
- 1TUM数据集官方说明&&相应的评估文件evaluate_rpe.py和evaluate_ate.py的使用
- 2B2N给互联网商业模式注入新活力
- 3解决Pycharm出现的Debug无法正常运行(Frames are not available)的问题
- 4单片机、DSP、ARM、FPGA,它们都能干什么_fpga和arm,2024年最新斗鱼直播Golang开发二面被刷_控制方案 单片机 fpga dsp
- 5Node-导入导出/npm/包/Express - 框架/同源策略/解决跨域_npm时候ecmascript导入
- 6HDLBits练习(二)Verilog Language_Basics_fpga用assign语句写一个非门
- 7零基础如何学习自动化测试_自动化测试自学教程
- 814岁的钢铁之心
- 9计算机专业论文没有实验怎么发,计算机专业的毕业论文参考文献怎么写
- 10深信服二面总结_深信服外包二面
文生图算法原理:从扩散模型到Stable Diffusion_文生图学习路线
赞
踩
导读
Stable Diffusion是扩散模型的一种实现。传统的扩散模型(如DDPM)的做法是在像素空间预测预测噪声图noise_t,输入是每一步的图片image_t和代表step的Time embedding,然后在图片image_t上减去模型预测的噪声noise_t,得到image_t-1,如此迭代N步,即可得到可识别的图片。
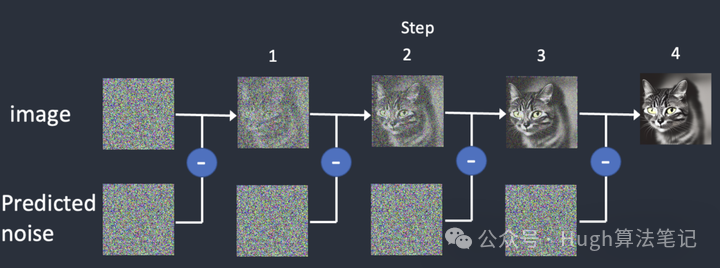
Stable Diffusion算法原理
但由于直接在图像上做diffusion的搜索空间太大,导致模型生成速度慢,且生成图像不可控,所以Latent Diffusion Model通过引入Cross Attention和隐空间机制,提升了模型的效率和可控性。
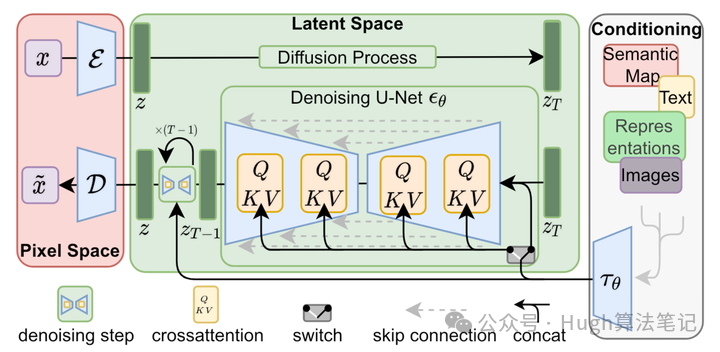
Stable Diffusion(后文简称SD)是在LDM基础上,由CompVis(LDM模型)、Stability AI(计算资源)和LAION(数据)等公司研发的一个文生图模型。由于SD的图片效果好、开源性强(模型、训练数据均开源),参数量小(仅1B左右,可以用消费级显卡调用),由此形成了良好的社区生态,推动了AIGC社区的蓬勃发展。
Diffusion Model(DDPM为例)

Stable Diffusion算法原理
前向扩散(Forward Diffusion,固定参数)
-
向训练图像添加噪声,逐渐将其变成无法分辨的噪声图像(like 墨水滴入水中扩散)
-
假设(DDPM):添加噪声是马尔科夫链,并符合一定预设参数(详见拓展阅读)

反向扩散(Reverse Diffusion,学习)
- 反向预测每一步添加的Noise,逐步给图片去噪
连续从图像中减去预测的噪声
噪声预测器(Noise Predictor)
-
作用:预测每个Step添加的噪声,它的结构是一个U-Net,
-
下面是DDPM的模型结构示意图
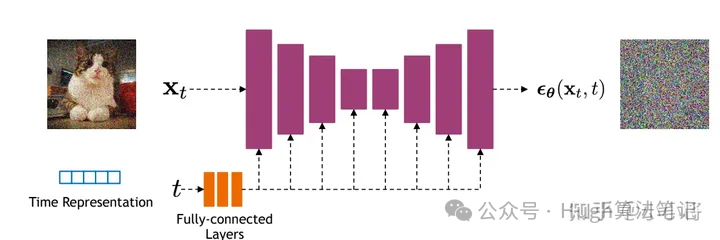
输入为图片和step对应的time embedding,输出为该step的噪声,采用MSE拟合
-
训练数据:纯图像
-
训练:训练图进行t步扩散,得到噪声图像x_t,将t和x_t输入U-Net,输出预测noise与真实Noise做MSE训练
-
预测:输入随机噪声图,根据step和噪声图进行反向迭代去噪
Noise schedule

15个step的Noise Schedule
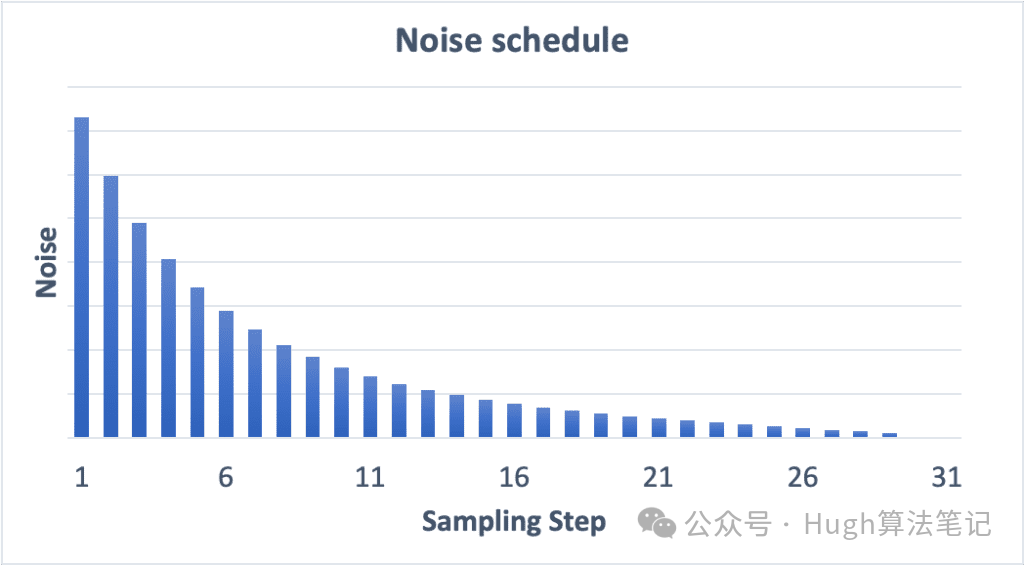
30个step的Noise Schedule
-
噪声值:类似步长,代表每个step减去的noise的尺度大小
-
规律:噪声在第一步最高,在最后一步逐渐降至零。
-
增加采样步数作用:每个步骤之间的噪音降低幅度较小,有助于减少采样的截断误差。
-
详见:https://stable-diffusion-art.com/samplers/
局限性
-
大&慢:由于在像素空间推理(512*512*3),导致模型搜索空间很大,且耗时很长(DDPM需要推理1000步)
-
无控制:只能拟合数据集中的图片分布随机生成图片,无法通过文本控制生成图片

DDPM生成样例(unconditioned,即只能随机拟合数据集分布,无法控制生成)
Latent Diffusion Models
为了解决上述提到的两个问题,LDM通过引入VAE和Conditioning机制,训练数据从DDPM的纯图片数据,变成了图文数据对,使模型可以用消费级显卡在10s内生成图像,同时在生成图像的质量、速度和可控性都上了一个台阶。下面来介绍一下模型结构,大致可分为下列几块:
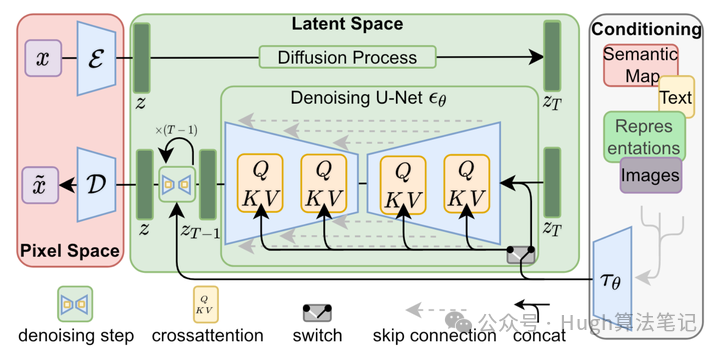
左侧红色为VAE,中间为Diffusion U-Net,右侧为Condition Encoder
VAE
-
作用:将图像转换到Latent Space,并从Latent Space进行恢复
-
结构:全卷积结构(基于ResnetBlock,中间存在两个self attention层)
-
Encoder:将图像压缩到Latent Space
-
Decoder:将Latent Matrix恢复为图片

VAE将图片转换为Latent Embedding,再恢复到图片
-
正则化方法:KL-reg和VQ-reg,SD采用了AutoencoderKL实现
-
压缩率f = H/h = W/w
-
可以看到过小的f(比如1和2)下收敛速度慢,此时图像的感知压缩率较小,扩散模型需要较长的学习;而过大的f其生成质量较差,此时压缩损失过大。
-
f在4~16时,可以取得相对好的效果

不同压缩率下的重构指标(左边越低越好,右边越高越好)
U-Net
- 结构:Time-conditional U-Net

U-Net结构,黄色代表Cross-Attention Block
-
z为latent space表示,z_T类比DDPM中的噪声图像
-
黄色部分为cross-attention block
-
每次迭代得到latent space的预测噪声,迭代T次
-
训练&推理:和像素空间DDPM类似,在Latent Space对latent matrix进行denoise
-
好处:Pixel Space(512*512*3)到Latent Space(64*64*4,Stable Diffusion),仅为原来的1/48
Conditioning 通过引入Cross Attention的机制,使得模型生成图片变得可控,具体实现如下:
- 引入Domain Specific Encoder(左图右侧):如Clip-text Encoder,对控制模态进行编码τ

控制模态输入cross attention block
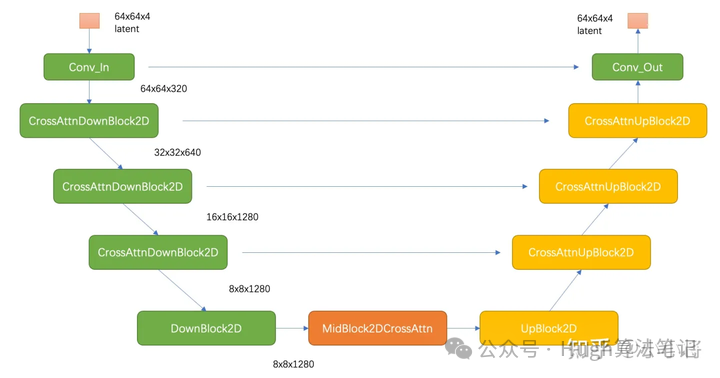
U-Net的Block,包含shortcut和cross attention,by虎哥
- 对latent Space的输入进行Cross Attention

query是隐向量,key和value都是控制模态τ
效果
VAE效果对比

Reconstruction FIDs and PSNR
文本控制生成效果

添加图片注释,不超过 140 字(可选)
Stable Diffusion训练相关
特指(v1)
自动编码器下采样因子为8,UNet大小为860M,文本编码器为CLIP ViT-L/14的LDM
autoencoder为84M,CLIP text encoder 为123M,UNet为860M,总参数量~1B
数据集:Laion-2B-en
Laion 5B介绍
通过CommonCrawl获取文本和图片,OpenAI的CLIP计算后获取图像和文本的相似性,并删除相似度低于设定阈值的图文对(英文阈值0.28,其余阈值0.26),500亿图片保留了不到60亿,最后形成58.5亿个图文对,包括23.2亿的英语(Laion-2B-en),22.6亿的100+语言及12.7亿的未知语言。
训练细节
不同版本
-
SD v1.1
-
在laion2B-en数据集上以256x256大小训练237,000步,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
-
SD v1.2
-
以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
-
SD v1.3
-
以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
-
SD v1.4
-
以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
-
SD v1.5(社区最多)
-
以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数。
训练设备
采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs),单卡的训练batch size为2,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x2=2048。训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间,文档上只说了用了150,000小时,这个应该是A100卡时,如果按照256卡A100来算的话,那么大约需要训练25天左右。
Stable Diffusion推理相关
文生图

by小小将
推理步骤
-
输入text用text encoder提取text embeddings
-
同时初始化一个随机噪音noise(latent上的,512x512图像对应的noise维度为64x64x4)
-
将text embeddings和noise送入扩散模型UNet中生成去噪后的latent
-
送入autoencoder的decoder模块得到生成的图像
推理参数
-
Size:最好与模型训练时长宽一致(512*512),否则生成效果较为奇怪
-
num_steps:去噪步数/采样步数,不同步数生成效果不同,与Sampler也有关系
-
Negative Prompt:见下文CFG
图生图
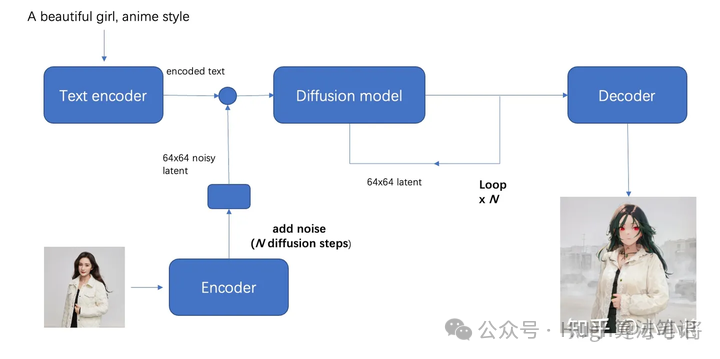
by小小将
-
步骤:初始图像经过autoencoder编码之后的latent加高斯噪音得到,其余步骤与文生图一致
-
参数strength:表示加噪声的程度,越大加的噪音越多(0-1)
图像Inpainting
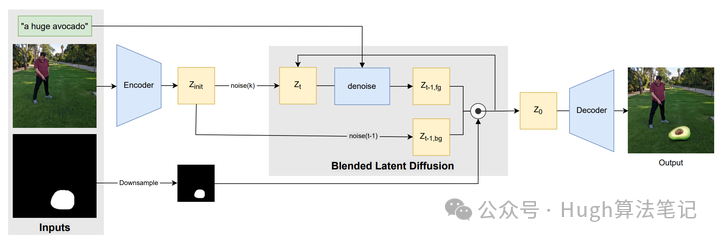
见Blended Latent Diffusion
-
为了保证mask以外的区域不发生变化,在去噪过程的每一步,都将扩散模型预测的noisy latent用真实图像同level的nosiy latent替换,其余步骤与图生图一样
-
原理参考Blended Latent Diffusion:https://arxiv.org/abs/2206.02779
其他重点
Classifier-Free Guidance(CFG)
训练
在训练条件扩散模型的同时也训练一个无条件的扩散模型(如:按10%的比例随机置空text)
预测
在采样阶段将条件控制下预测的噪音和无条件下的预测噪音组合在一起来确定最终的噪音

添加图片注释,不超过 140 字(可选)
这里w为guidance scale,越大时,condition起的作用越大,即生成的图像其更和输入文本一致,一般默认为7.5
Negative Prompt
有Negative时,CFG模型的输入为Negative Prompt,相当于把Prompt里带有neg Prompt的噪声减去
没有Negative Prompt时,CFG的输入为""
推理代码示例
-
diffuser代码:https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py#L1002-L1019
-
推理的时候是把neg_prompt和pos_prompt给concat起来,过同一个unet
Webui Recap
不同版本SD对比(By GPT-4)
Version | Release Date | U-Net Parameters | Text Encoder | Training Dataset | Resolution | Training Steps & Details | Notes |
1 | 860 million | CLIP ViT-L/14 | LAION-5B subsets | 512x512 | - | Initial release | |
1.4 | August 2022 | - | - | LAION-5B subsets | - | - | |
1.5 | October 2022 | - | - | LAION-5B subsets | - | - | |
2 | Nov 2022 | 865 million | OpenCLIP-ViT/H | LAION-5B subsets | 768x768 | Trained from scratch using 256 Nvidia A100 GPUs for a total of 150,000 GPU-hours, cost of $600,000 | Introduced OpenCLIP-ViT/H text encoder |
2.1 | Dec 2022 | - | - | LAION-5B subsets | 768x768/512x512 | Fine-tuned on 2.0 with a less restrictive NSFW filtering of LAION-5B | Both 768x768 and 512x512 versions available |
unclip | March 2023 | - | - | - | - | 实现单个图像的变换,有L和H两个版本 | |
XL 1.0 | July 2023 | 2.6 billion | OpenCLIP-ViT/H | LAION-5B subsets | 1024x1024 | - | 重新训练VAE |
AI绘画SD整合包、各种模型插件、GPT人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

