
- 1mysql存时间戳报错 Out of range value for column ‘create_time‘ at row 1_timestamp out of range
- 2鸿蒙HarmonyOS开发实战:【分布式音乐播放】_harmony音频播放
- 3error loading python lib,【Pyinstaller】mac打包后应用无法启动,错误提示Error loading Python lib ,code signature inva...
- 4Error: Cannot find module ‘vue-template-compiler/package.json‘ Require stack:_cannot find module 'vue-template-compiler
- 5离线部分+在线部分:命名实体审核任务RNN模型、命名实体识别任务BiLSTM+CRF模型、BERT中文预训练+微调模型、werobot服务+flask_あずにゃん在线
- 6PPAS 兼容oracle部分函数表达式索引
- 7为Atmega328P定制bootloader 添加自己的板卡到Arduino IDE
- 8WindowManager.LayoutParams之screenBrightness亮度设置
- 9Unity 退出游戏代码_unityeditor.editorapplication.isplaying = false
- 10conda安装python版本失败_为什么conda install python 不成功
为什么我们在自然语言处理(NLP)中使用词嵌入(word embedding)?_为什么要训练特定领域的词嵌入模型
赞
踩
本文是一篇翻译文章,原文地址(https://towardsdatascience.com/why-do-we-use-embeddings-in-nlp-2f20e1b632d2).
自然语言处理(NLP)是机器学习(ML)的一个子领域,NLP任务通常以文本形式处理自然语言,而文本本身由较小的单元(如单词和字符)组成。而要处理的文本数据是有问题的,因为我们的计算机,脚本和机器学习模型无法以任何人类的角度阅读和理解文本。
比如当我读到"猫"这个词时,就会想象到许多内容——它是一种可爱的小毛茸茸的动物,喜欢吃鱼,或者我的房东不允许养猫等。但是,这些语言关联是数百万年进化过程中相当复杂的神经相互影响的结果,而我们的机器学习(ML) 模型必须从零开始,它对词义没有预先构建的理解。
我们如何以数字化形式最好的表示文本输入数据?
理想情况下,无论我们想出什么数值表示方法,在语义上都会是有意义的——数值表示法应该尽可能多地捕获单词的语言意义。精心挑选的、信息丰富的输入表示形式会对整体模型性能产生巨大影响。
词嵌入(word embedding)是解决此问题的主要且普遍的方法,以至于在任何 的NLP 项目中实际上都使用了词嵌入的方法。无论你是在文本分类、情感分析还是机器翻译等任务中,你都可以下载预先计算好的嵌入数据(如果你的问题相对标准),或者考虑使用哪种方法从数据集中计算你自己的词嵌入。
但是为什么我们要在自然语言处理任务中使用词嵌入呢?
不谈论任何用于计算词嵌入的特定算法(假设你从来没有听说过 word2vec 或 FastText 或 ELMo),这篇文章将回到基础知识来回答以下问题:
- 为什么我们需要复杂的方法来表示单词?
- 用数字表示单词的最简单方法是什么?
- 词嵌入中的"将单词映射到高维语义空间"到底是什么意思?
- 如何可视化和直观地理解单词嵌入?
当没有词嵌入时
当给定 10000 个单词的词汇表,用数字表示每个单词的最简单方法是什么?

10000个词汇的单词表
那么最简单的就是为每个单词分配一个整数索引:

10000个有词汇索引的单词表
给定这种单词到整数的映射,我们可以将单词表示为数字向量,如下所示:
- 每个单词将被表示为一个n维向量,其中n是词汇量(本示例中n为10000)
- 每个单词的向量表示形式大多为"0",除了在词汇表中与单词索引相对应的位置中为"1"。
下边是一些示例:
- 我们第一个词汇单词“ aardvark”的矢量表示为[1,0,0,0,...,0],在第一个位置为“ 1”,后跟9,999个零
- 我们第二个词汇词“ ant”的矢量表示为[0,1,0,0,…,0],第一个位置为“ 0”,第二个位置为“ 1”,其后为9,998个零
- 其他的可以依次表示
此过程称为one-hot编码。你可能还听说过这种方法用于表示多分类问题中的标签。
现在,假设我们的NLP项目正在构建翻译模型,我们想将英语输入语句"the cat is black"翻译成另一种语言。我们首先需要用one-hot编码来表示每个单词。我们首先将查找第一个单词“ the”的索引,然后发现在我们的10,000长词汇列表中的索引为8676.

然后,我们可以使用长度为10,000的向量表示单词“ the”,其中只有8676位置为"1",其他位置为"0".

我们对输入句子中的每个单词进行索引查找,并创建一个向量来表示每个输入单词。整个过程看起来像是GIF:

使用one-hot编码"the cat is black"的过程
请注意,此过程为每个输入单词生成了非常稀疏的(几乎为零)特征向量(此处术语“特征向量”,“嵌入”和“词表示”可互换使用)。
这些one-hot vector是将单词表示为实值数字向量的快速简便方法。
问题来了:如果你想生成整个句子(而不只是每个单词)的表示,该怎么办?最简单的方法是连接或平均句子的组成词嵌入(或两者的混合)。更高级的方法将顺序读取每个单词的嵌入,比如 encoder-decoder RNN模型,以便通过变换的层级来逐步建立句子含义的密集表示(有关ELMo句子嵌入的快速概述,请参阅此帖子)
one-hot编码的稀疏性问题
我们已经完成one-hot编码,并成功地将每个单词表示为数字向量。许多NLP项目已经做到了这一点,但是最终结果却是中等的,尤其是在训练数据集很小的情况下。这是因为one-hot vectors不是很好的输入表示方法。
为什么one-hot编码是词表示的次优方法?
- 相似性问题。理想情况下,我们希望类似"cat"和"tiger"之类的词具有相似的特征。但是使用one-hot vector,"cat"和"tiger"就像其他任何单词一样,不能表示出相关性。一个相关的观点是,我们可能想对词嵌入进行类比矢量的操作(例如,“cat”-“small” +“large”等于什么?我们希望的结果是像老虎或者狮子之类大的动物)。我们需要足够丰富的字词表示法来进行此类操作。
- 词汇量问题。通过这种方法,当你的词汇量增加n时,特征向量的维度也将增加n。one-hot vector的维数与单词数相同。你可能不希望特征大小太大,也就是说,更多的特征需要更多的参数来评测,并且需要指数级的增加数据以充分估计这些参数来构建合理的通用模型(请搜索:curse of dimensionality)。
- 计算问题。每个单词的嵌入/特征向量大多为零,并且许多机器学习模型无法很好地使用高维和稀疏的特征。神经网络尤其难以处理此类数据(尽管存在变通方法,例如:using a type of LASSO-like feature selection)。面对如此大的特征空间,你可能有陷入内存甚至存储问题的危险,尤其是当你使用的模型不能很好地与稀疏矩阵的压缩版本配合使用时(e.g. SciPy’s CSR format for sparse matrices, tutorial here)
这些要点是相关的,计算和词汇量问题可以被视为技术问题,而相似性问题更像是“最好拥有”的点。
one-hot vector密集嵌入的问题?
嵌入解决的核心问题是泛化
- 泛化问题。如果假设“ cat”和“ tiger”之类的词确实相似,则我们需要某种方式将这些信息传递给模型。如果其中一个单词很少出现(例如,“ liger”),这一点就变得尤为重要,因为它可以搭载在类似的,更常见的单词贯穿模型的计算路径上。这是因为,在训练过程中,该模型通过按权重和偏差参数定义的转换层进行发送,从而学习以某种方式对待输入的“cat”。当网络最终看到“ liger”时,如果其嵌入类似于“ cat”,则它将采用与“ cat”相似的路径,而不是网络必须学习如何从头开始完全处理它。对事物进行预测是非常困难的,如果它与你所见过的事物有关,则要容易得多。
这意味着嵌入使我们可以构建更通用的模型,而不是网络需要为学习断开连接的输入而学习许多不同的方法,而让相似的词“共享”参数和计算路径。
稀疏的one-hot编码总是不好的吗?
在某些情况下,最好对嵌入使用稀疏的one-hot编码。为了解释Yoav Goldberg在他的神经网络中的NLP引物,如果:
- 你的输入特征数量较小
- 你不希望输入具有关联性(与上面的“cat”和“liger”示例相反)
- 你不希望输入数据共享模型的参数
- 并且你有许多数据可以学习
那么使用稀疏的one-hot编码可能不是最坏的主意。
一个独立但相关的观点:当然,对于分类数据进行预处理时,one-hot编码始终是有意义的,因为许多ML模型无法直接处理分类数据(例如文本标签)。你仍将使用它们将多类标签向量转换为许多二进制类向量,或将少数分类特征向量转换为其二进制形式。
面向密集的,语义上有意义的表示
现在,我们已经讨论了one-hot vector及其缺陷,下面我们来讨论使用密集的,语义上有意义的特征矢量来表示单词的含义。
如果我们从词汇表中选取5个示例单词(例如,单词“ aardvark”,“ black”,“ cat”,“ duvet”和“ zombie”)并检查通过上述one-hot编码方法创建的嵌入矢量,结果将如下所示:

使用one-hot编码的词向量。每个单词都由一个几乎为零的向量表示,除了该单词在词汇表中的索引所指示的位置中只有一个“ 1”。注意:并不是说“black”,“cat”和“duvet”具有相同的特征向量,而是这里看起来像这样。
但是,当人类说某种语言时,我们知道单词是这些丰富的实体,具有许多层次的含义和含义。让我们为这5个单词制作一些语义特征。具体来说,让我们将每个单词的四种语义(animal,fluffiness,dangerous,spooky)的值设置为介于0和1之间:

为词汇表中的5个词构建的语义特征
然后,解释一下这几个例子:
- 对于“ aardvark”一词,我们赋予它“动物(animal)”特征的较高值(因为它是一种动物),而“蓬松度(fluffiness)”(aarvarks的鬃毛教短),“危险(dangerous)”相对较低。和“怪异(spooky)”(它们很迷人)
- 对于“cat”这个词,我赋予它“动物(animal)”和“蓬松(fluffiness)”特征(不言自明)的较高的值,为“危险(dangerous)”赋予中间值和“ 怪异(spooky)”的中间值
根据语义特征值绘制词语
我们工作的要点:
每个语义特征可以在更广泛的,更高维度的语义空间中作为一个维度.
- 在以上组成的数据集中,有四个语义特征,我们可以一次将其中两个作为2D散点图绘制(请参见下文)。每个特征都是不同的轴/尺寸
- 该空间内每个单词的坐标由其在对应特征上的特定值给出。例如,在2D蓬松度(fluffiness)与动物(animal)2D绘图上的单词“aardvark”的坐标为(x = 0.97,y = 0.03)
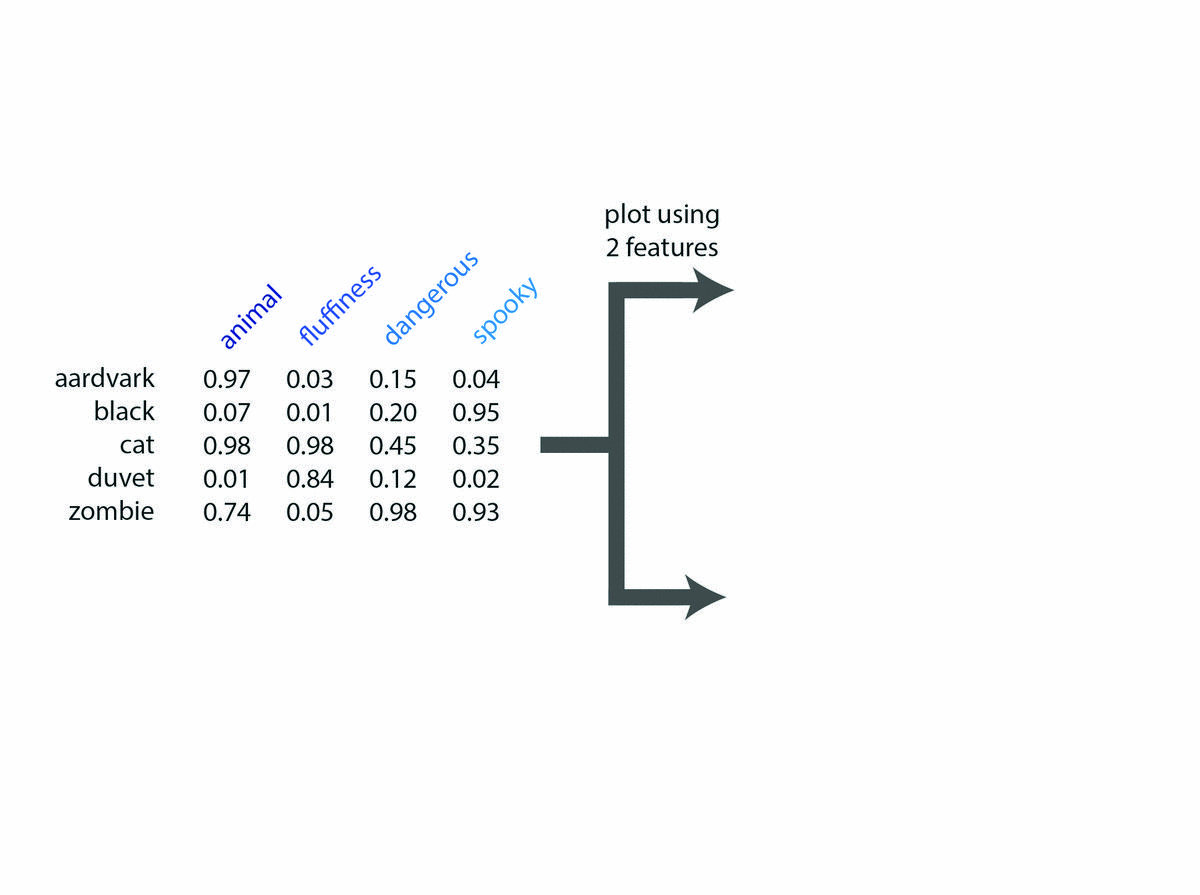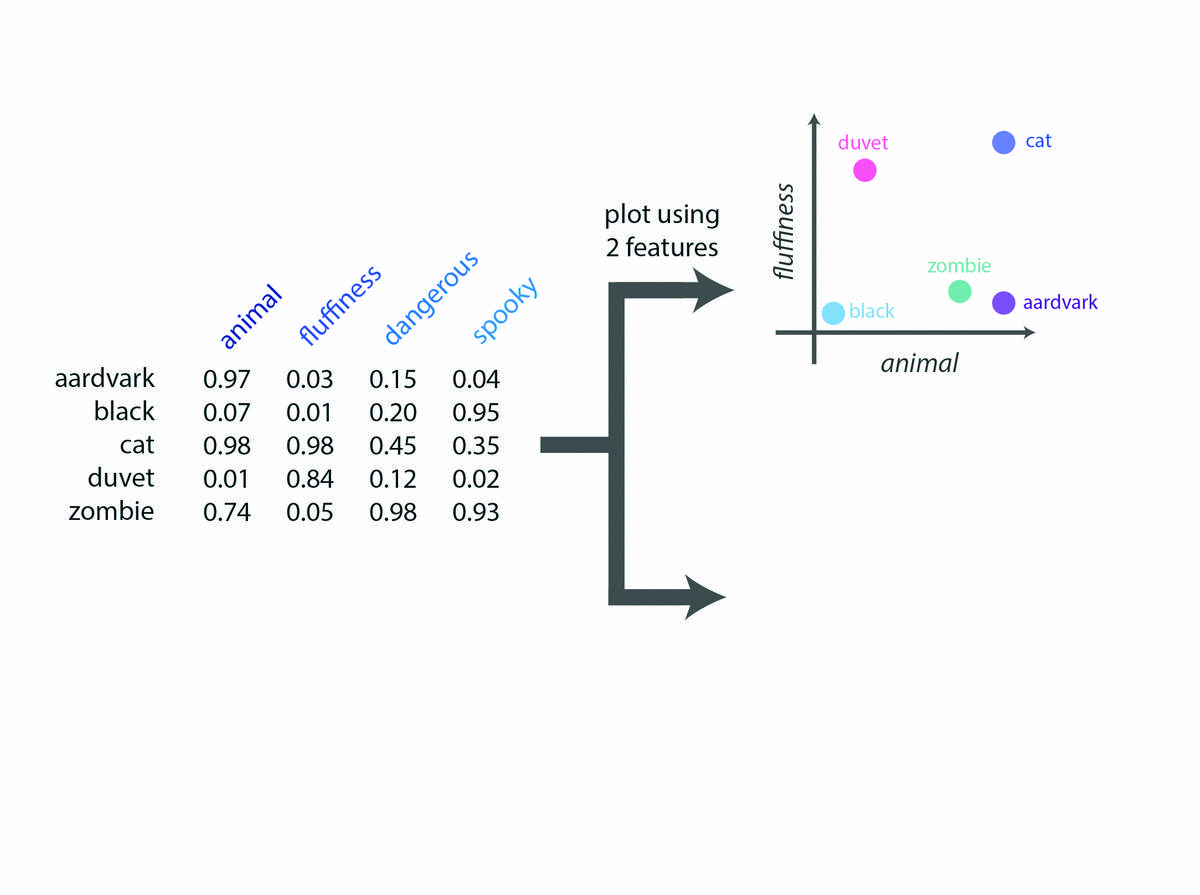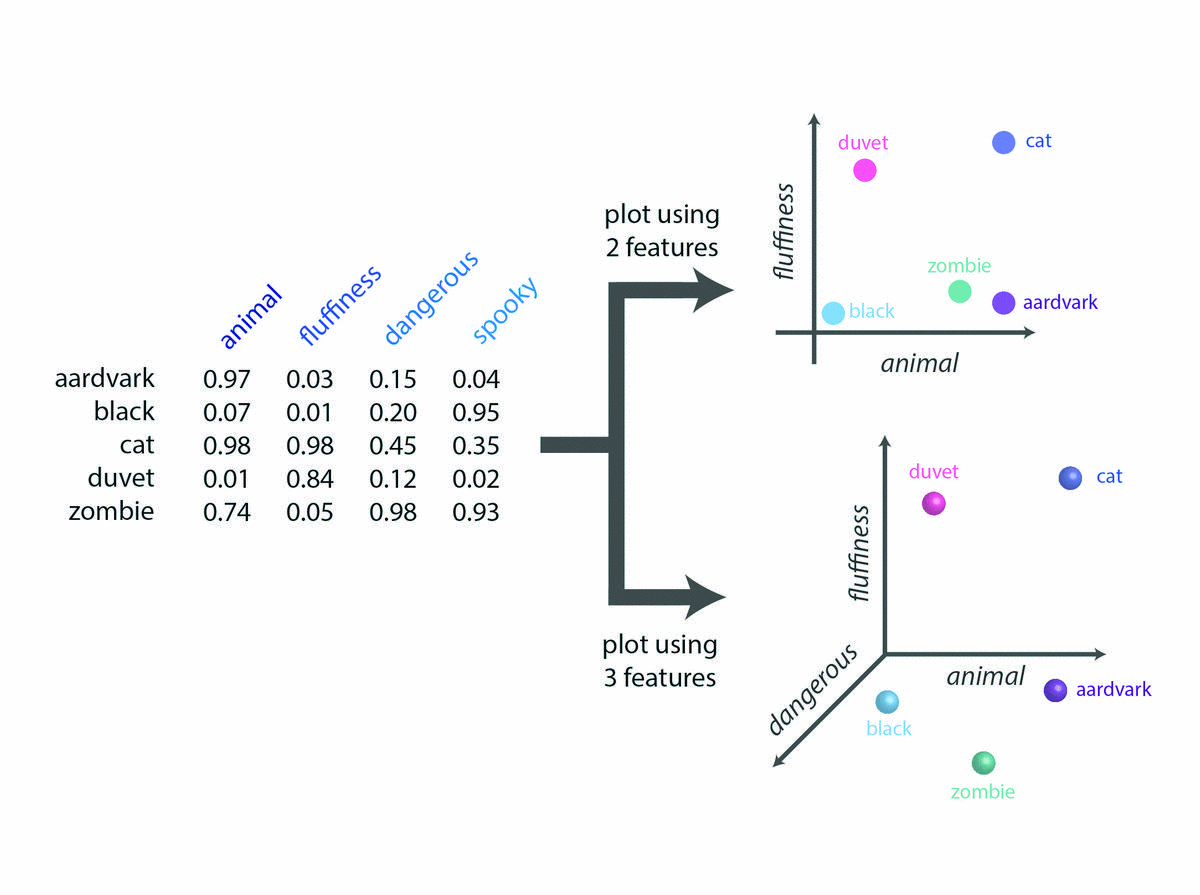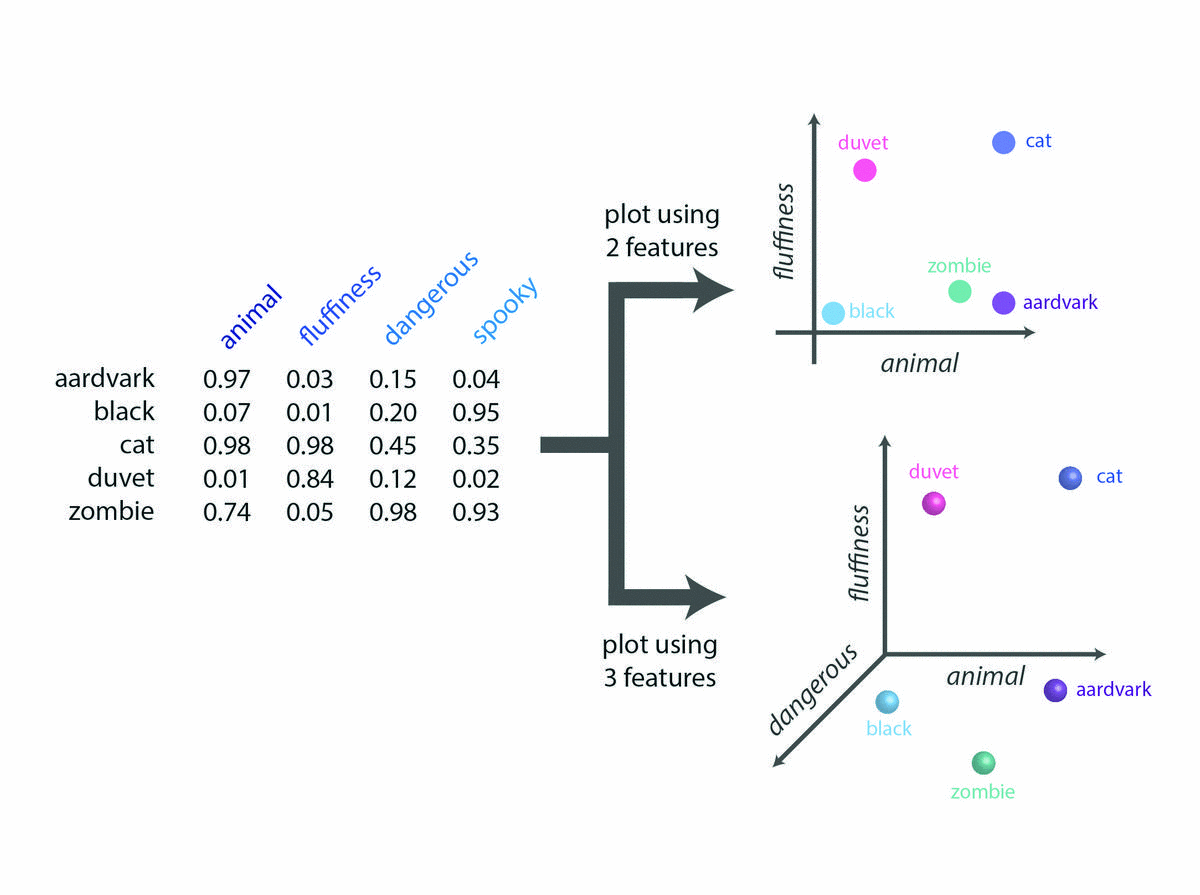
在2维或3维空间绘制词特征
- 同样,我们可以考虑这三个特征(“动物”,“蓬松”和“危险”),并在此3D语义空间中绘制单词的位置。例如,单词“duvet”的坐标为(x = 0.01,y = 0.84,z = 0.12),表明“duvet”与蓬松度概念高度相关,可能略有危险,并且不是动物。
这是一个自己制作的示例,但实际的嵌入算法当然会自动生成输入语料库中所有单词的嵌入向量。如果你希望,你可以将 word2vec 等词嵌入算法视为单词的不受监督的特征提取器。
像word2vec的词嵌入算法是对于词的无监督特征提取
这篇文章不会描述这些算法是如何工作的,但核心思想是,在类似上下文中使用的单词将得到类似的表示形式。也就是说,以类似方式使用的单词将紧密放置在高维语义空间中,这些点将聚集在一起,它们彼此之间的距离将很近。
应该用多少维度来表示词?
Word Emdedding算法通常要求你设置希望嵌入的维度数 - 那么合适且正确的维度应该是多少?
直观地是,你输入的类型更多得到的维度也更多。因此,如果你正在计算词的嵌入(其中语料库中可能有数万种类型),则需要更多维度,而如果你计算词性部分标记(如"名词","动词","形容词")的嵌入,则这些类型类型并不少。例如,在流行的 Python NLP 库 NLTK 中,只有 35 种词性(POS),你可能不需要太多的维度,就可以很好地表示每个 POS 类型。
嵌入的维度应该为多少实际上被证明是一个经验问题,而最优数还没有从理论上计算出来。这里的权衡标准是准确性和计算问题:
- 维度越小,越有可能计算越来越精确的字词表示
- 但更多的维度也意味着对计算资源(处理速度、内存要求)的更高需求 — 这在训练阶段更为明显,但它也会影响获得结果的速度
在实践中,人们使用尺寸在 50 到 500 左右的词嵌入向量(一般经常取 300 个),有时对于竞争非常激烈的系统,可以试图从模型中挤出尽可能多的嵌入向量。
可视化词嵌入
与此相关的是,鉴于这些语义空间通常非常高维,应该如何直观地看到它们中发生了什么?人不能看到超过 3 个维度。
“To deal with hyper-planes in a 14-dimensional space, visualise a 3-D space and say ‘fourteen’ to yourself very loudly. Everyone does it.” - Geoff Hinton
你可以随机选择两个或三个要素,并在这两个或三个轴上绘制点。但是,由于特征/轴通常无法解释,因此你不知道选择哪些要素。此外,单词的位置可能会因你选择的特定轴而变化很大,因此,如果你随机选择几个轴,你就不会获得准确的单词位置。
在实践中,人们通常会使用降维方法(如 t-SNE 或 PCA)将高维嵌入点投影到低维空间中(同时丢失信息)。重要的是,它允许你提取每个单词的两个坐标(比如说从300维降到2维),然后你可以使用 2D 散点图轻松可视化。有很多不错的教程,比如这个。
结论
总结说来,词嵌入:
- 将单词表示为语义上有意义的密集实值向量
- 这解决了简单的one-hot编码的许多问题
- 最重要的是,词嵌入可提高几乎任何 NLP 问题的通用化和性能,尤其是在没有太多的培训数据时
以上就是文章的翻译,欢迎指正。

