
- 1【AIGC】CPM-BEE 开源大模型介绍、部署以及创建接口服务_cpm大模型体验
- 2软件工程之软件项目管理_软件工程进行有效的项目管理
- 3Mysql锁定表/解锁句法_mysql锁表和解锁语句
- 4国内流行的vps免费管理面板推荐_vps面板推荐
- 5python done函数_python-函数进阶
- 6技术巨头背后的面试艺术与成功之道 --- 华为OD机试:围棋的气(Python & C & C++ & Java&Go & JS & PHP)_围棋的气华为od
- 7ajax请求可以在后端跳转到其他页面吗_Spring Boot2 系列教程(三十八)Spring Security 非法请求直接返回 JSON...
- 8Git 代码协同的使用方法 for Azure DevOps_azure data studio 链接git
- 9ORB-SLAM配置和安装(自保存用)ORB_SLAM3-0.4-beta版本_orbslam3 0.4 和1
- 10子分支想主分支发起合并请求
首个基于Mamba的MLLM来了!模型权重、训练代码等已全部开源_manba nlp模型 csdn
赞
踩
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注

近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显著的成功。然而,作为许多下游任务的基础模型,当前的 MLLM 由众所周知的 Transformer 网络构成,这种网络具有较低效的二次计算复杂度。为了提高这类基础模型的效率,大量的实验表明:(1)Cobra 与当前计算效率高的最先进方法(例如,LLaVA-Phi,TinyLLaVA 和 MobileVLM v2)具有极具竞争力的性能,并且由于 Cobra 的线性序列建模,其速度更快。(2)有趣的是,封闭集挑战性预测基准的结果显示,Cobra 在克服视觉错觉和空间关系判断方面表现良好。(3)值得注意的是,Cobra 甚至在参数数量只有 LLaVA 的 43% 左右的情况下,也取得了与 LLaVA 相当的性能。
大语言模型(LLMs)受限于仅通过语言进行交互,限制了它们处理更多样化任务的适应性。多模态理解对于增强模型有效应对现实世界挑战的能力至关重要。因此,研究人员正在积极努力扩展大型语言模型,以纳入多模态信息处理能力。视觉 - 语言模型(VLMs)如 GPT-4、LLaMA-Adapter 和 LLaVA 已经被开发出来,以增强 LLMs 的视觉理解能力。
然而,先前的研究主要尝试以类似的方法获得高效的 VLMs,即在保持基于注意力的 Transformer 结构不变的情况下减少基础语言模型的参数或视觉 token 的数量。本文提出了一个不同的视角:直接采用状态空间模型(SSM)作为骨干网络,得到了一种线性计算复杂度的 MLLM。此外,本文还探索和研究了各种模态融合方案,以创建一个有效的多模态 Mamba。具体来说,本文采用 Mamba 语言模型作为 VLM 的基础模型,它已经显示出可以与 Transformer 语言模型竞争的性能,但推理效率更高。测试显示 Cobra 的推理性能比同参数量级的 MobileVLM v2 3B 和 TinyLLaVA 3B 快 3 倍至 4 倍。即使与参数数量更多的 LLaVA v1.5 模型(7B 参数)相比,Cobra 仍然可以在参数数量约为其 43% 的情况下在几个基准测试上实现可以匹配的性能。

图 Cobra 和 LLaVA v1.5 7B 在生成速度上的 Demo
本文的主要贡献如下:
-
调查了现有的多模态大型语言模型(MLLMs)通常依赖于 Transformer 网络,这表现出二次方的计算复杂度。为了解决这种低效问题,本文引入了 Cobra,一个新颖的具有线性计算复杂度的 MLLM。
-
深入探讨了各种模态融合方案,以优化 Mamba 语言模型中视觉和语言信息的整合。通过实验,本文探索了不同融合策略的有效性,确定了产生最有效多模态表示的方法。
-
进行了广泛的实验,评估 Cobra 与旨在提高基础 MLLM 计算效率的并行研究的性能。值得注意的是,Cobra 甚至在参数更少的情况下实现了与 LLaVA 相当的性能,突显了其效率。

-
原文链接:https://arxiv.org/pdf/2403.14520v2.pdf
-
项目链接:https://sites.google.com/view/cobravlm/
-
论文标题:Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference
方法介绍
模型架构
Cobra 采用了经典的视觉编码器、连接两个模态的投影器和 LLM 语言主干组成的 VLM 结构。LLM 主干部分采用了 2.8B 参数预训练的 Mamba 语言模型,该模型在 600B token 数量的 SlimPajama 数据集上进行了预训练并经过了对话数据的指令微调。
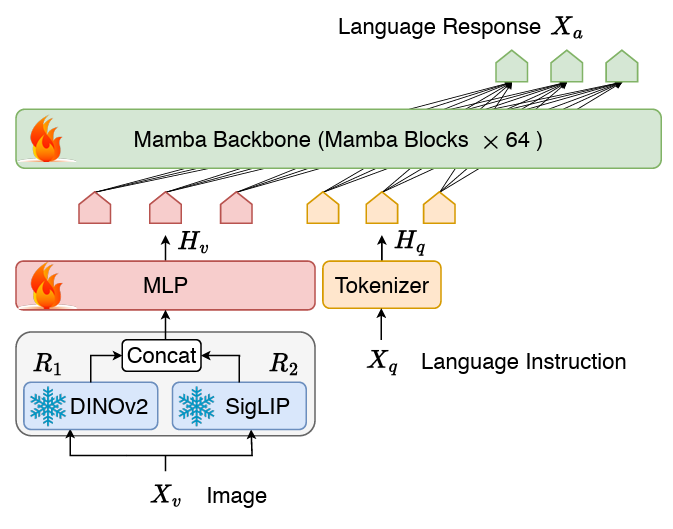
图 Cobra 网络结构图
与 LLaVA 等工作不同的是,Cobra 采用了 DINOv2 和 SigLIP 融合的视觉表征,通过将两个视觉编码器的输出拼接在一起送入投影器,模型能够更好的捕捉到 SigLIP 带来的高层次的语义特征和 DINOv2 提取的低层次的细粒度图像特征。
训练方案
最近的研究表明,对于基于 LLaVA 的现有训练范式(即,只训练投影层的预对齐阶段和 LLM 骨干的微调阶段各一次),预对齐阶段可能是不必要的,而且微调后的模型仍处于欠拟合状态。因此,Cobra 舍弃了预对齐阶段,直接对整个 LLM 语言主干和投影器进行微调。这个微调过程在一个组合数据集上随机抽样进行两个周期,该数据集包括:
-
在 LLaVA v1.5 中使用的混合数据集,其中包含总计 655K 视觉多轮对话,包括学术 VQA 样本,以及 LLaVA-Instruct 中的视觉指令调优数据和 ShareGPT 中的纯文本指令调优数据。
-
LVIS-Instruct-4V,其中包含 220K 张带有视觉对齐和上下文感知指令的图片,这些指令由 GPT-4V 生成。
-
LRV-Instruct,这是一个包含 400K 视觉指令数据集,覆盖了 16 个视觉语言任务,目的是减轻幻觉现象。
整个数据集大约包含 120 万张图片和相应的多轮对话数据,以及纯文本对话数据。
实验
定量实验
实验部分,本文对提出的 Cobra 模型和开源的 SOTA VLM 模型在基础 benchmark 上进行了比较,并对比了与同量级基于 Transformer 架构的 VLM 模型的回答速度。
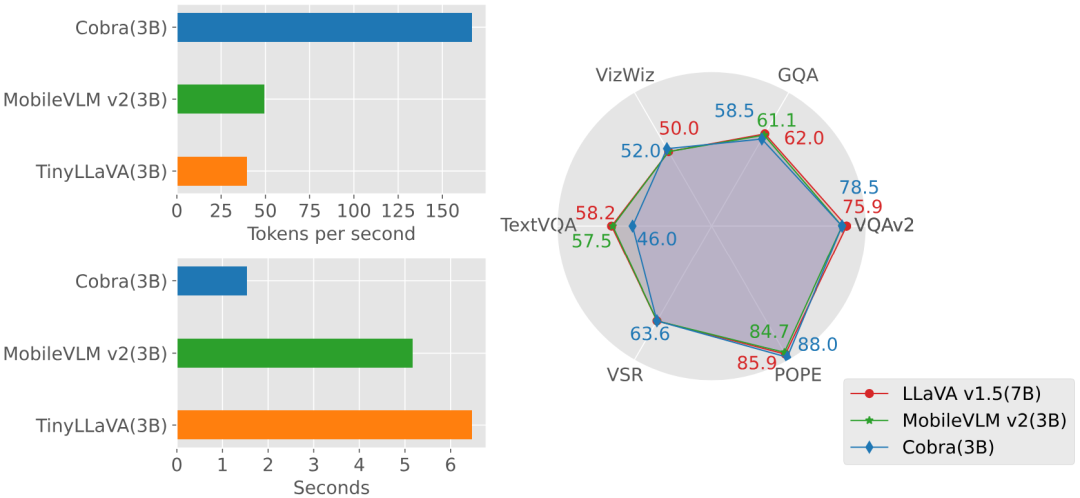
图 生成速度和性能对比图
同时,Cobra 也与更多的模型在 VQA-v2,GQA,VizWiz,TextVQA 四个开放 VQA 任务以及 VSR,POPE 两个闭集预测任务,共 6 个 benchmark 上进行了分数对比。
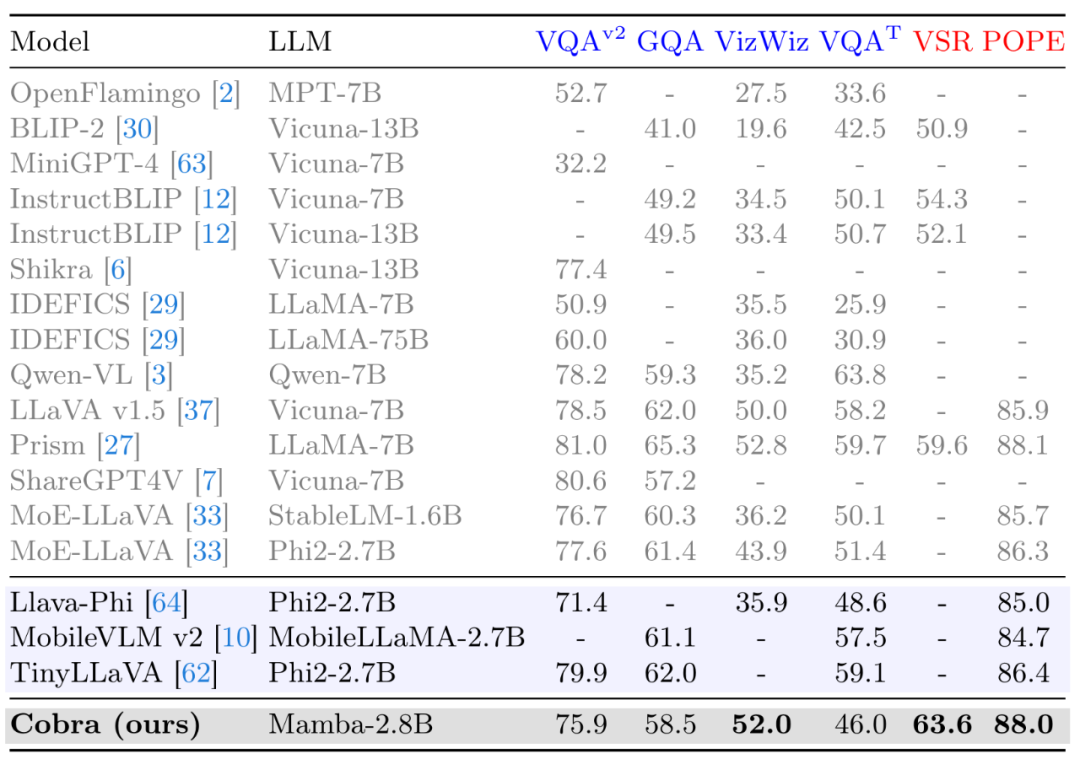
图 在 Benchmark 上和其他开源模型的对比
定性试验
此外 Cobra 也给出了两个 VQA 示例以定性说明 Cobra 在物体的空间关系认知和减轻模型幻觉两个能力上的优越性。

图 Cobra 和其他基线模型在物体空间关系判断的示例

图 Cobra 和其他基线模型在关于视觉错觉现象的示例
在示例中,LLaVA v1.5 和 MobileVLM 均给出了错误答案,而 Cobra 则在两个问题上都做出了准确的描述,尤其在第二个实例中,Cobra 准确的识别出了图片是来自于机器人的仿真环境。
消融实验
本文从性能和生成速度这两个维度对 Cobra 采取的方案进行了消融研究。实验方案分别对投影器、视觉编码器、LLM 语言主干进行了消融实验。
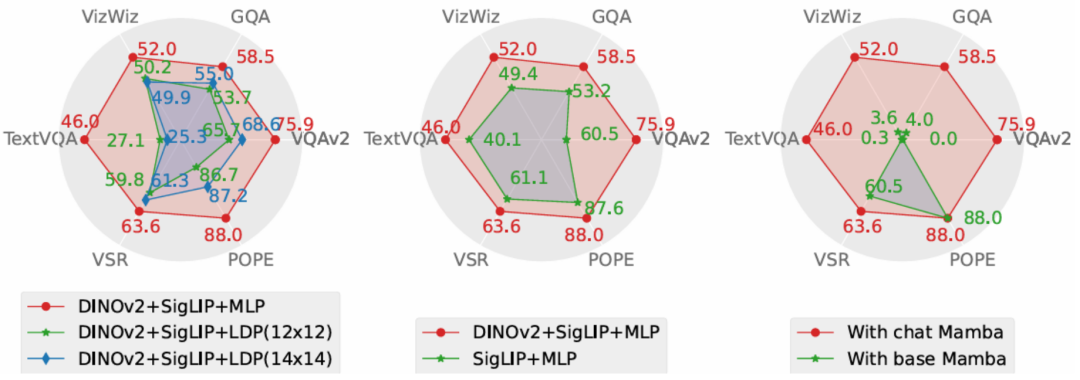
图 消融实验的性能对比图
投影器部分的消融实验结果显示,本文采取的 MLP 投影器在效果上显著优于致力于减少视觉 token 数量以提升运算速度的 LDP 模块,同时,由于 Cobra 处理序列的速度和运算复杂度均优于 Transformer,在生成速度上 LDP 模块并没有明显优势,因此在 Mamba 类模型中使用通过牺牲精度减少视觉 token 数量的采样器可能是不必要的。

图 Cobra 和其他模型在生成速度上的数值对比
视觉编码器部分的消融结果表明,DINOv2 特征的融合有效的提升了 Cobra 的性能。而在语言主干的实验中,未经过指令微调的 Mamba 语言模型在开放问答的测试中完全无法给出合理的答案,而经过微调的 Mamba 语言模型则可以在各类任务上达到可观的表现。
结论
本文提出了 Cobra,它解决了现有依赖于具有二次计算复杂度的 Transformer 网络的多模态大型语言模型的效率瓶颈。本文探索了具有线性计算复杂度的语言模型与多模态输入的结合。在融合视觉和语言信息方面,本文通过对不同模态融合方案的深入研究,成功优化了 Mamba 语言模型的内部信息整合,实现了更有效的多模态表征。实验表明,Cobra 不仅显著提高了计算效率,而且在性能上与先进模型如 LLaVA 相当,尤其在克服视觉幻觉和空间关系判断方面表现出色。它甚至显著减少了参数的数量。这为未来在需要高频处理视觉信息的环境中部署高性能 AI 模型,如基于视觉的机器人反馈控制,开辟了新的可能性。
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
更多资源欢迎关注

