
热门标签
热门文章
- 1运算放大器,放大倍数与增益的关系_运放的增益与放大倍数
- 2Docker 安装mysql并解决ERROR 1045 (28000)问题_docker exec -it mysql mysql -uroot -p enter passwo
- 3总结那些非常有用缓解工作压力的窍门
- 4一文读懂生成式人工智能的所有基础知识(上)_生成式人工智能基础
- 5【码银送书第六期】《ChatGPT原理与实战:大型语言模型的算法、技术和私有化》_chatgpt原理与实战 大型语言模型
- 6开源内网穿透神器:中微子代理(neutrino-proxy)实现内网穿刺
- 7ES查询[全网最全免费送付费内容]_es查询match指定分词器
- 8mysql 错误1136_mysql,_MySQL错误:Error Code: 1136,mysql - phpStudy
- 9解决Ubuntu 18.04.5LTS android studio的安装运行工程时出现的问题_ubuntu18.04启动android studio a ui exception occur
- 10程序开发——开源软件库
当前位置: article > 正文
论文代码复现之:GPT-too: A Language-Model-First Approach for AMR-to-Text-Generation(ARM-to-text)_gpt可以复现文献的代码吗
作者:繁依Fanyi0 | 2024-07-18 19:28:55
赞
踩
gpt可以复现文献的代码吗
资源引用
复现过程
虚拟环境创建
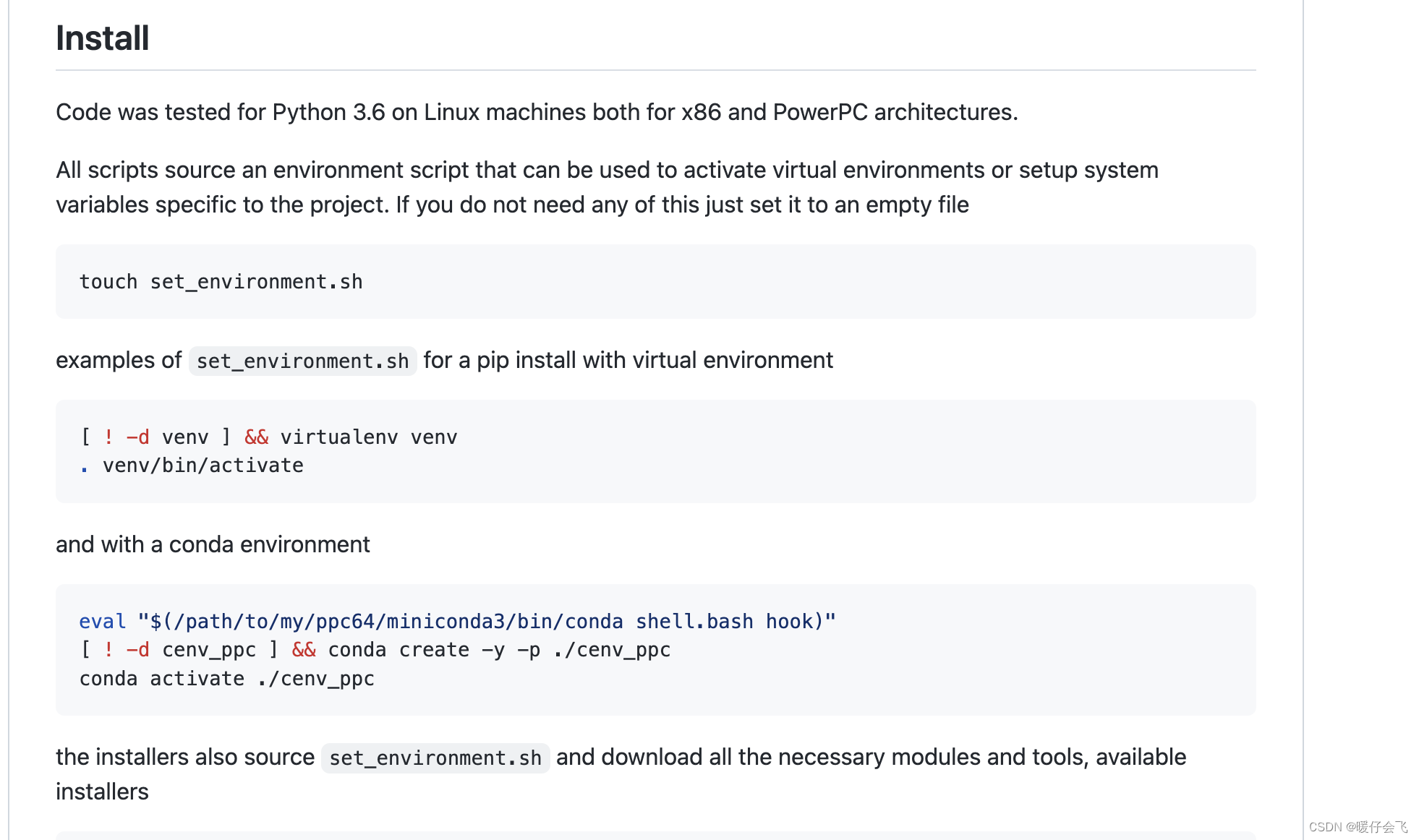
- 无论你是根据 github 提供的命令来创建虚拟环境,还是使用自己的虚拟环境都要执行第一步
touch set_environment.sh - 因为后面的运行需要根据这个文件
- 如果你是自己通过 anaconda 创建虚拟环境,那么你的 set_environment.sh 这个文件里面什么都不用写
- 或者你使用作者提供的下述命令写入到 set_environment.sh 文件中来创建你的虚拟环境并激活

通过 pip 或者 anaconda 安装依赖
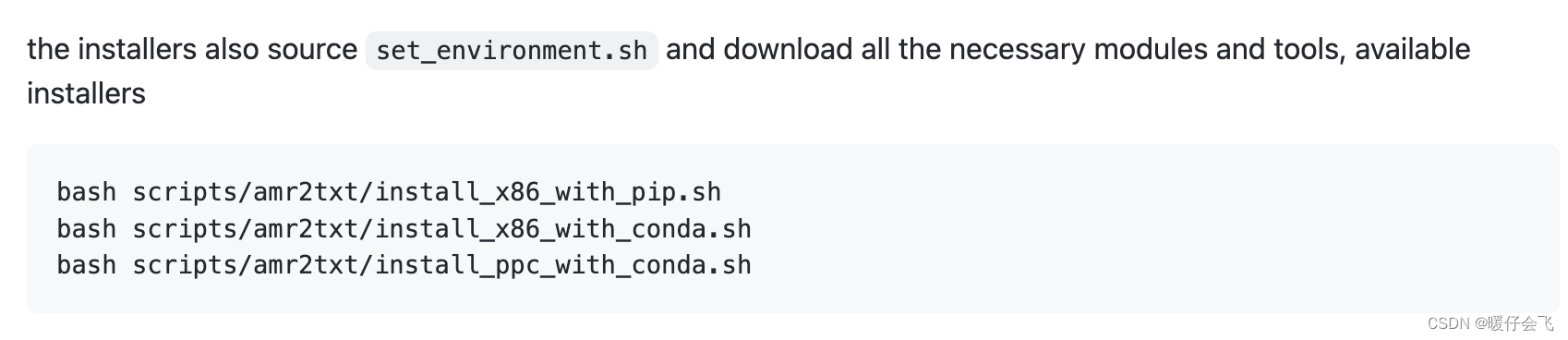
- 在作者提供的文件中,有这么三个
.sh文件,这三个文件使用三种不同的方式安装依赖,你选择一个执行即可。比如我选择用 pip 在我的虚拟环境中配置相关的依赖,那我执行的就是
bash scripts/amr2txt/install_x86_with_pip.sh
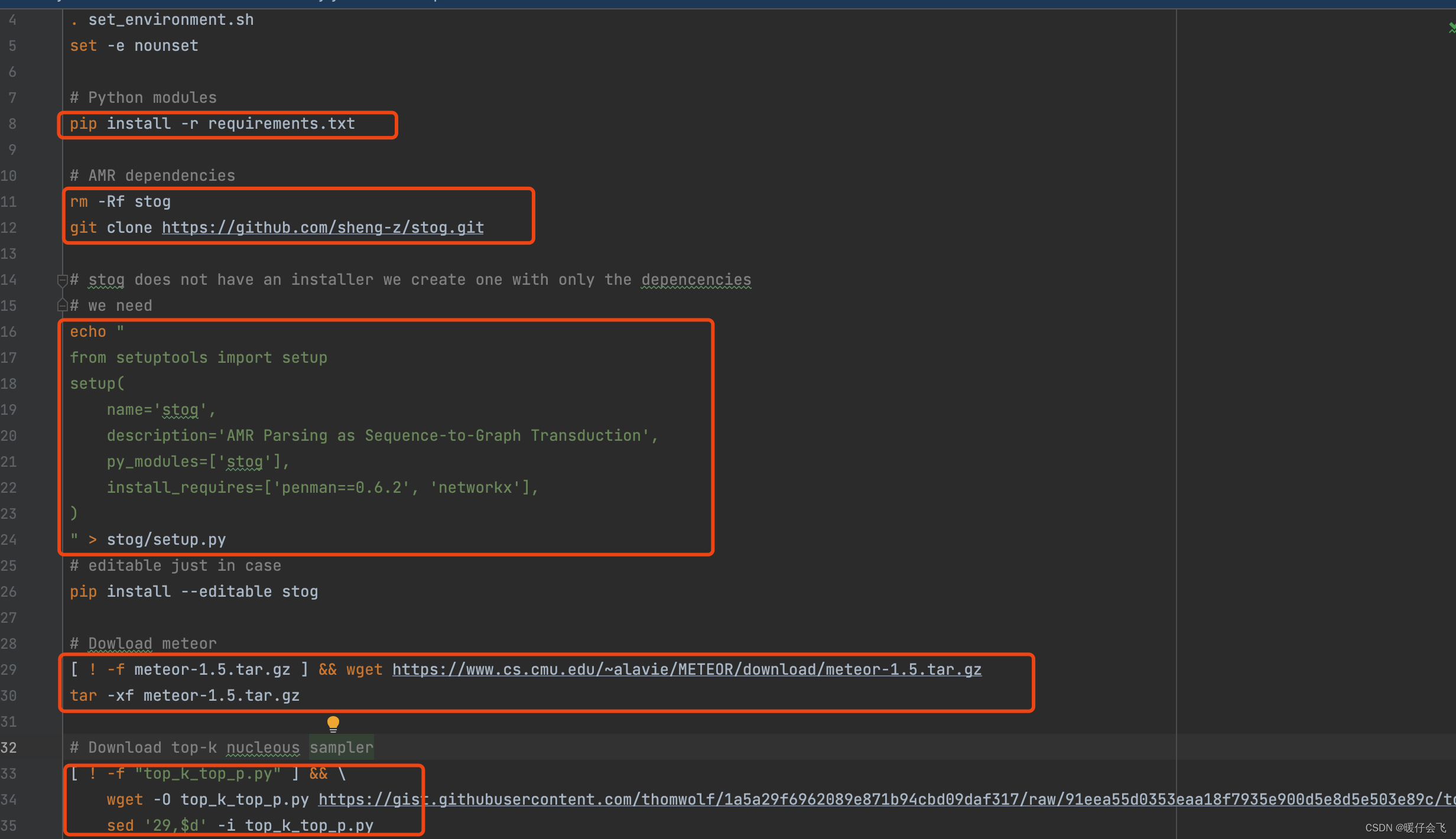
- 下面展示的就是
install_x86_with_pip.sh文件中的内容,这一步其实没有什么神秘的,只是给你安装一些现成的依赖,还有作者使用的一些工具,比如 stog,meteor
- 下面展示的就是
- 直接执行他的安装命令可能会出现一些问题,所以建议读者按照下面的步骤进行操作:
他原本的
requirements.txt是这么写的:
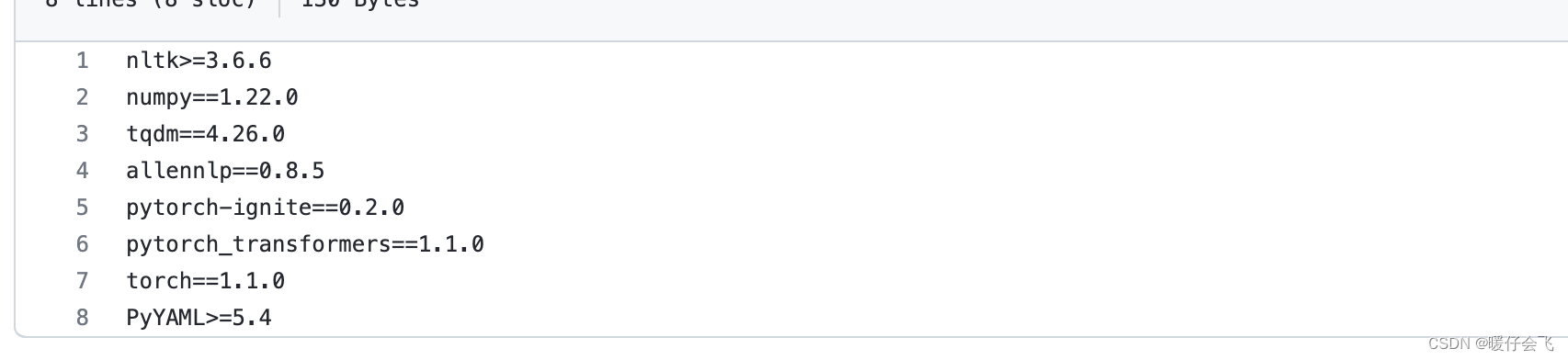
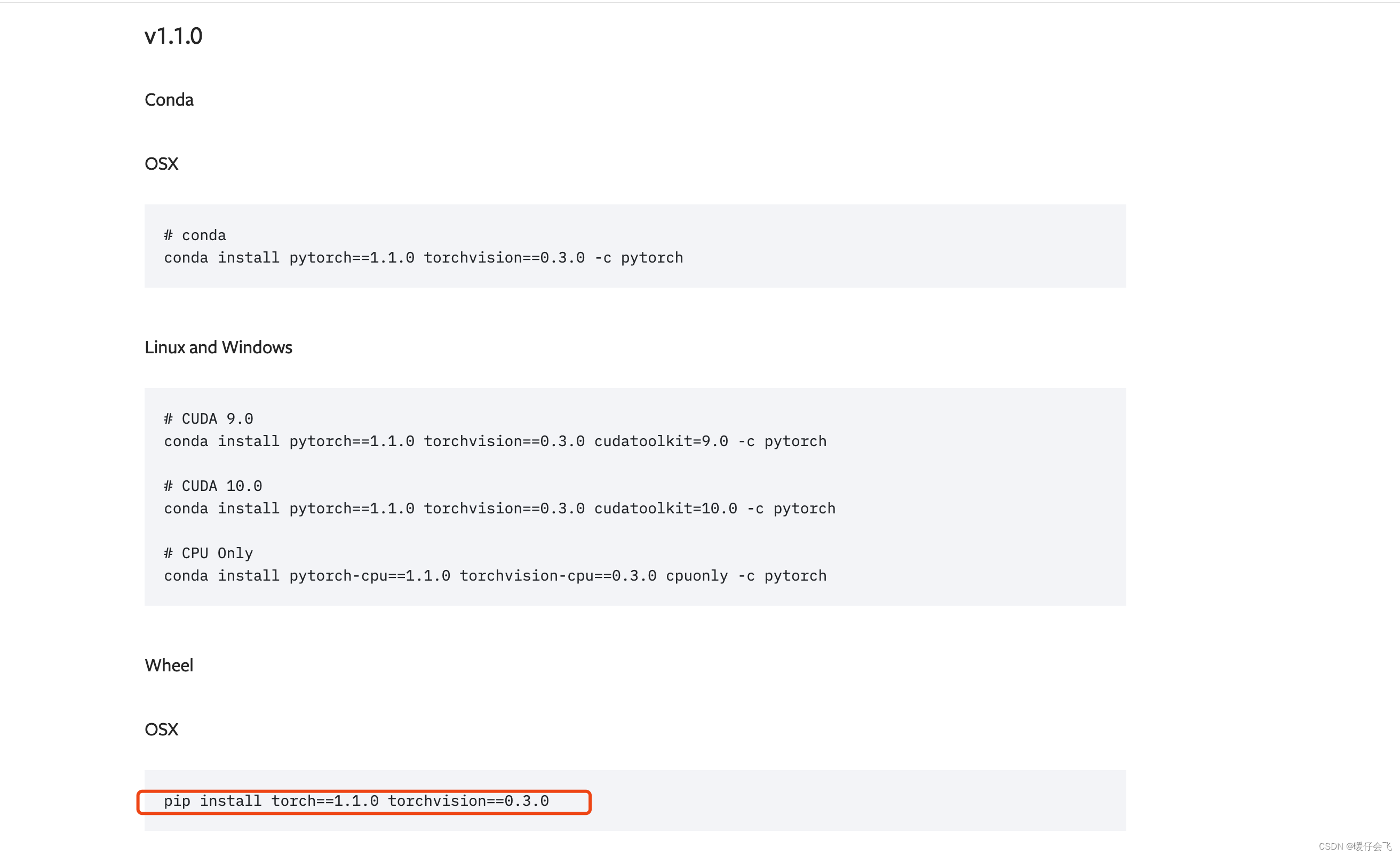
但是这样安装肯定是有问题的,因此我采取了如下手段:- 首先单独将 torch 安装好,也就是去 torch 的官网,找到 1.1 版本,然后用
pip命令安装(这里安装的是 cpu 版本,因为我的代码在服务器上跑,本地只是调试一下,所以我就下了 cpu版本,大家根据自己的需要调整)
- 剩下的就是常规安装了
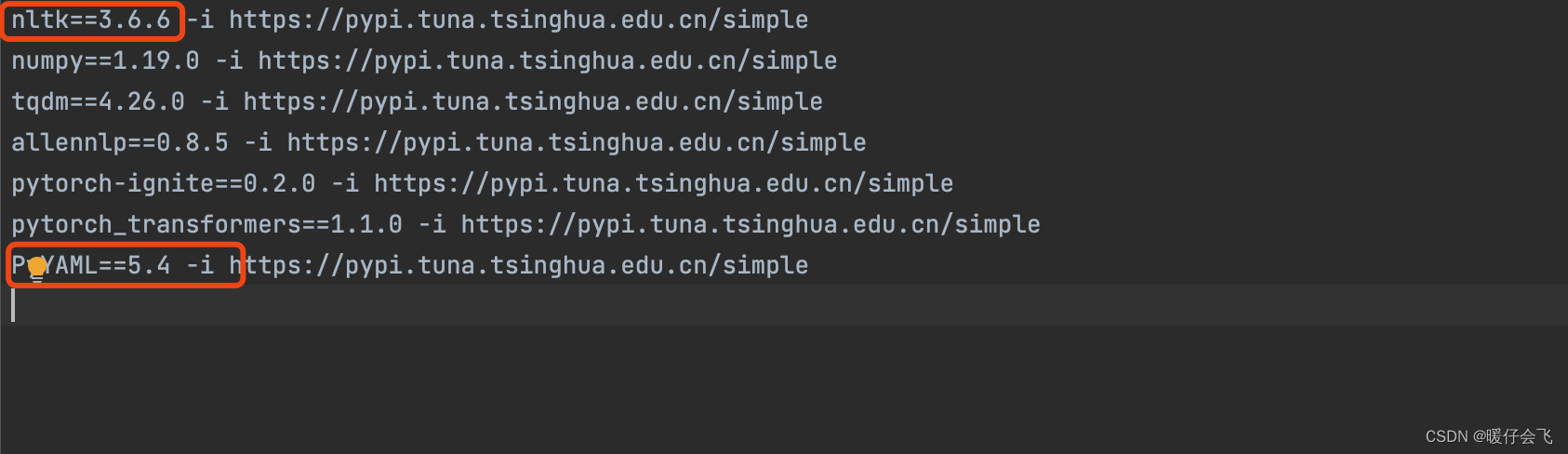
- 将
requirements.txt中的>=的符号全部改成一个确定的版本 - 然后为了速度,我给他们都加了清华源的后缀,最终我的
requirements.txt文件如下所示:
- 将
- 首先单独将 torch 安装好,也就是去 torch 的官网,找到 1.1 版本,然后用
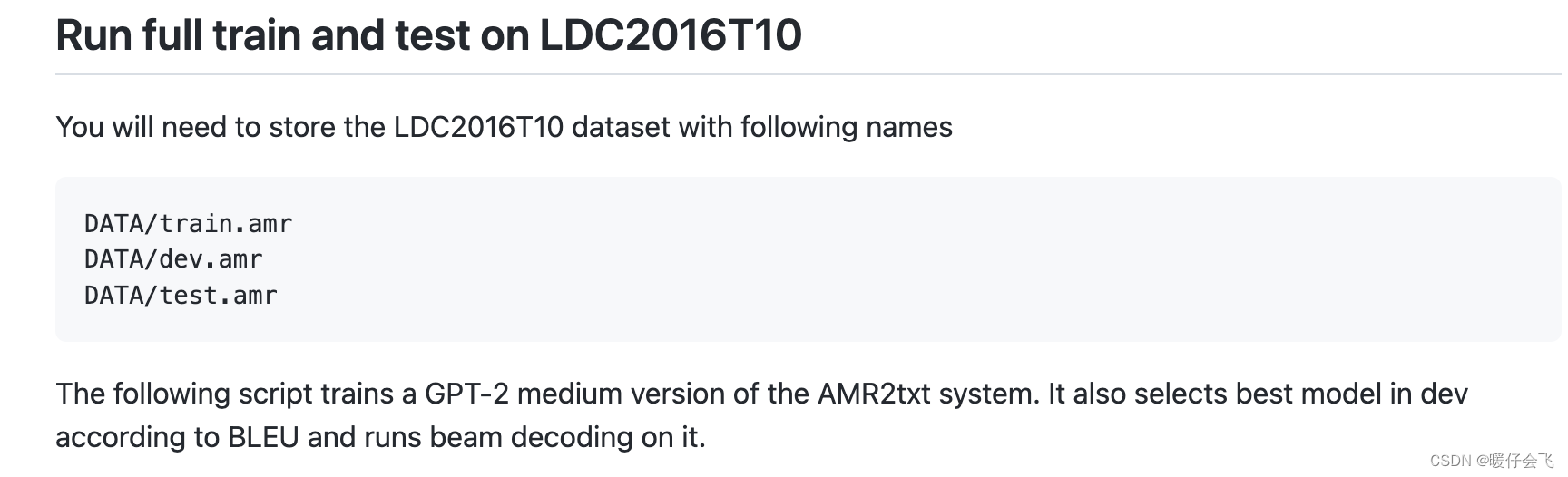
数据集
- 这个数据集他在 github 这里写错了,在论文里写的是
LDC2017T10

- 这个数据集的获取你必须参考我的另一篇 【文章】。在那里面我会详细地讲述如何处理
LDC2017T10数据集到本文要求的这种结构 - 文中强调要按照这个路径来保存数据集:
- 但是实际上从网站上下载下来的数据集的结构是这样的
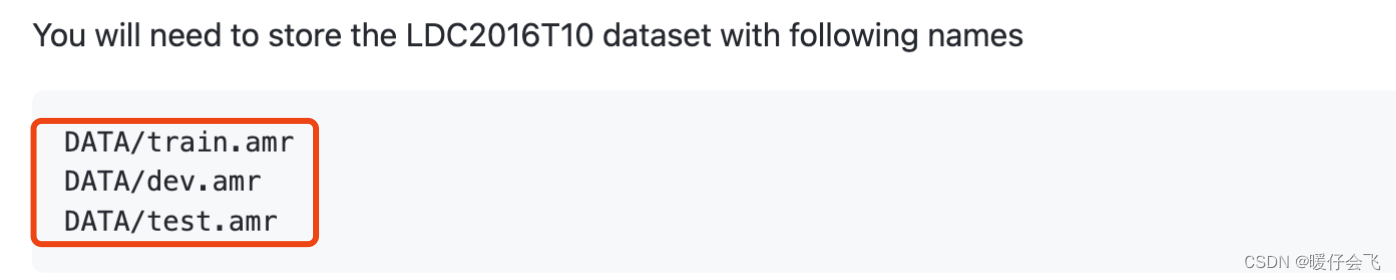
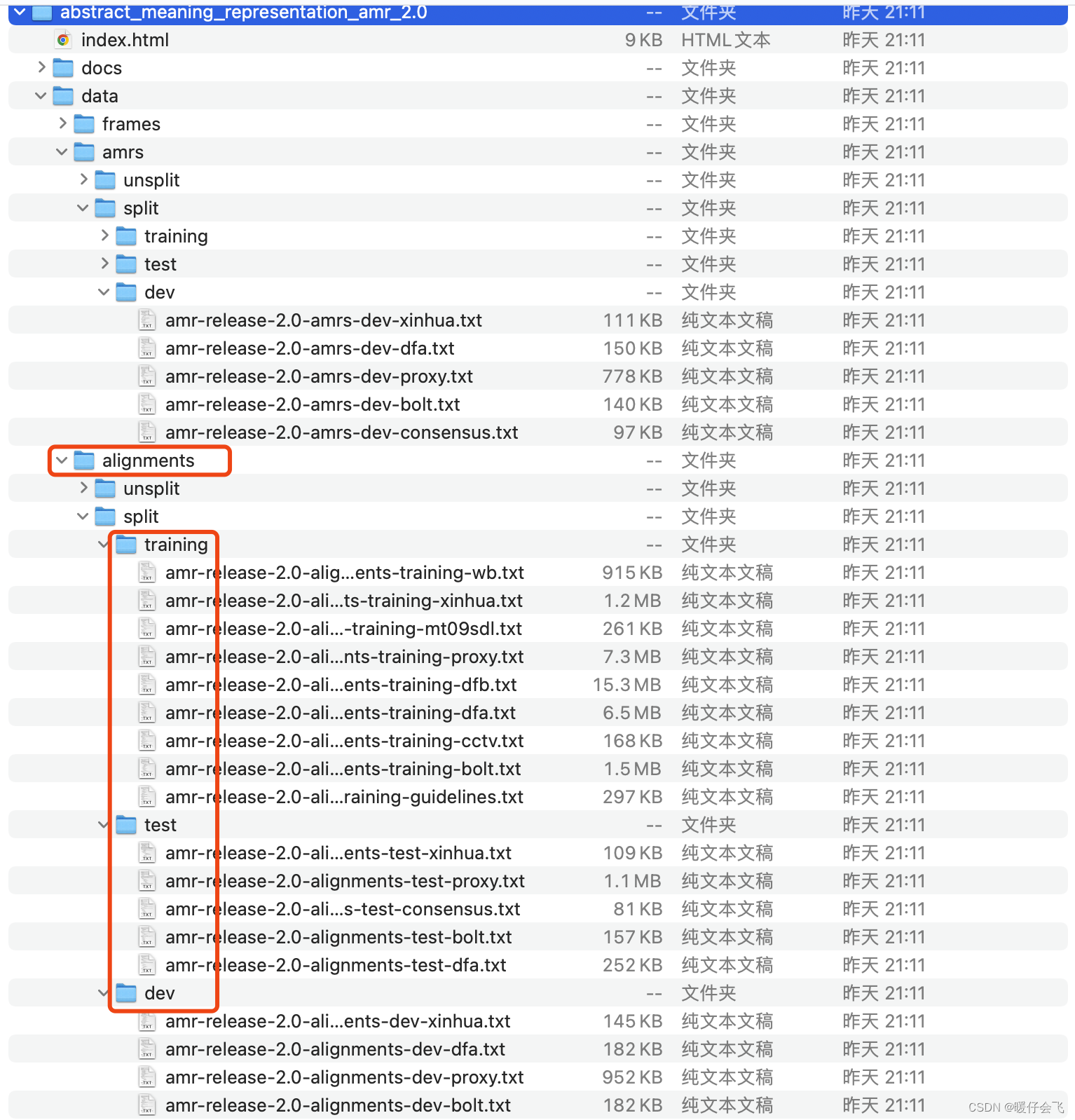
- 要得到 github 中规定的那种结构,需要按照 【文章】 对这个数据集进行预处理
-
如果你借鉴了那篇文章,最终可以得到这样的数据集结构:
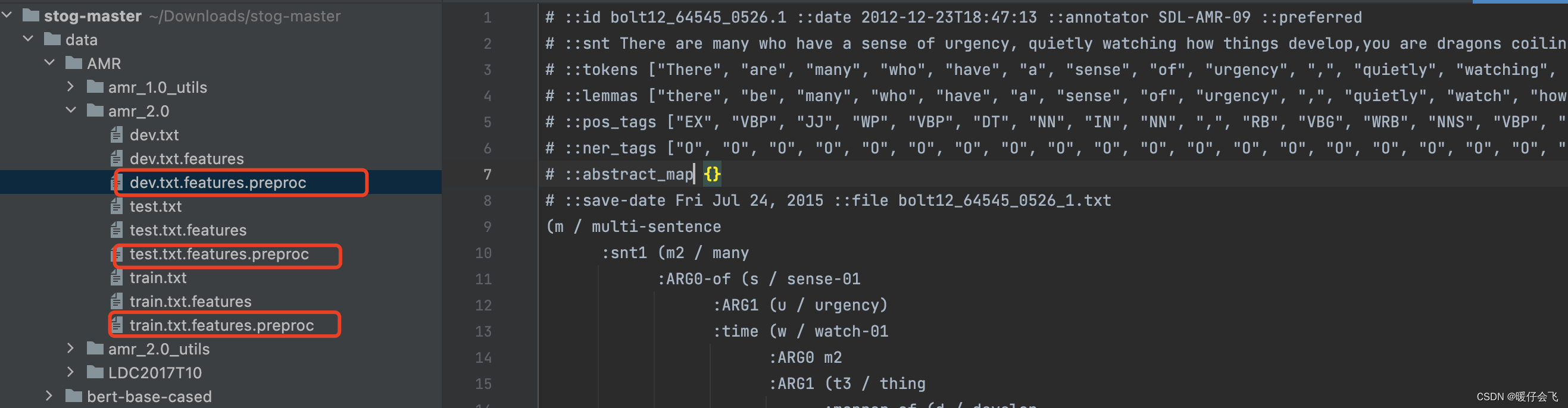
-
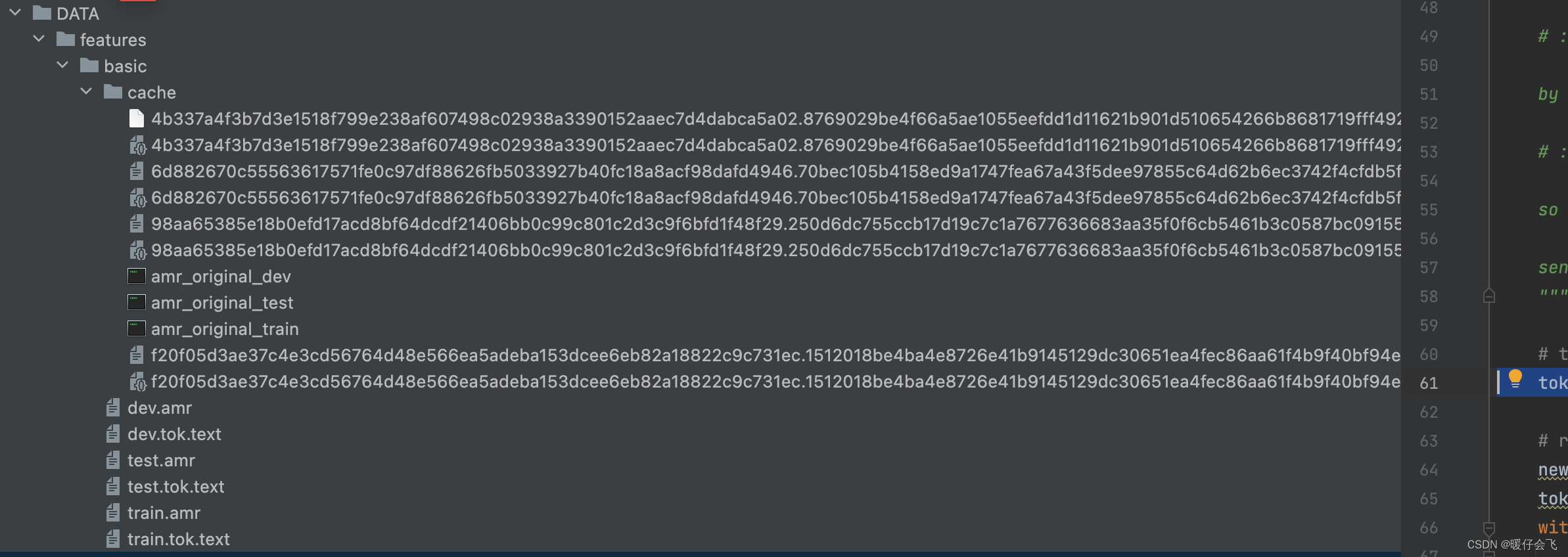
将这三个标红的文件复制到你当前
DATA文件路径下并分别改名成为train.amr,test.amr和dev.amr(友情提示:当你给这些文件改名的时候,不要在 pycharm 的项目中改,你最好打开 pycharm 这个项目所在的文件夹进行操作,因为你如果直接在 pycharm 这个界面中修改文件名称,可能导致与其相关联的一些引用发生改变)
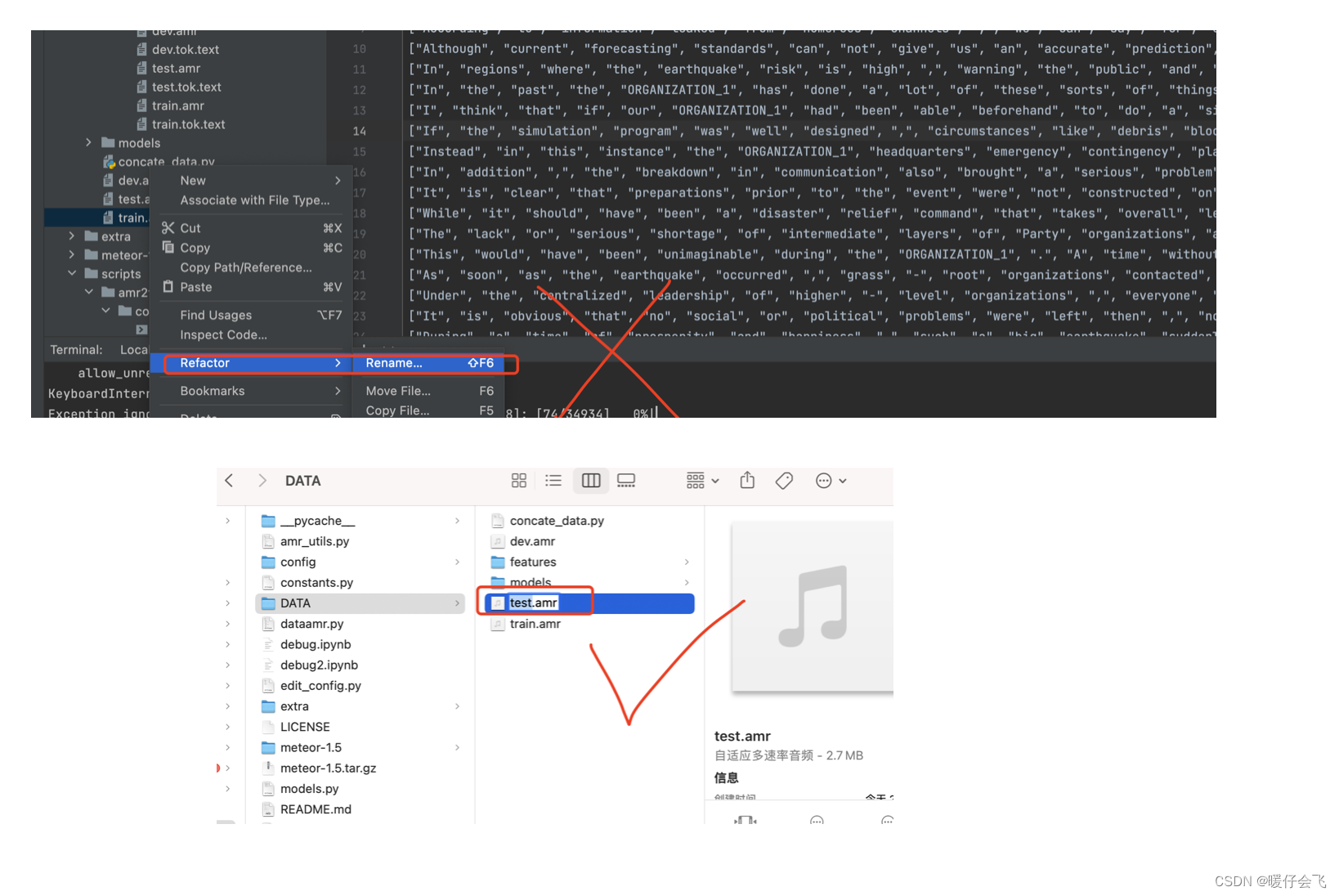
-
改完名称之后的目录应该长成下面的样子:

-
现在可以继续执行下面的步骤了
-
下载 GPT-2 预训练模型(medium尺寸的)并进行训练
解决作者的代码错误

- 当执行这一步脚本的时候,程序会根据
DATA中的三个文件夹生成feature/basic路径下train, dev和test所需要的所有文件,并且会帮你下载预训练模型 GPT-2,具体操作想研究的话可以去看看代码。
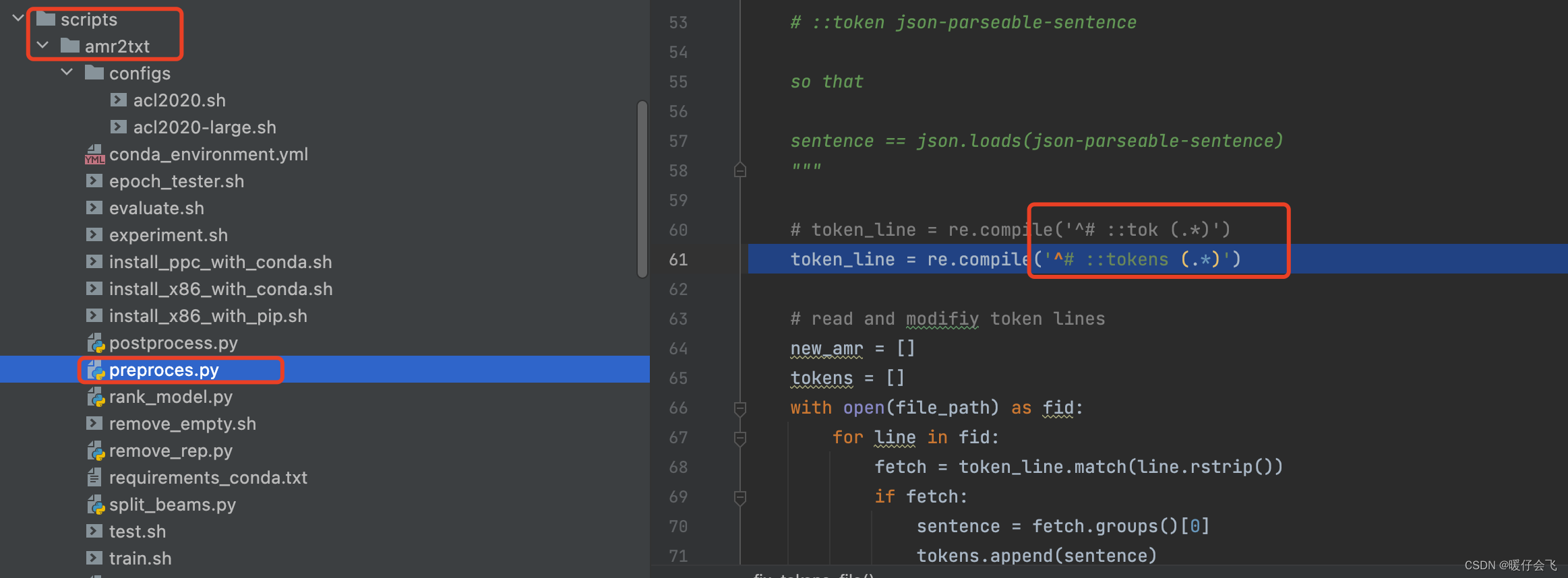
- 但是作者代码中写错了一个地方,导致我 debug 了好久好久好久才发现,我们需要首先改正这个地方,然后再去运行上述的
sh指令
- 作者原本在
scripts/amr2txt/preprocess.py中的写法是我注释掉的部分,正确的操作应该是我在图中红色圈出来的部分,也就是
token_line = re.compile('^# ::tokens (.*)')- 如果按照作者的写法,那么最终生成的
feature/basic/train.tok.text
feature/basic/dev.tok.text
feature/basic/test.tok.text
三个文件都会是空的
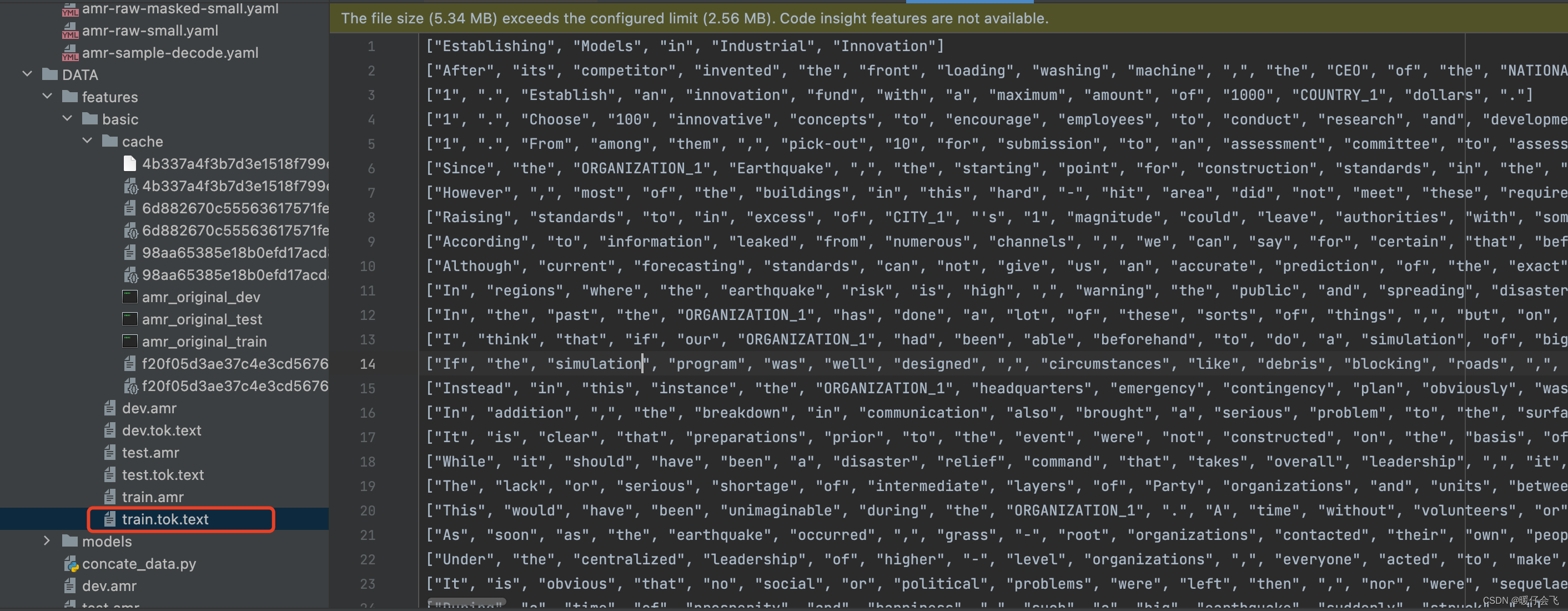
- 按照我的写法最终生成的那三个 tok.text 文件的内容大致如下图所示:
解决安装包的版本问题
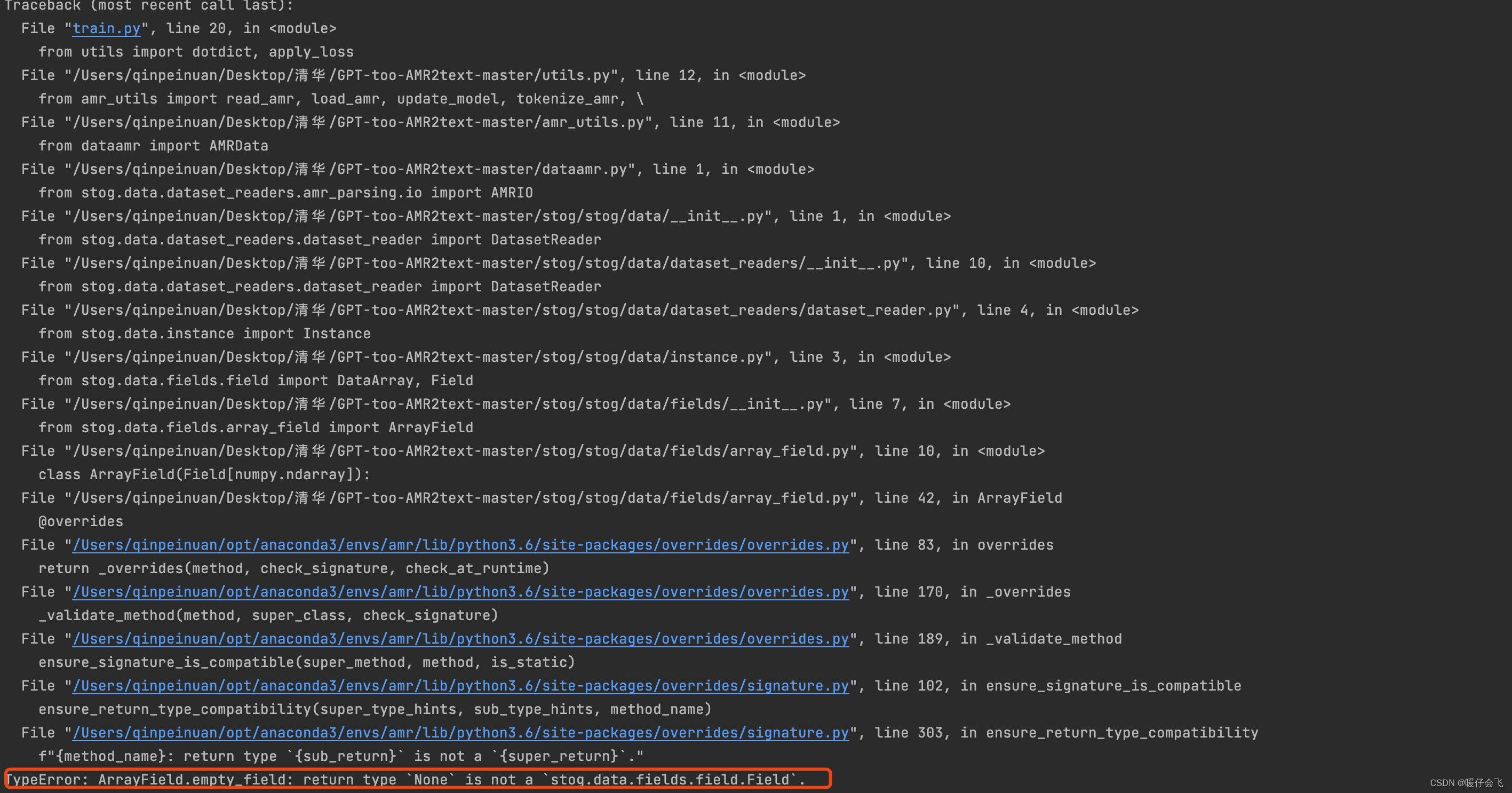
- 解决完作者本身存在的代码问题,当你重新执行上述的步骤时,依然可能报错,如果你报错的信息也是下图所示的这样:
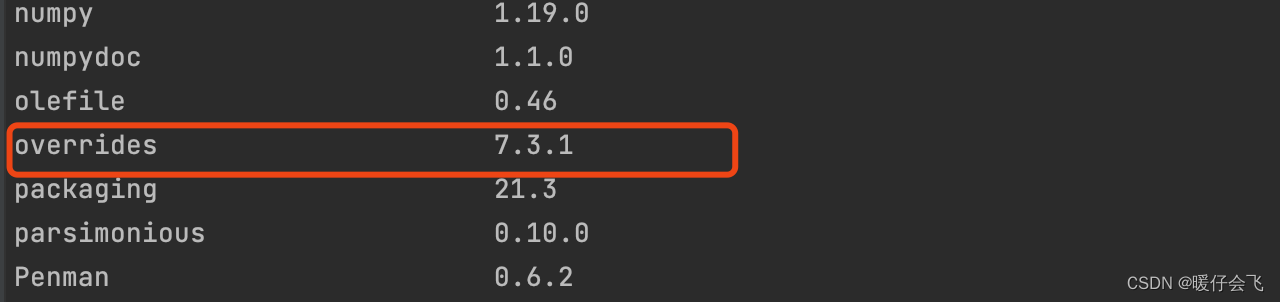
- 上网查了一下,原来是一个包的版本冲突,我默认安装的
overrides==7.3.1版本太高了,
- 只需要
pip install overrides==3.1.0即可解决- 解决这个问题的 参考网址
- 重新执行
bash scripts/amr2txt/experiment.sh scripts/amr2txt/configs/acl2020.sh,一切正常!
- 自动下载 GPT-2 的模型并进行训练,初始步骤算是完成了。
- 如果这个过程出现中断,请检查网络,或者使用 VPN,或者使用手机热点。我当时使用 VPN 和 wifi 都不太行,所以挂了手机热点下载成功的,大小 1.5G 左右。
总结
- 总体来说,作者在 github 上给出的步骤太过简略,没有阐明
DATA中数据的如何通过stog包预处理成可用的状态 - 关于上述问题,我专门写了一篇 文章 来教大家如何使用 stog 来生成这篇文章中要求的 DATA 结构
- 代码错误的存在也增加了调试的难度。代码的主要错误存在于:
scripts/amr2txt/preprocess.py文件
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/847321
推荐阅读
相关标签

