
- 1Unity 简单用C#实现物体左右循环移动_unity c# 设置物体往返运动
- 2Tensorflow和keras版本对应关系_tensorflow2.5.0对应keras
- 3解决:Error: JAVA_HOME is not defined correctly. CARBON cannot execute java
- 4Unity3D的射线使用(简单的点击处理版本)_unity射线实现点击出现音频
- 5微信小程序---主菜单入口形式的首页_微信小程序首页界面
- 6众人围剿,GPT-5招惹了谁_chatgtp5
- 7【华为OD机考 统一考试机试C卷】小明找位置(Java题解)
- 8【unity3D】TileMap基础知识(详细版)_unity tilemap
- 9我常用的几款免费AI生成视频平台_小视频创作需要的aigc工具
- 10嚼一嚼Halcon中的3D手眼标定_halcon手眼标定后精度
Dubbo与Spring集成_spring 集成dubbo
赞
踩
Dubbo框架常被当作第三方框架集成到应用中,当Spring集成Dubbo框架后,为什么在编写代码的时候,只用了@DubboReference注解就可以调用提供方的服务了呢?这篇笔记就是分析Dubbo框架是怎么与Spring结合的。
现状integration层代码编写形式
public interface SamplesFacade {
QueryOrderRes queryOrder(QueryOrderReq req);
}
- 1
- 2
- 3
public interface SamplesFacadeClient { QueryOrderResponse queryRemoteOrder(QueryOrderRequest req); } public class SamplesFacadeClientImpl implements SamplesFacadeClient { @DubboReference private SamplesFacade samplesFacade; @Override public QueryOrderResponse queryRemoteOrder(QueryOrderRequest req){ // 构建下游系统需要的请求入参对象 QueryOrderReq integrationReq = buildIntegrationReq(req); // 调用 Dubbo 接口访问下游提供方系统 QueryOrderRes resp = samplesFacade.queryOrder(integrationReq); // 判断返回的错误码是否成功 if(!"000000".equals(resp.getRespCode())){ throw new RuntimeException("下游系统 XXX 错误信息"); } // 将下游的对象转换为当前系统的对象 return convert2Response(resp); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
思路:
- SamplesFacade是下游提供方系统定义的一个接口,改接口中有一个queryOrder的方法。
- SamplesFacadeClient是integration层中定义的一个接口,并且实现了一个queryRemoteOrder方法,专门负责与SamplesFacade的queryOrder打交道。
- SamplesFacadeClientImpl也是定义在integration层中,并且实现了SamplesFacadeClient接口中,重写了queryRemoteOrder方法。
queryRemoteOrder方法封装了调用下游接口的逻辑,先构建调用下游系统的对象,然后把对象传入下游系统的接口中,再接收返回值并针对错误码判断,最后转成自己的Bean对象。
这个地方就可以做优化,封装一下,屏蔽下游提供方各种接口的差异性,减少重复性的代码编写。
封装
顺着调用链路分析有哪写变量因素在封装的时候需要考虑:
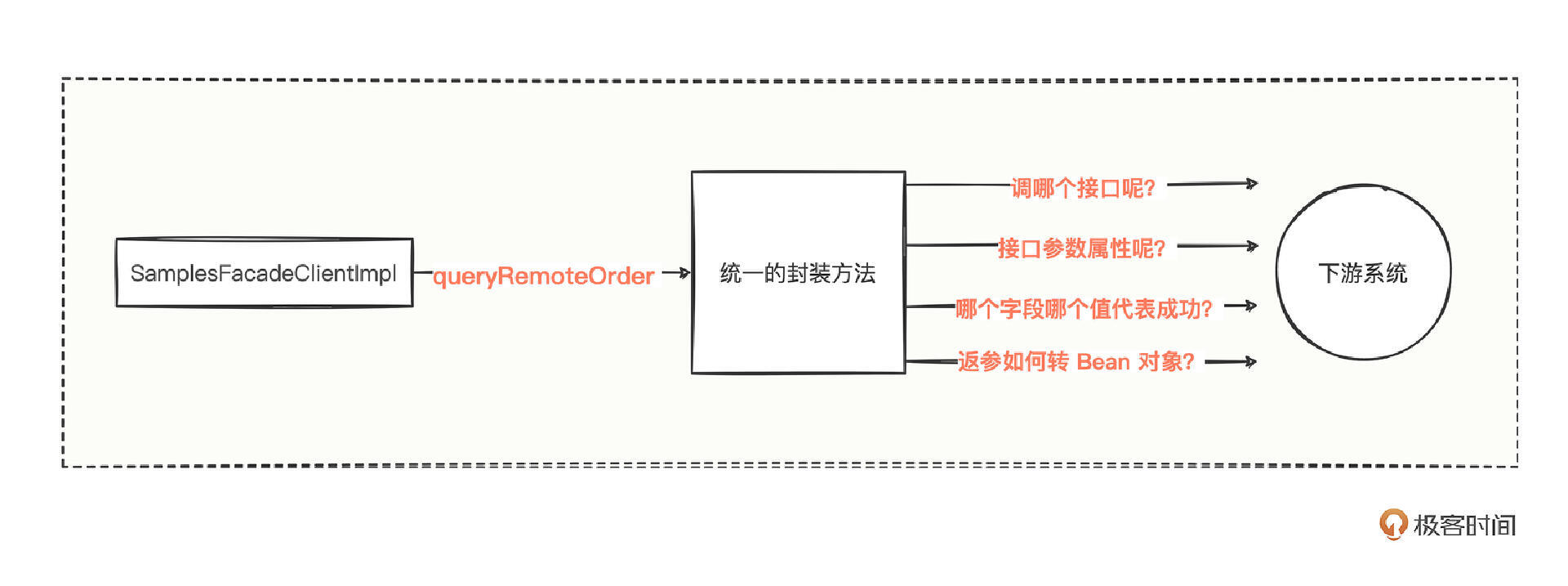
- 因素1:怎么知道调用下游提供方的哪个接口呢?这说明下游的接口类名、方法名、方法入参类名是变量因素。
- 因素2:怎么区分各个调用方的timeout、retries、cache、loadbalance等参数属性呢?这说明消费方接口级别的Dubbo参数属性也是变量因素。
- 因素3:调用下游提供方接口后拿到返回,有些接口需要判断错误码,有些接口不需要判断,而且不同接口的错误码字段、错误码,字段的值也可能不一样。这说明返参错误码的判断形式也是一个变量因素。
- 拿到下游接口的返回数据后,怎么转成各个调用方想要的对象呢?这说明将数据转成各个调用方期望的对象形式,也是一个变量因素。
抽象
抽象是把相似流程的骨架抽象出来,简单来说就是去掉表象,保留相对不变的。
一段代码的流程,可以是业务流程,也可以是代码流程,还可以是调用流程,当然本质都是一小块相对聚集的业务逻辑的核心主干流程,把不变的流程固化下来变成模板,然后把变化的因素交给各个调用方,意在求同存异,追求不变的稳定,放任变化的自由。
结合上班的例子,不变的是重复写的那段调用逻辑,先构建调用下游系统的请求对象,并将请求对象传入下游系统的接口中,然后接收返参并针对错误码进行判断,最后转成自己的Bean对象。把变化的因素分发给各个具体业务的实现类。
根据源码的一些设计思想,我们可以把变化的因素由注解来实现,根据这个思考放行,我们来再次分析前边是四大变化因素:
- 因素1是下游的接口类名、方法名、方法入参类名,涉及的类可以放在类注解上,方法名、方法入参可以放在方法注解上。
- 因素2中消费方接口级别的timeout、retries、loadbalance等属性,也可以放在方法注解上。
- 因素3中的错误码,理论上下游提供方一个类中多个方法返回的格式应该是一样的,所以如何判断错误码的变量因素可以放在类注解上。
- 因素4中如何将下游数据类型转换为本系统的Bean类型,其实最终还是接口级别的事,还是可以放在方法注解上。
根据我们的分析修改代码:
@DubboFeignClient(
remoteClass = SamplesFacade.class,
needResultJudge = true,
resultJudge = (remoteCodeNode = "respCode", remoteCodeSuccValueList = "000000", remoteMsgNode = "respMsg")
)
public interface SamplesFacadeClient {
@DubboMethod(
timeout = "5000",
retries = "3",
loadbalance = "random",
remoteMethodName = "queryRemoteOrder",
remoteMethodParamsTypeName = {"com.hmily.QueryOrderReq"}
)
QueryOrderResponse queryRemoteOrderInfo(QueryOrderRequest req);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们针对SamplesFacadeClient定义了两个注解,@DubboFeignClient是类注解,@DubboMethod是方法注解。
- 类注解中参数体现了调用系统方接口归属的类,以及怎么处理这个类中所有方法的返参错误码情况。
- 方法注解中参数体现了下游提供方的方法名和方法入参、返参对象类型转换、接口的timeout、retries、loadbalance等属性情况。
仿照Spring类扫描
把SamplesFacadeClient设计好后,之前调用下游提供方的代码,现在只需要自己定义一个接口,并添加上两种注解就好了,接下来是使用这个接口。
按照上边的思路顺下来,在integration层由一堆像SamplesFacadeClient这样的接口,每个接口上还有两个注解,在使用的时候可能这样写:
@Autowired
private SamplesFacadeClient samplesClient;
- 1
- 2
然后可以直接使用samplesClient.queryRemoteInfo这样的方式调用方法。这个时候就有问题了,samplesClient要想在运行时调用方法,首先samplesClient必须得有一个实例化的对象,可是我们根本没有SamplesFacadeClient接口的任何实现类,那怎么把一个接口变成运行时的实例对象呢?在这个具体例子里就是:任何使变量samplesClient被@Autowired注解修饰后变成实例对象?
@Autowired是Spring框架定义的,在Spring框架中被注解修饰变量可能是原型实例对象,也可能是代理对象,所以,该怎么把这个接口变成实例对象现在就有了答案,可以想办法把接口变成运行时的代理对象。
了解Spring源码中的一个类org.springframework.context.annotation.ClassPathBeanDefinitionScanner,这个类是Spring为了扫描一堆BeanDefinition而设计的,目的就是要从@SpringBootApplication注解中设置过的包路径及其子包路径中的所有类文件中,扫描出含有@Component、@Configuration等注解的类,并构建BeanDefinition对象。
我们可以利用Spring这套扫描机制,自定义扫描器类,然后自定义扫描器类中自己手动构建BeanDefinition对象并且后续创建代理对象。
public class DubboFeignScanner extends ClassPathBeanDefinitionScanner { // 定义一个 FactoryBean 类型的对象,方便将来实例化接口使用 private DubboClientFactoryBean<?> factoryBean = new DubboClientFactoryBean<>(); // 重写父类 ClassPathBeanDefinitionScanner 的构造方法 public DubboFeignScanner(BeanDefinitionRegistry registry) { super(registry); } // 扫描各个接口时可以做一些拦截处理 // 但是这里不需要做任何扫描拦截,因此内置消化掉返回true不需要拦截 public void registerFilters() { addIncludeFilter((metadataReader, metadataReaderFactory) -> true); } // 重写父类的 doScan 方法,并将 protected 修饰范围放大为 public 属性修饰 @Override public Set<BeanDefinitionHolder> doScan(String... basePackages) { // 利用父类的doScan方法扫描指定的包路径 // 在此,DubboFeignScanner自定义扫描器就是利用Spring自身的扫描特性, // 来达到扫描指定包下的所有类文件,省去了自己写代码去扫描这个庞大的体力活了 Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages); if(beanDefinitions == null || beanDefinitions.isEmpty()){ return beanDefinitions; } processBeanDefinitions(beanDefinitions); return beanDefinitions; } // 自己手动构建 BeanDefinition 对象 private void processBeanDefinitions(Set<BeanDefinitionHolder> beanDefinitions) { GenericBeanDefinition definition = null; for (BeanDefinitionHolder holder : beanDefinitions) { definition = (GenericBeanDefinition)holder.getBeanDefinition(); definition.getConstructorArgumentValues().addGenericArgumentValue(definition.getBeanClassName()); // 特意针对 BeanDefinition 设置 DubboClientFactoryBean.class // 目的就是在实例化时能够在 DubboClientFactoryBean 中创建代理对象 definition.setBeanClass(factoryBean.getClass()); definition.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
自定义DubboFeignScanner对象并且继承ClassPathBeanDefinitionScanner,重写doScan方法,接收包路径,利用super.doScan让Spring帮助扫描指定包路径下的所有类文件。还可以手动在processBeanDefinitons方法中创建BeanDefinition对象。
这里扩展一个点,以上是理想中的实现逻辑,但是实际开发中,可能经常发现指定的包路径下有一些其他类文件,导致DubboFeignScanner.doScan方法扫描后,不准确或者出现各种报错。可以借鉴Spring框架的处理思路,Spring 源码在添加 BeanDefinition 时,需要借助一个 org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#isCandidateComponent 方法,来判断是不是候选组件,也就是,是不是需要拾取指定注解。
我们也重写isCandidateComponent方法,判断一下,如果扫描出来的类包含有@DubboFeignClient注解,就添加BeanDefinition对象,否则就不处理。
这样包含@DubboFeignClient注解的类的BeanDefiniton对象都被扫描收集起来,接着Spring本身refresh方法中的org.springframework.beans.factory.support.DefaultListableBeanFactory#preInstantiateSingletons 方法进行实例化了,而实例化的时候,如果发现 BeanDefinition 对象是 org.springframework.beans.factory.FactoryBean 类型,会调用 FactoryBean 的 getObject 方法创建代理对象。
针对接口进行代理对象的创建,可以使用JDK中的java.lang.reflect,Proxy类,可以这样创建代理对象:
public class DubboClientFactoryBean<T> implements FactoryBean<T>, ApplicationContextAware { private Class<T> dubboClientInterface; private ApplicationContext appCtx; public DubboClientFactoryBean() { } // 该方法是在 DubboFeignScanner 自定义扫描器的 processBeanDefinitions 方法中, // 通过 definition.getConstructorArgumentValues().addGenericArgumentValue(definition.getBeanClassName()) 代码设置进来的 // 这里的 dubboClientInterface 就等价于 SamplesFacadeClient 接口 public DubboClientFactoryBean(Class<T> dubboClientInterface) { this.dubboClientInterface = dubboClientInterface; } // Spring框架实例化FactoryBean类型的对象时的必经之路 @Override public T getObject() throws Exception { // 为 dubboClientInterface 创建一个 JDK 代理对象 // 同时代理对象中的所有业务逻辑交给了 DubboClientProxy 核心代理类处理 return (T) Proxy.newProxyInstance(dubboClientInterface.getClassLoader(), new Class[]{dubboClientInterface}, new DubboClientProxy<>(appCtx)); } // 标识该实例化对象的接口类型 @Override public Class<?> getObjectType() { return dubboClientInterface; } // 标识 SamplesFacadeClient 最后创建出来的代理对象是单例对象 @Override public boolean isSingleton() { return true; } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.appCtx = applicationContext; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
代码中getObject是我们创建代理对象的核心过程,我们还创建了一个DuboClientProxy对象,这个对象放在java.lang,reflect.Proxy#newProxyInstance(java.lang.ClassLoader,java.lang.Class<?>[],**java.lang.reflect.InvocationHandler**)方法中的第三个参数。
这意味着,将来含有@DubboFeignClient注解的类的方法被调用的时候,一定会出发调用DubboClientProxy类,也就说我们可以在DubboClientProxy类拦截方法。
public class DubboClientProxy<T> implements InvocationHandler, Serializable { @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // 省略前面的一些代码 // 读取接口(例:SamplesFacadeClient)上对应的注解信息 DubboFeignClient dubboClientAnno = declaringClass.getAnnotation(DubboFeignClient.class); // 读取方法(例:queryRemoteOrderInfo)上对应的注解信息 DubboMethod methodAnno = method.getDeclaredAnnotation(DubboMethod.class); // 获取需要调用下游系统的类、方法、方法参数类型 Class<?> remoteClass = dubboClientAnno.remoteClass(); String mtdName = getMethodName(method.getName(), methodAnno); Method remoteMethod = MethodCache.cachedMethod(remoteClass, mtdName, methodAnno); Class<?> returnType = method.getReturnType(); // 发起真正远程调用 Object resultObject = doInvoke(remoteClass, remoteMethod, args, methodAnno); // 判断返回码,并解析返回结果 return doParse(dubboClientAnno, returnType, resultObject); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
DubboClientProxy.invoke方法,按照不变的代码流程,从类注解、方法注解分别将变化的因素读取出来,然后构建调用下游系统的请求对象,并将请求对象传入下游系统的接口中,然后接收返参并针对错误码进行判断,最后转成自己的Bean对象。
这样就实现了一套代码解决了所有的integration层接口的远超调用,简化了重复代码的开发,简化代码。
Dubbo扫描原理机制
Dubbo源码中的DubboClassPathBeanDefinitionScanner这个类,继承了ClassPathBeanDefinitionScanner,充分利用了Spring的扩展性来实现自己的三个注解类,org.apache.dubbo.config.annotation.DubboService、org.apache.dubbo.config.annotation.Service、com.alibaba.dubbo.config.annotation.Service,然后完成对BeanDefinition对象的创建,在完成Proxy代理对象的创建,最后在运行时可以直接拿来使用。
不管是在系统中定义接口也好,还是在自研框架中定义接口也好,如果这些接口是同类性质的,而且 Spring 还无法通过注解修饰接口直接使用的话,都可以采取扫描机制统一处理共性逻辑,将不变的流程逻辑下沉,将变化的因素释放给各个接口。
学习来源:极客时间 《Dubbo源码剖析与实战》 学习笔记 Day01

