
- 1安卓手机安卓Mysql,Termux安装MariaDB/MySQL数据库_最新termux安装 mariadb
- 2史诗手册!微信小程序新手自学入门宝典!你想要的都在这里
- 3mysql 将数据库中的所有表结构和数据 导入到另一个库(亲测有效)_数据库表结构怎么导
- 4HarmonyOS与Android:全面对比解析_android 与 harmonyos 开发区别简述
- 5mysql数据库代理--mycat_mysql 代理
- 6干洗店管理系统洗鞋店预约上门小程序洗护流程;
- 7minecraft服务器搭建教程_我的世界游戏服务器搭建详细教程
- 8计算机网络实验---Wireshark 实验_wireshark捕获fcs
- 9物联网云原生云边协同
- 10python中subprocess模块subprocess.run,subprocess.getoutput,subprocess.Popen、subprocess.call的使用
Faster RCNN总结_faster_rcnn_resnet50_coco_2018_01_28.pbtxt
赞
踩
faster RCNN选自2015年 NIPS, Faster R-CNN: Towards Real-Time Object Detection withRegion Proposal Networks

正如上图所示,检测不同尺度(scale),不同长宽比(aspect ratios)的目标物通常的3种做法。
(a)Pyramids of images,缩放图像来达到不同的scale,传统机器学习常用的方法
(b)Pyramids of filters,也就是sliding window的思想,也是传统机器学习常用的方法
(c)Pyramids of anchors,fast rcnn提出,Faster rcnn正式命名为RPN(region proposal network),并且从fast rcnn的cpu移植到了fasterrcnn的gpu上。可以实现不同不同scale和不同aspect ratios的检测,使得检测效果更佳准确完美啊。
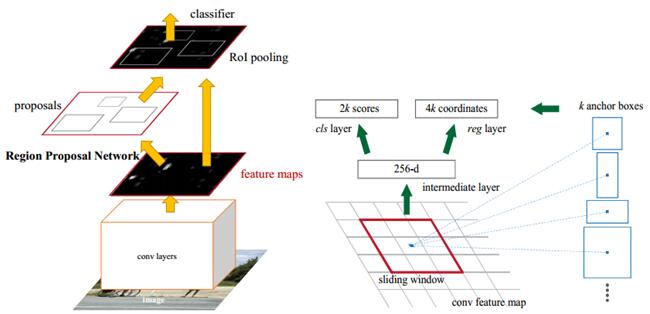
整个网络结构如上图的左图所示,分为2个网络结构,一个RPN网络和一个FastRCNN网络,两个网络共享了特征图这一层。由于是2个网络结构,训练过程也有点不一样,作者论文中给出了3个训练的方法,
(1)Alternating training,先从pretrained VGG16中导入初始参数,然后有了参数后,先训练RPN,然后RPN将结果送给Fast RCNN,在训练一把Fast RCNN训练完毕后更新卷积层,然后,RPN在从卷基层提取数据,如此不断循环往复。开源的matlab版本就是这种训练方法。
(2)Approximate joint training,就是2个网络一起训练,但是该方法忽略了wrt导数,开源的python版本就是这么训练的,可以减少25-50%的训练时间。为什么呢?因为caffe中所有层都是c++实现的,所以python_layer就没有进行back_ward,当然训练的时候必须显式指定loss_weight:1。
(3)Non-approximate joint training,作者没有实现。
上图中的右图详细说明了RPN的实现细节。
首先,作者提出了Anchor这个概念,其实就是feature map上的一个像素,以该Anchor为中心,可以生成k种 anchor boxes,简单理解就是不同大小和尺度的滑动框,例如本文中的k为9,则生成3个scales和1:1,1:2,2:1,3种aspect ratios。然后使用不同的anchor boxes进行滑动,整个feature map中IOU最高的和每个anchor中,IOU>0.7的将被激活,置为1,IOU<0.3的将被置为0,从而实现了hard negative mining,滑动完毕后将生成256维的向量,然后分别经过2个1*1的卷基层(classification layer,regression layer),分别生成2k scores(是物体,不是物体)和4k coordinates(x,y,w,h)。从而实现了物体的检测,最后经过softmax,实现物体的分类。
anchor:
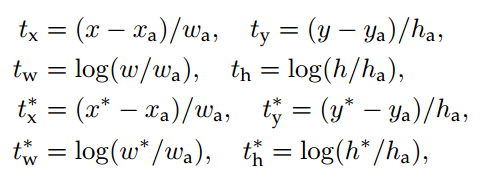
安装步骤:
git clone --recursive https://github.com/ShaoqingRen/faster_rcnn.git
cd ./faster-rcnn/external/caffe
make -j8&&make matcaffe
faster_rcnn_build.m
startup.m
fetch_data/fetch_faster_rcnn_final_model.m (这一步我下载失败,可以去作者github做下面的百度网盘下载,下载Final RPN+FastRCNN models就可以了)
experiments/script_faster_rcnn_demo.m
测试:
下面测试显卡为TitanX
使用VGG16的测试,

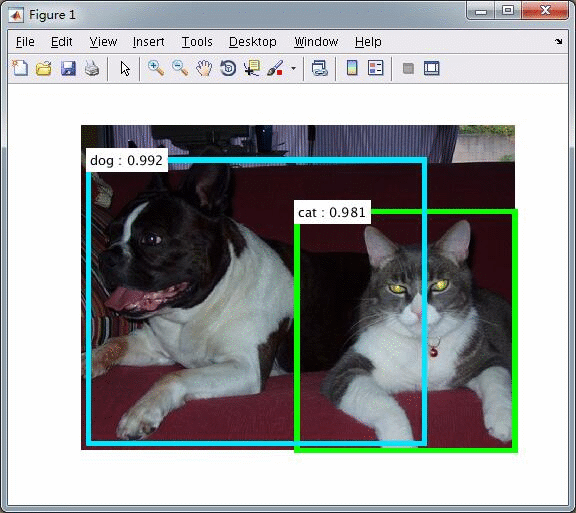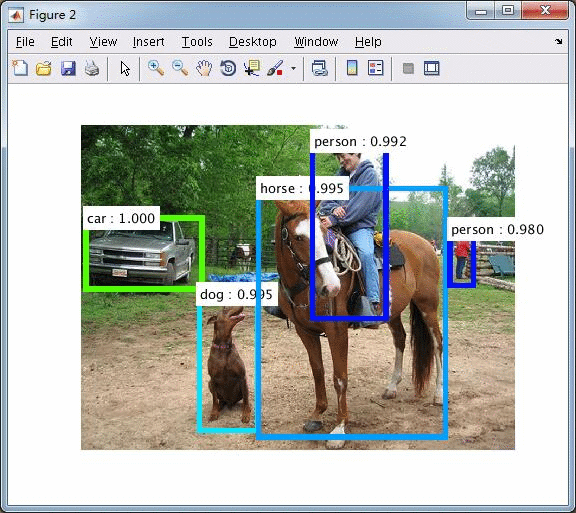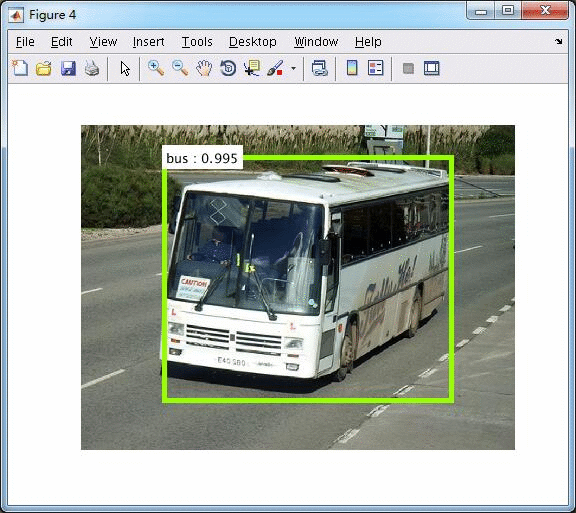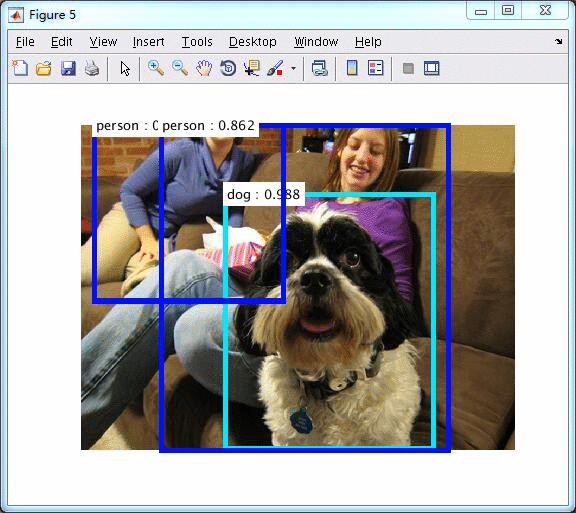
使用ZFnet的测试,
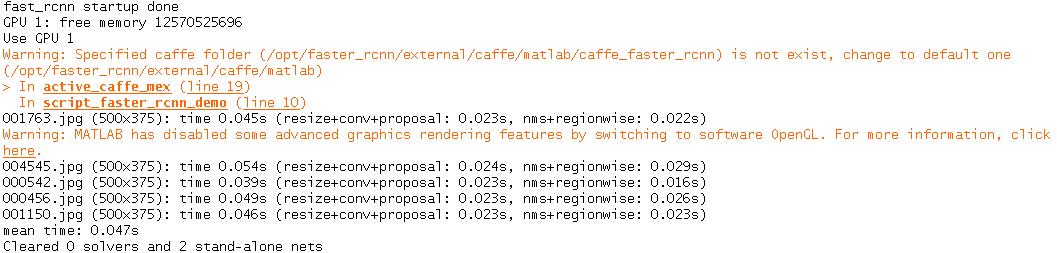
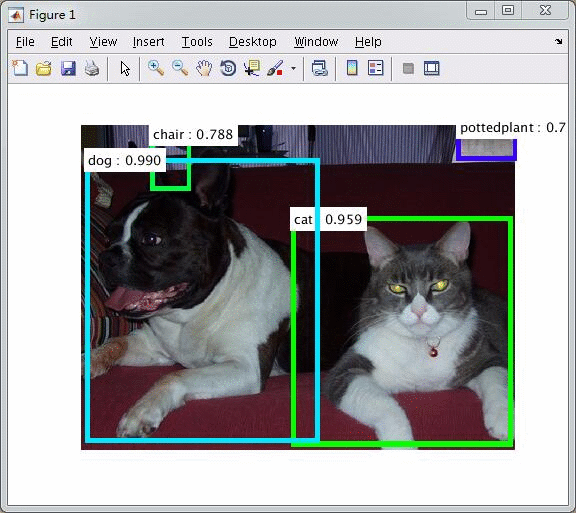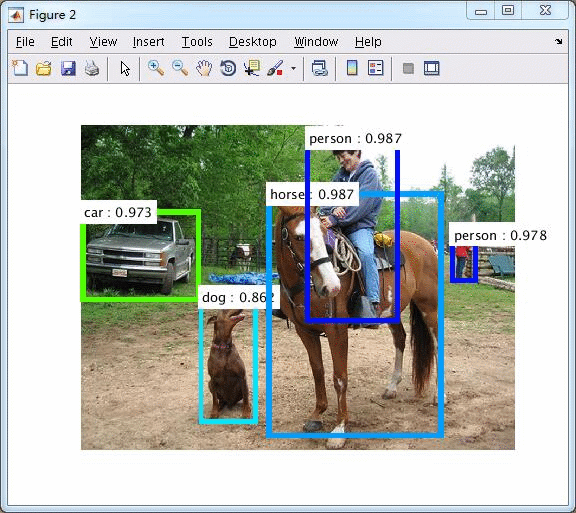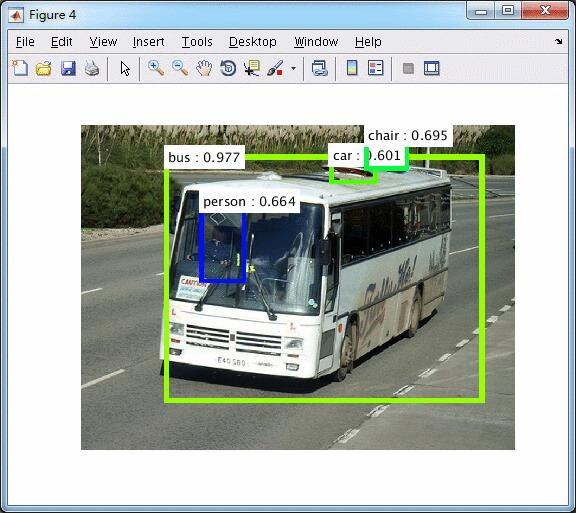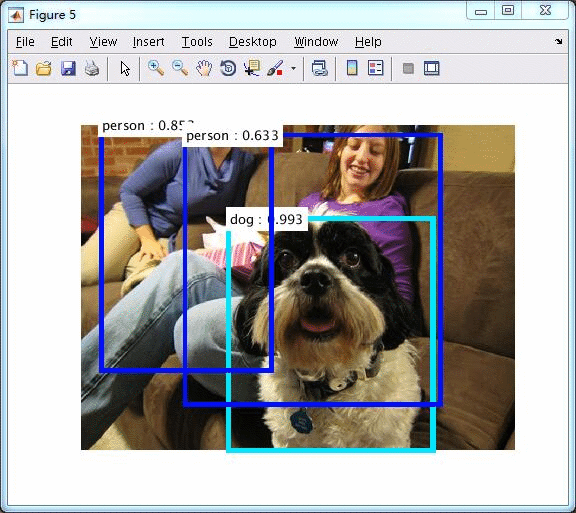
windows c++版本
这里所使用的windows caffe为https://github.com/Microsoft/caffe,
可以参考http://blog.csdn.net/qq_14845119/article/details/52415090这篇文章进行编译。
一个注意事项,在编译之前,在libcaffe下面的cu,include,src下面分别添加,roi_pooling_layer.cu,roi_pooling_layer.hpp,roi_pooling_layer.cpp。
这里的程序为根据matlab版本的faster-rcnn改写。
运行效果:
pets数据集上运行效果如下,1050Ti下运行时间为100ms的样子

整体流程:
(1)对整张图片进行cnn操作,得到feature map。
(2)将feature map输入RPN网络,得到候选框坐标信息。
(3)通过候选框坐标信息在feature map上提取特征,输入后续的cnn网络,得到特征信息。
(4)通过ROI poolig得到固定大小的特征图,然后输入分类和回归分支,进行分类和回归。
opencv3调用:
模型文件下载路径:
https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API#generate-a-config-file
c++调用:
可执行文件目录:
D:\opencv-3.4.4\x86\vc12\bin
包含目录:
D:\opencv-3.4.4\include
D:\opencv-3.4.4\include\opencv
D:\opencv-3.4.4\include\opencv2
库目录:
D:\opencv-3.4.4\x86\vc12\lib
链接-->输入:
opencv_core344d.lib
opencv_highgui344d.lib
opencv_imgproc344d.lib
opencv_dnn344d.lib
opencv_imgcodecs344d.lib
- #include "a.h"
- #include<opencv2\opencv.hpp>
- #include<opencv2\dnn.hpp>
- #include <iostream>
- #include<map>
- #include<string>
- #include<time.h>
- using namespace std;
- using namespace cv;
-
-
- //这是coco数据集的类别
- const char* classNames[] = { "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
- "fire hydrant", "background", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "background", "backpack",
- "umbrella", "background", "background", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket",
- "bottle", "background", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut",
- "cake", "chair", "couch", "potted plant", "bed", "background", "dining table", "background", "background", "toilet", "background", "tv", "laptop", "mouse", "remote", "keyboard",
- "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "background", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush", "background" };
-
-
-
- int main()
- {
-
- String weights = "faster_rcnn_resnet50_coco_2018_01_28/frozen_inference_graph.pb";
- String prototxt = "faster_rcnn_resnet50_coco_2018_01_28/faster_rcnn_resnet50_coco_2018_01_28.pbtxt";
- dnn::Net net = cv::dnn::readNetFromTensorflow(weights, prototxt);
-
- Mat frame = cv::imread("./1.png");
- Size frame_size = frame.size();
-
-
- cv::Mat blob = cv::dnn::blobFromImage(frame, 1, frame_size, false, true);
-
- net.setInput(blob);
- Mat output = net.forward();
-
- Mat detectionMat(output.size[2], output.size[3], CV_32F, output.ptr<float>());
-
- float confidenceThreshold = 0.5;
- for (int i = 0; i < detectionMat.rows; i++)
- {
- float confidence = detectionMat.at<float>(i, 2);
-
- if (confidence > confidenceThreshold)
- {
- size_t objectClass = (size_t)(detectionMat.at<float>(i, 1));
- int xLeftBottom = static_cast<int>(detectionMat.at<float>(i, 3) * frame.cols);
- int yLeftBottom = static_cast<int>(detectionMat.at<float>(i, 4) * frame.rows);
- int xRightTop = static_cast<int>(detectionMat.at<float>(i, 5) * frame.cols);
- int yRightTop = static_cast<int>(detectionMat.at<float>(i, 6) * frame.rows);
-
- ostringstream ss;
- ss << confidence;
- String conf(ss.str());
-
- Rect object((int)xLeftBottom, (int)yLeftBottom,
- (int)(xRightTop - xLeftBottom),
- (int)(yRightTop - yLeftBottom));
-
- rectangle(frame, object, Scalar(0, 255, 0), 2);
- String label = String(classNames[objectClass]) + ": " + conf;
- int baseLine = 0;
- Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
- rectangle(frame, Rect(Point(xLeftBottom, yLeftBottom - labelSize.height),
- Size(labelSize.width, labelSize.height + baseLine)),
- Scalar(0, 255, 0), CV_FILLED);
- putText(frame, label, Point(xLeftBottom, yLeftBottom),
- FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));
- }
- }
- namedWindow("image", CV_WINDOW_NORMAL);
- imshow("image", frame);
- waitKey(0);
- return 0;
- }

python3调用:
安装:
pip3 install opencv-contrib-python程序:
- import cv2 as cv
-
- cvNet = cv.dnn.readNetFromTensorflow('./faster_rcnn_resnet50_coco_2018_01_28/frozen_inference_graph.pb', './faster_rcnn_resnet50_coco_2018_01_28/faster_rcnn_resnet50_coco_2018_01_28.pbtxt')
-
- img = cv.imread('1.png')
- rows = img.shape[0]
- cols = img.shape[1]
- cvNet.setInput(cv.dnn.blobFromImage(img, size=(rows, cols), swapRB=True, crop=False))
- cvOut = cvNet.forward()
-
- for detection in cvOut[0,0,:,:]:
- score = float(detection[2])
- if score > 0.3:
- left = detection[3] * cols
- top = detection[4] * rows
- right = detection[5] * cols
- bottom = detection[6] * rows
- cv.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (255, 0, 0), thickness=2)
-
- cv.imshow('img', img)
- cv.waitKey()
总结:
(1)fast rcnn中提取roi区域使用的ss方法,而该方法想对还是比较耗时,faster rcnn中提出了RPN,同时还提出anchor机制,通过RPN实现了对于roi区域的提取。使得整个流程一体化,完全的端到端的训练。
最终收益:
| RCNN | fast RCNN | faster RCNN | |
| 每张图测试时间 | 50秒 | 2秒 | 0.2秒 |
| 加速比 | 1X | 25X | 250X |
| voc2007 map | 66.0 | 66.9 | 66.9 |
RCNN---->fast RCNN---->faster RCNN
| 操作步骤 | RCNN | fast RCNN | faster RCNN |
| ROI提取 | selective search | selective search | RPN |
| 特征提取 | CNN | roi pooling+CNN | roi pooling+CNN |
| 分类+回归 | SVM | softmax+smooth L1 | softmax+smooth L1 |
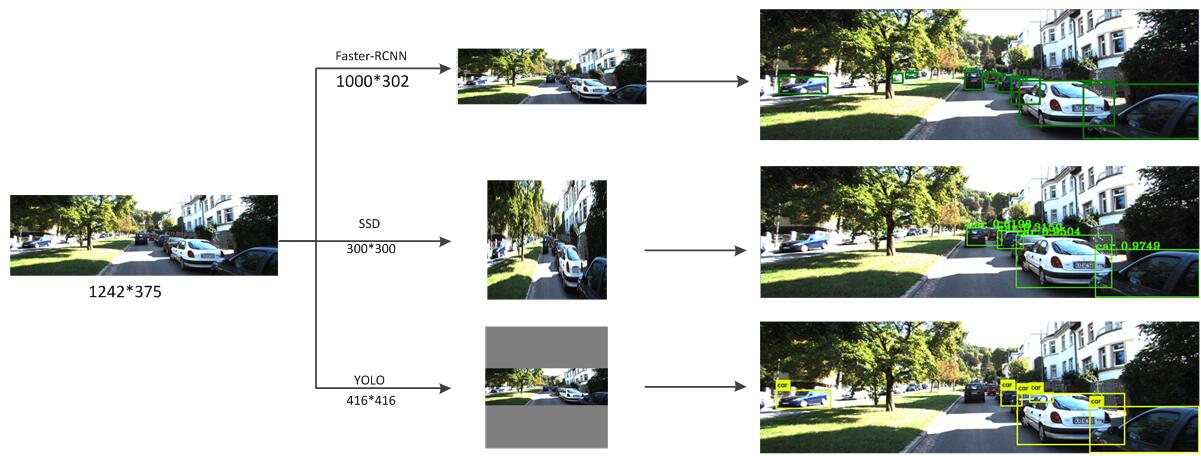
这里分析一下,目标检测的框架为什么faster-RCNN要比SSD对小目标更好,而RFCN又比faster-RCNN更好些呢?
首先看一下,几个框架读取图片传进网络前做的处理,
faster-RCNN的处理:
faster-RCNN对读取的图片进行了scale处理,首先假设,im_size原始图片大小,target_size为目标图片大小,max_size为目标图片最长边允许的最大长度。
那么在缩放的过程中,首先,定义scale大小为( target_size ) / im_size_min,如果这个scale的时候,长边的长度超过max_size,就将scale定义为( target_size) / im_size_min,否则就还是用原来的scale。这样做的好处就是输入的图片相对SSD300*300,SSD500*500都大点,最终对小目标也许效果就会更好,当然这样做的话也会使得运行速度变慢,显存使用增加,对于不同ratio(长宽比)的图片运行时间也有差别。使用作者的原始参数,target_size=600 ,max_size=1000也许是对精度,速度,显存占用的一个很好的折中吧。
这里为什么faster-RCNN可以输入Blob不同ratio的数据,这就是RPN网络的亮点,全卷基层的设计,当然不受ratio的影响。
function im_scale = prep_im_for_blob_size ( im_size ,target_size ,max_size )
im_size_min = min(im_size ( 1 : 2 ) ) ;
im_size_max = max(im_size ( 1 : 2 ) ) ;
im_scale = double ( target_size ) / im_size_min ;
%Prevent the biggest axis from being more than MAX_SIZE
if round (im_scale ∗ im_size_max ) > max size
im_scale = double (max_size ) / double (im_size_max) ;
end
end
SSD的处理:
直接进行缩放处理,这样做虽然会使图像变形,但是保证了输入的整个图像都是有效的像素。
cv::Mat sample_resized;
if (sample.size() != input_geometry_)
cv::resize(sample, sample_resized, input_geometry_);
else
sample_resized = sample;
YOLOV2的处理:
YOLO的处理也保证了图片的ratio,比如tiny-yolo的输入尺寸为416*416,在对图片进行保证ratio的缩放后,对其他区域进行127像素的填充,这样做的好处就是保证了ratio,不足之处就是当输入图片的ratio比较大的时候,就会填充好多无效的127像素,一个图中,无效区域比有效区域还大,当然对小目标的检测就还不如SSD奏效了。
static image_t ipl_to_image(IplImage* src)
{
unsigned char *data = (unsigned char *)src->imageData;
int h = src->height;
int w = src->width;
int c = src->nChannels;
int step = src->widthStep;
image_t out = make_image_custom(w, h, c);
int i, j, k, count = 0;;
for (k = 0; k < c; ++k) {
for (i = 0; i < h; ++i) {
for (j = 0; j < w; ++j) {
out.data[count++] = data[i*step + j*c + k] / 255.;
}
}
}
return out;
}
static void rgbgr_image(image_t im)
{
int i;
for (i = 0; i < im.w*im.h; ++i) {
float swap = im.data[i];
im.data[i] = im.data[i + im.w*im.h * 2];
im.data[i + im.w*im.h * 2] = swap;
}
}
RFCN的处理:
RFCN的处理主要是在网络卷积参数的设计上,引入了dilation参数,也就是所谓的hole algorithms,可以有效的增大map,提高对小目标的检测。
如下图所示,假设第一个为原始的map(3*3),第二个为dilation: 2时得到的map(7*7),第三个为在第二个的基础上,dilation: 4得到的map(15*15)。

layer {
bottom: "res5a_branch2a"
top: "res5a_branch2b"
name: "res5a_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
dilation: 2
pad: 2
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
这里用KITTI的一张图片进行测试说明,
The End!

