
- 1探索开源新声:深入Fish Speech,革新文本转语音技术的先锋!
- 2消息中间件MQ——RabbitMQ、RocketMQ、Kafka_使用什么mq
- 3手把手教你在linux中部署stable-diffusion-webui
- 4【零基础学flink】flink DataStream API 详解
- 5LaTex使用技巧10:公式中的各种英文字体_latex 英文字体
- 6基于sklearn的七种回归算法预测波士顿房价_波士顿房价预测sklearn
- 7【数据结构笔记备忘】单链表,双向链表,循环单双链表_哪些排序用到单链,双链,循环链
- 8使用Java替换字符串中的占位符${xx}_java根据${}替换
- 9JAVA面试题分享四百三十九:要保证消息不丢失,又不重复,消息队列怎么选型?_面试消息队列保证消息不丢失
- 10探索React Apollo:下一代GraphQL客户端
Contrast and Generation Make BART a Good Dialogue Emotion Recognizer
赞
踩

摘要
在对话系统中,具有相似语义的话语在不同的语境下可能具有不同的情感。因此,用说话者依赖来建模长期情境情绪关系在对话情绪识别中起着至关重要的作用。同时,区分不同的情绪类别也不是很简单的,因为它们通常具有语义上相似的情绪。为此,我们采用监督对比学习,使不同的情绪相互排斥,从而更好地识别相似的情绪。同时,我们利用一个辅助反应生成任务来增强模型处理上下文信息的能力,从而迫使模型在不同的上下文中识别具有相似语义的情绪。为了实现这些目标,我们使用预先训练好的编码器-解码器模型BART作为我们的主干模型,因为它非常适合于理解和生成任务。在四个数据集上的实验表明,我们提出的模型在对话情绪识别方面比现有的模型获得了更有利的结果。消融研究进一步证明了监督对比损失和生成损失的有效性。
介绍
随着个人智能终端技术和社交网络的发展和普及,构建一个能够理解用户情绪和意图并进行有效对话互动的对话系统的重要性显著增加。对话系统中的一个关键模块是自然语言理解模块,它可以分析用户的行为,如意图或情绪。利用上下文关系分析用户情绪是简单情绪分类任务的一个高级步骤,更适合于现实世界中的使用场景,具有更多的研究价值。对话中的情感识别(ERC)的任务是为具有语境关系的历史对话中的所有话语分配情感标签。同时,每个历史对话都包含了多个不同说话者之间的交互,如图1所示。
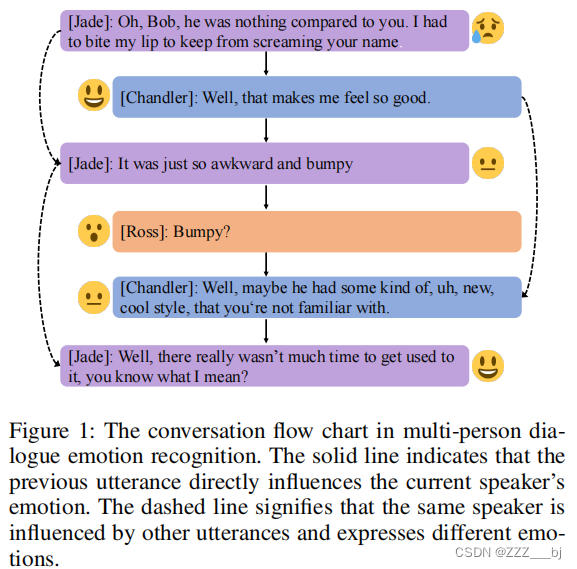
ERC面临着三个挑战。
- (1)第一个挑战是,每一个话语的情绪都可能会受到上下文信息的影响。例如,特定的情绪将取决于上下文的某些话语。同时,具有相同表达方式的话语在不同的语境中可能有完全不同的情绪。因此,有效地建模上下文依赖和说话人依赖是区分该任务与传统情绪分类的主要因素。
- (2)第二个挑战是,每个说话者的情绪都会受到谈话中其他说话者的话语的影响,所以说话者的情绪可能会发生突然的变化。
- (3)第三个挑战在于语义上相似但不同的情绪类别,比如“沮丧”到“悲伤”,“快乐”到“兴奋”,等等。很难区分这些语义上相似的情绪类别。
最近的相关工作使用各种图网络解决上下文依赖和说话者关系(Shen等2021b;Ghosal等2019年;石谷等2020年;Sheng等2020年)。然而,随着层数的加深,过度平滑的现象开始出现(Chen et al. 2020a)开始出现,导致类似情绪的表现难以区分。
这项工作通过更好地建模上下文和说话者信息和辅助生成任务来处理上述挑战。
首先,我们引入了一个对话级Transformer(Vaswani et al. 2017)层来建模话语之间的长期上下文依赖关系。一个预先训练过的语言模型捕捉了每个话语的表示。与以往仅采用预先训练好的模型作为特征提取器(Liu et al. 2019)并将提取出的特征作为下游图网络的节点表示的方法相比,纯Transformer结构做出的先前结构假设更少(Lin et al. 2021)。
其次,我们采用监督对比学习(SCL)(Khosla et al. 2020)来缓解相似情绪分类的困难,在充分利用标签信息的情况下,使具有相同情绪的凝聚和不同情绪的样本互斥。与有噪声标签的交叉熵损失相比,有监督的对比损失可以提高训练的稳定性,提高模型的泛化性(Gunel et al. 2021)。与常规的SCL不同,我们复制一批中所有样本的隐藏状态,并分离其梯度作为它的多视图表示。原因是现有ERC数据集中的类别高度不平衡,有些类别可能存在于一个只有一个样本的批次中。如果只使用原始的SCL,它将导致不正确的损失计算。
第三,我们引入了一个辅助响应生成任务,以增强ERC捕获上下文信息的能力。对下一句话语的预测使模型充分考虑了上下文的依赖性,从而迫使模型在识别对话中的情绪时,考虑上下文中的信息,并依赖于当前的话语本身。此外,通过在说话前直接将说话者拼接起来,作为说话者信息的提示,说话者和话语之间的依赖关系得到了充分的建模,并且没有额外的参数。
最后,我们利用BART(Lewis et al. 2020),一个预先训练过的具有编译码器结构的Transformer,作为我们的骨干模型,并通过对比和生成损失来增强它。我们提出的协同约束和生成增强的BART(CoG-BART)在四个ERC数据集上,与基线模型相比,获得了最先进的结果。此外,消融实验和案例研究证明了对比损失和生成损失在ERC任务中的有效性。
综上所述,我们的主要贡献可以总结如下:
- 据我们所知,我们首次在ERC中使用监督对比学习,显著提高了模型区分不同情绪的能力。
- 通过将响应生成作为辅助任务,当涉及到某些上下文信息时,ERC的性能得到了提高。
- 我们的模型很容易实现,因为它不依赖于外部资源,比如基于图的方法。
方法
问题定义
在对话情绪识别中,数据由多个对话{c1、c2、···、cN }组成,每个对话由多个话语[u1、u2、··、=]和情绪标签Yci = {y1、y2、···、ym}∈S组成,其中y表示情绪类别。对于一个话语,它由几个token=ut[wt、1、wt、2、····、wt、n]组成。对话中的每一句话都由一个说话者说,可以用p(ci)=(p(u1)、·、p(ui)、·、p(um)和p(ui)∈P表示,其中P表示说话者的类别或名称。因此,整个问题可以表示为在一段对话中根据上下文和说话者信息获取每个话语的情感标签: Yci = f(ci,p(ci))。
针对ERC的监督对比学习
话语编码
为了模拟说话者和话语之间的依赖关系,对于对话中的某个话语,我们在话语之前拼接说话者的名字或类别。在使用说话人信息的标记话语后,我们得到:
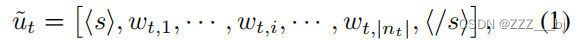
其中,,和被视为特殊的标记来表示话语的开始和结束。然后是将标记化后的token序列输入到BART的共享嵌入层,获取话语中每个标记的隐藏状态,然后将其发送给BART的编码器和解码器。将Ht发送到BART后,获得当前话语的表示:

对话建模
由BART-Model获得的表示Ht进行最大池化,以获得话语的聚合表示如下:
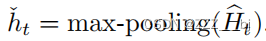
为了建模对话的历史上下文信息,我们利用对话级Transformer(Vaswani et al. 2017)层作为上下文编码器。多头注意力机制可以在多轮对话中捕捉不同对话之间的交互作用,并聚合不同的特征,得到最终的隐式表征,从而充分建模不同话语和语境关系之间的复杂依赖关系。对于一个语境中的所有话语,对话ˇhj、ˇhk中两个不同话语之间隐藏状态的多头注意得分可以通过以下公式计算:

因此,通过上述对话级Transformer,可以获得建模上下文依赖性的话语表示:
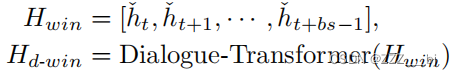
监督对比学习
监督对比学习假设一些关键方面得到注意,当在预训练模型上进行微调时,允许小样本学习更稳定(Gunel et al. 2021)。典型的对比学习只使用一对正样本,而所有其他的样本都被视为负样本。监督对比学习通过充分利用标签信息,将该批中所有具有相同标签的例子视为正样本。
对于ERC,某些数据集中每个类别的样本数量(Li et al. 2017)是高度不平衡的,而监督对比学习在计算损失时会掩盖自己。如果批中某个类别只存在一个样本,则不能直接用于计算损失。因此,通过复制话语Hd-win的隐藏状态,得到-Hd-win,并分离其梯度。并且,参数优化保持稳定。
对于有N个训练样本的批次,每个样本采用上述机制进行操作,获得多视图2N个样本,那么一个批次中所有样本的监督对比损失可以用下式表示:

辅助响应生成
为了便于模型在确定话语情绪时考虑更丰富的上下文信息,模型需要在给出当前话语ut的情况下生成其后续话语ut+1。ut+1中每个token的输出隐藏状态由BART解码器按顺序生成。
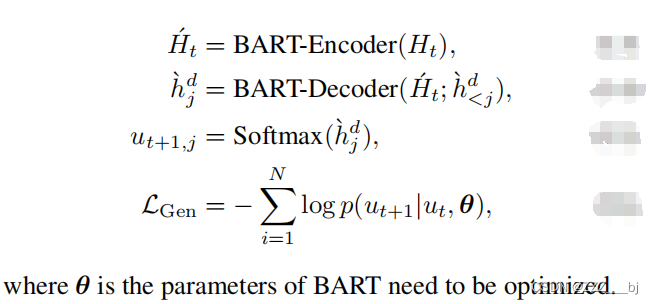
模型训练
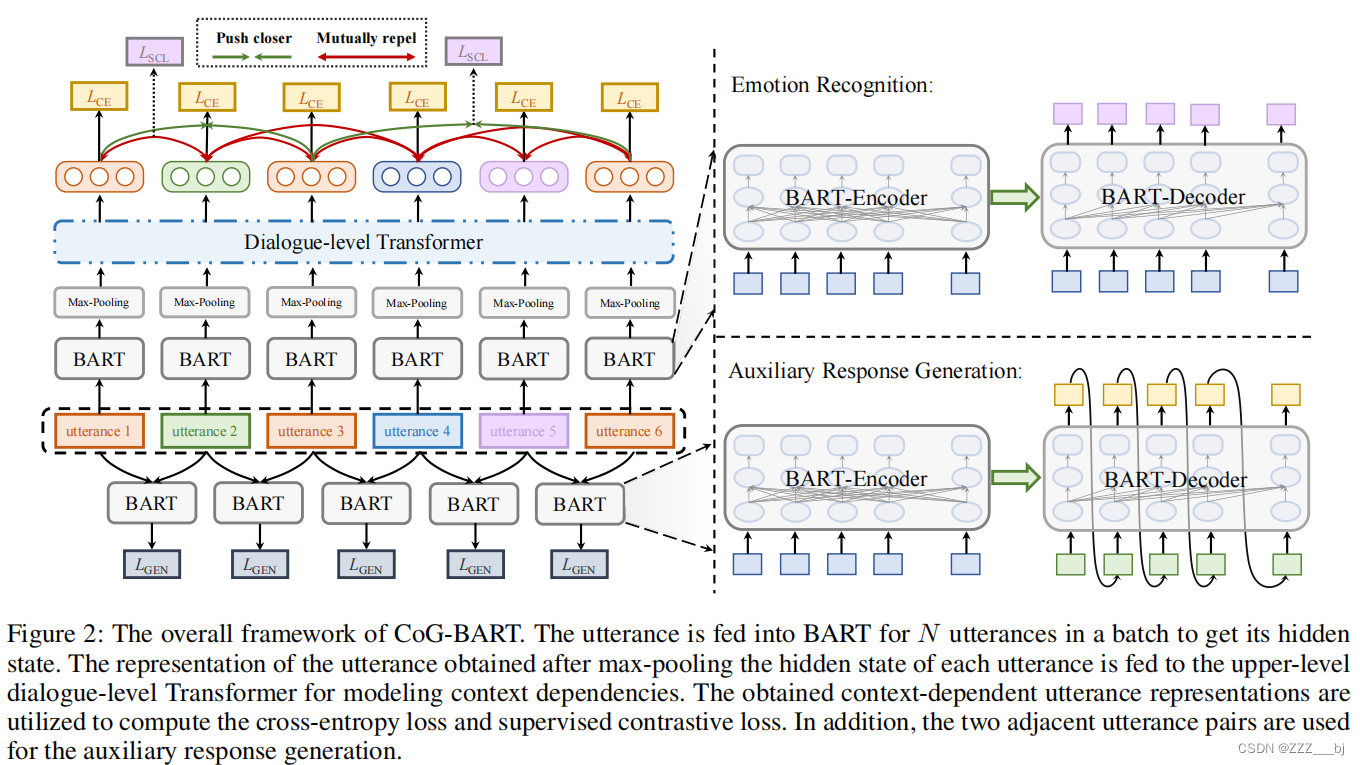
模型训练的损失包括三个部分:上下文建模中通过多层感知器得到的隐藏状态Hd-win,以获得计算交叉熵损失。另一部分是有监督的对比损失和响应生成的损失。损失是三个分量的加权和,它们的权重的和等于1。CoG-BART的总体框架如图2所示。

实验设置
本节将详细介绍实验中采用的数据集、基线模型、实验条件和参数设置。
实验设置
BART的代码框架和初始重量来自于拥抱脸的变形金刚(Wolf et al. 2020)。应用于模型训练的优化器是一个线性计划的热身策略。本实验调整的参数包括批大小、学习率、预热率、α和β。我们通过保留的验证集对模型训练进行了超参数搜索。测试集上的结果来自于验证集中的最佳检查点,我们对来自5个不同的随机种子的得分取平均值。所有实验均在GeForce RTX 3090 GPU上进行。
数据集
四个基准数据集:MELD(Pouria等人2019年)、EmoryNLP(Zahiri和Choi2018年)、每日对话框(Li等人2017年)和IEMOCAP(Busso等人2008年),用于与基线模型进行比较。
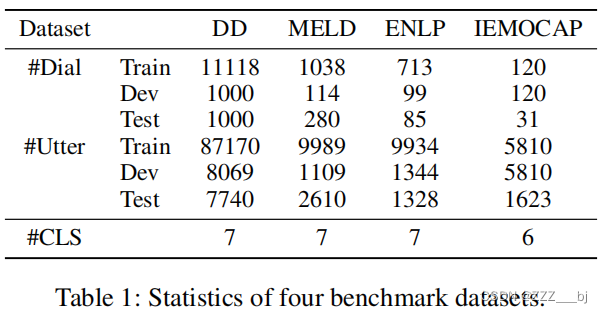
四个数据集的详细统计数据如表1所示,其中“#Dial”表示train/dev/tese/中对话的数量,“#Utter”表示对话中所有话语的数量,“#CLS”表示每个数据集的情绪类别数量。
指标
对于MELD、EmoryNLP和IEMOCAP,我们采用加权平均f1作为评价指标。由于“中性”在DailyDialog中占多数,我们采用micro-F1作为该数据集的评价指标,我们在计算结果时忽略了“中性”的标签(Zhu等,2021;Shen等,2021b)。
结果与分析
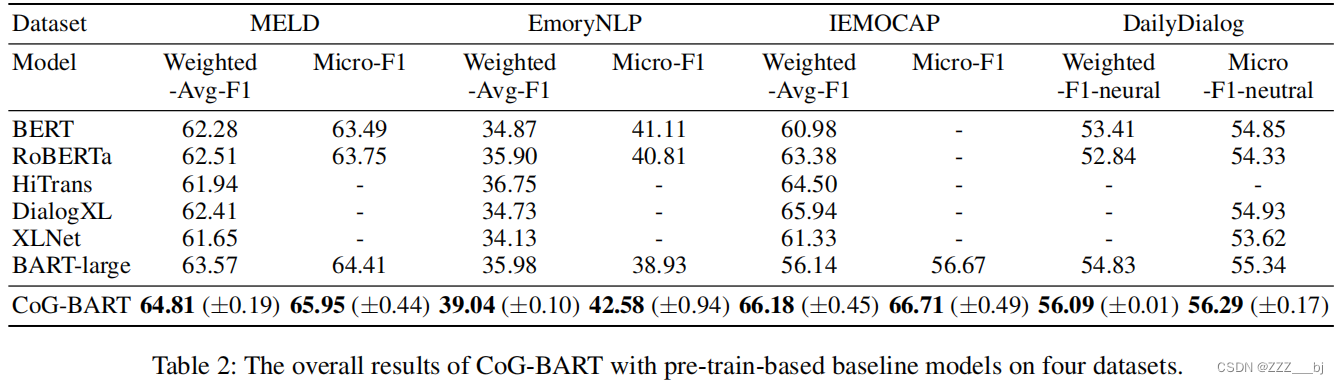
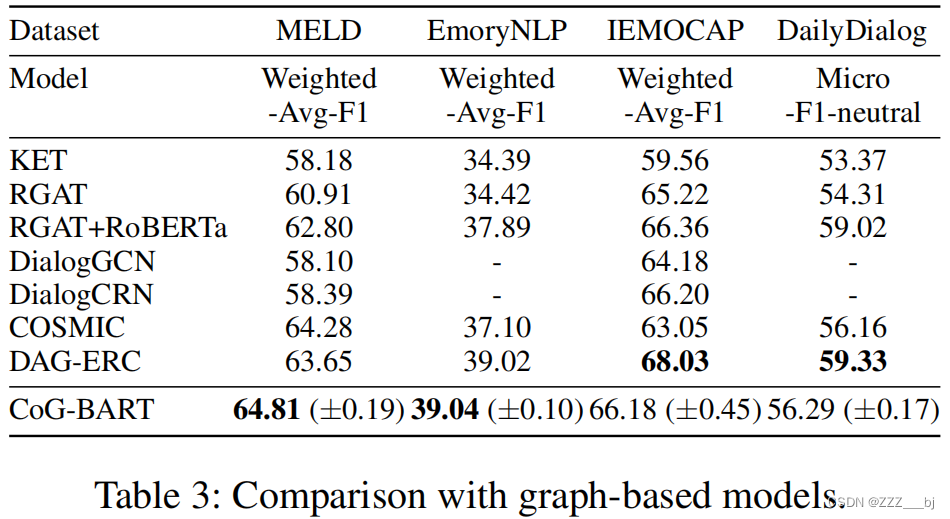
表2和表3记录了四个数据集上CoG-BART与基线模型的比较结果。
-
在基于序列的模型及其变体中,所选的基线模型包括BERT(Devlin等2019年)、RoBERTa(Liu等2019年)、HiTrans(Li等2020年)、DialogXL(Shen等2021年a)和XLNet (Yang等2019年)。在MELD(Poria等人2019年)中,CoG-BART比之前最先进的bart大有大约1.24%的改进(Lewis等人2020年)。
-
对于基于图的模型,列出了KET(钟、王、苗2019)、RGAT(石谷等2020)、 DialogGCN(Ghosal等2019)、 DialogCRN(胡、魏、淮2021)、COSMIC(对话等2020)和DAG-ERC(Shen等2021b)。 与基于图的模型相比,CoG-BART比COSMIC提高了0.53个点(Ghosal et al. 2020)。值得注意的是,COSMIC使用RoBERTa-large作为特征提取器,而CoG-BART只采用BART-large骨干结构获得竞争结果,这表明在 MELD 中,对有效模拟上下文之间依赖关系的预训练模型进行充分的知识转移也能获得可喜的结果。
-
我们可以从EmoryNLP(Zahiri和Choi 2018)的结果中观察到,使用预先训练的模型作为特征提取器的基于图的模型总体上比仅使用预先训练的模型作为主干网络的模型效果更好。同时,CoG-BART仍取得了显著的改进效果。此外,与基于预训练的模型相比,基于图的模型可以在 IEMOCAP上获得更高的F1值(Busso et al. 2008)。

