
- 1ComfyUI中使用 SD3 模型(附模型下载详细说明)_comfyui sd3
- 2ChatGLM4重磅开源! 连忙实操测试一波,效果惊艳,真的好用!_chatglm4 开源发布时间
- 310款国内可用的AI工具分享,每一款都能让你工作效率翻倍_魔术todo任务分解
- 4普通人也能搞的,0成本,热门副业AI绘画,月入1w+_2024年0成本如何日入10000
- 5聚类模型的算法性能评价
- 6NLP综述:知识脉络图、四大类任务【序列标注(分词、词性标注、NER)、分类任务(文本分类、情感分析)、句子关系判断(顺序判断、相似度计算)、生成式任务(机器翻译、问答 、文本摘要)】_图书馆nlp标注 脉络洞察
- 7百度云不限速客户端让你获取SVIP速度_加速链接获取中啥意思
- 8C++11 智能指针详解_c++ 11所有的智能指针
- 9大模型入门指南:基本技术原理与应用_大模型原理
- 10Kafka和Spark Streaming的组合使用学习笔记(Spark 3.5.1)_2. kafka和structured streaming组合使用 (1)编写生产者程序每1秒生成一
【Golang - 90天从新手到大师】Day09 - string
赞
踩
系列文章合集
String
一个字符串是一个不可改变的字节序列。字符串可以包含任意的数据,但是通常是用来包含人类可读的文本。
len()返回字符串字节数目(不是rune数)。
通过索引可以访问某个字节值,0 <= index < len(str)。越界会panic。索引不是对应的字符而是对应的字节,因为有有非ASCII的UTF8字符有多个字节。
- s := "hello, world"
-
- fmt.Println(len(s)) // "12" 英文字符占一个字节
- fmt.Println(s[0], s[7]) // "104 119" ('h' and 'w')
for range
循环是循环的字节,而非字符
- for i, r := range "Hello, 世界ꡐ" {
- fmt.Printf("%d\t%q\t%d\n", i, r, r)
- }
- 0 'H' 72
-
- 1 'e' 101
- 2 'l' 108
- 3 'l' 108
- 4 'o' 111
- 5 ',' 44
- 6 ' ' 32
- 7 '世' 19990
- 10 '界' 30028
- 13 'ꡐ' 43088
第三列是字符的码点。
字符串截取与链接
- fmt.Println(s[:5]) // "hello"
- fmt.Println(s[7:]) // "world"
- fmt.Println(s[:]) // "hello, world"
- fmt.Println("hi" + s[5:]) //hi world
比较
1 字符串可以用==和<进行比较。通过逐个字节比较完成的,因此比较的结果是字符串自然编码的顺序。
2 原生字符
使用`反引号括起来,没有转义操作。
应用:HTML模板、JSON面值、命令行提示信息等。
编码
1 Unicode让我们可以通过Unicode码点输入特殊的字符。有两种形式:\uhhhh对应16bit的码点值,\Uhhhhhhhh对应32bit的码点值,其中h是一个十六进制数字,每一个对应码点的UTF8编码。以下表示相同字符:
- "世界"
- "\xe4\xb8\x96\xe7\x95\x8c"
- "\u4e16\u754c"
- "\U00004e16\U0000754c"
2 对于小于256码点值可以写在一个十六进制转义字节中,例如'\x41'对应字符'A',但是对于更大的码点则必须使用\u或\U转义形式。因此,'\xe4\xb8\x96'并不是一个合法的rune字符,虽然 这三个字节对应一个有效的UTF8编码的码点。
3 字符串长度用utf8.RuneCountInString(s)来获取。
rune
1 Unicode码点对应Go语言中的rune整数类型。
2 因为 rune大小一致,所以支持数组索引和方便切割。
string与[]rune转换
- r := []rune("你好 world!")
- fmt.Printf("%x\n", r) // "[4f60 597d 20 77 6f 72 6c 64 21]"
- fmt.Println(string(r)) // "你好 world"
- }
- fmt.Println(string(65)) // "A", not "65" 整形字符串输出为unicode码点的utf8字符串。
- fmt.Println(string(0x4eac)) // "京"
对字符串操作的4个包bytes、strings、strconv、unicode包
-
bytes包操作[]byte。因为字符串是只读的,因此逐步构创建字符串会导致很多分配和复制。使用 bytes.Buffer类型会更高。
-
strings包提供切割,索引,前缀,查找替换等功能。
-
strconv包提供了布尔型、整型数、浮点数和对应字符串的相互转换,还提供了双引号转义相 关的转换。
-
unicode包提供了IsDigit、IsLetter、IsUpper和IsLower等类似功能,它们用于给字符分类。
字符串与数字转换
将一个整数转为字符串
- x := 123
- fmt.Println(strconv.Itoa(x)) // "123"
将一个字符串解析为整数
- x, err := strconv.Atoi("123") // x is an int
- y, err := strconv.ParseInt("123", 10, 64)
FormatInt和FormatUint函数可以用不同的进制来格式化数字:
fmt.Println(strconv.FormatInt(int64(23), 2)) //将int64转换成2进制底层原型及编码
- #runtime/string.go
- type stringStruct struct {
- str unsafe.Pointer
- len int
- }
从字符串定义可以看出字符串是一个结构体,包含字符串指针和长度。
测试代码见下方:
- package main
- var s string
- func main() {
- s = "123 你好 world!"
- }
编译及通过gdb查看变量s的内存数据分布见图1:

图1
从上图可得知字符串数字123占3个字节分别为0x31 0x32 0x33。分别对应的是ascii。
- "\344\275\240\345\245\275"是8进制表示的你好。
- "0xe4 0xbd 0xa0 0xe5 0xa5 0xbd"是16进制表示的你好。
那计算机是如何识别是ascii还是unicode的呢,内存中存储的都是以字节为单元的,相邻哪几个是组成一个汉字呢?为了说明这个问题还是看一下上图1以”好“这个字说明,见下表格:
| 8进制 | 345 | 245 | 275 |
|---|---|---|---|
| 16进制 | 0xe5 | 0xa5 | 0xbd |
| 2进制 | 11100101 | 10100101 | 10111101 |
“好”字的依据图2可知,unicode的十六进制值为\u597d。
参考:https://www.unicode.org/charts/PDF/Unicode-5.2/U52-4E00.pdf
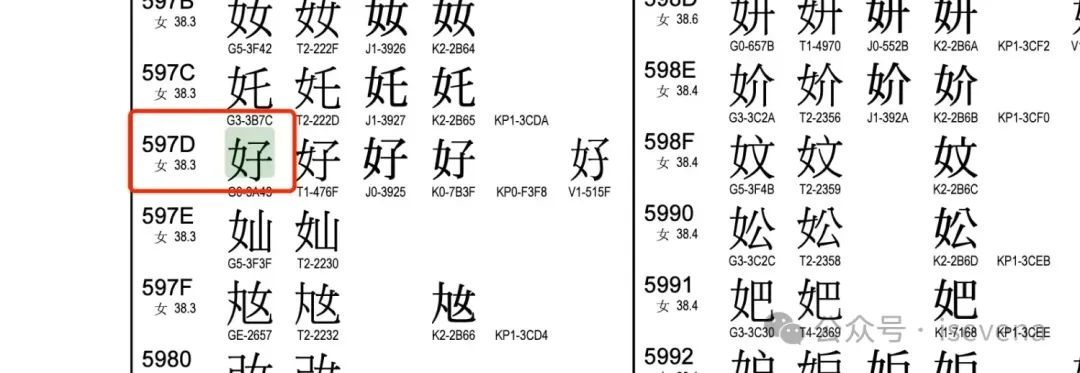
图2
那如何将3个字节转换成unicode的呢?
根据utf8编码规则见图3-go语言圣经截图:

图3-go语言圣经截图
发现好字的2进制表示正好符合1110xxxx 10xxxxxx 10xxxxxx
所以计算机识别的时候只要识别到1110且后两个字节的前2位都是10那这3个字节组成的就表示成一个字。
具体如何将这3个字节转换成unicode,有兴趣的朋友可以查查。
转换成unicode之后就可以根据unicode码找到字体包中的字。

