- 1花3个月面过京东测开岗,拿个22K不过分吧?_京东测开一共几面
- 2大厂经典面试题:Redis为什么这么快?
- 3【深度学习】实践方法论
- 4重磅!Stable Diffusion 3.0正式开源!史上最强AI绘画模型!(附安装方法和下载地址)_stable diffusion 3 下载
- 5如何使用 Git 优雅的回滚_怎么在本地revert一整个mr
- 6CNN卷积神经网络故障诊断(Matlab)_cnn故障诊断matlab
- 7二刷算法训练营Day41 (Day40休息) | 动态规划(3/17)
- 8[SwiftUI]页面跳转_swiftui 页面跳转
- 9FPGA自动洗衣机的设计与验证(Verilog编写)_fpga洗衣机设计
- 10neo4j导出导入csv文件_neo4j导出csv
推荐系统_让用户更好更快的获取自己所需的内容,让内容更快更好的推送到喜欢它的用户手中,让
赞
踩
推荐系统的主要内容
推荐系统概述
推荐系统的目的
- 信息过载
- 推荐系统是信息过载所采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品。解决一些人的“选择恐惧症”;面向没有明确需求的人。
·解决如何从大量信息中找到自己感兴趣的信息。
·解决如何让自己生产的信息脱颖而出,受到大众的喜爱。
·让用户更快更好的获取到自己需要的内容
·让内容更快更好的推送到喜欢它的用户手中
·让网站(平台)更有效的保留用户资源
推荐系统的应用

推荐系统的基本思想
- 知你所想,精准推荐:利用用户和物品的特征信息,给用户推荐那些具有用户喜欢的特征的物品。
- 物以类聚:利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品。
- 人以群分:利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品。
推荐系统分类
推荐系统分类
- 根据实时性分类:
离线推荐
实施推荐 - 根据推荐原则分类:
基于相似度的推荐
基于知识的推荐
基于模型的推荐 - 根据推荐是否个性化分类:
基于统计的推荐
个性化推荐 - 根据数据源分类:
基于人口统计学的推荐:人以群分
基于内容的推荐(Content based,CB)
基于协同过滤的推荐(Collaborative Filtering,CF)
CB和CF的区别:
·基于内容(Content based,CB)主要利用的是用户评价过的物品的内容特征,而CF方法还可以利用其他用户评分过的物品内容,CF可以解决CB的一些局限:
-物品内容不完全或者难以获得时,依然可以通过其他用户的反馈给出推荐
-CF基于用户之间对物品的评价质量,避免了CB仅依赖内容可能造成的对物品质量判断的干扰
-CF推荐不受内容限制,只要其他类似用户给出了对不同物品的兴趣,CF就可以给用户推荐出内容差异很大的物品(但有某种内在联系)
推荐算法简介
基于人口统计学的推荐
基于内容的推荐
- Content-based Recommendations (CB)根据推荐物品或内容的元数据,发现物品的相关性,再基于用户过去的喜好记录,为用户推荐相似的物品。
-通过抽取物品内在或者外在的特征值,实现相似度计算。
-比如一个电影,有导演、演员、用户标签UGC、用户评论、时长、风格等等,都可以算是特征。
·将用户(user)个人信息的特征(基于喜好记录或是预设兴趣标签),和物品(item)的特征相匹配,就能得到用户对物品感兴趣的程度。
-在一些电影、音乐、图书的社交网站有很成功的应用,有些网站还请专业的人员对物品进行基因编码/打标签(PGC)。
基于协同过滤的推荐
(1)不单单基于用户和物品,而是都有关联。
(2)分类:
- 基于近邻的协同过滤:基于用户(User-CF)、基于物品(Item-CF)。根据的是相同“口碑”准则
- 基于模型的协同过滤:奇异值分解(SVD)、潜在语义分析(LSA)、支撑向量机(SVM)
User-CF和ltem-CF的比较
- 同样是协同过滤,在User-CF 和ltem-CF 两个策略中应该如何选择呢?.
- ltem-CF 应用场景
-基于物品的协同过滤((ltem-CF)推荐机制是 Amazon 在基于用户的机制上改良的一种策略。
因为在大部分的Web站点中物品的个数是远远小于用户的数量的,而且物品的个数和相似度相对比较稳定,同时基于物品的机制比基于用户的实时性更好一些,所以ltem-CF成为了目前推荐策略的主流。 - User-CF应用场景
-设想一下在一些新闻推荐系统中,也许物品——也就是新闻的个数可能大于用户的个数,而且新闻的更新程度也有很快,所以它的相似度依然不稳定,这时用User-CF可能效果更好。
- ltem-CF 应用场景
(3)基于用户的协同过滤
- 基于用户的协同过滤推荐的基本原理是,根据所有用户对物品的偏好,发现与当前用户口味和偏好相似的"邻居"用户群,并推荐近邻所偏好的物品
- 在一般的应用中是采用计算"K-近邻“的算法;基于这K个邻居的历史偏好信息,为当前用户进行推荐
- User-CF 和基于人口统计学的推荐机制
-两者都是计算用户的相似度,并基于相似的“邻居"用户群计算推荐
-它们所不同的是如何计算用户的相似度:基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好
(4)基于物品的协同过滤
- 基于项目的协同过滤推荐的基本原理与基于用户的类似,只是使用所有用户对物品的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户
- ltem-CF和基于内容(CB)的推荐
- 其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好推断,而后者是基于物品本身的属性特征信息
- 同样是协同过滤,在基于用户和基于项目两个策略中应该如何选择呢?
- 电商、电影、音乐网站,用户数量远大于物品数量
- 新闻网站,物品(新闻文本)数量可能大于用户数量
(5)基于模型的协同过滤
-
基本思想
- 用户具有一定的特征,决定着他的偏好选择;-物品具有一定的特征,影响着用户需是否选择它;
- 用户之所以选择某一个商品,是因为用户特征与物品特征相互匹配;
- 基于这种思想,模型的建立相当于从行为数据中提取特征,给用户和物品同时打上"标签";这和基于人口统计学的用户标签、基于内容方法的物品标签本质是一样的,都是特征的提取和匹配
- 有显性特征时(比如用户标签、物品分类标签)我们可以直接匹配做出推荐;没有时,可以根据已有的偏好数据,去发掘出隐藏的特征,这需要用到隐语义模型(LFM)
-
基于模型的协同过滤推荐,就是基于样本的用户偏好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测新物品的得分,计算推荐
-
基于近邻的推荐和基于模型的推荐
- 基于近邻的推荐是在预测时直接使用已有的用户偏好数据,通过近邻数据来预测对新物品的偏好
(类似分类) - 而基于模型的方法,是要使用这些偏好数据来训练模型,找到内在规律,再用模型来做预测(类似回归)
- 基于近邻的推荐是在预测时直接使用已有的用户偏好数据,通过近邻数据来预测对新物品的偏好
-
训练模型时,可以基于标签内容来提取物品特征,也可以让模型去发掘物品的潜在特征;这样的模型被称为隐语义模型(Latent Factor Mogel,LFM)
(6)隐语义模型(LFM) -
用隐语义模型来进行协同过滤的目标
- 揭示隐藏的特征,这些特征能够解释为什么给出对应的预测评分
- 这类特征可能是无法直接用语言解释描述的,事实上我们并不需要知道,类似“玄学”
-
通过矩阵分解进行降维分析
- 协同过滤算法非常依赖历史数据,而一般的推荐系统中,偏好数据又往往是稀疏的;这就需要对原始数据做降维处理
- 分解之后的矩阵,就代表了用户和物品的隐藏特征
-
隐语义模型的实例
- 基于概率的隐语义分析(pLSA)-隐式迪利克雷分布模型(LDA
- 矩阵因子分解模型(基于奇异值分解的模型,SVD)
(7)基于协同过滤的推荐优缺点
- 基于协同过滤的推荐机制的优点:
- 它不需要对物品或者用户进行严格的建模,而且不要求对物品特征的描述是机器可理解的,所以这种方法也是领域无关的
- 这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好
- 存在的问题:
- 方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动"的问题-推荐的效果依赖于用户历史偏好数据的多少和准确性
- 在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等
- 对于一些特殊品味的用户不能给予很好的推荐
混合推荐
实际网站的推荐系统往往都不是单纯只采用了某一种推荐的机制和策略,往往是将多个方法混合在一起,从而达到更好的推荐效果。比较流行的组合方法有:
- 加权混合:用线性公式 (linear formula)将几种不同的推荐按照一定权重组合起来,具体权重的值需要在测试数据集上反复实验,从而达到最好的推荐效果。
- 切换混合:切换的混合方式,就是允许在不同的情况(数据量
系统运行状况,用户和物品的数目等)下,选择最为合适的推荐机制计算推荐。 - 分区混合:采用多种推荐机制,并将不同的推荐结果分不同的区显示给用户。
- 分层混合:采用多种推荐机制,并将一个推荐机制的结果作为另一个的输入,从而综合各个推荐机制的优缺点,得到更加准确的推荐。
推荐系统评测
评测指标:
预测准确度、用户满意度、覆盖率(不仅仅推热门的,也要推小众产品)、多样性、惊喜度、信任度、实时性、健壮性、商业目标(点击率等)
评测方法:
- 离线实验
-通过体制系统获得用户行为数据,并按照一定格式生成一个标准的数据集-将数据集按照一定的规则分成训练集和测试集
-在训练集上训练用户兴趣模型,在测试集上进行预测-通过事先定义的离线指标评测算法在测试集上的预测结果 - 用户调查
-用户调查需要有一些真实用户,让他们在需要测试的推荐系统上完成一些任务;我们需要记录他们的行为,并让他们回答一些问题;最后进行分 - 在线实验
-AB测试(把用户分组,应用不同的推荐系统,然后采集不同的数据等进行测评)
推荐准确度评测:
- 评分预测
-很多网站都有让用户给物品打分的功能,如果知道用户对物品的历史评分,就可以从中学习一个兴趣模型,从而预测用户对新物品的评分
-评分预测的准确度一般用均方根误差(RMSE)或平均绝对误差(MAE)计算
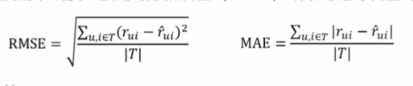
- Top-N推荐
-网站提供推荐服务时,一般是给用户一个个性化的推荐列表,这种推荐叫做Top-N推荐(用户最可能喜欢的)
-Top-N推荐的预测准确率一般用精确率(precision)和召回率(recall)来度量

推荐系统的数据分析
要推荐物品或内容的元数据,例如关键字,分类标签,基因描述等;
系统用户的基本信息,例如性别,年龄,兴趣标签等;
用户的行为数据,可以转化为对物品或者信息的偏好,根据应用本身的不同,可能包括用户对物品的评分,用户查看物品的记录,用户的购买记录等。这些用户的偏好信息可以分为两类:
- 显式的用户反馈
这类是用户在网站上自然浏览或者使用网站以外,显式的提供反馈信息,例如用户对物品的评分,或者对物品的评论。 - 隐式的用户反馈
这类是用户在使用网站是产生的数据,隐式的反应了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息等等。

用户画像
- 用户画像(User Profile)就是企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌作是企业应用大数据技术的基本方式
- 用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息
- 作为大数据的根基,它完美地抽象出一个用户的信息全貌,为进一步精准快速地分析用户行为习惯、消费习惯等重要信息,提供了足够的数据基础。
相似度计算

基于内容推荐系统的高层次结构

特征工程
- 特征(feature):数据中抽取出来的对结果预测有用的信息。·特征的个数就是数据的观测维度
- 特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程
- 特征工程一般包括特征清洗(采样、清洗异常样本),特征处理和特征选择特征按照不同的数据类型分类,有不同的特征处理方法:
-数值型
- 特征处理:
用连续数值表示当前维度特征,通常会对数值型特征进行数学上的处理,主要的做法是归一化和离散化。 - 幅度调整/归一化
特征与特征之间应该是平等的,区别应该体现在特征内部。
例如:房屋价格和住房面积的幅度是不同的,房屋价格可能在3000000- 15000000(万)之间,而住房面积在40~300(平方米)之间,那么明明是平等的两个特征,输入到相同的模型中后由于本身的幅值不同导致产生的效果不同,这是不合理的。 - 离散化
-
将原始连续值切断,转化为离散值。
-
让座问题:假设我们要训练一个模型判断在公交车上应不应该给一个人让座,按照常理,应该是给年龄很大和年龄很小的人让座。
-
对于以上让座问题中的年龄特征,对于一些模型,假设模型为y = 0x,输入的x(年龄)对于最后的贡献是正/负相关的,即×越大越应该让座,但很明显让座问题中,年龄和是否让座不是严格的正相关或者负相关,这样只能兼顾年龄大的人,无法兼顾年龄大的人和年龄小的人。

-
离散化的两种方式
- 等步长:简单但不一定有效
- 等频:min->25%->75%->max
两种方法对比
- 等频的离散化方法很精准,但需要每次都对数据分布进行一遍从新计算,因为昨天用户在淘宝上买东西的价格分布和今天不一定相同,因此昨天做等频的切分点可能并不适用,而线上最需要避免的就是不固定,需要现场计算,所以昨天训练出的模型今天不一定能使用
- 等频不固定,但很精准,等步长是固定的,非常简单,因此两者在工业上都有应用
-类别型
- 类别型特征处理
- 类别型数据本身没有大小关系,需要将它们编码为数字,但它们之间不能有预先设定的大小关系,因此既要做到公平,又要区分开它们,那么直接开辟多个空间
- One-Hot编码/哑变量
- One-Hot编码/哑变量所做的就是将类别型数据平行地展开,也就是说,经过One-Hot编码/哑变量后,这个特征的空间会膨胀

-时间型
- 时间型特征处理
- 时间型特征既可以做连续值,又可以看做离散值。连续值
- 持续时间(网页浏览时长)
- 间隔时间(上一次购买/点击离现在的时间间隔)
- 离散值
- 一天中哪个时间段
- 一周中的星期几
- 一年中哪个月/星期
- 工作日/周末
-统计型
- 统计型特征处理
- 加减平均:商品价格高于平均价格多少,用户在某个品类下消费超过多少。
- 分位线:商品属于售出商品价格的分位线处。
- 次序性:商品处于热门商品第几位。
- 比例类:电商中商品的好/中/差评比例。
推荐系统常见反馈数据
基于UGC的推荐
- 用户用标签来描述对物品的看法,所以用户生成标签(UGC)是联系用户和物品的纽带,也是反应用户兴趣的重要数据源
- 一个用户标签行为的数据集一般由一个三元组(用户,物品,标签)的集合表示,其中一条记录(u,i,b)表示用户u给物品i打上了标签b
- 一个最简单的算法
- 统计每个用户最常用的标签
- 对于每个标签,统计被打过这个标签次数最多的物品b
- 对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门的物品,推荐给他-所以用户u对物品|的兴趣公式为
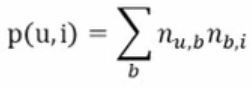
其中,n(u,b)(u,b是n的小脚标)是用户u打过标签b的次数,n是物品|被打过标签b的次数。
基于UGC简单推荐的问题
- 简单算法中直接将用户打出标签的次数和物品得到的标签次数相乘,可以简单地表现出用户对物品某个特征的兴趣
- 这种方法倾向于给热门标签《谁都会给的标签,如"大片、“搞笑"等)、热门物品(打标签人数最多)比较大的权重。如果一个热门物品同时对应着热门标签,那它就会"霸榜。推荐的个性化、新颖度就会降低
- 类似的问题,出现在新闻内容的关键字提取中。比如以下新闻中,哪个关键字应该获得更高的权重?

TF-IDF
-
词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)是一种用于资讯检索与文本挖掘的常用加权技术
-
TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降
TF-IDF=TF*IDF -
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率T高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类
.TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级 -
词频(Term Frequency,TF)
-
指的是某一个给定的词语在该文件中出现的频率。这个数字是对词 数的归一化,以防止偏向更长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
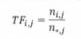
-
其中Tf,表示词语1在文档j中出现的频率,ny表示i在j中出现的次数,n.y表示文档j的总词数·逆向文件频率(lnverse Document Frequency,IDF)
-是一个词语普遍重要性的度量,某一特定词语的 IDF,可以由总文档数目除以包含该词语之文档的数目,再将得到的商取对数得到
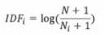
其中 IDF,表示词语「在文档集中的逆文档频率;N 表示文档集中的文档总数,N表示文档集中包含了词语i的文档数。
-
TF-IDF对基于UGC推荐的改进
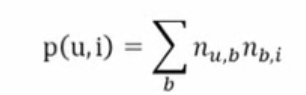
- 为了避免热门标签和热门物品获得更多的权重,我们需要对”热门°进行惩罚
- 借鉴TF-IDF的思想,以一个物品的所有标签作为“文档,标签作为“词语",从而计算标签的"词频”(在物品所有标签中的频率)和逆文档频率”(在其它物品标签中普遍出现的频率)
- 由于“物品i的所有标签"n.,应该对标签权重没有影响,而“所有标签总数"N对于所有标签是一定的,所以这两项可以略去。在简单算法的基础上,直接加入对热门标签和热门物品的惩罚项:
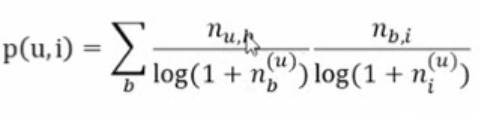
其中, nb的u记录了标签 b被多少个不同的用户使用过,ni的u记录了物品被多少个不同的用户打过标签。
TF-IDF算法代码实例
0.引入依赖
import numpy as np
import pandas as pd
- 1
- 2
1.定义数据和预处理
docA="The cat sat on my bed"//定义了一个字符串,相当于定义了一个文档
docB="The dog sat on my knees"
//关键词是cat和dog,坐在哪?(bed、knees)
- 1
- 2
- 3
#做分词,提取关键字
bowA=docA.split(" ")
bowB=docB.split(" ")
bowA
//得['The','cat','sat','on','my','bed']
#构建词库
wordSet=set(bowA).union(set(bowB))
wordSet
//得['The','bed','cat','dog','knees','my','on','sat']列表中元素默认升序排列
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.进行词数统计
#用统计字典来保存词出现的次数
wordDictA=dict.fromkeys(wordSet,0)
wordDictB=dict.fromkeys(wordSet,0)
wordDictA
//得{'cat':0,'on':0,'sat':0,'knees':0,'bed':0,'The':0,'my':0,'dog':0}
#遍历文档,统计词数
for word in bowA:
wordDictA[word]+=1
for word in bowB:
wordDictB[word]+=1
wordDictA
//得{'cat':1,'on':1,'sat':1,'knees':0,'bed':1,'The':1,'my':1,'dog':0}
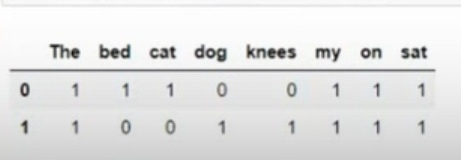
pd.DataFrame([wordDictA,wordDictB])
//如下图
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.计算词频TF
def computeTF(wordDict,bow):
//用一个字典对象记录tf,把所有的词对应在bow文档里得tf都算出来
tfDict={}
nbowCount=len(bow)
for word,count in wordCount.items():
tfDict[word]=count/nbowCount
return tfDict
tfA=computeTF(wordDictA,bowA)
tfB=computeTF(wordDictB,bowB)
tfA
//得{'cat':0.166666666666,'on':0.166666666666,'sat':0.166666666666,'knees':0.0,'bed':0.166666666666,'The':0.166666666666,'my':0.166666666666,'dog':0.0}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.计算逆文档频率idf
def computeIDF(wordDictList): //用一个字典对象保存idf结果,每个词作为key,初始值为0 idfDict=dict.fromkeys(wordDictList[0],0) //与是A文档还是B文档无关 N=len(wordDictList) import math for wordDict in wordDictList: //遍历字典中的每个词汇 for word,count in wordDict.items(): if count>0: //先把Ni增加1,存入到idfDict中 idfDict[word]+=1 //已经得到所有词汇i对应的Ni,现在根据公式把它替换为idf值 for word,ni in idfDict.items(): idfDict[word]=math.log10((N+1)/(ni+1)) return idfDict idfs=computeIDF([wordDictA,wordDictB]) idfs //得{'cat':0.17609125905568124,'on':0.0,'sat':0.0,'knees':0.17609125905568124,'bed':0.17609125905568124,'The':0.0,'my':0.0,'dog':0.17609125905568124} //因为on,sat,The,my在所有文档里都出现了,所有是0,所有它们不关键

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
5.计算TF-IDF
def computeTFIDF(tf,idfs):
tfidf={}
for word,tfval in tf.items():
tfidf[word]=tfval*idfs[word]
return tfidf
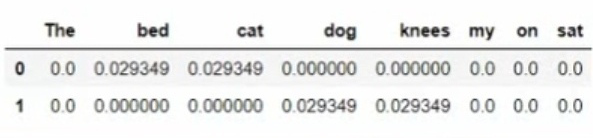
tdidfA=computeTFIDF(tfA,idfs)
tdidfB=computeTFIDF(tfB,idfs)
pd.DataFrame([tdidfA,tfidfB])
//得,见下图
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9