
- 1java高级面试题总结_高级java面试
- 2实现c语言中的strstr函数_strstr c语言实现
- 3Android开发:应用百度智能云中的身份证识别OCR实现获取个人信息的功能_百度ai身份证识别 sdk
- 4【python】动态可视化+爬虫(超燃超简单)_python爬虫可视化代码
- 5Redis三种集群模式-Cluster集群模式
- 6混淆矩阵的生成(python实现,含机器学习方法)
- 7探秘双记账系统:DoubleEntry 开源库的奥秘
- 8使用STM32CubeMX读取温度传感器数据的嵌入式应用_stm32读取温度
- 9『大模型笔记』Ollama ModelFile(模型文件)
- 10分布式事务——微服务下的分布式事务问题、分布式事务的解决方案_微服务事务解决方案
mysql keepalived_mysql高可用+keepalived
赞
踩
生产环境中一台mysql主机存在单点故障,所以我们要确保mysql的高可用性,即俩台mysql服务器如果其中有一台mysql服务器挂掉后,另外一台就能立刻接替进行工作。
MYSQL的高可用方案一般有
Keepalived+双主,MHA,PXC,MMM,Heartbeat+DRBD等 比较常用的是keepalived+双主MHA和PXC
这次主要介绍利用keepalived实现MYSQL数据库的高可用。
基本思路:俩台MYSQL互为主从关系(双主),通过keepalived配置配置虚拟IP,实现当其中一台mysql挂机后,应用能够自动切换到另外一台MYSQL数据库,保证系统的高可用。
操作系统 Centos7.2
MYSQL版本5.7
Keepalived:keepalived-1.2
Mysql-vip:192.168.0.100
Mysql-master1:192.168.0.7
Mysql-slave1:192.168.0.6
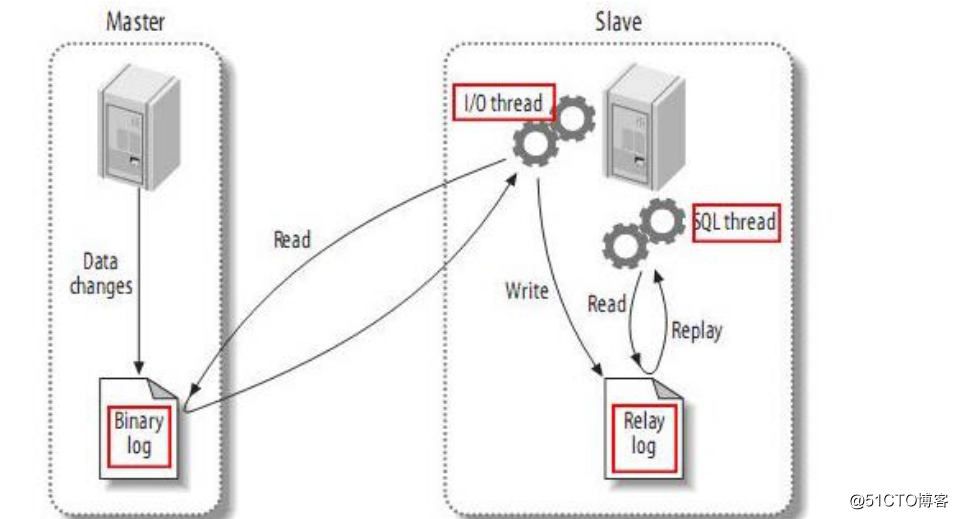
该过程的第一部分就是master记录着二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。Mysql将事务写入二进制日志,在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程--I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。
Binlog dump process 从master的二进制日志中读取事件。I/O线程将这些事件写入中继日志。
SQL slave thread (SQL从线程) 处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该进程与I/O线程保持一致,中继日志通常位于OS缓存中,所以中继日志的开销很小。
主主同步就是俩台机器互为主从关系,在任何一台机器上写入都会同步。
1:修改MYSQL配置文件
俩台mysql均要开启binlog日志功能,开启方法:在MYSQL配置文件加上
Log-bin=MYSQL-bin选项,俩台mysql的server-ID不能一样,默认情况下server-ID都是1,需要其中slave修改为2即可。
一:master1中有关配置如下basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
server_id = 1
socket = /usr/local/mysql/mysql.sock
log-error = /usr/local/mysql/data/mysqld.err
log-bin=mysql-bin
binlog_format=mixed
relay-log=relay-bin
relay-log-index=slave-relay-bin.index
auto-increment-increment=2
auto-increment-offset=1
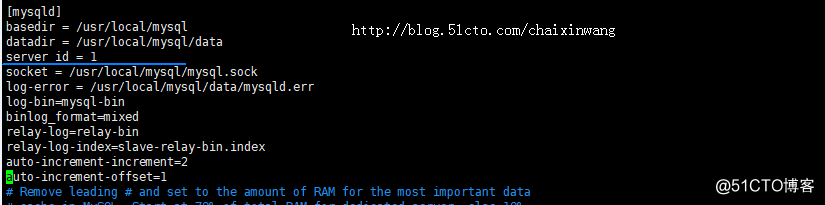
重启mysql服务
Master2中有关复制配置如下[mysqld]
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
server_id = 2
socket = /usr/local/mysql/mysql.sock
log-error = /usr/local/mysql/data/mysqld.err
log-bin=mysql-bin
binlog_format=mixed
relay-log=relay-bin
relay-log-index=slave-relay-bin.index
auto-increment-increment=2
auto-increment-offset=2

重启mysqld服务
二:将master1设为master2的主服务器
在master1主机上创建授权账户,允许在master2(192.168.0.6)主机上连接mysql> grant replication slave on *.* to 'rep@192.168.0.7' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.01 sec)
查看master1的当前binlog状态信息

在slave上将master设为自己的主服务器并开启slave功能mysql>change,master,to,master_host='192.168.0.6',master_user='rep',master_password='123456',master_log_file='mysql-bin.000004',master_log_pos=451;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
 mysql> start slave;
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
查看从的状态,以下俩个值必须为yes,代表从服务器能正常连接主服务器
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
mysql> show slave status\G;

三,将master2设为master1的主服务器
在slave主机上创建授权账户,允许在master(192.168.0.6)主机上连接mysql> grant replication slave on *.* to 'rep'@'192.168.0.6' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)
查看slave的当前binlog状态信息
mysql> show master status;

在master上将slave设为自己的主服务器并开启slave功能mysql>change,master,to ,master_host='192.168.0.7',master_user='rep',master_password='123456',master_log_file='mysql-bin.000003',master_log_pos=154;
Query OK, 0 rows affected, 2 warnings (0.03 sec)

查看从的状态下,以下俩个值必须为yes代表从服务器能正常连接主服务器

四:测试主主同步
在master上创建数据库chai看看slave是否同步
主的服务器

从的服务器验证已经同步过来

现在任何一台MYSQL上更新数据同步到另一台mysql同步完成
注意:若主MYSQL服务器已经存在,只是后期才搭建从MYSQL服务器,在配置数据同步前应先主MYSQL服务器的要同步的数据库拷贝到从MYSQL服务器上(如先在主MYSQL上备份数据库,再用备份在从MYSQL服务器上恢复
接着完成keepalived的高可用性
Keepalived是集群管理中保证集群高可用的一个软件解决方案,其功能类似与heartbeat用来防止单点故障
keepalived的工作原理是VRRP(Virtual Router Redundancy Protocol)虚拟路由冗余协议。在VRRP中有两组重要的概念:VRRP路由器和虚拟路由器,主控路由器和备份路由器。VRRP路由器是指运行VRRP的路由器,是物理实体,虚拟路由器是指VRRP协议创建的,是逻辑概念。一组VRRP路由器协同工作,共同构成一台虚拟路由器。 Vrrp中存在着一种选举机制,用以选出提供服务的路由即主控路由,其他的则成了备份路由。当主控路由失效后,备份路由中会重新选举出一个主控路由,来继续工作,来保障不间断服务。
二 keepalived安装配置
1 在master和slave上安装软件包keepalived
安装keepalived软件包和服务控制
在编译安装keepalived之前,必须安装内核开发包kernel-devel以及openssl-devel popt-devel等支持

若没有安装通过rom或者yum工具安装
编译安装keepalived
使用指定的linux内核位置对keepalived进行配置,并将安装路径制定为根目录,这样就无需额外创建连接文件,配置完成 依次执行make make install进行安装

使用keepalived服务
执行make install操作之后 会自动生成/etc/init.d/keepalived脚本文件,但是需要手动添加为系统服务,这样就可以使用server chkconfig工具对keepalived服务进程管理了

2修改keepalived配置文件
keepalived 只有一个配置文件keepalived.conf,里面主要包括以下几个配置区域,分别是
global_defs、vrrp_instance和virtual_server。
global_defs:主要是配置故障发生时的通知对象以及机器标识。
vrrp_instance:用来定义对外提供服务的VIP区域及其相关属性。
virtual_server:虚拟服务器定义
master1 主机上的keepalived.conf文件的修改:
vi /etc/keepalived/keepalived.conf:
! Configuration File for keepalived //!表示注释
global_defs {
router_id MYSQL-1 //表示运行keepalived服务器的一个标识
}
vrrp_instance VI_1 {
state BACKUP //指定keepalived的角色,两台配置此处均是BACKUP,设为BACKUP将根据
优先级决定主或从
interface eth0 //指定HA监测网络的接口
virtual_router_id 51 //虚拟路由标识,这个标识是一个数字(取值在0-255之间,用来区分多个
instance 的VRRP组播),同一个vrrp实例使用唯一的标识,
确保和 master2 相同,同网内不同集群此项必须不同,否则发
生冲突。
priority 100 //用来选举master的,要成为master,该项取值范围是1-255(在此范围
之外会被识别成默认值 100),此处master2上设置为50
advert_int 1 //发VRRP包的时间间隔,即多久进行一次master选举(可以认为是健康查
检时间间隔)
nopreempt //不抢占,即允许一个priority比较低的节点作为master,即使有priority更高
的节点启动
authentication { //认证区域,认证类型有PASS和HA(IPSEC),推荐使用PASS(密码
只识别前 8 位)
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { //VIP 区域,指定vip地址
192.168.0.100
}
}
virtual_server 192.168.0.100 3306 { //设置虚拟服务器,需要指定虚拟IP地址和服务端口,
IP 与端口之间用空格隔开
delay_loop 2 //设置运行情况检查时间,单位是秒
lb_algo rr //设置后端调度算法,这里设置为rr,即轮询算法
lb_kind DR //设置LVS实现负载均衡的机制,有NAT、TUN、DR三个模式可选
persistence_timeout 60 //会话保持时间,单位是秒。这个选项对动态网页是非常有用的,
为集群系统中的 session 共享提供了一个很好的解决方案。
有了这个会话保持功能,用户的请求会被一直分发到某个服务节点,
直到超过这个会话的保持时间。
protocol TCP //指定转发协议类型,有TCP和UDP两种
real_server 192.168.1.101 3306 { //配置服务节点1,需要指定real server的真实IP地址和
端口,IP 与端口之间用空格隔开
注:slave 上此处改为192.168.0.7(即slave本机ip)
weight 3 //配置服务节点的权值,权值大小用数字表示,数字越大,权值越高,设置权
值大小为了区分不同性能的服务器
notify_down /etc/keepalived/bin/mysql.sh //检测到realserver的mysql服务down后执行的
脚本
TCP_CHECK {
connect_timeout 3 //连接超时时间
nb_get_retry 3 //重连次数
delay_before_retry 3 //重连间隔时间
connect_port 3306//健康检查端口
}
}
}
启动 keepalived 服务
#/etc/init.d/keepalived start
3、master1和master2上都添加此检测脚本,作用是当mysql停止工作时自动关闭本机的
keepalived,从而实现将故障机器踢出(因每台机器上keepalived只添加了本机为realserver).
当 mysqld 正常启动起来后,要手动启动keepalived服务。#mkdir /etc/keepalived/bin
vi /etc/keepalived/bin/mysql.sh,内容如下:
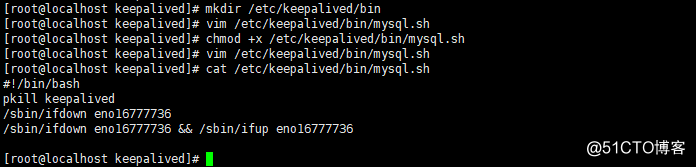
4、测试
在 master 和slave分别执行ipaddr show dev eno16777736命令查看master和slave对VIP
(群集虚拟 IP)的控制权。
Master1 主的查看结果:

Slave查看结果 并在master停止mysql查看IP地址是否飘逸
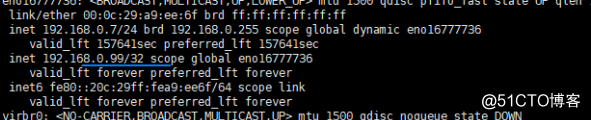
总结:
Keepalived+mysql 双主一般来说,中小型规模的时候,采用这种架构是最省事的。
在 master 节点发生故障后,利用keepalived的高可用机制实现快速切换到备用节点。
在这个方案里,有几个需要注意的地方:
1.采用keepalived作为高可用方案时,两个节点最好都设置成BACKUP模式,避免因为意外
情况下(比如脑裂)相互抢占导致往两个节点写入相同数据而引发冲突;
2.把两个节点的auto_increment_increment(自增步长)和auto_increment_offset(自增起
始值)设成不同值。其目的是为了避免 master 节点意外宕机时,可能会有部分binlog未能
及时复制到 slave 上被应用,从而会导致slave新写入数据的自增值和原先master上冲突了,
因此一开始就使其错开;当然了,如果有合适的容错机制能解决主从自增 ID 冲突的话,也可以不这么做;
3.slave 节点服务器配置不要太差,否则更容易导致复制延迟。作为热备节点的slave服务器,
硬件配置不能低于 master 节点;
4.如果对延迟问题很敏感的话,可考虑使用MariaDB分支版本,或者直接上线MySQL 5.7最
新版本,利用多线程复制的方式可以很大程度降低复制延迟;

