
- 1unity导入视频并实现播放及进度条滑动_unity2d放视频
- 2Jenkins用户密码重置
- 3sqlmap基本信息及参数使用方法
- 4Vue版Ant Design给a-form表单-赋值及获取表单数据-案例_ant design vue 怎么获取form的值
- 5Windows平台安装Pygame报错:is not a supported wheel on this platform._error: pygame-2.1.2-cp311-cp311-win_amd64.whl is n
- 6DL-1-week2-Basics of Neural Network Programming_week 2 quiz - neural network basics
- 7VUE3使用wavesurfer.js_vue3 wavesurfer.js
- 8spine介绍和在Unity里面的应用_unity spine
- 9WPF学习之绘图和动画_shader effects buildtask and templates
- 10Python Turtle 初学者指南_turtle.bgcolor
【NLP】NLP基础知识_nlp学习
赞
踩
目录
自然语言处理主要内容

自然语言的构成

自然语言处理的步骤1:词法分析

1 分词:


1.1 分词Python Jieba库
# 1.中文分词
# “结巴”Python中文分词组件
# * 支持三种分词模式:
# - 精确模式,试图将句子最精确地切开,适合文本分析;
# - 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
# - 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
# * 支持繁体分词
# * 支持自定义词典
import jieba
# 基本功能
# jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
# jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("【全模式】: " + ", ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("【精确模式】:" + ", ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # “杭研”并没有在词典中,但是也被Viterbi算法识别出来了
print("【新词识别】:"+", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院,后在日本京都大学深造") # 搜索引擎模式
print("【搜索引擎模式】:"+", ".join(seg_list))
# 2 自定义词典
# 用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
# 词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
# eg:
# ```
# 创新办 3 i
# 云计算 5
# 凱特琳 nz
# 台中
# ```
test_sent = (
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
jieba.load_userdict("data/userdict.txt") #加载用户词典
words = jieba.cut(test_sent)
print('/'.join(words))
# 使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
jieba.add_word('石墨烯')
jieba.add_word('雷课教育')
words = jieba.cut(test_sent)
print('/'.join(words))
# 使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
print('/'.join(jieba.cut('如果放到post中将出错。')))
jieba.suggest_freq(('中', '将'), True)
print('/'.join(jieba.cut('如果放到post中将出错。')))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
2 实体识别

3 实体识别方法:序列标注
把文本变成一长串字符标识,通过字符标识看成序列,学习序列与序列间的依赖关系来推断词是什么词从而识别是什么实体

4 序列标注关键算法:
CRF:条件随机场;LSTM:特殊循环神经网络

5 序列标注应用:
5.1 新词发现:

5.2 领域中文分词

5.3 命名实体识别

5.4 依存句法分析(帮助句法分析)
将句法树展为序列进行序列标注,再还原为树

自然语言处理的步骤2:句法分析

1 主题模型与特征提取
1.0 简单文本表示(one-hot和词袋模型)
# 文本表示
# 文本是最常用的序列之一,可以理解为字符序列或单词序列,但最常见的是单词级处理。与其他神经网络一样,深度学习模型不会接收原始文本作为输入,只能处理数值张量。文本表示是指将文本转换为数值张量的过程。
# 注意:数据要在一个空间内,也就是共用词典
# one-hot编码
from keras.preprocessing.text import Tokenizer
texts = ['Python是目前最流行的数据分析和机器学习编程语言',
'Python语言编程将很快成为各个高校的必修课',
'Python是科研工作者开展科学研究的高效工具']
sentences = []
for text in texts:
seg_list = jieba.cut(text)
sentences.append(' '.join(seg_list))
tk = Tokenizer()
# 创建单词索引
tk.fit_on_texts(sentences)
print(tk.word_index)
print(tk.index_word)
# 把单词转换为序列
seqs = tk.texts_to_sequences(sentences)
print(seqs)
for seq in seqs:
print(seq)
'''
[[1, 3, 4, 5, 6, 2, 7, 8, 9, 10, 11],
[1, 12, 13, 14, 15, 16, 17, 18, 2, 19],
[1, 3, 20, 21, 22, 23, 2, 24, 25]]
'''
#one hot编码
one_hot_results = tk.texts_to_matrix(sentences, mode='binary')
for one_hot_result in one_hot_results:
print(one_hot_result)
'''
[0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0.]
[0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0.
0. 0.]
[0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1.
1. 1.]
'''
# 用pairwise_distances计算的Cosine distance是1-(cosine similarity)结果
from sklearn.metrics.pairwise import cosine_similarity
user_similarity = cosine_similarity(one_hot_results)
print(user_similarity)
'''
array([[1. , 0.19069252, 0.30151134],
[0.19069252, 1. , 0.21081851],
[0.30151134, 0.21081851, 1. ]])
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
# 词袋模型,对one-hot的改进,有一定的语料,标注统计词频
# Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。
# 它支持包括TF-IDF,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
# * 语料(Corpus):一组原始文本的集合,用于无监督地训练文本主题的隐层结构。语料中不需要人工标注的附加信息。在Gensim中,Corpus通常是一个可迭代的对象(比如列表)。每一次迭代返回一个可用于表达文本对象的稀疏向量。
# * 向量(Vector):由一组文本特征构成的列表。是一段文本在Gensim中的内部表达。
# * 稀疏向量(SparseVector):通常,我们可以略去向量中多余的0元素。此时,向量中的每一个元素是一个(key, value)的元组
# * 模型(Model):是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。
# 词袋模型
# 要将文档转换为向量,我们将使用名为bag-of-words的文档表示 。在此表示中,每个文档由一个向量表示,其中每个向量元素表示问题 - 答案对,仅通过它们的(整数)id来表示问题是有利的。问题和ID之间的映射称为字典:
dictionary = corpora.Dictionary(texts) #创建一个映射字典,建词表
dictionary.save('tmp/deerwester.dict')
print(dictionary)
print(dictionary.token2id)
# 要将标记化文档实际转换为向量:
new_doc = "Python 语言 编程 是 数据分析 的 编程语言"
new_vec = dictionary.doc2bow(new_doc.lower().split()) #使用我们刚构造的字典来进行编码
print(new_vec)# 把一句话变成一个向量
# 该函数doc2bow()只计算每个不同单词的出现次数,将单词转换为整数单词id,并将结果作为稀疏向量返回。 因此,稀疏向量 [(0, 1), (4, 1), (7, 1), (8, 1), (9, 1)]读取:在文档“Python语言编程是数据分析的编程语言”中,词Python(id 0)、数据分析(id 4)、编程语言(id 7)、语言(id 8)和编程(id 9)出现一次; 其他十七个字典词(隐含地)出现零次。
print(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
corpora.MmCorpus.serialize('tmp/deerwester.mm', corpus)
print(corpus)# 三句话分别求三个向量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1.1 TF-IDF

# TF-IDF模型
#
# 在Gensim中,每一个向量变换的操作都对应着一个主题模型,例如上面提到的对应着词袋模型的doc2bow变换。每一个模型又都是一个标准的Python对象。下面以TF-IDF模型为例,介绍Gensim模型的一般使用方法。
# 首先是模型对象的初始化。通常,Gensim模型都接受一段训练语料(注意在Gensim中,语料对应着一个稀疏向量的迭代器)作为初始化的参数。显然,越复杂的模型需要配置的参数越多。
# 需使用到词袋模型的结果,例如:
print(texts)
corpus
# [['python', '目前', '最', '流行', '数据分析', '机器', '学习', '编程语言'], ['python', '语言', '编程', '将', '很快', '成为', '各个', '高校', '必修课'], ['python', '科研', '工作者', '开展', '科学研究', '高效', '工具']]
# [[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1)],[(0, 1),(8, 1),(9, 1),(10, 1),(11, 1),(12, 1),(13, 1),(14, 1),(15, 1)],[(0, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1)]]
# 创建转换
from gensim import models
tfidf = models.TfidfModel(corpus) #使用TF-IDF模型
# 其中,corpus是一个返回bow向量的迭代器。这两行代码将完成对corpus中出现的每一个特征的IDF值的统计工作。
# 接下来,我们可以调用这个模型将任意一段语料(依然是bow向量的迭代器)转化成TFIDF向量(的迭代器)。需要注意的是,这里的bow向量必须与训练语料的bow向量共享同一个特征字典(即共享同一个向量空间)。
# TF-IDF用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
# TF:词频,指的是某一个给定的词语在该文件中出现的频率
# IDF:倒文档词频,是一个词语普遍重要性的度量,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
# 挑选文档的特征词:某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。
# TF-IDE=TF*IDF
new_doc = "Python 语言 编程 是 数据分析 的 编程语言"
new_vec = dictionary.doc2bow(new_doc.lower().split()) #使用我们刚构造的字典来进行编码
print(new_vec) #[(0, 1), (2, 1), (7, 1), (13, 1), (14, 1)]
print(tfidf[new_vec]) #[(2, 0.5), (7, 0.5), (13, 0.5), (14, 0.5)]
#输出每个词 在这个文档中重要性
# 或者将转换应用于整个语料库:
corpus_tfidf = tfidf[corpus]
for doc in corpus_tfidf:
print(doc) #[(1, 0.3779644730092272), (2, 0.3779644730092272), (3, 0.3779644730092272), (4, 0.3779644730092272), (5, 0.3779644730092272), (6, 0.3779644730092272), (7, 0.3779644730092272)]...
# 可以将训练好的模型持久化到磁盘上,以便下一次使用:
tfidf.save("tmp/model.tfidf") #保存
new_tfidf = models.TfidfModel.load("tmp/model.tfidf")#加载
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
1.2 主题模型

1.3 LDA(潜在狄利克雷分配Latent Dirichlet Allocation)
LDA描述的是一篇文章是如何产生的。一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”。LDA 通过主题模型把每一个主题词分析出来以后,把文档表示成向量,可以对文档做聚类、分类、信息提取,特征选择等。
LDA应用场景:
(1)通常LDA用户进主题模型挖掘,当然也可用于降维。
(2)推荐系统:应用LDA挖掘物品主题,计算主题相似度
(3)情感分析:学习出用户讨论、用户评论中的内容主题
LDA算法的主要优点有:
(1)在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
(2)LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
LDA算法的主要缺点有:
(1)LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
(2)LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
(3)LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
(4)LDA可能过度拟合数据。


# LDA模型
# 需使用词袋模型建立的词表dictionary,corpus是想进行LDA的语料
lda = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10) # 需要人为事先指定主题的个数
new_doc = "Python 语言 编程 是 数据分析 的 编程语言"
new_vec = dictionary.doc2bow(new_doc.lower().split()) #使用我们刚构造的字典来进行编码
print(new_vec) #[(0, 1), (2, 1), (7, 1), (13, 1), (14, 1)]
#输出每个词 在这个文档中重要性(主题概率)0~9指的是主题词
print(lda[new_vec]) #[(0, 0.016668105), (1, 0.01666673), (2, 0.01666673), (3, 0.01666673), (4, 0.42808887), (5, 0.01666673), (6, 0.01666673), (7, 0.01666673), (8, 0.43857592), (9, 0.01666673)]
# 将单个主题作为格式化字符串
lda.print_topic(2, topn=3) #'0.045*"python" + 0.045*"学习" + 0.045*"开展"'
# 把所有的主题打印出来看看
lda.print_topics(num_topics=10, num_words=3) #[(0, '0.120*"python" + 0.120*"高效" + 0.120*"工具"'),(1, '0.045*"python" + 0.045*"科研" + 0.045*"学习"'),(2, '0.045*"python" + 0.045*"学习" + 0.045*"开展"'),(3, '0.045*"python" + 0.045*"科学研究" + 0.045*"开展"'),(4, '0.098*"python" + 0.098*"将" + 0.098*"很快"'),(5, '0.045*"python" + 0.045*"科研" + 0.045*"最"'),(6, '0.045*"python" + 0.045*"工作者" + 0.045*"目前"'),(7, '0.045*"python" + 0.045*"工作者" + 0.045*"科学研究"'),(8, '0.108*"python" + 0.108*"数据分析" + 0.108*"机器"'),(9, '0.045*"python" + 0.045*"科学研究" + 0.045*"学习"')]
# 将转换应用于整个语料库:
corpus_lda = lda[corpus]
for doc in corpus_lda:
print(doc)
# 可以将训练好的模型持久化到磁盘上,以便下一次使用:
lda.save("tmp/model.lda")
new_lda = models.LdaModel.load("tmp/model.lda")
doc = "Python 语言 编程 是 数据分析 的 编程语言" #来啦一句新的话
vec_bow = dictionary.doc2bow(doc.lower().split()) #词袋模型编码
vec_lda = new_lda[vec_bow] #求主题模型向量
print(vec_lda) #[(0, 0.016668107), (1, 0.016666729), (2, 0.016666729), (3, 0.016666729), (4, 0.42814282), (5, 0.016666729), (6, 0.016666729), (7, 0.016666729), (8, 0.438522), (9, 0.016666729)]
# 求这句话与语料库的话的相似度
# similarities.MatrixSimilarity只有当整个向量集适合内存时,该类才适用。例如,当与此类一起使用时,一百万个文档的语料库在256维LSI空间中将需要2GB的RAM。
#如果没有2GB的可用RAM,则需要使用similarities.Similarity该类。此类通过在磁盘上的多个文件(称为分片)之间拆分索引,在固定内存中运行。它使用similarities.MatrixSimilarity和similarities.SparseMatrixSimilarity内部,所以它仍然很快,虽然稍微复杂一点。
index = similarities.MatrixSimilarity(new_lda[corpus])
# 要获得我们的查询文档与三个索引文档的相似性:
sims = index[vec_lda]
print(list(enumerate(sims))) #[(0, 0.7241974), (1, 0.70637095), (2, 0.049605016)]
#余弦测量返回范围中的相似度(越大,越相似)
# 将这些相似性按降序排序,并获得查询 Python语言编程是数据分析的编程语言 的最终答案:
sims = sorted(enumerate(sims), key=lambda item: -item[1])
print(sims)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
1.4 词向量与分布式表示Word2Vec:
词向量:
指的是一个词的向量表示。如果希望计算机能够进行一些复杂点的文本语义学习,你必须得将文本数据编码成计算机能够处理的数值向量,所以词向量是一个自然语言处理任务中非常重要的一环。
怎么得到上述具有语义Distributional representations的词向量:
2013年提出的word2vec的方法就是一种非常方便得到高质量词向量的方式。其主要思想是:一个词的上下文可以很好的表达出词的语义,它是一种通过无监督的学习文本来用产生词向量的方式。
100+ Chinese Word Vectors 上百种预训练中文词向量
提供了各种各样的中文词向量



Word2Vec思想:用一个词附近的其他词来表示该词。进而有了Word2vec、fastText、GloVe,利用深度学习的思想,把文本内容简单处理简化为K维向量空间中的向量计算。
Word2Vec应用:计算相似的词,潜在语言学计算,实体的聚类,短语分析。
# 词向量模型与词向量的应用
from gensim import models
new_model = models.KeyedVectors.load_word2vec_format('tmp/sgns.wiki.bigram-char', binary=False) #词向量模型是文本格式binary=False,当前使用维基百科的训练的一个语料
new_model['北京'] #array([-1.895390e-01, 2.102730e-01, -3.276010e-01, -3.600300e-01,...(稠密的分布式的向量)
len(new_model['北京']) #300维
# 得到与一个词最相关的若干词及相似程度(词向量的应用)
new_model.similar_by_word('北京') #[('天津', 0.6173436045646667), ('北京市', 0.5824244022369385), ('上海', 0.5780521631240845),('北平', 0.5682350397109985),('南京', 0.5669952034950256),('沈阳', 0.5609930753707886),('哈尔滨', 0.5396846532821655('北京组织', 0.5318084955215454),('北京饭店', 0.5287923216819763),('北京市区', 0.5265966653823853)]
new_model.similar_by_word('苹果', topn=3) #取前3,[('苹果公司', 0.6365625858306885),('苹果梨', 0.6067387461662292),('苹果电脑', 0.5989832878112793)]
# 得到两组词的相似度
list1 = [u'核能']
list2 = [u'电能']
list3 = [u'电力']
list_sim1 = new_model.n_similarity(list1, list2) #比较两句话的相似度
print(list_sim1) #0.4872034
list_sim2 = new_model.n_similarity(list2, list3)
print(list_sim2) #0.56210846
y2 = new_model.wv.similarity(u"苹果", u"香蕉")#求俩个词的相似度
print(y2) #0.4488025
for i in new_model.wv.most_similar(u"笔记本电脑"):
print (i[0],i[1])#笔记型电脑 0.763359785079956笔记型 0.7508394718170166笔电 0.7042805552482605桌上型 0.6807361841201782手提电脑 0.6782387495040894笔记本 0.6753861904144287掌上电脑 0.6743722558021545型电脑 0.6550002098083496台式机 0.6405402421951294个人电脑 0.6388059258460999
# 得到一组词中最无关的词
list4 = [u'汽车', u'火车', u'飞机', u'北京']
print(new_model.doesnt_match(list4)) #北京
#词语的加减(词向量的应用)
#king - man + woman = queen 国王 - 男人 + 女人 = 王后
new_model.most_similar(positive=['国王', '女人'], negative=['男人'])
#[('王后', 0.5674946308135986),('女王', 0.5539615154266357),('王国', 0.5226463675498962),('英王', 0.5111727714538574),('王储', 0.5046637654304504),('沙特王国', 0.5022165775299072),('王或', 0.49841436743736267),('王威廉', 0.4965606927871704),('皇帝', 0.49619776010513306),('王室', 0.4949503540992737)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
Word2vec两种训练模式:
(1)周围词推中间词 cbow(连续词袋模型)
(2)中间词推周围词训练出词向量 skip-gram
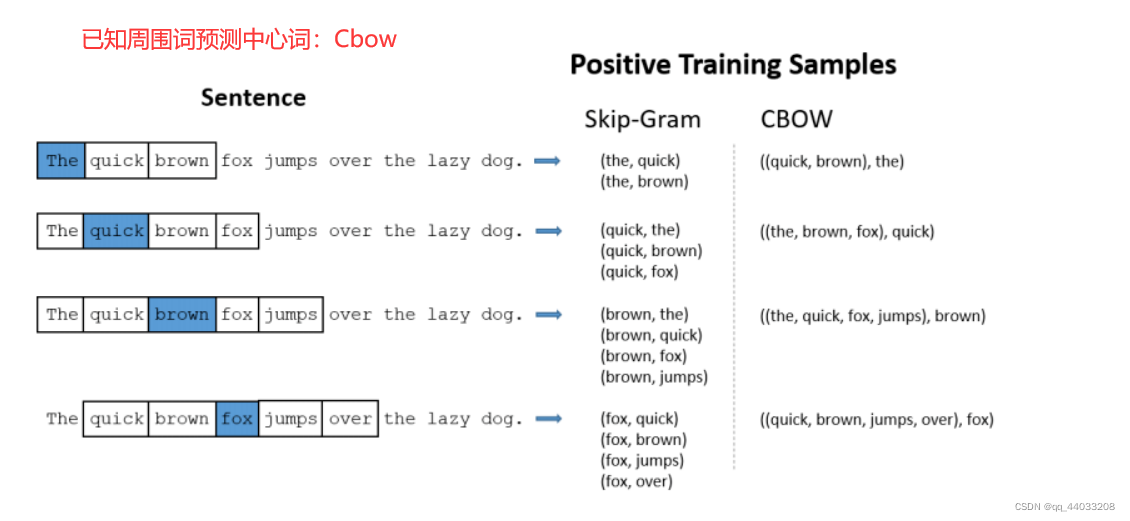
比如 “the quick brown fox jumps over the lazy dog” 如果定义window-size为2的话,就会产生如下图所示的数据集,window-size决定了目标词会与多远距离的上下文产生关系:
Skip-Gram:(the,quick) ,其中the 是模型的输入,quick是模型的输出。
Cbow :((quick,brown),the),其中(quick,brown)是模型的输入,the是模型的输出。
使用
word2vec.Word2Vec这个API的来训练词向量,参数说明如下:
size:表示词向量的维度,默认值是100。
window:决定了目标词会与多远距离的上下文产生关系,默认值是5。
sg:如果是0,则是Cbow模型,是1则是Skip-Gram模型,默认是0即Cbow模型。 采用Cbow模型——通过周围词预测中心词的方式训练词向量。
Word2vec俩种训练模式最终得到词向量,新输入的话也依次训练得到词向量,隐藏层把这个当做词向量对待。
#本地的200篇新闻文档用于训练
import os
fpath = 'data/IT'
flist = os.listdir(fpath) # 列出文件目录
flist[:5] #['IT_10.txt', 'IT_100.txt', 'IT_1000.txt', 'IT_1010.txt', 'IT_1020.txt']
datas = list()
for i in range(0, len(flist)):
path = os.path.join(fpath, flist[i])#具体文件路径
with open(path, 'r', encoding='utf-8') as f:
datas.append(f.read().strip())
datas[:1] #['本报讯 记者 王京 联想 THINKPAD 近期 几乎 系列 笔记本 电脑 降价促销 最高 降幅 达到 降幅 达到 42% 记者 联想 美国 官方 网站 发现 联想 相关 人士 表示 纪念 联想 成立 美国 市场 推出 促销 产品 包括 THINKPAD T 系列 笔记本 促销 价格战 THINK 品牌 高端 商务 路线 方向 不会 改变','赛迪网 消息 思科 周二 发布 其财 第三季度 财报 财报 显示 股票 期权 开支 收购 相关 费用 影响 季度 营收 实现 增长 净利润 同比 下降 \u3000据 Maketwatch 网站 报道 思科 季度 实现 净利润 低于 去年 同期 本季度 收益 去年 同期 收益 思科 去年 同期 发行 股票 数量 于今 Thomson First Call 调查 分析师 预计 收益 \u3000本 季度 营收 同比 增长 高于 华尔街 分析师 预计 思科 新近 收购 Scientific-Atlanta 公司 季度 营收 增长 做出 贡献 思科 上个世纪 年代 进行 收购 实现 发展 目的 现在 希望 借助 价格 收购 Scientific-Atlanta 公司 扩大 互联网 设备 市场 份额 分析师 投资者 看好 思科 Scientific-Atlanta 收购 思科 股价 进入 今年 上涨 财报 发布 思科 股票 盘后 交易 上涨',
len(datas)#199篇文档
datas[0]#'本报讯 记者 王京 联想 THINKPAD 近期 几乎 系列 笔记本 电脑 降价促销 最高 降幅 达到 降幅 达到 42% 记者 联想 美国 官方 网站 发现 联想 相关 人士 表示 纪念 联想 成立 美国 市场 推出 促销 产品 包括 THINKPAD T 系列 笔记本 促销 价格战 THINK 品牌 高端 商务 路线 方向 不会 改变'
sentences = list()
for data in datas:
sentences.append(data.split())
sentences[:1]#[['本报讯','记者','王京','联想','THINKPAD',...]]
#开始训练
from gensim.models import Word2Vec
model = Word2Vec(sentences, size=50, window=5, min_count=5, workers=4) #sentences是分好词的句子,size词向量维度,词频为5的舍去,线程为4
model.save('tmp/my.word2vec')
model = Word2Vec.load('tmp/my.word2vec')
model.wv['电脑'] #array([-0.4120238 , 0.93129444, -0.15996793, -0.14292578, -0.16040058,...], dtype=float32)
len(model.wv['电脑']) #50
model.similarity(u'笔记本', u'电脑') #0.99974334
# 词向量增量训练
# model = gensim.models.Word2Vec.load(fname)
# model.train(sentences,total_examples=new_model.corpus_count, epochs=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
1.5 文档向量模型Doc2vec:
前面是Word2vec训练词向量的细节,讲解了一个词是如何通过Word2vec模型训练出唯一的向量来表示的。Doc2vec能够将一个句子甚至一篇短文也用一个向量来表示,训练一个句子向量。
Doc2vec又叫Paragraph Vector,是基于Word2vec模型提出的,其具有一些优点,比如不用固定句子长度,接受不同长度的句子做训练样本,Doc2vec是一个无监督学习算法,该算法用于预测一个向量来表示不同的文档,该模型的结构潜在的克服了词袋模型的缺点。
Doc2vec的两种训练方式:(与Word2vec类似,在预测的中间加了文档的id,表示这个段落)
(1)PV-DM(Distributed Memory Model of paragraphvectors):类似于word2vec中的Cbow模型,如图:

(2)PV-DBOW(Distributed Bag of Words of paragraph vector):类似于word2vec中的skip-gram模型,如图

model = Doc2Vec(documents = sentences, dm = 1, vector_size = 100, window = 3,min_count = 1, iter = 10, workers = Pool()._processes)
- 1
- 参数说明:
documents: training data (has to be iterable TaggedDocument instances)vector_size: 向量的维度dm: 1 PV-DM, 0 PV-DBOWwindow: 上下文词语离当前词语的最大距离min_count: 词频小于min_count的词会被忽略iter: 在整个语料上的迭代次数(epochs),推荐10到20workers: number of worker threads to train
# 文档向量模型Doc2vec
sentences2 = sentences[:] #仍使用上面word2vec的句子
sentences2[0] #['本报讯','记者','王京','联想',...]
import gensim
# Create the tagged document needed for Doc2Vec
for i in range(len(sentences2)):
sentences2[i] = gensim.models.doc2vec.TaggedDocument(words = sentences2[i], tags = [i]) #给每篇文档打tag
sentences2[0] #TaggedDocument(words=['本报讯', '记者', '王京', '联想', 'THINKPAD', '近期', '几乎', '系列', '笔记本', '电脑', '降价促销', '最高', '降幅', '达到', '降幅', '达到', '42%', '记者', '联想', '美国', '官方', '网站', '发现', '联想', '相关', '人士', '表示', '纪念', '联想', '成立', '美国', '市场', '推出', '促销', '产品', '包括', 'THINKPAD', 'T', '系列', '笔记本', '促销', '价格战', 'THINK', '品牌', '高端', '商务', '路线', '方向', '不会', '改变'], tags=[0])
# 开始训练
# Init the Doc2Vec model
model = gensim.models.doc2vec.Doc2Vec(dm=1, vector_size=100, window=5, min_count=2, workers=4)
# Build the Volabulary
model.build_vocab(sentences2)
# Train the Doc2Vec model
model.train(sentences2, total_examples=model.corpus_count, epochs=5)
# 与标签‘0’最相似的(与第0篇文档最相似的)
model.docvecs.most_similar(0) #[(16, 0.9943929314613342),(178, 0.9941708445549011),(107, 0.994168758392334),(71, 0.9941332340240479),(44, 0.9940872192382812),(37, 0.99403977394104),(110, 0.9940279722213745),(191, 0.9940222501754761),(31, 0.9940007328987122),(157, 0.993998646736145)]
# 进行相关性比较
model.docvecs.similarity(0, 2) #0.9931895
# 输出标签为‘0’句子的向量
model.docvecs[0]
# 也可以推断一个句向量(未出现在语料中)
# 新句子:硅谷动力消息国外媒体报道
model.infer_vector(['硅谷动力', '消息', '国外', '媒体', '报道']) #新文档,分词后array([ 4.5228358e-03, 5.9929048e-03, 2.6739310e-04, -1.0082212e-03,...
model['电脑'] #因为也是基于词的 array([ 0.03124144, 0.3127994 , -0.06973337, 0.08067959, -0.20974208,...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2 文本分类与相似度量
怎么利用向量进行文本分类。传统分类方法:KNN、贝叶斯网络(天然合适,有概率)、DT、NN、SVM、voting method

自然语言处理的步骤3:语义分析

自然语言处理的发展
1 基于规则
按照分词以后把文字变成句法树

2 基于统计学
提出统计的语音识别
3 基于大数据
2005年谷歌统计机器翻译,采用六元模型分析(基于海量数据)
4 基于深度学习
文本进行特征表示,从高维转向低维。主要有CNN、RNN、CLSTM


1.TestCNN


2.RNN


3.CLSTM

自然语言处理的应用和发展
随着大数据、人工智能的的发展,NLP技术趋势逐渐发生变化:从规则到统计,由词典匹配到序列标注,偏重机器学习算法建设,重视语料库的建设。

自然语言处理技术路线


NLP前沿进展
1.神经语言模型
1906,马尔科夫提出马尔科夫链:俩个词汇之间有状态转移(最早语言模型)
1948,香农提出:信息熵,用熵的概率分布来表示一段文字代表的意思,概率多高
1956,乔姆斯基提出:N元模型,几个字组合到一块来转化为有限状态机(dp问题)
2003,Bengio提出:向量表达文本,谷歌实现了Word2Vec
2.序列到序列模型
一种使用神经网络将一个序列映射到另外一个序列的通用框架,常用与翻译。一句话变成一个序列映射到另外一句话中。
3.注意力机制模型
解决信息超载问题,哪些重要哪些不重要。
4.预训练语言模型
提前训练一些模型。


