
- 1大数据的岗位职责,我们未来的大数据职业选择有哪些
- 2oracle sql developer 字符集,ORACLE pl/sqldeveloper 客戶端亂碼--修改Oracle客戶端字符集...
- 3idea 项目误删文件or拉取别人代码时未提交代码被覆盖怎么恢复_idea未提交代码找回
- 4Python 多线程编程-06-threading 模块 - Timer_threading.timer
- 5ubuntu neo4j单机安装和集群环境安装_java内嵌式开发neo4j支持集群模式吗
- 6woyundaole_error:(11, 30) java: 程序包com.cloudera.sqoop.lib不存在
- 7涨点利器:推荐系统中对双塔模型的各种改造升级(上)
- 8Vue2.5学习笔记(二)深入了解组件_vue2.5获取组件实例
- 9内存管理之连续-非连续内存分配方式_iceoryx 内存管理是连续还是非连续
- 10Java 反射机制 -- Java 语言反射的概述、核心类与高级应用
最新【ES专题】ElasticSearch集群架构剖析_es集群(3),2024年最新大数据开发常见面试题知乎_es 3集群搭建
赞
踩
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
1.2 ES集群核心概念
ES集群中有2个比较核心的概念需要理解一下。分别是:节点、分片。在聊这些概念之前,我们先重新梳理一下,ES的集群是什么。
ES的集群,亦上图所示,它通常由如下特征:
- 集群中有一个或者多个节点
- 不同的集群通过不同的名字来区分,默认名字【elasticsearch】
注意:ES在实际生产环境中,还会部署多个集群一起工作
- 通过配置文件修改,或者在命令行中
-E cluster.name=es-cluster进行设定
1.2.1 节点
ES中的节点本质上是一个Elasticsearch的实例,一个Java进程。通常,我们建议生产环境中,一台机器只运行一个ES实例。(一台机器部署多个节点,其实是违背【高可用】原则的)
ES节点有如下特性:
- 每一个节点都有名字,通过配置文件配置,或者启动时候
-E node.name=node1指定 - 每一个节点在启动之后,会分配一个UID,保存在data目录下
- 节点有多种角色(类型),不同角色通常有不同的功能,它们分别是:
Master Node:主节点,负责索引的删除创建Master eligible nodes:【直译:符合条件的节点】。可以参与选举的合格节点Data Node:数据节点,负责文档的写入、读取。节点保存数据并执行与数据相关的操作,如CRUD、搜索和聚合Coordinating Node:协调节点- 其他节点
通过ES多角色定义可以看的出来,ES的集群架构非常成熟,它也是我目前见过的角色最丰富的架构。如此丰富的角色定义,肯定是为了拓展集群架构而生的,单一职责嘛。不过有一点我没想通的是,如果节点太多了,做一次CRUD的速度能快吗?会不会在通信上就花费了很多时间。
节点类型,可以通过如下配置参数禁用/启用
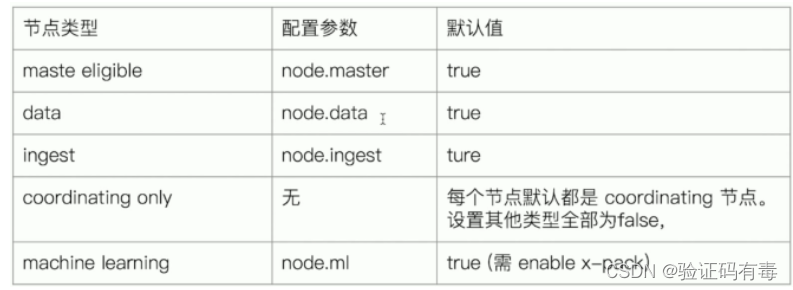
关于Master eligible nodes和Master Node
- 每个节点启动后,默认就是一个Master eligible节点,即都可以参与集群选举,成为Master节点。可以通过
node.mater=false禁止 - 当第一个节点启动时候,它会将自己选举成Master节点
- 每个节点上都保存了集群的状态,但是只有Master节点才能修改集群的状态信息。集群状态信息(Cluster State) 维护了一个集群中所有必要的信息。比如:
- 所有节点信息
- 所有的索引和其他相关的Mapping与Setting信息
- 分片的路由信息
关于Data Node 和 Coordinating Node
- Data Node:
- 可以保存数据的节点,叫做Data Node,负责保存分片数据。在数据扩展上起到了至关重要的作用
- 节点启动后,默认就是数据节点。可以设置
node.data: false禁止 - 由Master Node决定如何把分片分发到数据节点上
- 通过增加数据节点可以解决数据水平扩展和解决数据单点问题
- Coordinating Node:
- 负责接受Client的请求, 将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了Coordinating Node的职责
其他节点类型
Hot & Warm Node:冷热节点。不同硬件配置 的Data Node,用来实现Hot & Warm架构,降低集群部署的成本
不同硬件配置,通常是CPU跟硬盘。硬盘根据冷热数据类型,可以选择固态或者机械硬盘
Ingest Node:数据前置处理转换节点,支持pipeline管道设置,可以使用ingest对数据进行过滤、转换等操作Machine Learning Node:负责跑机器学习的Job,用来做异常检测Tribe Node:Tribe Node连接到不同的Elasticsearch集群,并且支持将这些集群当成一个单独的集群处理
以下是一个多集群业务架构图:

1.2.1.1 Master Node主节点的功能
Master节点主要功能::
- 管理索引和分片的创建、删除和重新分配
- 监测节点的状态,并在需要时进行重分配
- 协调节点之间的数据复制和同步工作
- 处理集群级别操作,如创建或删除索引、添加或删除节点等
- 维护集群的状态
1.2.1.2 Data Node数据节点的功能
Data Node数据节点的功能:
- 存储和索引数据:Data Node 节点会将索引分片存储在本地磁盘上,并对查询请求进行响应
- 复制和同步数据:为了确保数据的可靠性和高可用性,ElasticSearch 会将每个原始分片的多个副本存储在不同的 Data Node 节点上,并定期将各节点上的数据进行同步
- 参与搜索和聚合操作:当客户端提交搜索请求时,Data Node 节点会使用本地缓存和分片数据完成搜索和聚合操作
- 执行数据维护操作:例如,清理过期数据和压缩分片等
官方定义:
数据节点保存包含您已索引的文档的分片。数据节点处理数据相关操作,例如 CRUD、搜索和聚合。这些操作是 I/O、内存和 CPU 密集型操作。监视这些资源并在过载时添加更多数据节点非常重要。
拥有专用数据节点的主要好处是主角色和数据角色的分离。
要创建专用数据节点,请设置:node.roles: [ data ]
在多层部署体系结构中,您可以使用专门的数据角色将数据节点分配到特定层:data_content、data_hot、data_warm、data_cold或data_frozen。一个节点可以属于多个层,但具有专用数据角色之一的节点不能具有通用data角色。
1.2.1.3 Coordinate Node协调节点的功能
官方定义:
诸如搜索请求或批量索引请求之类的请求,它们可能涉及不同数据节点上保存的数据。例如,搜索请求分两个阶段执行,这两个阶段由接收客户端请求的节点(协调节点)协调。
- 在分散阶段,协调节点将请求转发到保存数据的数据节点。每个数据节点在本地执行请求并将其结果返回给协调节点
- 在收集阶段,协调节点将每个数据节点的结果缩减为单个全局结果集
每个节点都是隐式的协调节点。这意味着具有显式空角色列表的节点node.roles将仅充当协调节点,无法禁用。因此,这样的节点需要有足够的内存和 CPU 才能处理收集阶段。
1.2.1.4 Ingest Node协调节点的功能
官方定义:
在实际的文档索引发生之前,使用摄取节点对文档进行预处理。摄取节点拦截批量和索引请求,应用转换,然后将文档传递回索引或批量api。
默认情况下,所有节点都启用摄取,因此任何节点都可以处理摄取任务。您还可以创建专用的摄取节点。如果要禁用节点的摄取,请在elasticsearch. conf中配置以下配置。yml文件:node.ingest: false
要在索引之前对文档进行预处理,请定义一个指定一系列处理器的管道。每个处理器都以某种特定的方式转换文档。例如,管道可能有一个处理程序从文档中删除字段,然后有另一个处理程序重命名字段。然后,集群状态存储配置的管道。
要使用管道,只需在索引或批量请求上指定pipeline参数。这样,摄取节点就知道要使用哪个管道。例如:
PUT my-index/my-type/my-id?pipeline=my_pipeline_id
{
"foo": "bar"
}
- 1
- 2
- 3
- 4
- 5
1.2.1.5 其他节点功能
其他节点相对来说使用的比较少,不做介绍了
1.2.1.6 Master Node主节点选举流程
ES的选举流程也很简单,如下:
- 通常集群启动时,第一个启动的节点会被选为主节点。当主节点挂了的时候,进行下一步
- 互相Ping对方,Node ld 低的会成为被选举的节点
- 其他节点会加入集群,但是不承担Master节点的角色。一旦发现被选中的主节点丢失,就会重新选举出新的Master节点
在我们的生产过程中,Master Node的最佳实践方案
- Master节点非常重要,在部署上需要考虑解决单点的问题
- 为一个集群设置多个Master节点,每个节点只承担Master 的单一角色
1.2.2 分片
分片是ES中一个比较重要的概念。ElasticSearch是一个分布式的搜索引擎,索引可以分成一份或多份,多份分布在不同节点的分片当中。ElasticSearch会自动管理分片,如果发现分片分布不均衡,就会自动迁移。
分片又有【主分片】、【副本分片】之分。它们的区别如下:
- 主分片(Primary Shard)
- 用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的Lucene的实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
- 副本分片
- 用以解决数据高可用的问题。 副本分片是主分片的拷贝(备份)
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
# 指定索引的主分片和副本分片数
PUT /csdn_blogs
{
"settings": {
"number\_of\_shards": 3,
"number\_of\_replicas": 1
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
分片架构
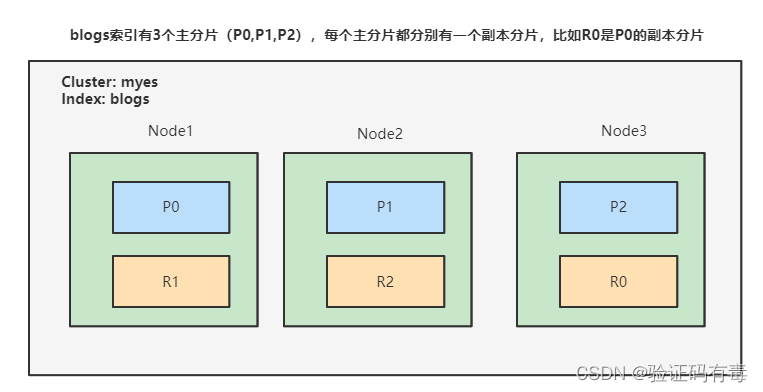
如上图是某个集群的分片架构,它有如下特征:
- 集群中有3个节点
通常都是奇数,所谓【集群奇数法则】。但其实只是名字很唬人,本质上也没那么神奇。你自己想想,如果是偶数的话,是不是很有可能出现选举平票的时候?根据我的经验,选举算法通常都希望快速选举一个master或者leader出来,以便能够快速提供服务,所以没空扯皮
- 每个节点各有一个主副分片
高可用之——故障转移
- 主副分片之间交叉存储(
node1的副本放在node3,node2放在node1,node3放在node2)
使用【cat API查看集群信息】
- GET /_cat/nodes?v #查看节点信息
- GET /_cat/health?v #查看集群当前状态:红、黄、绿
- GET /_cat/shards?v #查看各shard的详细情况
- GET /_cat/shards/{index}?v #查看指定分片的详细情况
- GET /_cat/master?v #查看master节点信息
- GET /_cat/indices?v #查看集群中所有index的详细信息
- GET /_cat/indices/{index}?v #查看集群中指定index的详细信息 `
1.3 搭建三节点ES集群
1.3.1 ES集群搭建步骤
下面是在Linux环境,centos7下面的集群搭建步骤:
1)系统环境准备
首先创建用户,因为es不允许root账号启动
adduser es
passwd es
- 1
- 2
- 3
安装版本:elasticsearch-7.17.3。接着切换到root用户,修改/etc/hosts:
vim /etc/hosts
192.168.66.150 es-node1
192.168.66.151 es-node2
192.168.66.152 es-node3
- 1
- 2
- 3
- 4
- 5
2)修改elasticsearch.yml
注意配置里面的注释,里面有一些细节。比如:
- 注意集群的名字,3个节点的集群名称必须一直
- 给每个节点指定名字,比如这里是node1/2/3
- 是否要开启外网访问,跟redis的配置差不多
# 指定集群名称3个节点必须一致 cluster.name: es-cluster #指定节点名称,每个节点名字唯一 node.name: node-1 #是否有资格为master节点,默认为true node.master: true #是否为data节点,默认为true node.data: true # 绑定ip,开启远程访问,可以配置0.0.0.0 network.host: 0.0.0.0 #用于节点发现 discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"] #7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。 #该选项配置为node.name的值,指定可以初始化集群节点的名称 cluster.initial_master_nodes: ["node-1","node-2","node-3"] #解决跨域问题 http.cors.enabled: true http.cors.allow-origin: "\*"

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
三个节点配置很简单,按照上面的模板,依次修改node.name就行了
3) 启动每个节点的ES服务
# 注意:如果运行过单节点模式,需要删除data目录, 否则会导致无法加入集群
rm -rf data
# 启动ES服务
bin/elasticsearch -d
- 1
- 2
- 3
- 4
- 5
4)验证集群
正常来说,如果我们先启动了192.168.66.150,那么它就是这个集群当中的主节点,所以我们验证集群的话,只需要访问http://192.168.66.150:9200即可看到如下界面:
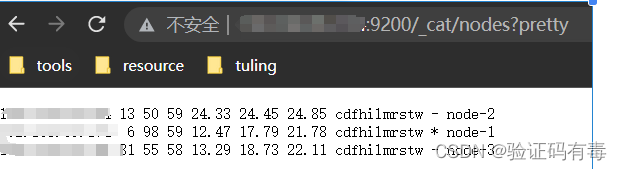
1.3.2 安装客户端
介绍完了ES的集群部署,我们再来看看ES客户端的部署。这里有两个可选方案,它们分别是Cerebro和Kibana,它们的区别与联系如下:
Cerebro和Kibana都是用于Elasticsearch的开源工具,但它们在功能和使用场景上存在一些区别。
功能:
- Cerebro:Cerebro是Elasticsearch的图形管理工具,可以查看分片分配和执行常见的索引操作,功能集中管理alias和index template,十分快捷。此外,Cerebro还具有实时监控数据的功能。
- Kibana:Kibana是一个强大的可视化工具,可以用于Elasticsearch数据的探索、分析和展示。它提供了丰富的图表类型,包括折线图、直方图、饼图等,可以方便地展示基于时间序列的数据。此外,Kibana还提供了日志管理、分析和展示的功能
使用场景:
- Cerebro:Cerebro适合用于生产和测试环境的Elasticsearch集群管理,尤其适用于需要快速查看和执行索引操作的情况。由于Cerebro轻量且适用于实时监控,它可能更适用于较小的集群和实时监控的场景。
- Kibana:Kibana适合对Elasticsearch数据进行深入的分析和探索,以及对日志进行管理和分析。它提供了丰富的可视化功能和灵活的数据展示方式,适用于各种规模的数据分析和监控场景。
Cerebro安装
Cerebro 可以查看分片分配和通过图形界面执行常见的索引操作,完全开源,并且它允许添加用户,密码或 LDAP 身份验证问网络界面。Cerebro 基于 Scala 的Play 框架编写,用于后端 REST 和 Elasticsearch 通信。 它使用通过 AngularJS 编写的单页应用程序(SPA)前端。
安装包下载地址如下:https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.zip
下载安装之后,用以下命令启动即可:
cerebro-0.9.4/bin/cerebro
#后台启动
nohup bin/cerebro > cerebro.log &
- 1
- 2
- 3
- 4
- 5
访问:http://192.168.66.150:9000/
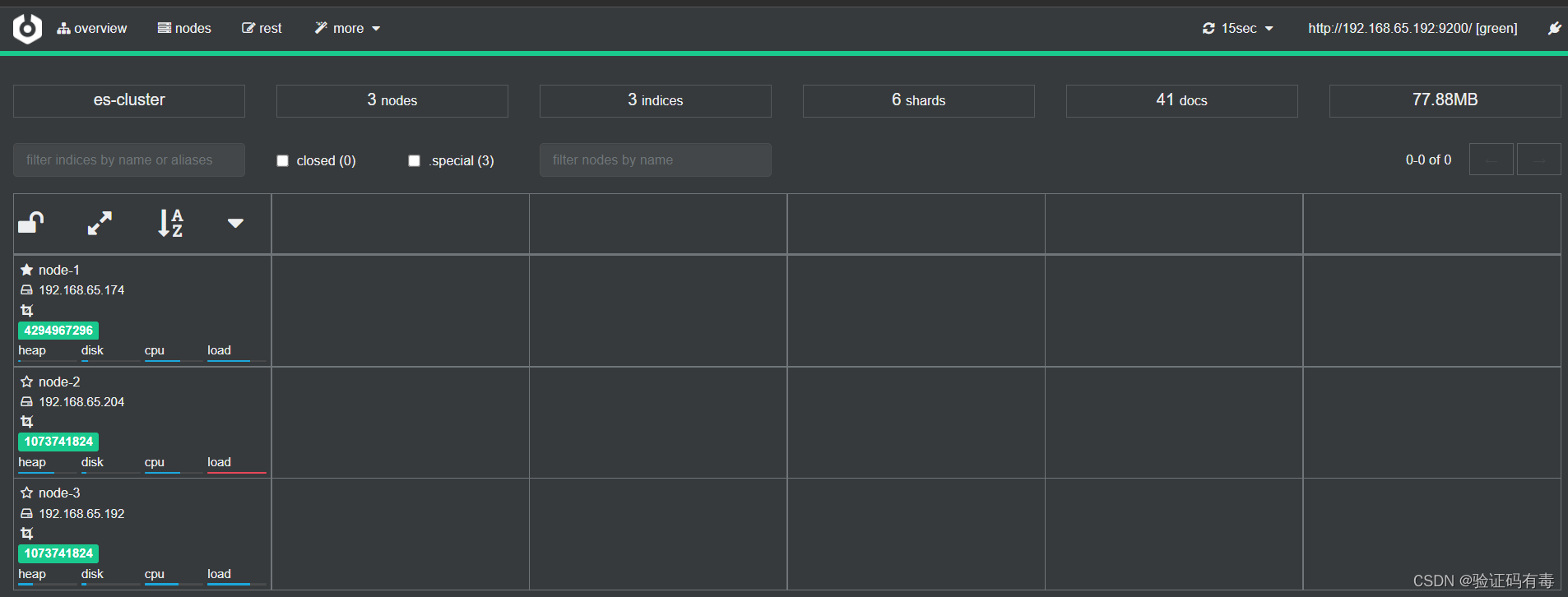
输入ES集群节点:http://192.168.66.150:9200,建立连接。然后会出现以下界面:
kibana安装
1)修改kibana配置
vim config/kibana.yml
server.port: 5601
server.host: "192.168.66.150"
elasticsearch.hosts: ["http://192.168.66.150:9200","http://192.168.66.151:9200","http://192.168.66.152:9200"]
i18n.locale: "zh-CN"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2)运行Kibana
#后台启动
nohup bin/kibana &
- 1
- 2
- 3
3)访问
访问http://192.168.66.150:5601/验证
二、生产环境最佳实践
2.1 一个节点只承担一个角色的配置
我们在上面的介绍中知道,节点有多种不同的类型(角色),有:Master eligible / Data / Ingest / Coordinating /Machine Learning等。不过跟之前学习的各种集群架构不同的是,ES一个节点可承担多种角色。
不过,在生产环境中尽量还是一个节点一种角色比较好,优点是:极致的高可用;缺点是:可能有点费钱
想要一个节点只承担一个角色,只需要修改如下配置:
#Master节点 node.master: true node.ingest: false node.data: false #data节点 node.master: false node.ingest: false node.data: true #ingest 节点 node.master: false node.ingest: true node.data: false #coordinate节点 node.master: false node.ingest: false node.data: false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.2 增加节点水平扩展场景
在实际生产中,我们可能会遇到需要水平扩展容量的场景,通常来说,以下是几个常见的场景:
- 当磁盘容量无法满足需求时,可以增加数据节点
- 磁盘读写压力大时,增加数据节点
- 当系统中有大量的复杂查询及聚合时候,增加Coordinating节点,增加查询的性能
2.3 异地多活架构
下面是一个多集群架构。集群处在三个数据中心,数据三写,使用GTM分发读请求
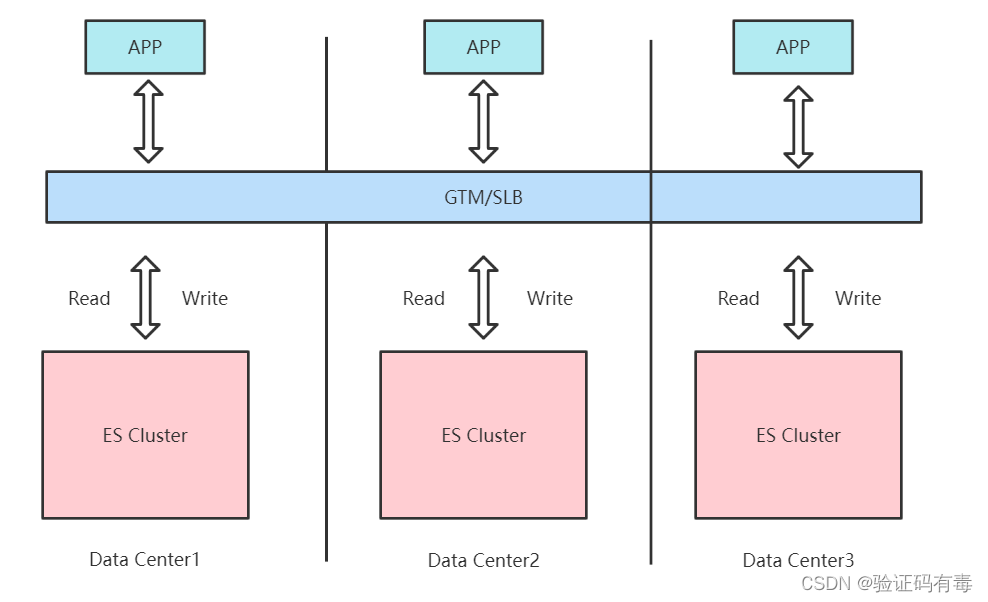
全局流量管理(GTM)和负载均衡(SLB)的区别:
GTM 是通过DNS将域名解析到多个IP地址,不同用户访问不同的IP地址,来实现应用服务流量的分配。同时通过健康检查动态更新DNS解析IP列表,实现故障隔离以及故障切换。最终用户的访问直接连接服务的IP地址,并不通过GTM。
而 SLB 是通过代理用户访问请求的形式将用户访问请求实时分发到不同的服务器,最终用户的访问流量必须要经过SLB。 一般来说,相同Region使用SLB进行负载均衡,不同region的多个SLB地址时,则可以使用GTM进行负载均衡。
2.4 Hot & Warm 架构
热节点存放用户最关心的热数据;温节点或者冷节点存放用户不太关心或者关心优先级低的冷数据或者暖数据。
它的典型的应用场景如下:
在成本有限的前提下,让客户关注的实时数据和历史数据硬件隔离,最大化解决客户反应的响应时间慢的问题。业务场景描述:每日增量6TB日志数据,高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
- ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储热数据,提升查询效率。
- 若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。
ES为什么要设计Hot & Warm 架构呢?
- ES数据通常不会有 Update操作;
- 适用于Time based索引数据,同时数据量比较大的场景。
- 引入 Warm节点,低配置大容量的机器存放老数据,以降低部署成本
两类数据节点,不同的硬件配置:
- Hot节点(通常使用SSD)︰索引不断有新文档写入。
- Warm 节点(通常使用HDD)︰索引不存在新数据的写入,同时也不存在大量的数据查询
Hot Nodes:用于数据的写入
- lndexing 对 CPU和IO都有很高的要求,所以需要使用高配置的机器
- 存储的性能要好,建议使用SSD
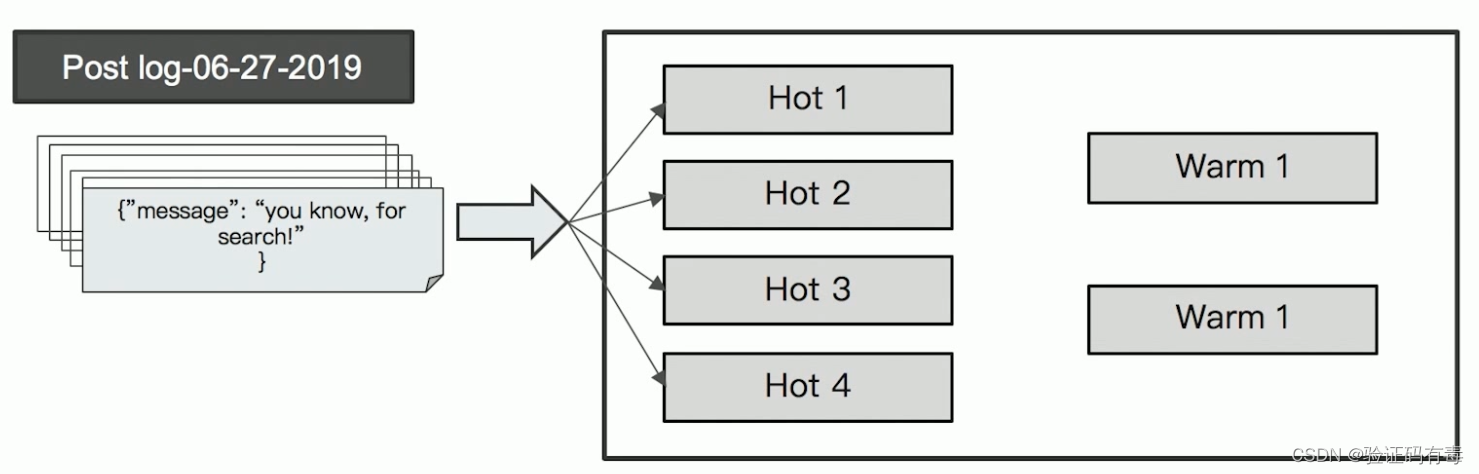
Warm Nodes
用于保存只读的索引,比较旧的数据。通常使用大容量的磁盘
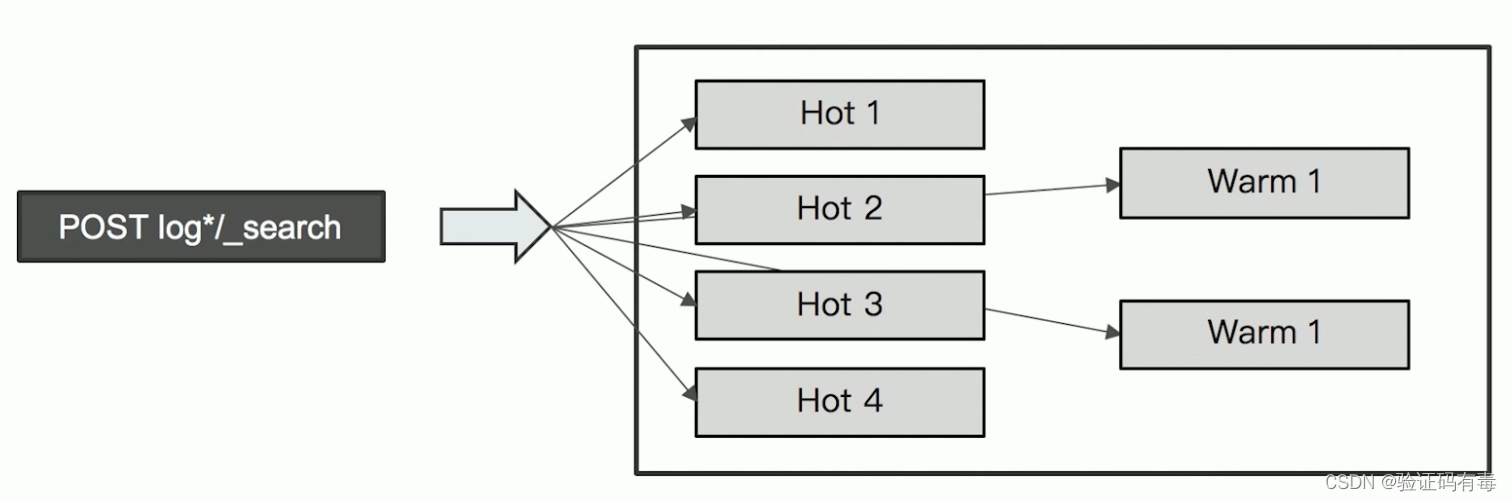
配置Hot & Warm 架构
使用Shard Filtering实现Hot&Warm node间的数据迁移
- node.attr来指定node属性:hot或是warm。
- 在index的settings里通过index.routing.allocation来指定索引(index)到一个满足要求的node

使用 Shard Filtering,步骤分为以下几步: - 标记节点(Tagging)
- 配置索引到Hot Node
- 配置索引到 Warm节点
1)标记节点
需要通过“node.attr”来标记一个节点
- 节点的attribute可以是任何的key/value
- 可以通过elasticsearch.yml 或者通过-E命令指定
# 标记一个 Hot 节点 elasticsearch.bat -E node.name=hotnode -E cluster.name=tulingESCluster -E http.port=9200 -E path.data=hot_data -E node.attr.my\_node\_type=hot # 标记一个 warm 节点 elasticsearch.bat -E node.name=warmnode -E cluster.name=tulingESCluster -E http.port=9201 -E path.data=warm_data -E node.attr.my\_node\_type=warm   **网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。** **[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)** **一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!** cluster.name=tulingESCluster -E http.port=9200 -E path.data=hot_data -E node.attr.my\_node\_type=hot # 标记一个 warm 节点 elasticsearch.bat -E node.name=warmnode -E cluster.name=tulingESCluster -E http.port=9201 -E path.data=warm_data -E node.attr.my\_node\_type=warm [外链图片转存中...(img-67FB4MqX-1715110133332)] [外链图片转存中...(img-zTCrxUfi-1715110133332)] **网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。** **[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)** **一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35


