
- 1JAVA 防止重复提交 防止用户重复提交数据拦截器_blade 防重复提交
- 2移动端的布局
- 3android 分区 f2fs,一加5 切换data分区为f2fs格式,随机读写暴涨8倍!30秒开机,APP秒开!...
- 4FAILED BINDER TRANSACTION (Android Binder传输数据大小限制)_!!! (parcel size = 116)
- 5ArkTs基本组成和基本使用介绍_arkts 怎么新建页面
- 6ASP.NET防止数据重复提交_aspnet避免重复交易
- 7《缓存背后的黑科技:揭秘Redis架构设计与高性能原理》_redis架构原理与高性能实战
- 8基于STM32的ESP8266WIFI模块的通信_esp8266wifi模块连接stm32
- 9简单三步,教你如何批量查询快递单号_查询条件中需要支持批量查询单号
- 10Unity3D错误整理(一)_unity收不到激活邮件
AIGC内容分享(三十五):AIGC赋能的“秒鸭相机”到底有多强?
赞
踩
目录
01-FaceChain算法简介

FaceChain是一个可以用来打造个人数字形象的深度学习模型工具。用户仅需要提供最低一张照片即可获得独属于自己的个人形象数字替身。它是一个个性化的肖像生成框架,它结合了一系列定制的图像生成模型和一组丰富的人脸相关感知理解模型(如人脸检测、深度人脸嵌入提取和人脸属性识别),以应对上述挑战并生成真实的个性化肖像,其中只有少数人像图像作为输入。
具体而言,与之前的解决方案(如DreamBooth、InstantBooth或其它仅限LoRA的方法)相比,作者在生成过程中注入了几个SOTA人脸模型,实现了更高效的标签标记、数据处理和模型后处理。FaceChain被设计成一个由可插入组件组成的框架,这些组件可以轻松调整以适应不同的风格和个性化需求。此外,基于FaceChain,作者进一步开发了几个应用程序,以构建一个更广阔的游乐场,更好地展示其价值,包括虚拟试穿和2D会说话的头。
FaceChain支持在gradio的界面中使用模型训练和推理能力、支持资深开发者使用python脚本进行训练推理,也支持在sd webui中安装插件使用。上图展示了几个FaceChain工具的测试样例生成效果。
02-FaceChain-FACT算法简介
虽然FaceChain是一款具有面部身份保护功能的个性化肖像生成工具,但是它需要训练用户的LoRA模型,这增加了用户的开发成本。为了解决该问题,作者提出了一种称为FaceChain-FACT的零样本版本,该版本不需要训练Face-LoRA模型。此外,只需要用户的一张照片就可以生成定制的肖像。与SOTA的商业应用相比,该算法的生成速度加快了100倍,达到了二级图像生成速度。作者集成了一个基于变换器的人脸特征提取器,其结构类似于稳定扩散,使稳定扩散能够更好地利用人脸信息;该算法使用密集的细粒度特征作为人脸条件,具有更好的字符再现性;FaceChain FACT与ControlNet和LoRA插件无缝兼容,即插即用。
03-FaceChain算法流程
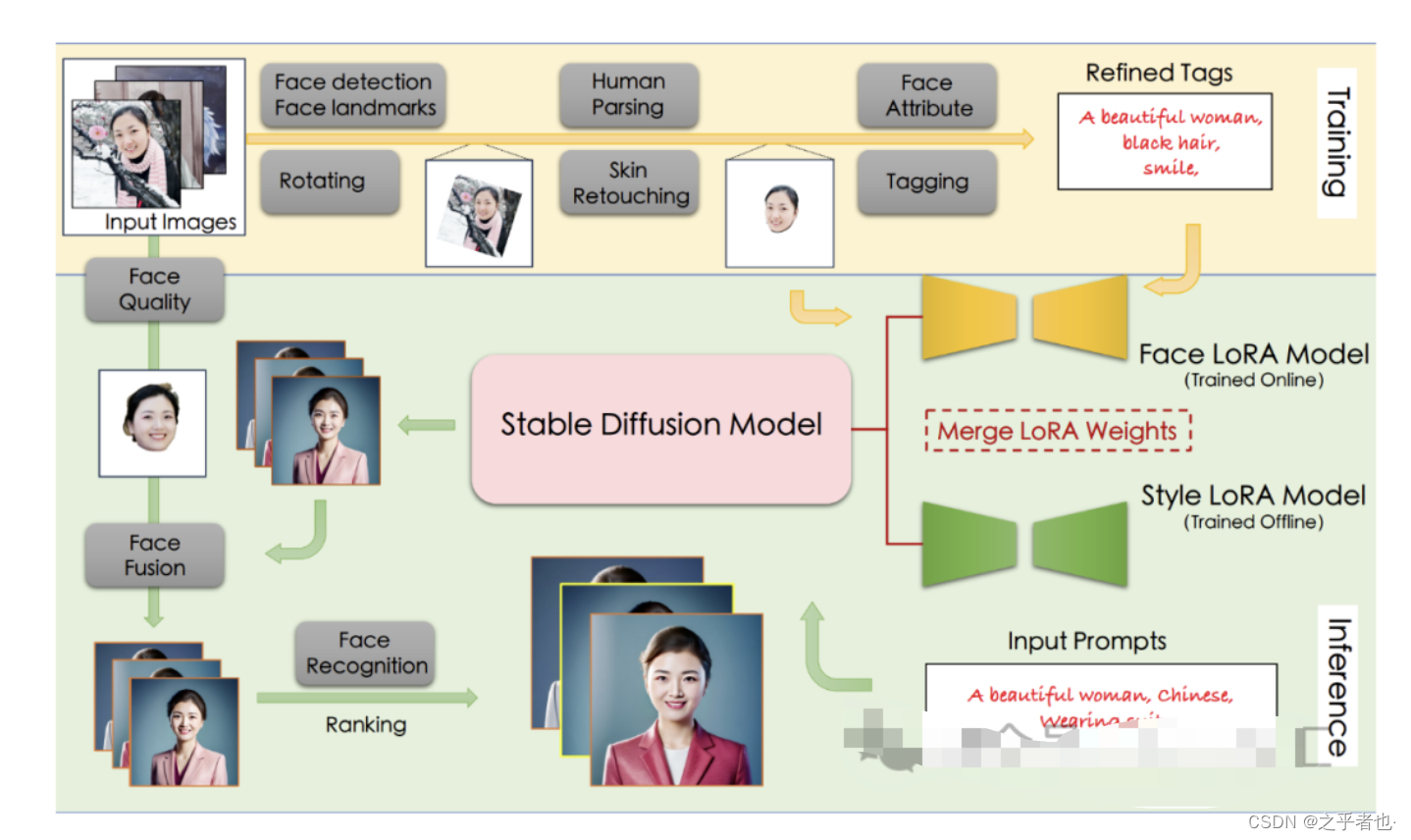
上图展示了FaceChain算法的整体流程,个人写真模型的能力来源于Stable Diffusion模型的文生图功能,输入一段文本或一系列提示词,输出对应的图像。作者考虑影响个人写真生成效果的主要因素:写真风格信息,以及用户人物信息。为此,作者分别使用线下训练的风格LoRA模型和线上训练的人脸LoRA模型以学习上述信息。LoRA是一种具有较少可训练参数的微调模型,在Stable Diffusion中,可以通过对少量输入图像进行文生图训练的方式将输入图像的信息注入到LoRA模型中。因此,个人写真模型的能力分为训练与推断两个阶段,训练阶段生成用于微调Stable Diffusion模型的图像与文本标签数据,得到人脸LoRA模型;推断阶段基于人脸LoRA模型和风格LoRA模型生成个人写真图像。
输入:用户上传的包含清晰人脸区域的图像
输出:人脸LoRA模型
步骤:首先,分别使用基于朝向判断的图像旋转模型,以及基于人脸检测和关键点模型的人脸精细化旋转方法处理用户上传图像,得到包含正向人脸的图像;接着,使用人体解析模型和人像美肤模型,以获得高质量的人脸训练图像;随后,使用人脸属性模型和文本标注模型,结合标签后处理方法,产生训练图像的精细化标签;最后,使用上述图像和标签数据微调Stable Diffusion模型得到人脸LoRA模型。
推理阶段的细节如下所述:
输入:训练阶段用户上传图像,预设的用于生成个人写真的输入提示词
输出:个人写真图像
步骤:首先,将人脸LoRA模型和风格LoRA模型的权重融合到Stable Diffusion模型中;接着,使用Stable Diffusion模型的文生图功能,基于预设的输入提示词初步生成个人写真图像;随后,使用人脸融合模型进一步改善上述写真图像的人脸细节,其中用于融合的模板人脸通过人脸质量评估模型在训练图像中挑选;最后,使用人脸识别模型计算生成的写真图像与模板人脸的相似度,以此对写真图像进行排序,并输出排名靠前的个人写真图像作为最终输出结果。
04-FaceChain-FACT算法流程
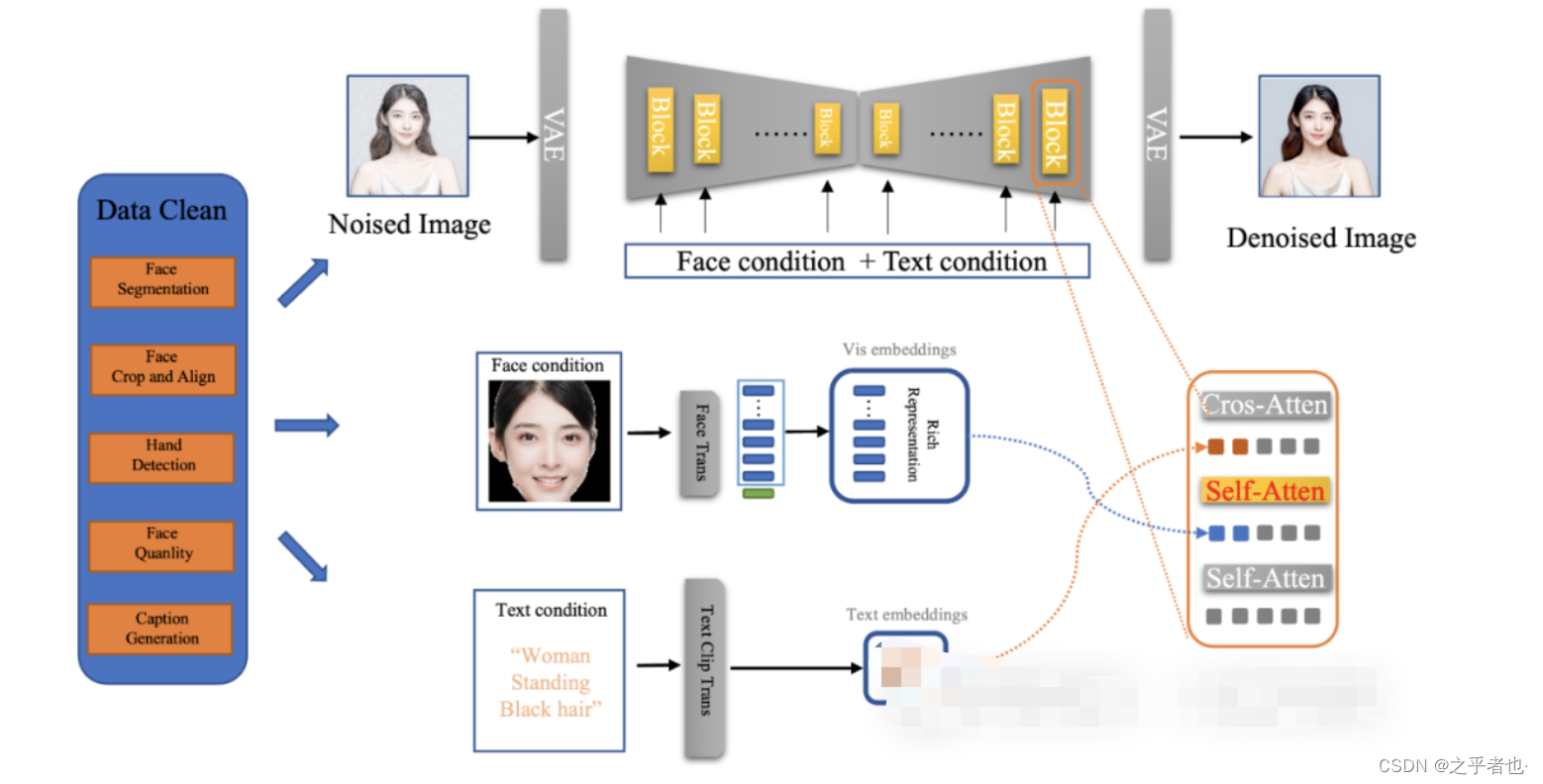
上图展示了FaceChain-FACT算法的具体流程。详细的步骤如下所述:
首先,使用一系列图像预处理,包括人脸分割、人脸裁剪和对齐、手部检测、人脸质量筛选等,来筛选并获得训练数据集。
然后,利用基于transformer的人脸特征提取器来提取特征,并利用倒数第二层的密集细粒度特征作为人脸条件。
接着,稳定扩散通过FACT适配器接收人脸条件,并将其与文本嵌入相结合,生成人像图像。
最后,通过融合FaceChain的各种LoRA模型,它可以生成各种风格的肖像。
05-FaceChain算法应用场景
05.01-虚拟试衣
随着网上购物的快速发展,人们对虚拟试穿的需求激增,虚拟试穿为特定的人和服装提供虚拟试穿体验。根据人或服装信息是否固定在交互体验中,虚拟试穿方法的核心思想可以分为生成服装和人的数字双胞胎。
作为人脸/以人为中心的身份保护肖像生成的游乐场,FaceChain还支持固定服装和生成人物的虚拟试穿。具体来说,给定要试穿的服装的真实或虚拟模型图像,以及经过训练的人脸LoRA模型,FaceChain可以重新绘制服装外部的区域,包括人物和背景,以获得虚拟试穿结果。
05.02-头像特写
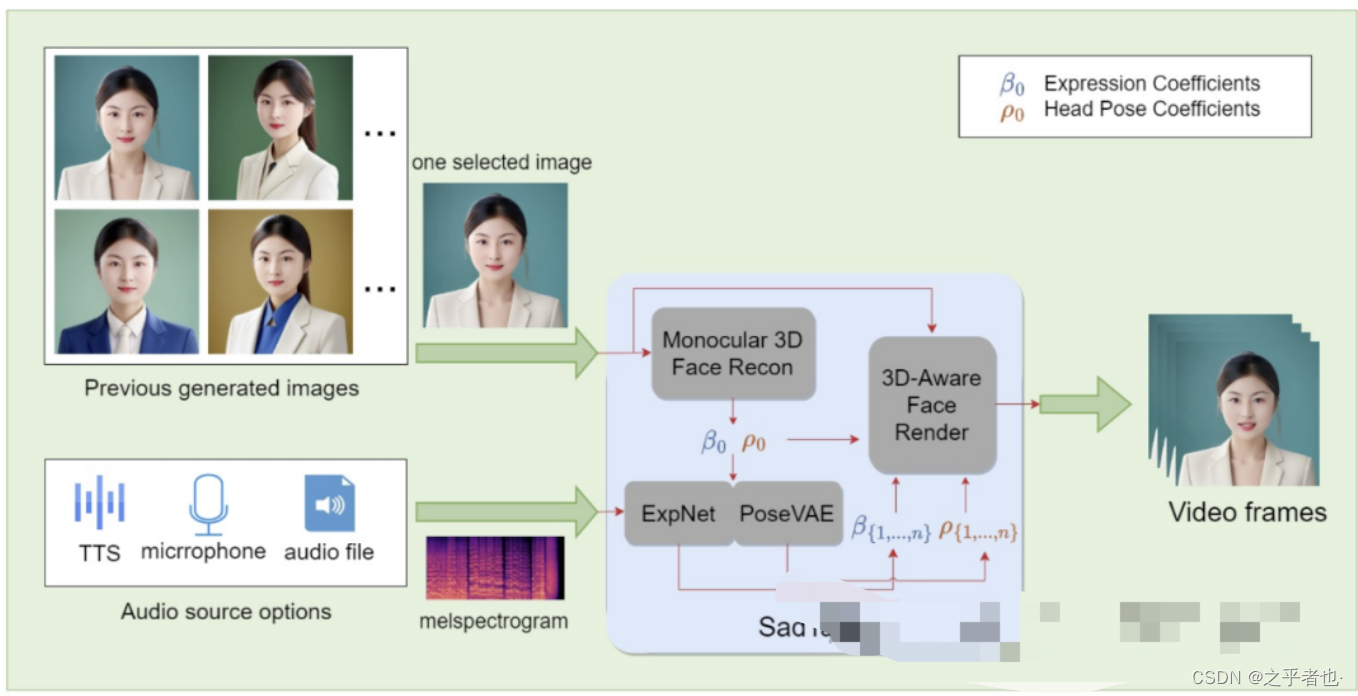
为了进一步探索生成的肖像的使用案例,作者想到了让肖像生动起来,具体来说,如上图所示,用户从以前生成的人像库中选择一张人脸图像,然后用户提供一个音频片段,FaceChain将使用它们输出一个讲肖像的视频。为了实现这一点,作者测试了几种会说话的头/脸算法,这些算法可以生成嘴唇与输入音频相对应的人像视频。最后,作者选择sadtake作为我们的谈话头部后端算法,因为wav2lip和视频重新命名只能改变面部的嘴唇,而SadTaker提出的PoseVAE和ExpNet可以分别改变头部姿势和面部表情,其中头部姿势可以从46个嵌入中选择一个,表情系数可以控制,并且还可以控制眨眼频率。
因为SadTaker的输入和输出分辨率是256或512,如果原始输入图像中的人脸分辨率相对较大,或者用户只是想提高整体分辨率,我们也支持使用GFPGAN作为后处理模块,可以将视频的分辨率提高一倍。至于音频剪辑,我们支持三种选项:1)TTS合成,2)麦克风录制,3)本地文件上传。至于TTS合成,作者使用微软Edge的API,因为它支持多语言混合输入,并支持多种语言合成,这使得FaceChain对世界各地的用户更加友好。
06-FaceChain环境搭建与运行
06.01-环境准备
- FaceChain是一个组合模型,基于PyTorch机器学习框架,以下是已经验证过的主要环境依赖:
- # 软件配置
- python环境: py3.8, py3.10
- pytorch版本: torch2.0.0, torch2.0.1
- CUDA版本: 11.7
- CUDNN版本: 8+
- 操作系统版本: Ubuntu 20.04, CentOS 7.9
- GPU型号: Nvidia-A10 24G
- # 硬件配置
- GPU: 显存占用约19G
- 磁盘: 推荐预留50GB以上的存储空间
06.02-Demo执行方案
- 方案1--使用ModelScope提供的notebook环境
-
- # Step1: 我的notebook -> PAI-DSW -> GPU环境
- # Step2: 进入Notebook cell,执行下述命令从github clone代码:
- !GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
-
- # Step3: 切换当前工作路径,安装依赖
- import os
- os.chdir('/mnt/workspace/facechain') # 注意替换成上述clone后的代码文件夹主路径
- print(os.getcwd())
-
- !pip3 install gradio==3.50.2
- !pip3 install controlnet_aux==0.0.6
- !pip3 install python-slugify
- !pip3 install onnxruntime==1.15.1
- !pip3 install edge-tts
- !pip3 install modelscope==1.10.0
-
- # Step4: 启动服务,点击生成的URL即可访问web页面,上传照片开始训练和预测
- !python3 app.py
-
- 方案2--创建docker镜像
-
- # Step1: 机器资源
- 您可以使用本地或云端带有GPU资源的运行环境。
- 如需使用阿里云ECS,可访问:https://www.aliyun.com/product/ecs,推荐使用”镜像市场“中的CentOS 7.9 64位(预装NVIDIA GPU驱动)
-
- # Step2: 将镜像下载到本地 (前提是已经安装了docker engine并启动服务,具体可参考:https://docs.docker.com/engine/install/)
- # For China Mainland users:
- docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.4
- # For users outside China Mainland:
- docker pull registry.us-west-1.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.4
-
- # Step3: 拉起镜像运行
- docker run -it --name facechain -p 7860:7860 --gpus all registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.4 /bin/bash # 注意 your_xxx_image_id 替换成你的镜像id
- # 注意:如果提示无法使用宿主机GPU的错误,可能需要安装nvidia-container-runtime
- # 1. 安装nvidia-container-runtime:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
- # 2. 重启docker服务:sudo systemctl restart docker
-
- # Step4: 在容器中安装gradio
- pip3 install gradio==3.50.2
- pip3 install controlnet_aux==0.0.6
- pip3 install python-slugify
- pip3 install onnxruntime==1.15.1
- pip3 install edge-tts
- pip3 install modelscope==1.10.0
-
- # Step5: 获取facechain源代码
- GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
- cd facechain
- python3 app.py
- # Note: FaceChain目前支持单卡GPU,如果您的环境有多卡,请使用如下命令
- # CUDA_VISIBLE_DEVICES=0 python3 app.py
-
- # Step6: 点击 "public URL", 形式为 https://xxx.gradio.live
-
- 方案3--创建Conda虚拟环境
-
- # Step1: 创建并进入虚拟环境
- conda create -n facechain python=3.8 # 已验证环境:3.8 和 3.10
- conda activate facechain
-
- # Step2: 获取源代码
- GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
- cd facechain
-
- # Step3: 安装三方依赖
- pip3 install -r requirements.txt
- pip3 install -U openmim
- mim install mmcv-full==1.7.0
-
- # Step4: 执行demo
- # 进入facechain文件夹,执行:
- python3 app.py
- # Note: FaceChain目前支持单卡GPU,如果您的环境有多卡,请使用如下命令
- # CUDA_VISIBLE_DEVICES=0 python3 app.py
-
- # 最后点击log中生成的URL即可访问页面。
-
- 方案4--Colab中执行Demo
- https://colab.research.google.com/github/modelscope/facechain/blob/main/f

07-FaceChain算法效果展示

图7.1-FaceChain算法效果展示1

图7.2-FaceChain算法效果展示2
08-FaceChain-FACT算法效果展示

图8.1-FaceChain-FACT算法效果展示1

图8.2-FaceChain-FACT算法效果展示2

图8.3-FaceChain-FACT算法效果展示3

