
- 1Pandas分组与排序_pandas分组排序
- 2苹果电脑批量生成准考证wps_wps批量制作准考证
- 3易语言tcp多线程服务端客户端_从TCP协议到TCP通信的各种异常现象和分析
- 4MySQL — 关联查询_mysql关联查询
- 5人工智能讲师咨询叶梓案例实战:人工智能在搜索引擎的应用目录信息自动抓取-2_智能咨询女
- 6【论文分享】基于微信小程序的快递取寄系统设计与实现_基于微信小程序的乡村快递代拿系统设计与实现
- 7劝人写码,千刀万剐——“前端已死”难道要成真了?
- 8PostgreSQL 中强大的全文搜索_postgresql 全文检索
- 9Centos的Filesystem中/dev/mapper/centos-root内存已满的解决办法_/dev/mapper/centos-root 满了
- 10MacBook IDEA 下载 安装 配置 使用_idea mac
Tied Block Convolution: 具有共享较薄滤波器的更简洁、更出色的CNN
赞
踩
摘要
https://arxiv.org/pdf/2009.12021.pdf
卷积是卷积神经网络(CNN)的主要构建块。我们观察到,随着通道数的增加,优化后的CNN通常具有高度相关的滤波器,这降低了特征表示的表达力。我们提出了Tied Block Convolution(TBC),它在等量的通道块上共享相同的较薄的滤波器,并使用单个滤波器生成多个响应。TBC的概念也可以扩展到组卷积和全连接层,并且可以应用于各种骨干网络和注意力模块。
我们在分类、检测、实例分割和注意力等方面进行了广泛的实验,结果表明,与传统的卷积和组卷积相比,TBC在各方面都取得了显著的增益。我们提出的TiedSE注意力模块甚至可以使用比SE模块少64倍的参数来实现相当的性能。特别地,标准的CNN往往在有遮挡的情况下无法准确地聚合信息,导致产生多个冗余的部分对象提议。通过跨通道共享滤波器,TBC减少了相关性,并可以有效地处理高度重叠的实例。当遮挡比为80%时,TBC将MS-COCO对象检测的平均精度提高了6%。我们的代码将会公开。
引言
卷积是卷积神经网络(CNN)的主要构建块,这些网络在图像分类(Krizhevsky、Sutskever和Hinton 2012;He等人2016;Xie等人2017;Simonyan和Zisserman 2014)、物体检测(Girshick 2015;Ren等人2015;He等人2017)、图像分割(Kirillov等人2019;Long、Shelhamer和Darrell 2015;Chen等人2017,2018)和动作识别(Ji等人2012;Wang等人2016;Carreira和Zisserman 2017;Wang等人2018)等任务中取得了广泛的成功。然而,标准的卷积在计算、存储和内存访问方面仍然成本高昂。更重要的是,优化后的CNN通常会发展出高度相关的滤波器。
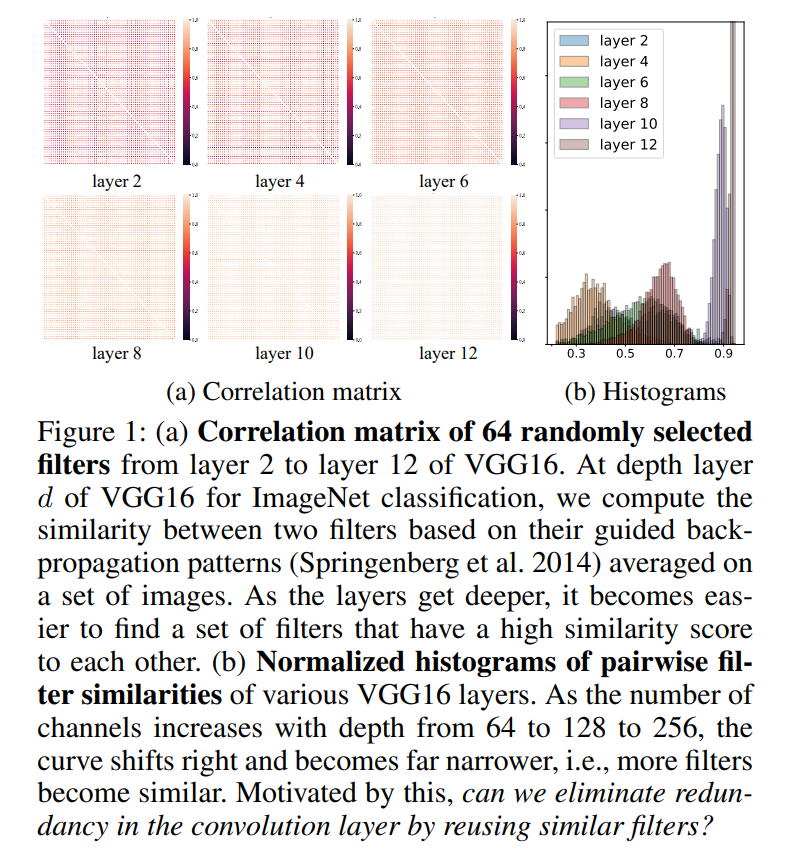
我们可以使用一组ImageNet图像的引导反向传播模式(Springenberg等人2014)的余弦相似度来评估标准卷积(SC)中滤波器对的相似性。图1显示,随着层深度的增加,滤波器的相关性也增加。也就是说,从早到晚的层中,滤波器变得更相似,降低了特征表示的表达力。
如何优化具有较少冗余的CNN一直是研究的重点(Howard等人2017;Zhang等人2018;Ma等人2018;Xie等人2017),通常是通过探索跨空间和通道维度的依赖关系来实现。在标准卷积(SC)中,虽然每个滤波器在空间上的大小有限,但它会扩展到完整的输入特征集,而在组卷积(GC)(Krizhevsky、Sutskever和Hinton 2012)中,滤波器只与输入特征的一个子集进行卷积。因此,如果有B组输入特征,每个GC层通过将每个滤波器的大小减少B倍来减少参数数量B倍。深度卷积(DW)是GC的一个极端情况,其中每个组只包含一个通道,从而最大限度地减少了参数数量。
虽然组卷积(GC)和深度卷积(DW)在减小模型大小方面很有效,但它们没有研究滤波器之间的相关性,并且它们的孤立表示无法捕获跨通道关系。与GC和DW中通过减小每个滤波器的大小来消除冗余不同,我们通过探索每个滤波器的潜力来探索另一种消除冗余的方法。直接减少滤波器的数量会降低模型容量(He等人2016)。然而,由于SC滤波器变得相似(图1),我们可以通过在不同的特征组之间重用它们来减少有效滤波器的数量。我们提出了一种名为Tied Block Convolution(TBC)的简单替代方案:我们将C个输入特征通道分成B个相等的块,并使用仅定义在
C
B
\frac{C}{B}
BC个通道上的单个块滤波器来产生B个响应。图2显示,一个SC滤波器跨越整个C通道,而在B=2时,我们的TBC仅跨越
C
2
\frac{C}{2}
2C个通道,但它也产生2个滤波器响应。TBC是跨组共享的GC,当B=1时,TBC简化为SC。通过将此概念扩展到全连接层和组卷积层,可以直接得到Tied Block Group Convolution(TGC)和Tied Block Fully Connected Layer(TFC)。
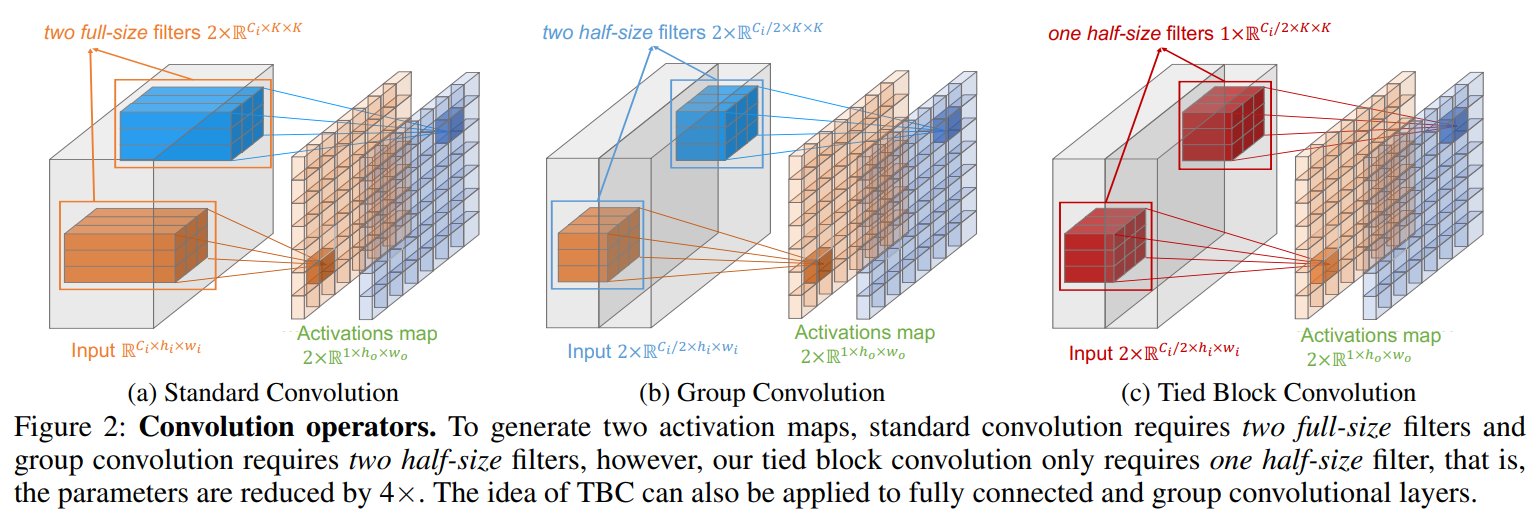
我们的TBC更有效地利用了每个滤波器、内存访问和样本。1)在B=2时,TBC使用了一个减半大小的薄滤波器来获得相同数量的响应,接近相同大小的SC输出,但模型大小减少了4倍。2)由于相同的薄滤波器被应用于每个B块,TBC通过利用GPU并行处理更有效地进行内存访问。3)由于每个薄滤波器在B倍的更多样本上进行训练,学习也变得更加有效。4)由于每组TBC滤波器都应用于所有输入通道,TBC可以跨通道聚合全局信息,并更好地建模跨通道依赖关系。
虽然TBC在理论上似乎是一个吸引人的概念,但我们能否在实践中证明其相对于SC或GC的优势将严重依赖于神经网络架构。我们将TBC/TGC/TFC应用于各种骨干网络,包括ResNet(He等人2016)、ResNeXt(Xie等人2017)、SENet(Hu、Shen和Sun 2018)和ResNeSt(Zhang等人2020),并提出了它们的绑定版本:TiedResNet、TiedResNeXt、TiedSENet和TiedResNeSt。我们对分类、检测、分割和注意力进行了广泛的实验,这些实验表明TBC/TGC/TFC在标准卷积、组卷积和全连接层上的全面性能都有显著提升。例如,图6显示了TiedResNet始终优于ResNet、ResNeXt和HRNetV2(Wang等人2019),并且模型更精简。在各种框架、任务和数据集中也获得了类似的性能提升和模型简化。
最后,学到的滤波器冗余不仅会在膨胀的尺寸下降低模型容量,还会使CNN无法捕获多样性,从而导致性能较差。对于MS-COCO上的目标检测,标准CNN往往无法准确定位目标对象区域并从前景中汇总有用信息。因此,存在多个重叠的部分对象建议,导致无法从建议池中产生单个完整对象建议。TiedResNet可以更好地处理高重叠实例,并在遮挡比为0.8时将平均精度(AP)提高6%,将IoU = 0.75时的A P提高8.3%。
相关工作
骨干网络。AlexNet(Krizhevsky,Sutskever和Hinton 2012)是在ILSVRC竞赛中首次取得显著精度提升的CNN。然而,较大的内核和全连接层极大地增加了模型的大小。使用较小的内核,GoogleNet(Szegedy等人,2015)和VGGNet(Simonyan和Zisserman 2014)仅需要比(Krizhevsky,Sutskever和Hinton 2012;Zeiler和Fergus 2014)少12倍的参数就能取得更好的性能。然而,网络深度过大会导致梯度消失问题,这在ResNet(He等人,2016)中的残差连接设计中得到了解决。由于模型的深度不再是问题,研究人员开始探索如何更有效地使用参数。在具有可比模型复杂性的情况下,ResNeXt(Xie等人,2017)在许多主要任务中优于ResNet,这主要是由于使用了高效的组卷积。通过精心设计架构,HRNetV2(Wang等人,2019)在多个主要任务上实现了最先进的性能。与这些使用GC或SC的工作相比,我们的TBC进一步发挥了每个更薄滤波器的全部潜力。我们在后面的部分中提供了与这些网络的比较。
分组卷积。组卷积(GC)(Krizhevsky,Sutskever和Hinton 2012)旨在消除滤波器冗余。由于每个GC滤波器仅与其组内的特征进行卷积,具有相同数量的通道,因此该机制可以通过因子B减少每层的参数数量,其中B是组的数量。当组的数量与输入特征的数量相同时,GC变得与深度卷积(DW)(Howard等人,2017)相同。GC和DW都通过减小每个滤波器的大小来极大地减少模型冗余。然而,它们从未研究过(学习的)滤波器之间的相关性。
由于GC和DW中的每个滤波器仅对部分输入特征图进行响应,因此在GC中损害了跨通道维度融入全局信息的能力,而在DW中则完全丧失了这种能力。相比之下,我们的TBC滤波器在所有输入通道之间是共享的,并且可以聚合长距离依赖关系。这种机制还带来了另一个好处,即我们的TBC只有一个碎片。因此,TBC可以充分利用GPU的强大并行计算能力。
注意力模块。(Hu,Shen和Sun 2018)引入了squeeze-and-excitation(SE)模块,以自适应地重新校准通道特征响应。(Cao等人,2019)将SE和非局部(Wang等人,2018)模块统一到一个全局上下文块(GCB)中。虽然SE和GCB相对较轻,但SE(GCB)仍占模型大小的10%(25%)。我们的绑定块卷积和绑定全连接层可以集成到各种注意力模块中,并显着减少参数数量:对于SE,2.53 M对比0.04 M;对于GCB,10 M对比2.5 M。
Tied Block Convolution 网络设计
我们首先分析TBC和TGC来指导我们的网络设计。我们还开发了TFC并将其应用于注意力模块。
TBC公式化
让我们将输入特征表示为 X ∈ R c i × h i × w i X \in \mathbb{R}^{c_{i} \times h_{i} \times w_{i}} X∈Rci×hi×wi,将输出特征表示为 X ~ ∈ R c o × h o × w o \tilde{X} \in \mathbb{R}^{c_{o} \times h_{o} \times w_{o}} X~∈Rco×ho×wo,其中 (c, h, w) 分别是特征映射的通道数、高度和宽度。为了清晰起见,我们忽略了偏置项。卷积核的大小为 k × k k \times k k×k。
标准卷积,用 ( * ) 表示,可以公式化为:
X
~
=
X
∗
W
\tilde{X}=X * W
X~=X∗W
Group Convolution first divides input feature X into G equal-sized groups X_{1}, \ldots, X_{G} with size c_{i} / G \times h_{i} \times w_{i} per group. Each group shares the same convolutional filters W_{g} . The output of GC is computed as:
其中, W ∈ R c o × c i × k × k W \in \mathbb{R}^{c_{o} \times c_{i} \times k \times k} W∈Rco×ci×k×k是空间卷积SC的卷积核。因此,空间卷积(SC)的参数数量为: c o × c i × k × k c_{o} \times c_{i} \times k \times k co×ci×k×k。
分组卷积首先将输入特征X分成 G 个大小相等的组
X
1
,
…
,
X
G
X_{1}, \ldots, X_{G}
X1,…,XG,每组的大小为
c
i
/
G
×
h
i
×
w
i
c_{i} / G \times h_{i} \times w_{i}
ci/G×hi×wi。每个组共享相同的卷积滤波器
W
g
W_{g}
Wg。分组卷积的输出计算如下:
X
~
=
X
1
∗
W
1
⊕
X
2
∗
W
2
⊕
⋯
⊕
X
G
∗
W
G
\tilde{X}=X_{1} * W_{1} \oplus X_{2} * W_{2} \oplus \cdots \oplus X_{G} * W_{G}
X~=X1∗W1⊕X2∗W2⊕⋯⊕XG∗WG
其中, ⊕ \oplus ⊕ 表示沿通道维度的拼接操作, W g W_{g} Wg 是第g组的卷积滤波器,其中 g ∈ 1 , … , G g \in {1, \ldots, G} g∈1,…,G,且 W g ∈ R c o G × c i G × k × k W_{g} \in \mathbb{R}^{\frac{c_{o}}{G} \times \frac{c_{i}}{G} \times k \times k} Wg∈RGco×Gci×k×k。分组卷积(GC)的参数数量为: G × c o G × c i G × k × k G \times \frac{c_{o}}{G} \times \frac{c_{i}}{G} \times k \times k G×Gco×Gci×k×k。
绑定块卷积(Tied Block Convolution)通过以下公式在不同的特征组之间重用滤波器,从而减少了有效滤波器的数量:
X
~
=
X
1
∗
W
′
⊕
X
2
∗
W
′
⊕
⋯
⊕
X
B
∗
W
′
\tilde{X}=X_{1} * W^{\prime} \oplus X_{2} * W^{\prime} \oplus \cdots \oplus X_{B} * W^{\prime}
X~=X1∗W′⊕X2∗W′⊕⋯⊕XB∗W′
X ~ = X 1 ∗ W ′ ⊕ X 2 ∗ W ′ ⊕ ⋯ ⊕ X B ∗ W ′ \tilde{X}=X_{1} * W^{\prime} \oplus X_{2} * W^{\prime} \oplus \cdots \oplus X_{B} * W^{\prime} X~=X1∗W′⊕X2∗W′⊕⋯⊕XB∗W′ 其中 W ′ ∈ R c o B × c i B × k × k W^{\prime} \in \mathbb{R}^{\frac{c_{o}}{B} \times \frac{c_{i}}{B} \times k \times k} W′∈RBco×Bci×k×k 是所有组之间共享的TBC滤波器。参数数量为: c o B × c i B × k × k \frac{c_{o}}{B} \times \frac{c_{i}}{B} \times k \times k Bco×Bci×k×k。
TBC与GC的比较。虽然TBC是跨组共享滤波器的GC,但在实际应用结果中,它与GC存在几个主要区别(假设 (B=G))。
- TBC的参数数量比GC少B倍。
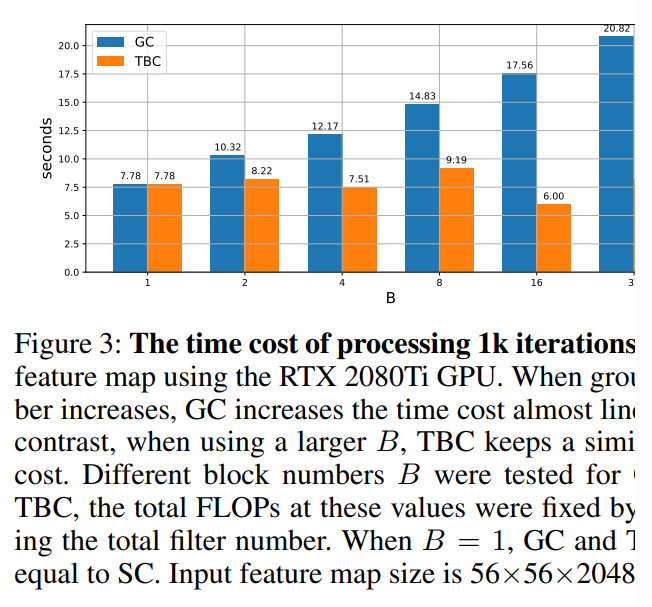
- TBC在GPU利用率上只有一个碎片,而GC有 G个碎片,大大降低了并行度。图3显示,GC的处理时间随着组数的增加而线性增加,而我们的TBC几乎保持相同的处理时间。
- TBC能更好地建模跨通道依赖。由于每组GC滤波器仅在通道的子集上进行卷积,因此GC在跨通道聚合全局信息时遇到困难。然而,每组TBC滤波器应用于所有输入通道,并能更好地建模跨通道依赖。
- 基于TBC的TiedResNet在目标检测和实例分割任务中大大超过了集成GC的ResNeXt。TiedResNet-S甚至可以在模型大小减少两倍的情况下超过ResNeXt,这表明TiedResNet更有效地利用了模型参数。
捆绑块组卷积(TGC)捆绑块滤波的思想也可以直接应用于组卷积,表述为:
X
~
=
(
X
11
∗
W
1
′
⊕
⋯
⊕
X
1
B
∗
W
1
′
)
⊕
⋯
⊕
(
X
G
1
∗
W
G
′
⊕
⋯
⊕
X
G
B
∗
W
G
′
)
˜X=(X11∗W′1⊕⋯⊕X1B∗W′1)⊕⋯⊕(XG1∗W′G⊕⋯⊕XGB∗W′G)
其中, W g ′ ∈ R c o B G × c i B G × k × k , X g b ∈ R c i B G × h i × w i W_{g}^{\prime} \in \mathbb{R}^{\frac{c_{o}}{B G} \times \frac{c_{i}}{B G} \times k \times k},X_{g b} \in \mathbb{R}^{\frac{c_{i}}{B G} \times h_{i} \times w_{i}} Wg′∈RBGco×BGci×k×k,Xgb∈RBGci×hi×wi 是分割后的特征图, g ∈ [ 1 , G ] g \in[1, G] g∈[1,G]和 b ∈ [ 1 , B ] b \in[1, B] b∈[1,B]。
捆绑块全连接层(TFC)卷积是全连接(FC)层的一种特殊情况,正如FC是卷积的一种特殊情况一样。我们将相同的捆绑块滤波思想应用于FC。捆绑块全连接层(TFC)在输入通道的相等块之间共享FC连接。与TBC一样,TFC可以减少B^{2}倍的参数和B倍的计算成本。
在瓶颈模块中的TBC/TGC
ResNet/ResNeXt/ResNeSt的瓶颈模块具有1x1和3x3的卷积滤波器。我们按照图4所示的不同方式应用TBC/TGC。对于ResNet和ResNeXt中的3x3卷积,我们将所有滤波器分组;每个组都有自己的TBC/TGC设置。这种选择允许不同程度的共享,并受到网络可视化工作(Zeiler和Fergus 2014;Bau等人2017)的启发:在不同层中,滤波器扮演着不同的角色,其中一些是独特的概念检测器(Agrawal,Carreira和Malik 2015;Bau等人2017)。对于瓶颈入口和出口的1x1卷积,我们用B=2的TBC替换入口卷积,以允许滤波器共享,同时保持出口卷积以跨通道聚合信息。由于ResNeSt将3x3卷积替换为多路径和具有k个基数的分割注意力模块,因此3x3卷积占整体模型复杂性的比例较小。因此,我们仅将所有3x3卷积替换为B=2的TBC,如1x1卷积所示。进一步增加B只会略微减少模型参数,但会大大降低性能。
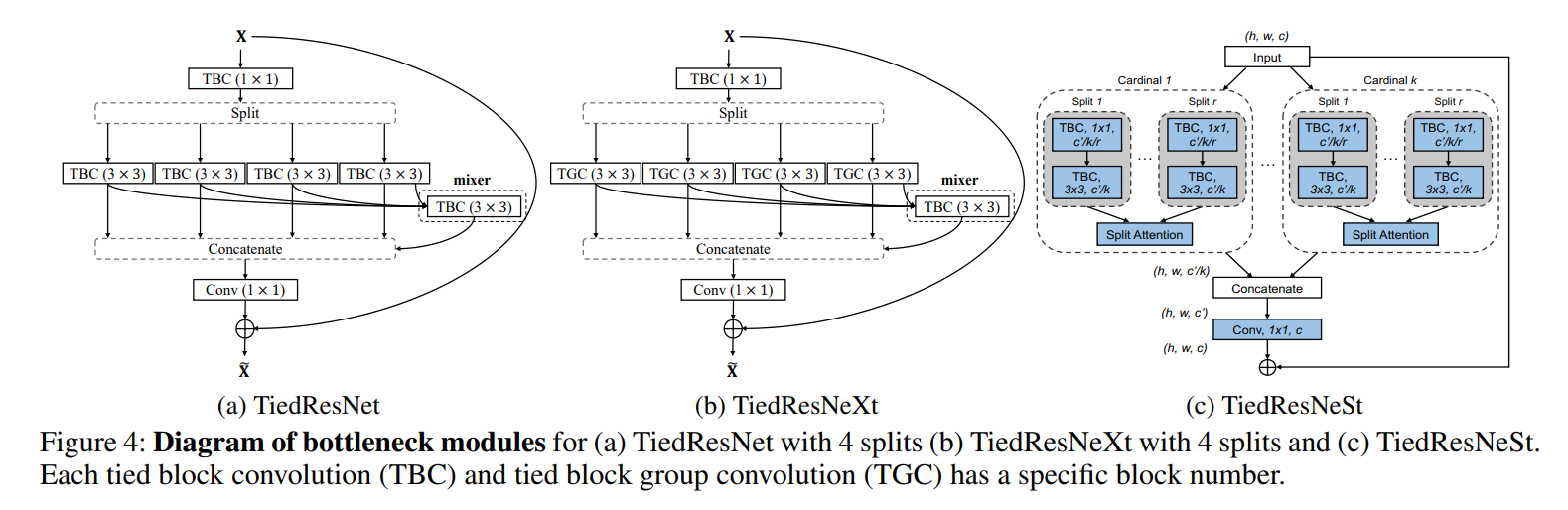
对于TiedResNet-50(TiedResNeXt-50)的默认设置是4个分组,基础宽度为32(64),即 4 s × 32 w ( 4 s × 64 w ) 4 \mathrm{~s} \times 32 \mathrm{w}(4 \mathrm{~s} \times 64 \mathrm{w}) 4 s×32w(4 s×64w),而对于TiedResNet-S(TiedResNeXt-50 S)的默认设置是 4 s × 18 w ( 4 s × 36 w ) 4 \mathrm{~s} \times 18 \mathrm{w}(4 \mathrm{~s} \times 36 \mathrm{w}) 4 s×18w(4 s×36w)。我们的TiedBottleNeck在ImageNet-1K上的top-1准确率方面提高了1%以上的性能。然而,失去跨通道集成可能会削弱模型。为了弥补这一点,我们引入了一个融合器,用于融合多个分组的输出。引入融合器可使性能再提高0.5%。融合器的输入可以是分组输出的拼接或逐元素求和。表6显示逐元素求和具有更好的权衡。
TBC和TFC在注意力模块中的应用
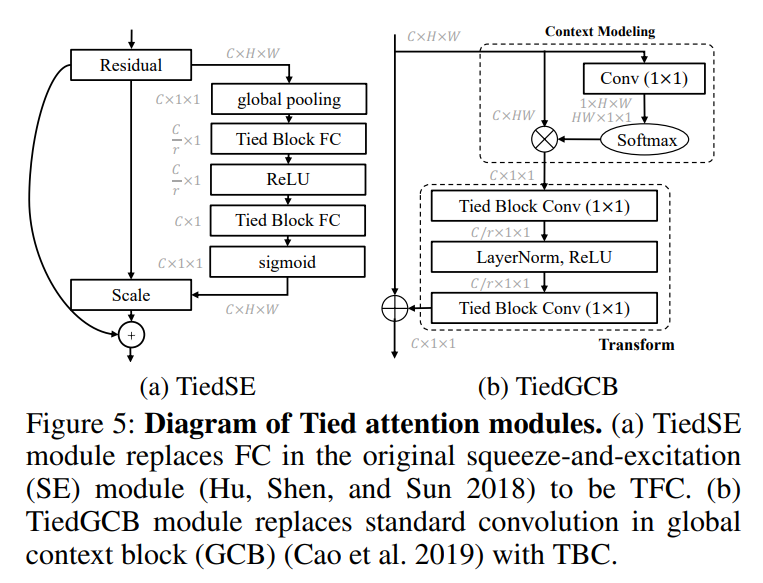
我们将TBC和TFC应用于注意力模块,如SE(Hu,Shen和Sun 2018)和GCB(Cao等人2019),只需将其中的SC和FC替换为对应的捆绑块(图5)即可。这两种设计都显著减少了参数数量,同时没有降低性能。
实验结果
我们在对象识别、对象检测、实例分割和注意力等主要基准测试集上,对TBC、TGC和TFC进行了广泛的测试。
ImageNet分类
实现方法。我们遵循标准实践,使用随机裁剪进行数据增强,将图像大小调整为224x224像素(He等人,2016年)。我们使用SGD进行网络训练,动量设置为0.9,在8个GPU上使用256个样本的小批量。初始学习率设置为0.1,然后在30个周期后衰减10倍,总共训练100个周期。
性能提升。表1比较了多个模型在ImageNet-1k(Deng等人,2009年)验证集上的识别准确率。在表1中,TiedResNet50-S在top-1准确率上超过了ResNet50,但只使用了60%的浮点运算和54%的参数。类似地,TiedResNet101-S也超过了ResNet101。在相似的模型复杂度下,TiedResNet50和TiedResNet101分别比基准模型高出1.5%和1.4%的准确率,同时参数减少了10%。对于TiedResNeXt和TiedSENet也可以观察到类似的趋势。为了进一步证明TBC的有效性,我们将其与当前的SOTA模型ResNeSt集成。TiedResNeSt-50-S仅使用59%的参数和82%的计算成本,在ImageNet-1k上的性能优于ResNeSt-50-S。

物体检测和实例分割
MS-COCO(Lin等人,2014年)包含80个对象类别,分别有118K/5K/208K张图像用于训练(train-2017)、验证(val-2017)和测试(test-2017)。评估平均精度(AP)从IoU阈值0.5到0.95,间隔为0.05。报告了不同质量下的检测性能,即AP50和AP75,以及不同尺度下的APs、APm和APl。所有模型都在train-2017子集上进行训练,并在val-2017上报告结果。
实现方法。我们在PyTorch实现的(Chen等人,2019年)检测器中使用基准骨干网络和我们的TiedResNet模型。图像的长边和短边分别调整至最大1333和800,同时保持纵横比不变。由于1x学习率调度(LS)是不足的,因此我们只在基线和我们的模型上报告2xLS的结果。
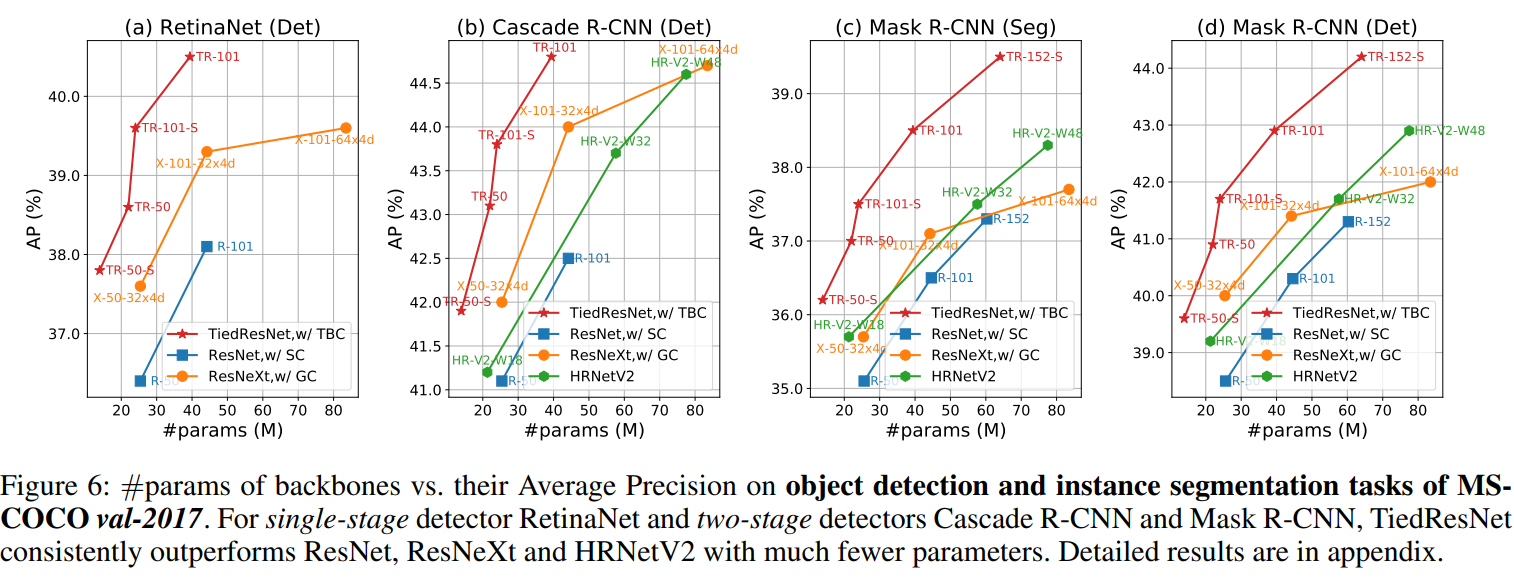
结果。我们在多个最先进的框架上,包括单阶段检测器RetinaNet(Lin等人,2017年)和两阶段检测器及Mask R-CNN(He等人,2017年),与ResNeXt和ResNet进行了彻底的比较,如图6所示。由于(Chen等人,2019年)重新实现的结果通常比原始论文中的结果更好,因此我们报告了重新实现的结果以进行公平比较。
物体检测。如图6所示,使用TiedResNet作为骨干网络,单阶段检测器RetinaNet和两阶段检测器Cascade R-CNN以及Mask R-CNN在框AP方面始终比基准模型高出2%到2.5%。在RetinaNet上的TiedResNet101甚至大大超过了重量更大的ResNeXt101-64×4d。在各种框架和Pascal VOC(Everingham等人,2015年)上的详细比较见附录材料。
实例分割。使用轻量级的TiedResNet-S和大小相当的TiedResNet骨干网络,我们观察到APmask分别增加了1.1%和2.1%。无论基准检测器有多强大,我们总是观察到AP的提升,这证实了TBC的有效性。高度遮挡的实例。由于遮挡要求网络准确检测目标区域并同时区分不同的实例,因此具有大遮挡的图像上的性能揭示了网络的定位能力。每个图像的遮挡比率(r)为:
r
=
total overlap area
total instance area
r=\frac{\text { total overlap area }}{\text { total instance area }}
r= total instance area total overlap area
平均精度(AP)是在IoU从0.5到0.95的范围内计算的,而在IoU=0.75时的AP(即AP75)则作为标准和限制性的评估指标。图7a和图7b显示,ResNet受到遮挡的影响很大,在遮挡比率r=0.8时,AP75下降了6%以上,而我们的TiedResNet仅轻微下降了0.7%,超过了基线8.3%。同样,随着遮挡率的增加,AP的提升从2.8%增加到5.9%。这些在MS-COCO上的定量结果表明,TiedResNet在处理高度重叠的实例方面具有强大的能力,特别是在限制性评估指标上。图7c显示,TiedResNet具有更少的错误正例提议和更好的分割质量。

轻量级注意力
图5展示了我们的轻量级注意力模块。当B=1时,SE模块可以看作是我们TiedSE的一个特例;同样,GCB是TiedGCB在B=1时的情况。
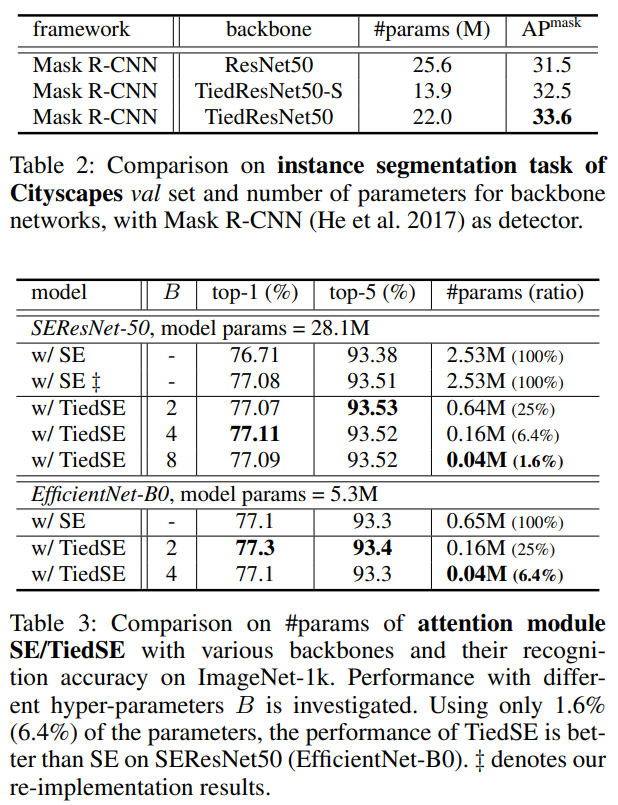
TiedSE的结果。表3中的所有实验对于基准模型和我们的模型都使用了16的降维比率。我们调查了TFC层的几个超参数设置。由于我们重新实现的基准结果比(Hu,Shen,和Sun 2018)中的结果更好,因此我们报告了我们的结果以进行公平比较。虽然SE是轻量级的,但它仍然占用了模型总参数的10%。表3显示,在B=8时,通过64倍的参数减少,TiedSE仍然获得了可比的性能。TiedSE不仅在SEResNet上显著减少了参数而没有牺牲性能,而且在移动架构EfficientNet(Tan和Le 2019)上也同样如此。
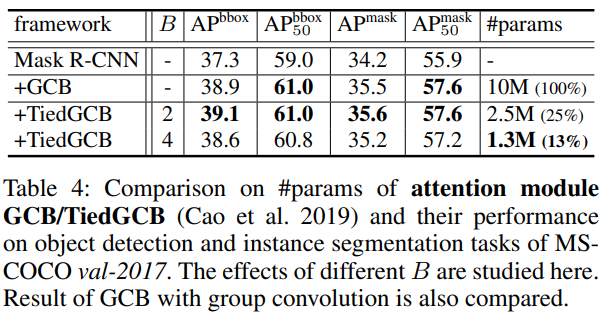
TiedGCB的结果。全局上下文块(GCB)(Cao等人,2019年)通过全局上下文建模和长距离依赖关系增强了分割和检测预测。将GCB与TBC结合,可以在不损失性能的情况下显著减少参数数量。表4显示,TiedGCB在参数减少16倍的情况下,分别实现了1.8%和1.4%的mAPmask和mAPbbox提升。虽然组卷积可以通过2倍的方式减少参数,但由于每个GC滤波器只看到特征的一个子集,因此建模跨通道依赖性的能力也会降低,导致mAPmask和mAPbbox分别下降了0.4%。

消融研究
分割数量的影响。根据(Zeiler和Fergus 2014;Bau等人2017;Xu等人2015)的研究,对应于各种视觉概念(如颜色、纹理、对象、部分、场景、边缘和材料)的单元/滤波器的比例是不同的,具有不同级别的可解释性(Agrawal,Carreira,和Malik 2015;Bau等人2017)。对于不同级别的共享,将不同的功能滤波器分组在一起可能是有用的。在表5中,我们将3x3卷积层中的所有通道分成s个分割。每个分割的基础宽度为w,B对于四个3x3的TBC层中的每一个分别是1、2、4、8,在4s×32w的设置中。在表5中,最佳的性能和模型复杂度的权衡可以在4s×32w时达到。表5还显示了将输入特征图分割成几个块的必要性,当只有2个分割时,top-1准确率将下降0.4%。
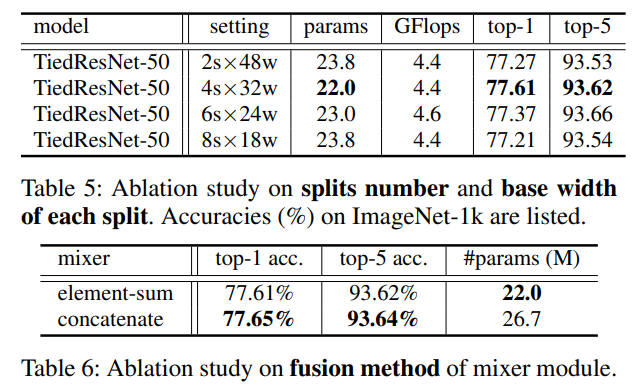
TiedBottleneck中的Mixer模块。由于我们将输入特征图分割成多个部分,因此这些部分之间的相互依赖关系会丢失。为了跟踪这种相互依赖关系,我们使用了Mixer来聚合跨分割的信息。在表6中,我们调查了几种融合方法。使用拼接(concatenation)达到了最高的准确率,但它引入了更多的参数。因此,我们选择元素级求和(elementwise-sum)作为融合函数,以在准确率和模型大小之间取得平衡。
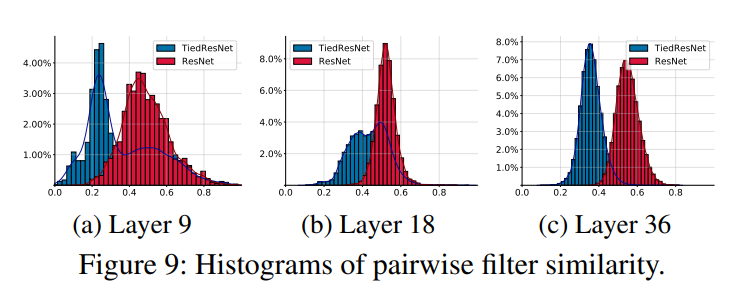
滤波器相似性。我们使用ImageNet预训练的ResNet50和TiedResNet50-S来比较不同层之间的余弦滤波器相似性。我们使用1000个ImageNet验证集分割中滤波器引导的反向传播模式(Springenberg等人,2014年)之间的成对余弦相似度平均值来生成这些直方图。如图9所示,x轴是余弦相似度,y轴是概率密度。与VGG(Simonyan和Zisserman,2014年)相比,ResNet(He等人,2016年)的冗余更少,而我们的TiedResNet具有最低的相似性,因此在整个深度层中消除了大多数冗余,这验证了我们的假设和动机。
Grad-CAM可视化。为了定性比较不同的基础网络,我们使用了来自ImageNet的图像,应用了gradCAM(Selvaraju等人,2017年)。Grad-CAM利用流入CNN最后一个卷积层的梯度信息来理解每个神经元。生成的定位图强调了图像中对于预测概念的重要区域,并反映了网络在目标对象区域利用信息的能力。图A.1显示,与ResNet和ResNetX相比,TiedResNet更准确地关注目标对象,这表明性能的提升来自于准确的注意力和对无关杂乱的减少。
这一特性对于目标检测和实例分割等任务非常有用,因为这些任务要求网络更准确地关注目标区域并从其中聚合特征。对目标区域的不正确关注也会导致大量的假阳性建议(图7c)。
总结
我们提出了Tied Block Convolution(TBC),它在等量的通道块上共享相同的较薄滤波器,并使用单个滤波器产生多个响应。TBC的概念还可以扩展到组卷积和全连接层,并可以应用于各种基础网络和注意力模块,同时基线性能得到一致的提升。基于TBC的TiedResNet也超过了基线,具有更高的参数使用效率和更好的检测严重遮挡物体的能力。
补充资料
物体检测和实例分割的详细结果
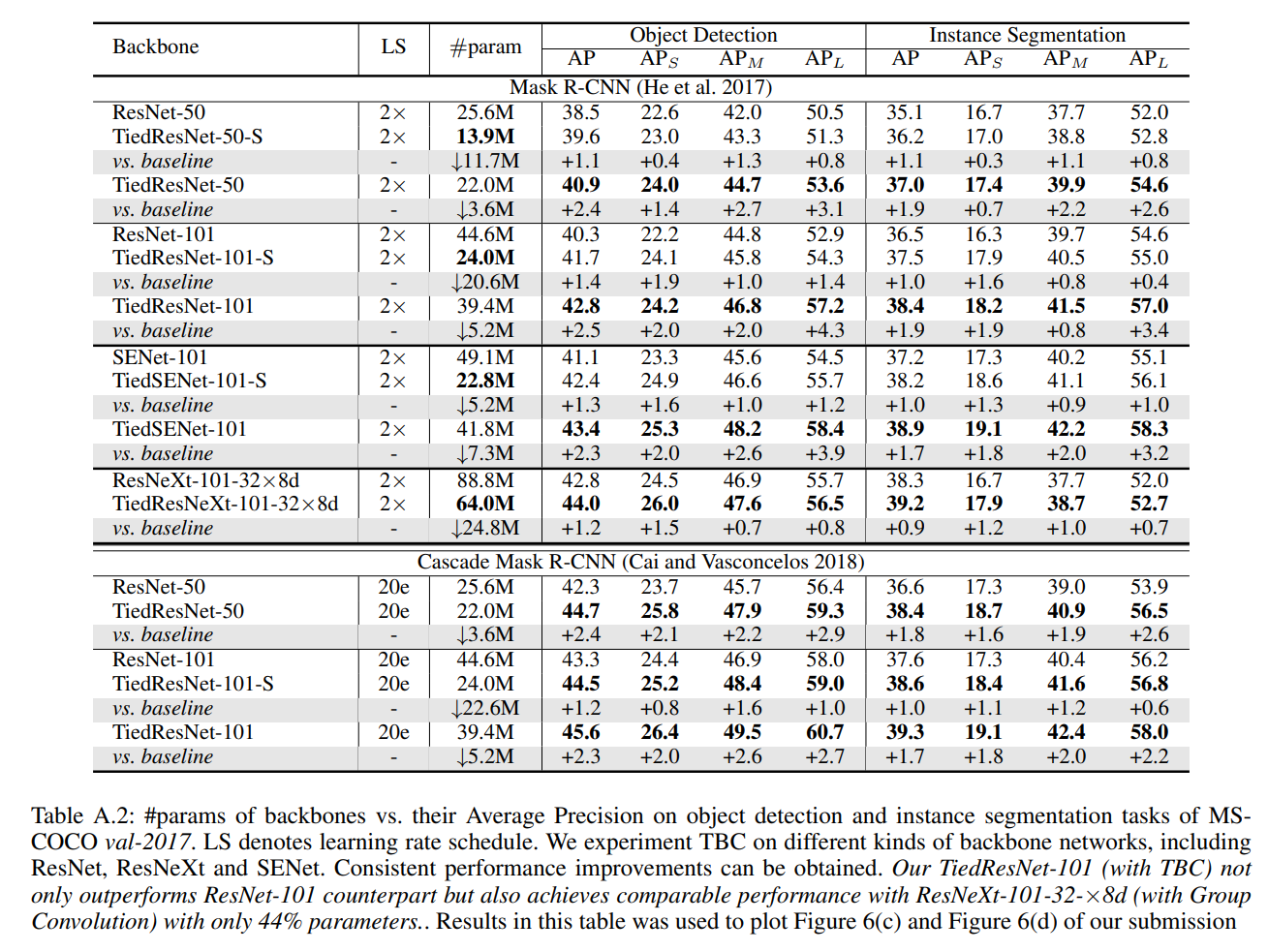
在表A.1和表A.2中,我们提供了在MS-COCO(Lin等人,2014年)的物体检测和实例分割任务上,经过实验的不同基础网络和框架的详细结果。报告了从0.5到0.95(间隔为0.05)的IoU阈值的平均精度(AP)以及不同质量和尺寸下的AP。所有实验都是在mmdetection v1.0代码库(Chen等人,2019年)上进行的。

无论实验检测器的类型和性能如何,TiedResNet始终比ResNet高出2%以上,并具有更高的参数使用效率。TiedResNet的轻量级版本甚至通过减少大约2倍的参数,将性能提高了1.2%。此外,在检测和实例分割任务中的改进(约2.5%)通常比在识别任务中的改进(约1.5%)更高。相比之下,ResNeXt在识别和检测任务中的改进相似,即大约1.4%。这表明TiedResNet更适合于检测任务,并具有更强的定位能力。

我们还使用Mask R-CNN作为检测器,在多个基础网络上实验了我们的TBC/TGC/TFC,以证明这些提出的运算符在检测和实例分割任务上的有效性和普遍性。所有这些基础网络及其对应网络都在ImageNet上进行了100个周期的预训练,以进行公平的比较。与ImageNet识别任务中的观察结果类似,通过将TBC/TGC/TFC集成到多个基础网络中,我们获得了持续的性能提升。
额外的Grad-CAM可视化结果
图A.1展示了使用Grad-CAM(Selvaraju等人,2017年)的额外可视化结果。Grad-CAM是一种创建高分辨率类别判别可视化的算法,它能够展示网络在目标对象区域中利用信息的能力。图A.1表明,与基准模型相比,TiedResNet能够更准确地定位目标实例,这表明在物体检测和实例分割任务中的性能提升来自于对精确注意力的控制和对无关杂乱的噪声的减少。

样本结果
包括Cityscapes(Cordts等人,2016年)、Pascal VOC(Everingham等人,2015年)和MS-COCO(Lin等人,2014年)在内的多个数据集上的物体检测和实例分割任务的样本结果在图A.2中进行了可视化。我们的TiedResNet显示出处理高度重叠实例的强大能力。

