- 1Springcloud OpenFeign 的实现(二)
- 2详解多分类模型的Macro-F1/Precision/Recall计算过程_多分类的f1计算
- 3Unity使用图片实现transform.LookAt功能_unity lookat y轴
- 4通过SpringMVC实现RabbitMQ消费队列_spring启动后如何让其运行一个自己的类消费mq队列数据
- 5【QML】使用Qt Design Studio设计UI动态行为_qml怎么用设计器
- 6flask对数据库通过html进行修改,flask拓展(数据库操作)
- 7linux删除目录下文件|删除文件保持目录结构|各种删除方法总结_删除/backup/var/目录下所有内容,仅保留/backup/var/目录
- 8阿里云对象存储OSS打造私人图床&私人云存储(1年仅9元)_个人使用对象存储搭建的图床费用
- 9pytorch梯度下降法讲解(非常详细)
- 10同目录下放置了ddddocr文件夹(含__init__.py),和直接放置ddddocr.py有何不同
LangChain+glm3原理解析及本地知识库部署搭建_chatglm3 本地知识库
赞
踩
前期准备:在部署LangChain之前,需要先下载chatglm3模型,如何下载可以查看我的上一篇文章chatglm3本地部署
本地知识库和微调的区别:
- 知识库是使用向量数据库存储数据,可以外挂,作为LLM的行业信息提供方。
- 简单理解,微调相当于让大模型去学习了新的一门学科,在回答的时候完成闭卷考试。知识库相当于为大模型提供了新学科的课本,回答的时候为开卷考试。
LangChain+glm3实现本地知识库原理:
首先给出git地址,git上其实也有他是原理也可以去git上看langchain-chatchat
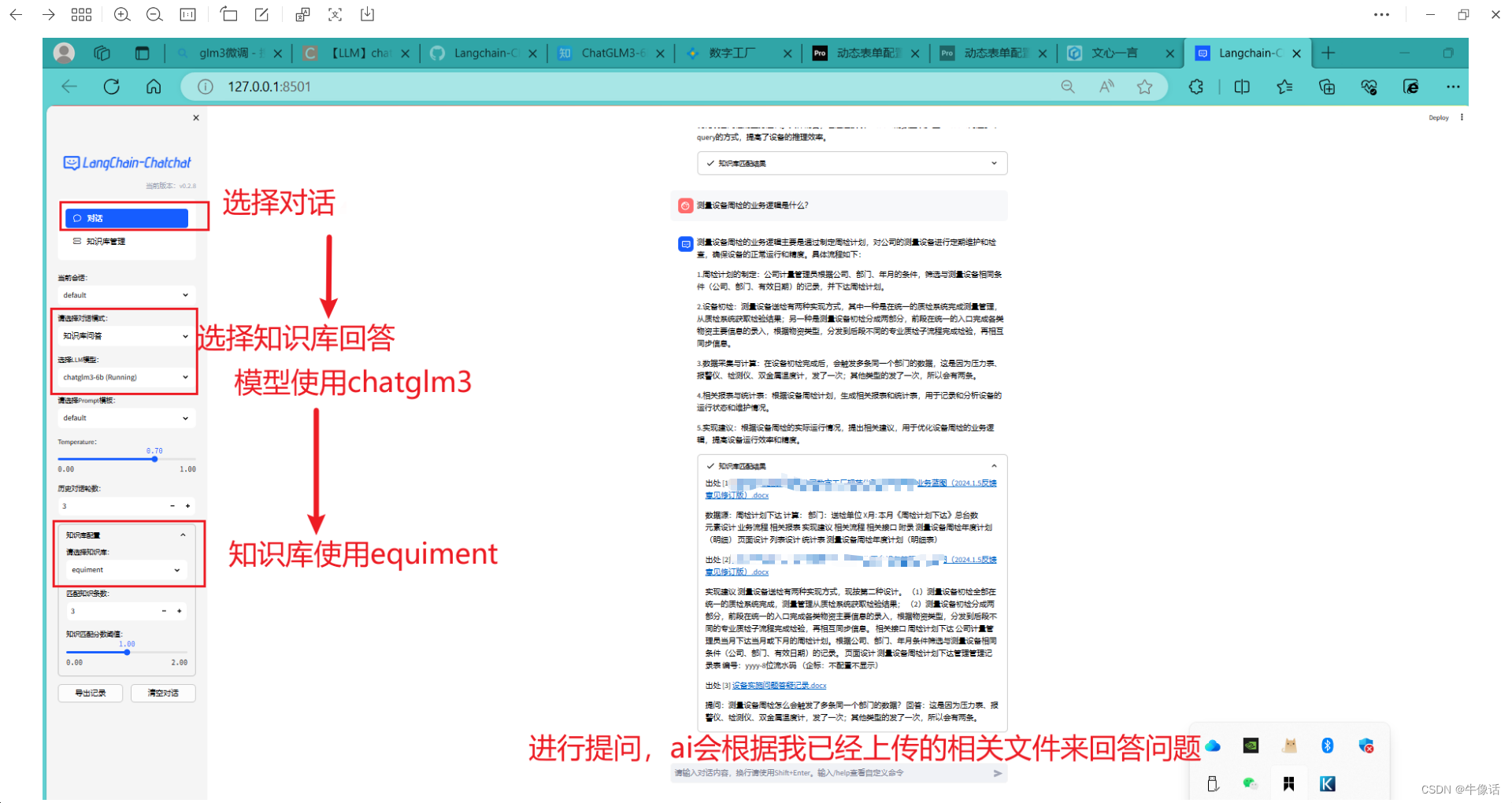
原理如下图:
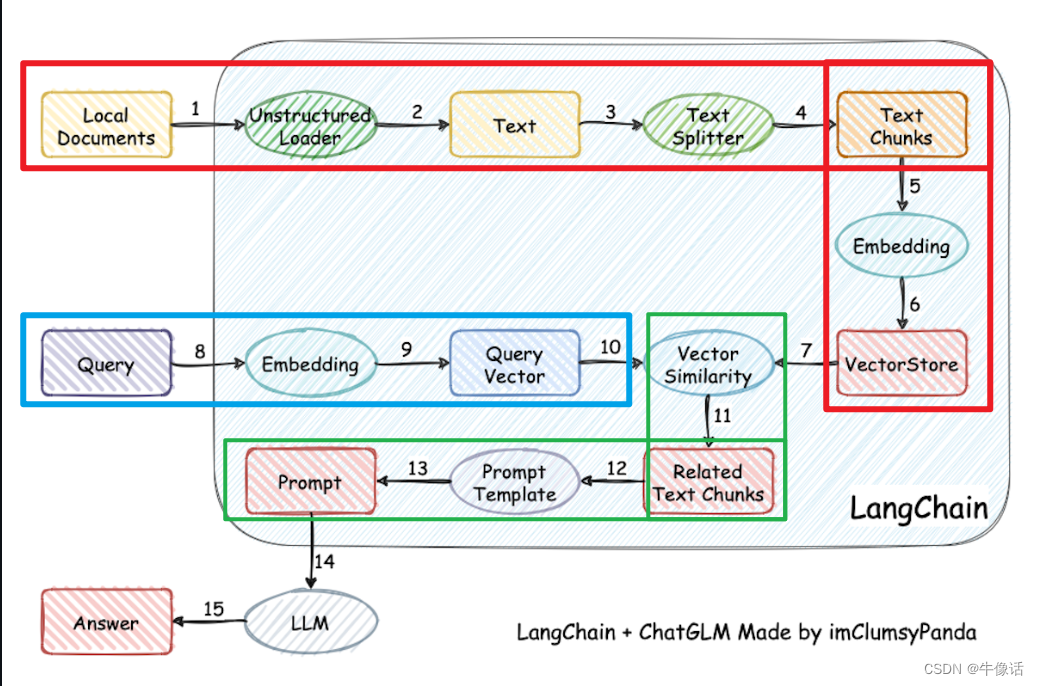
红框: 红框内是经历了这样一个过程,首先上传本地文档,然后把文档的内容进行分割,其中文档的分割方法有很多,比如可以按照符号分割,按照段落分割,或者按照语气词分割,接下来把分割后的内容,进行Embedding操作生成词向量,如果不清楚Embedding是什么的,可以参考我的这篇文章Embedding And Word2vec,最后把生成的词向量存入VectorStore,也就是词向量数据库。
蓝框: query是用户输入的信息,然后把用户输入的信息也做Embedding操作,然后得到词向量。
绿框: 利用向量相关性算法(例如余弦算法),计算用户输入后的词向量和向量数据库中最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 promt 提交给 LLM 回答。
本地部署:
1.拉取代码
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
- 1
2.创建一个conda环境,python环境我这里使用的是3.10.13,官方推荐的是 3.8 - 3.11,如果不知道如何创建的,在文章开头中的那篇文章里有。
3.激活刚刚创建的环境,然后下载torch,下载方法在文章开头中的那篇文章里有。
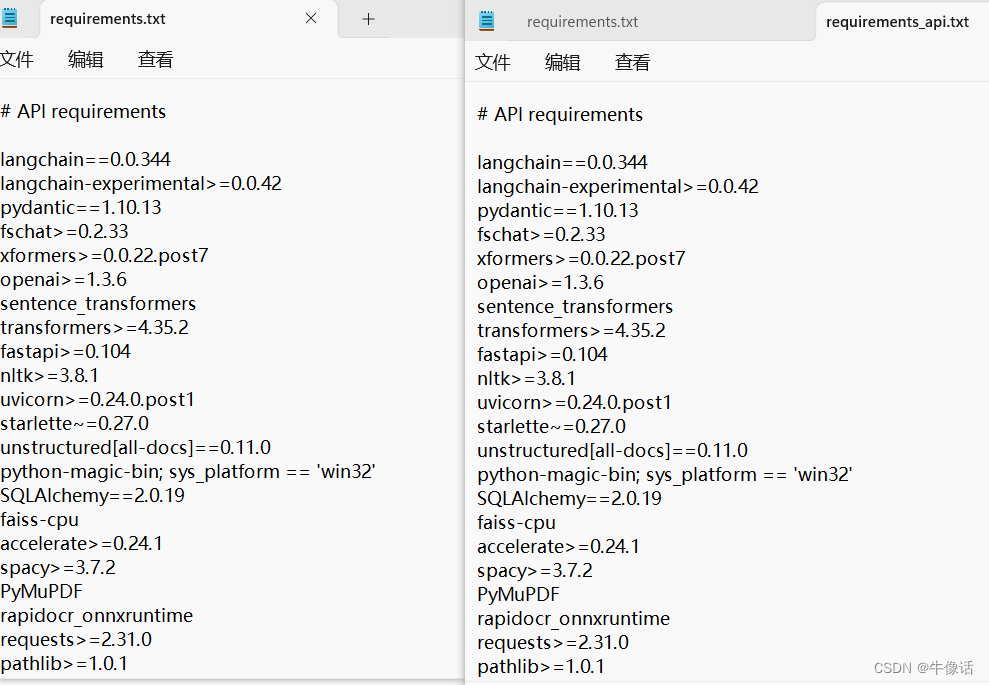
4.安装依赖,在安装依赖之前,需要把下面requirements.txt和requirements_api.txt文件中,有关torch的所有安装内容都删掉。因为如果直接执行下面的命令,下载的torch是cpu版本,从而导致后面无法启动langchain,这就是为什么我们要先装torch。
$ pip install -r requirements.txt
$ pip install -r requirements_api.txt
$ pip install -r requirements_webui.txt
- 1
- 2
- 3
5.把下载好的模型复制到langchain下
6.初始化知识库和配置文件
$ python copy_config_example.py
$ python init_database.py --recreate-vs
- 1
- 2
7.启动
$ python startup.py -a
- 1
8.创建知识库
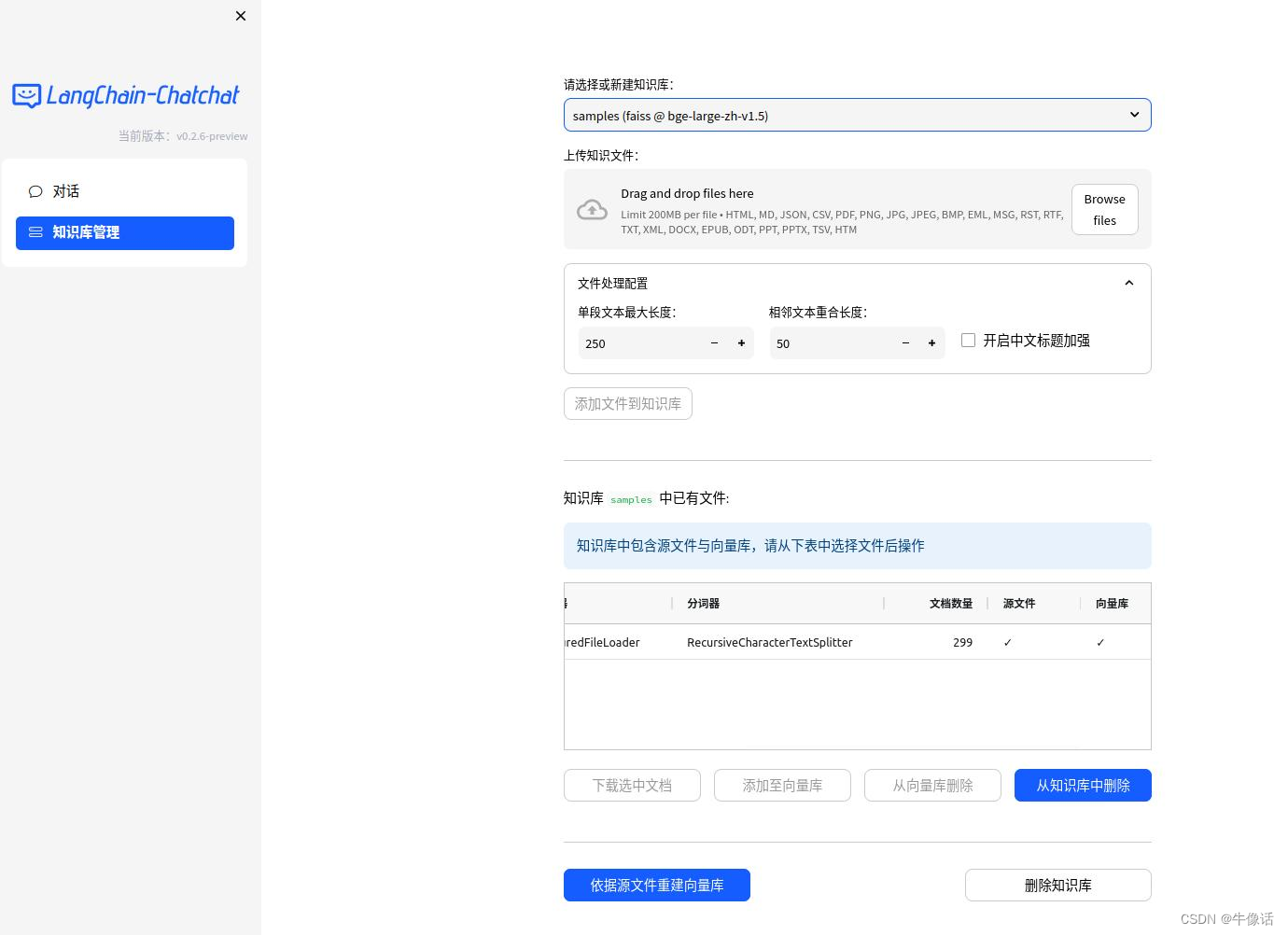
9.使用