
- 1Mybatis入门学习,以及在编写入门案例时大家可能遇到的问题,例如sqlSession未回滚所遇到的问题导致代码可以执行,但是数据无法正常与数据库进行交互……_mybaits sqlsession 不会滚
- 2JSP和Servlet面试题
- 3frp反向代理配置不生效_frps.ini修改了配置文件但是没有生效
- 4理解 JavaScript 中的 blob_javascript blob
- 5Unity_SteamVR_VRTK_手柄发射射线_unity vrtk手柄射线
- 6技术淘宝
- 7计算机网络之应用层图解,秒解应用层HTTP,期末考试不担心!!_计算机应用图解
- 8SnappyData--一个统一OLTP+OLAP+流式写入的内存分布式数据库_snappydata官网
- 9Android7.0新特性及开发指南(转载)_android7或者更高版本的设备中,使用jit/aot混合编译模式
- 10【Server】Socket编程原理详解_serversocket原理
CVPR 2022 Oral | 利用递归"瞥视"解码器优化Transformer目标检测算法
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:京东探索研究院
本工作由京东探索研究院和悉尼大学联合完成,已经被CVPR 2022 接收,并获得口头报告(oral)展示机会。在本文中,我们提出了一个利用递归“瞥视”解码器的方法来利用兴趣区域信息,从而有效加速基于Transformer的目标检测算法。具体来说,我们试图模仿人类的视觉感知过程并借助类似于“瞥视”的行为获取有关物体位置的大致信息,然后通过一个多阶段递归的处理过程,帮助模型逐渐地聚焦到正确的物体区域,从而较大程度上降低模型进行目标检测的难度,减少其所需的训练周期。在大数据集实验中,我们的方法被证明能减少30%左右当前最先进模型所需的训练周期且不会使目标检测的准确率下降。在使用相同训练周期的情况下,我们的方法也能进一步提升5%左右的检测准确率。


Paper: https://arxiv.org/abs/2112.04632
Code: https://github.com/zhechen/Deformable-DETR-REGO
01
研究背景
近期,基于Transformer的目标检测算法开始在学术界流行起来。这一类算法通过建模全局视觉信息,能直接输出图片中出现物体的详细位置和类别信息。和传统目标检测算法不同,此类算法避免了额外的后处理过程,能高效高质量地进行目标检测。
然而,此类算法一个比较重要的缺陷在于往往需要极长的训练周期来优化模型参数并确保其能正确地关注物体区域。具体来说,传统算法一般需要12或24个训练周期来获取高质量模型参数,而最原始的基于Transformer的目标检测算法却需要500个训练周期来获取同等质量的模型参数。这一缺点极大地阻碍了这一类算法的发展和应用。
经过调研,我们发现近期的一些工作试图通过优化特征表示或是改进模型结构来处理这一问题。总体上,目前的改进工作倾向于在训练的过程中帮助基于Transformer的目标检测器更快地找到正确的物体区域,从而减少整体的训练过程。这些工作在一定程度上缓解了这一问题。
不同于目前的方法,我们发现有关可能包含物体的兴趣区域(region-of-interest)信息能直接、简单、有效地帮助缩短需要的训练周期。具体来说,我们试图模仿人类的视觉感知过程并借助类似于“瞥视”的行为获取有关物体位置的大致信息,然后通过一个多阶段递归的处理过程,帮助模型逐渐地聚焦到正确的物体区域,从而较大程度上降低模型进行目标检测的难度,减少其所需的训练周期。依此,在本文中,我们提出了一个利用递归“瞥视”解码器的方法来利用兴趣区域信息,从而有效加速基于Transformer的目标检测算法。
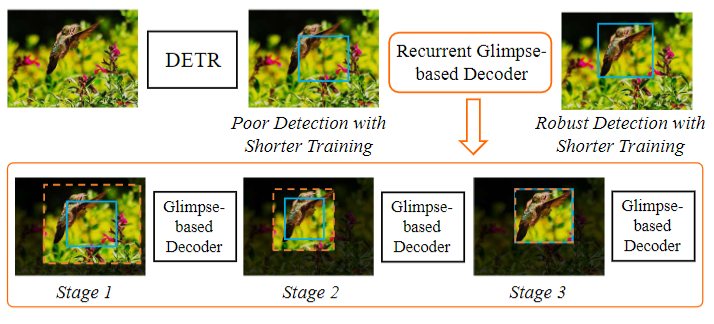
图1 递归“瞥视”解码器 (REGO: Recurrent Glimpsed-based Decoder) 的概念展示。
02
递归“瞥视”解码器
2.1 算法概述
递归“瞥视”解码器主要通过扩大物体兴趣区域并提取其中的视觉信息作为“瞥视”的实现。然后,我们引入了一个视觉解码器以解释获取到的“瞥视”信息,使其能帮助基于Transformer的目标检测器更能正确地捕捉到物体区域。在实现的过程中,我们使用了递归多阶段处理的策略,使其能逐渐且稳定地改善检测器的输出。在每一个递归阶段中,我们都进行一次“瞥视”和解码。解码后的信息,和原始Transformer目标检测算法的视觉信息合并,进而产生改善的视觉信息表示及目标检测结果。每一个阶段得到的最终视觉信息和检测结果则会被递归地送到下一阶段的处理过程中。图2展示了具体的操作流程。
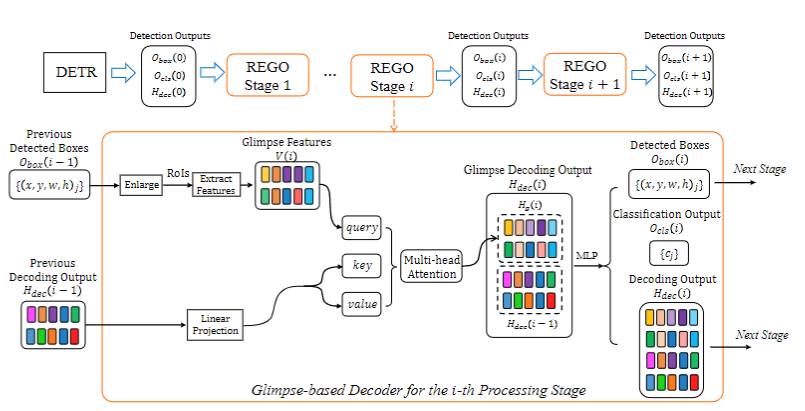
图2 递归“瞥视”解码器(REGO)每一阶段的处理框架图
2.2 算法详述
在每一个阶段中,我们使用前一个阶段的视觉解码信息 及其检测框预测结果 作为算法输入,然后输出本阶段“瞥视”信息改进的视觉解码信息 及检测结果 ,包括物体类别识别结果 和及其检测框预测结果 。值得一提的是,我们令原始基于Transformer的目标检测算法的视觉信息和检测框预测结果作为第一个阶段的输入,则后续阶段可以递归地进行“瞥视”解码及改进操作。
在一个阶段中,我们首先提取“瞥视”信息。提取过程主要通过扩大前一阶段预测的检测框然后提取其中的视觉特征得到。假设 代表视觉特征, 代表提取的“瞥视”信息,则我们使用一下操作:
(1)
其中 代表视觉特征提取操作, 代表扩大检测框的操作, α 则表示本阶段使用的扩大系数。
根据公式(1)得到的“瞥视”信息,我们使用一个解码器,定义为 ,将其根据前一个阶段的信息解码成可以用来改进检测的表示 :
(2)
最后,我们将“瞥视”解码结果 和建议阶段的视觉解码信息合并 ,得到本阶段的视觉解码信息:
(3)
在得到本阶段的视觉解码信息之后,我们就可以让神经网络基于这一信息产生关于物体类别机器检测框位置的预测。
2.3 实验结果
在大数据集实验中,我们的方法可以被证明能减少30%左右当前最先进模型所需的训练周期且不使得目标检测准确率下降。在使用相同训练周期的情况下,我们的方法也能进一步提升5%左右的检测准确率。这些结果证明了我们提出的方法在基于Transformer的目标检测算法上的高效性,同时也展示出了我们的方法代表了本领域发展的最前沿成果。
具体来说,我们首先能改进原始基于Transformer的目标检测算法的收敛速度。图3展示了我们的方法(红线)应用在现有Transformer检测器(灰线)的收敛效果,横轴代表了训练周期长短,竖轴代表了检测效果。可以看到,我们的方法使用36圈即可以得到比原方法50圈的收敛结果还要好的检测效果,大大减少了训练周期。
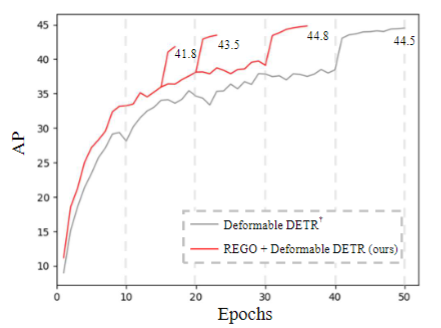
图3 我们的方法(REGO)相对于baseline在收敛速度上的提升效果
我们在图4展示了更详细的目标检测实验效果比较。我们对比了改进后的原始Transformer检测器(DETR)以及最新的Transformer检测器(Deformable DETR)在是否使用我们提出方法(REGO)的情况下得到的检测效果。从实验结果中,我们可以看到,我们的方法能帮助原有方法在36圈训练周期里得到和原来50圈训练周期相当水平的结果。同时,我们的方法也能在50圈训练周期里得到大致相对5%的检测精度提升。同时,我们的方法仅仅引入了较少的计算复杂都和参数量。
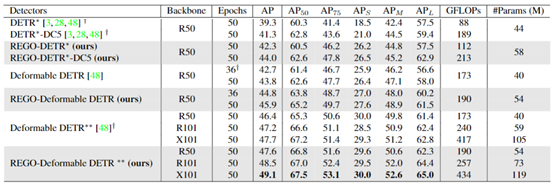
表1 基于Transformer的目标检测算法以及我们的方法(REGO)检测表现对比
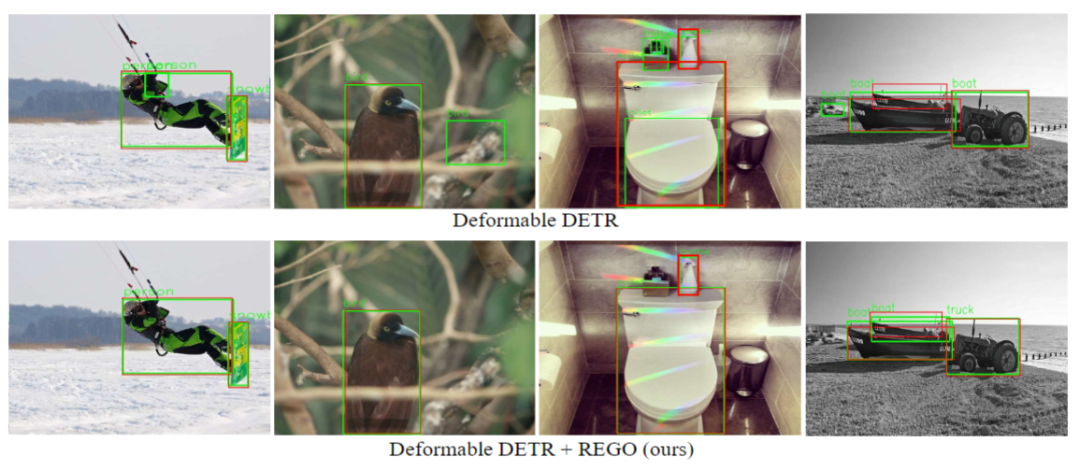
图 4 我们的方法(REGO)和原始方法(Deformable DETR)检测结果可视化
我们在图4中进一步展示了我们的方法(REGO)和原始方法(Deformable DETR)检测结果的可视化效果。我们可以看到,原始的方法仍然会产生一些错误的检测,而我们的方法能有效地帮助识别并排除这些错误检测结果。
03
结论
在本文中,我们提出了一个利用递归“瞥视”解码器的方法来利用兴趣区域信息,从而有效加速基于Transformer的目标检测算法。我们成功地借用了人类的视觉感知过程中 “瞥视” 的概念并实现了一个有效的多阶段递归 “瞥视” 解码的处理过程,帮助模型逐渐地聚焦到正确的物体区域,从而较大程度上降低模型进行目标检测的难度,减少其所需的训练周期。在每一个阶段中,我们通过扩大物体兴趣区域并提取其中的视觉信息作为 “瞥视” 的实现,然后我们引入了一个视觉解码器以解释获取到的 “瞥视” 信息。我们基于视觉解码器的输出来产生本阶段的目标检测结果,这一结果之后被递归地送到下一阶段的处理过程中,进而产生改善的目标检测结果。在大数据集实验的结果证明了我们提出的方法在基于Transformer的目标检测算法上的高效性,同时也展示出了我们的方法代表了本领域发展的最前沿成果。
参考文献
[1] Chen, Zhe, Jing Zhang, and Dacheng Tao. "Recurrent Glimpse-based Decoder for Detection with Transformer." In CVPR, 2022.
[2] Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. "End-to-end object detection with transformers." In ECCV, 2020.
[3] Meng, Depu, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, and Jingdong Wang. "Conditional detr for fast training convergence." In ICCV. 2021.
[4] Zhu, Xizhou, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. "Deformable DETR: Deformable Transformers for End-to-End Object Detection." In ICLR. 2020.
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
- 目标检测和Transformer交流群成立
- 扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲扫码或加微信: CVer6666,进交流群
- CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
-
- ▲扫码进群
- ▲点击上方卡片,关注CVer公众号
-
- 整理不易,请点赞和在看

