平均理论得分87.0,位居所有模型之首。结合其MathBench-A的应用得分70.9,GPT-4o在理论与应用层面均展现卓越性能。
Qwen系列模型紧随其后,其中Qwen1.5-110B-Chat在初级阶段领先,并在“Primary”阶段以93.4的CE分数居首。但在高级教育阶段,GPT-4o优势明显,如大学级理论知识阶段高出Deepseek-Math-7B-RL达16.9分。
InternLM2-Chat-7B在70亿参数模型中表现稳健,其理论阶段表现优于Qwen-7B-Chat达31.3%。Deepseek-Math-7B-RL在数学领域持续领先,成绩超越Llama-3-70B-Instruct。
MathBench测试显示,模型在理论与应用能力上排名相近,理论强的模型应用亦佳,反之亦然。
Base模型评估结果
下表展示了Base模型的结果,可以看出Base模型与其Chat模型性能一致。
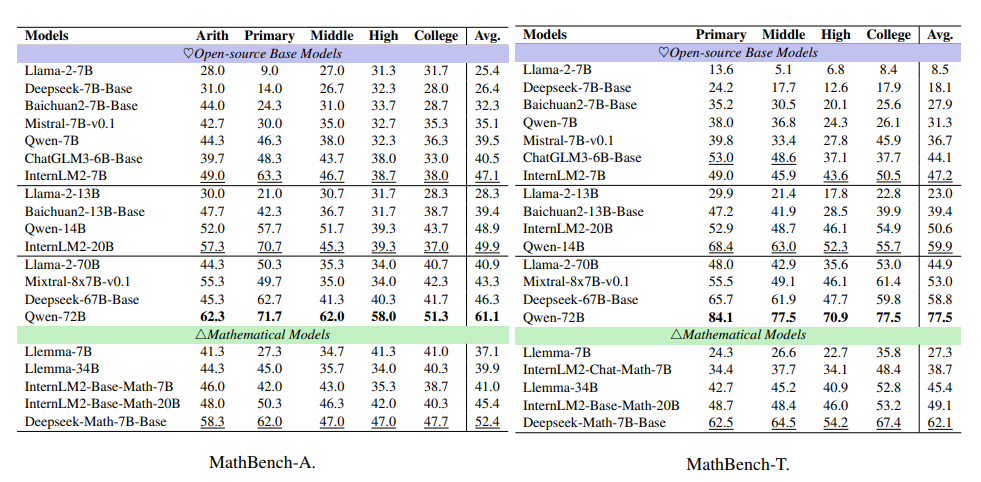
在7B参数范围里,InternLM2-7B的表现是最好的。Qwen-14B和Qwen-72B在MathBench基准测试中,各自在其所属的参数类别中表现得非常出色。
在处理数学任务时,Deepseek-Math-7B-Base与Chat模型的表现结果非常接近,这说明基础模型(Base模型)和聊天模型(Chat模型)在性能上有很高的相似性。
ChatGLM3-6B-Base在7B类别中排在第二位,它超过了Qwen-7B和Mistral-7B-v0.1。但是,它的聊天版本ChatGLM3-6B在MathBench-A测试中,性能比Qwen-7B-Chat差95.2%,在MathBench-T测试中,差距更是高达104.7%。这种性能上的差异很可能是因为在后续优化阶段,它们采用了不同的调整方法。
细粒度分析
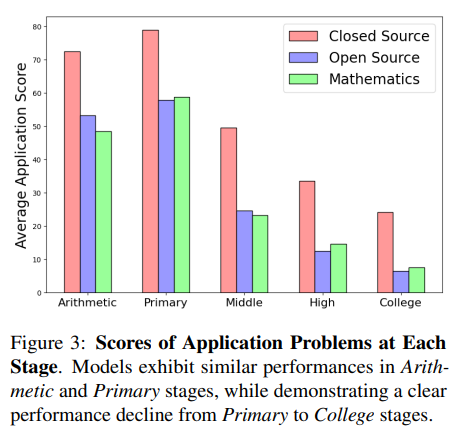
模型在应用问题上的得分随着问题难度的提升而显著变化。
如下图所示,大多数模型在算术和基础数学问题上的表现很出色。然而,当问题难度达到中等或更高时,它们的性能会大幅下降。这说明当前模型在解决可以通过直接计算、模式识别或记忆基本概念的任务时表现良好,但在面对更复杂的数学问题时则显得力不从心。
模型的理论理解与应用能力之间存在差距吗?
模型的理论理解与应用能力之间确实存在差距,尤其是在处理不同阶段的数学问题时。如下图所示,LLM在不同阶段的理论和应用得分趋势揭示了这一点。
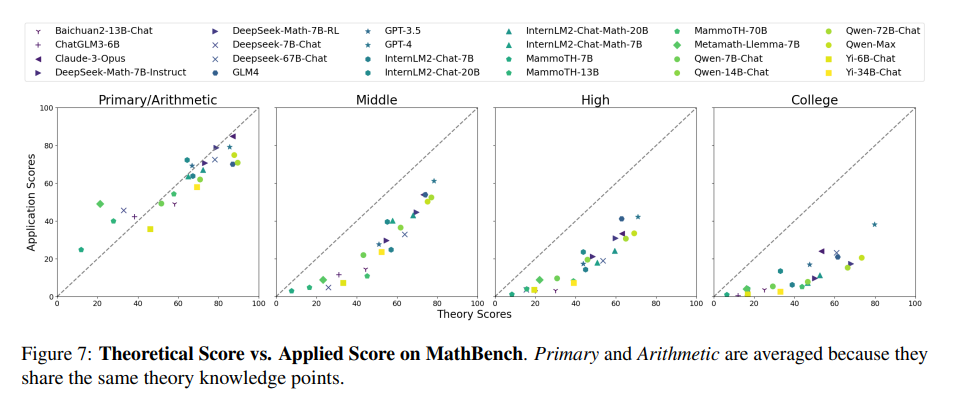
在基础阶段,大多数LLM的理论和应用得分高度相关,显示出它们在解决简单任务时,理论理解和应用能力能够较好地结合。然而,也有少数例外。例如,Qwen-72B-Chat在理论能力上表现出色,而Claude-3-Opus在应用能力上更胜一筹。
随着问题难度的增加,即进入中等及以上阶段,模型需要更强的计算和推理能力来取得良好的应用得分。在这一阶段,理论与应用之间的差距开始显现。GPT-4在所有阶段的应用表现都领先,尤其是在更高级阶段,这种差距更加明显。
因此,虽然理论是解决大多数应用问题的基础,但在面对更高难度的任务时,模型的理论理解与应用能力之间会存在一定的差距。为了提高模型的整体性能,我们需要在加强模型理论理解的同时,注重提升其在实际应用中的表现。
模型在不同子主题下表现如何?
如下图所示,模型在涉及基础数学技能的主题上表现优异,如“单位转换”、“四则运算”和“方程的基本概念”,这些主题的平均得分较高。
然而,面对需要抽象推理和复杂计算的主题,如“双重积分”、“数学逻辑”和“集合论”,模型表现欠佳,平均得分较低。
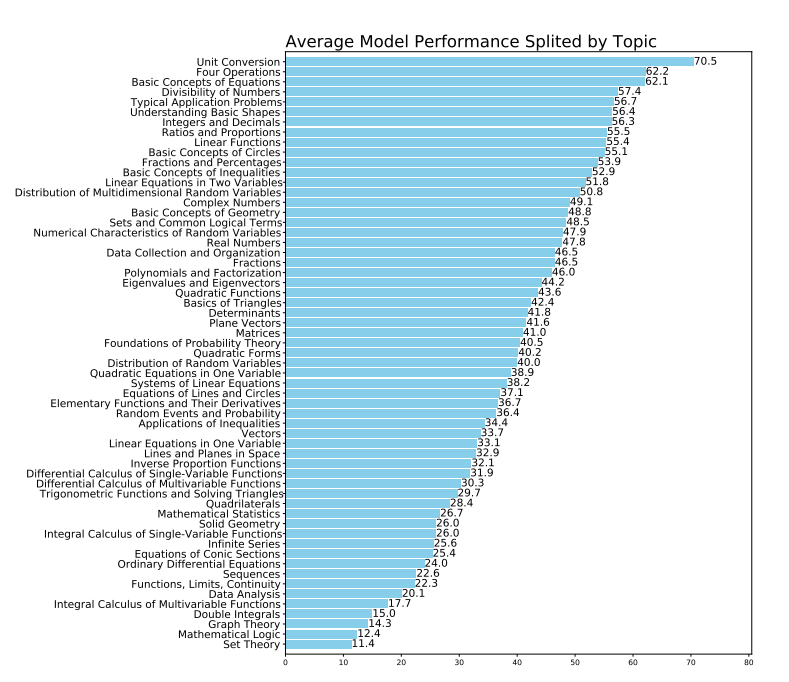
这提示我们,针对这些较难的数学问题,需要对模型进行专门的分析和优化,找出推理能力不足或基础理论概念掌握不稳定的根源,以提高模型的整体性能。
在双语场景下,哪种模型表现更佳?
下图展示了各种LLM在MathBench上的双语能力,强调了处理需要理解不同语言和数学概念细微差别数学任务时语言灵活性的重要性。
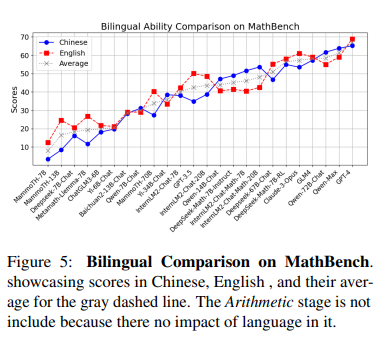
在所有LLM中,GPT-4以67.1的最高双语分数领先,它在中文(65.2)和英语(69.0)方面的表现均衡,这显示出其卓越的双语处理能力。其他模型如Qwen-72B-Chat和DeepSeek Math-7B-RL也展现出了显著的双语能力。但值得注意的是,大多数评估的LLM在中文和英语之间的性能差距相比GPT-4要大得多。
错误分析
本文还对每个阶段随机抽取的80个理论问题和100个应用问题进行了全面的错误分析,如下图所示:
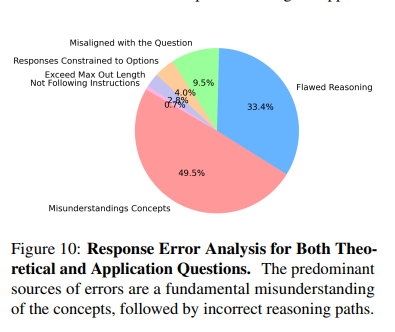
错误主要由以下问题引起:
-
知识匮乏:在理论性问题中,高达78%的模型错误源于对数学概念的误解,这一比例在所有错误中占据49.5%。这表明大多数模型在掌握基础知识和术语上还存在明显的不足。
-
推理能力欠缺:模型在逻辑推理方面存在明显短板,33.4%的错误源于逻辑上虽连贯但存在缺陷的推理过程。此外,还有9.6%的错误是因为模型偏离了用户的查询意图,这反映出模型在理解用户意图和给出恰当回答方面的局限性。随着任务难度的增加,这类与推理相关的错误也会增多。
-
长度限制:尽管在统计上不是主要的错误类型(仅占4.0%),但模型在处理复杂任务时受限于输出长度,这暴露了模型在有限空间内处理复杂指令和任务的挑战。
-
其他不足:有时,模型会给出缺乏明确推理过程的回答,这使得审查变得困难。然而,那些具备更强推理能力的模型在面对选择时,能够展现出批判性思维,提供超出预设选项的解答。
结语
MathBench根据问题难度和阶段对数学题进行分类,全面评估了LLMs的数学能力。它覆盖了教育各阶段的广泛学科和主题,为数学学习和评估领域的研究者及教育工作者提供了宝贵的资源。


