
- 1jenkins 自动化部署的实现(10)_remotedirectorysdf 什么意思
- 2sqlmap——json注入_sqlmap json注入
- 3Android—Jetpack教程(一)_android jetpack
- 4Fiddler抓不到包该怎么解决_fiddler抓不了包怎么办
- 5【LabVIEW FPGA入门】FPGA中的数据流
- 6Vue系列之—Vuex详解
- 7Linux “wget”命令详解_linux wget
- 8Java线上问题排查系列--系统问题排查的方法/步骤_java线上问题排查–系统问题排查的方法/步骤
- 9快应用开发商城app的实践分享 - 调试
- 10机器学习是如何利用线性代数来解决数据问题的_线性代数在机器人中的应用
20240126请问在ubuntu20.04.6下让GTX1080显卡让whisper工作在large模式下?_whisper 使用large模型很慢
赞
踩
20240126请问在ubuntu20.04.6下让GTX1080显卡让whisper工作在large模式下?
2024/1/26 21:19
问GTX1080模式使用large该如何配置呢?
这个问题没有完成,可能需要使用使用显存更大的显卡了!
比如GTX1080Ti 11GB,更猛的可以选择:RTX2080TI 22GB了!
以下四种large模式都异常了!
large
large-v1
large-v2
large-v3


rootroot@rootroot-X99-Turbo:~$
rootroot@rootroot-X99-Turbo:~$ watch -n 2 nvidia-smi
rootroot@rootroot-X99-Turbo:~$ whereis whisper
whisper: /home/rootroot/.local/bin/whisper
rootroot@rootroot-X99-Turbo:~$
root@rootroot-X99-Turbo:/#
root@rootroot-X99-Turbo:/# find . -name whisper
./usr/lib/x86_64-linux-gnu/espeak-ng-data/voices/!v/whisper
./home/rootroot/.cache/whisper
./home/rootroot/.local/bin/whisper
./home/rootroot/.local/lib/python3.8/site-packages/whisper
./home/rootroot/3TB/76Android11.0/out3/.path/whisper
./home/rootroot/3TB/76Android11.0/out/.path/whisper
find: ‘./run/user/1000/gvfs’: Permission denied
root@rootroot-X99-Turbo:/#
root@rootroot-X99-Turbo:/# whereis whisper
whisper:
root@rootroot-X99-Turbo:/#
root@rootroot-X99-Turbo:/#
https://www.bilibili.com/read/cv29388784/?jump_opus=1
【教程】利用whisper模型自动生成英文粗字幕
运行环境
硬件
NVIDIA GeForce 3090 GPU with 24GB VRAM
该模型理论上也能在CPU环境下运行,但极慢。GPU运行也需要占用较大显存。官方提供了多种规模的变体,所需显存从1GB-10GB不等(如下图)
软件
Ubuntu 18.04
理论上来说Windows和MacOS也是支持的,不过我没有尝试过
PyTorch 1.11.1
官方说的是在1.10.1上训练的,不过这个影响不大
操作步骤
克隆项目仓库 git clone https://github.com/openai/whisper.git
从源码安装Python包 pip install .
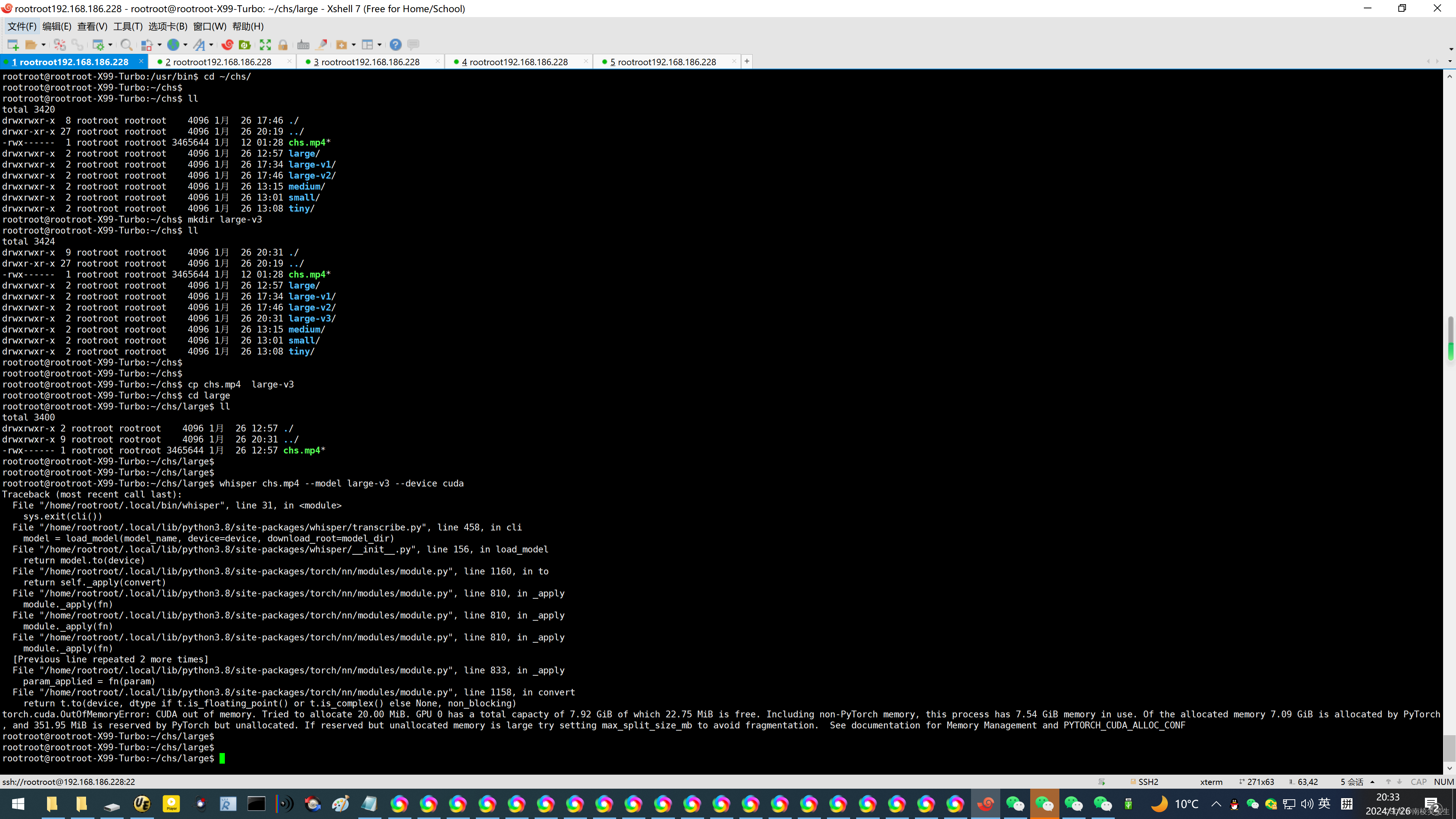
命令行使用 whisper audio.aac --model large-v3 --device cuda
whisper chs.mp4 --model large-v3 --device cuda
rootroot@rootroot-X99-Turbo:~/chs/large$ whisper chs.mp4 --model large-v3 --device cuda
Traceback (most recent call last):
File "/home/rootroot/.local/bin/whisper", line 31, in <module>
sys.exit(cli())
File "/home/rootroot/.local/lib/python3.8/site-packages/whisper/transcribe.py", line 458, in cli
model = load_model(model_name, device=device, download_root=model_dir)
File "/home/rootroot/.local/lib/python3.8/site-packages/whisper/__init__.py", line 156, in load_model
return model.to(device)
File "/home/rootroot/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1160, in to
return self._apply(convert)
File "/home/rootroot/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 810, in _apply
module._apply(fn)
File "/home/rootroot/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 810, in _apply
module._apply(fn)
File "/home/rootroot/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 810, in _apply
module._apply(fn)
[Previous line repeated 2 more times]
File "/home/rootroot/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 833, in _apply
param_applied = fn(param)
File "/home/rootroot/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1158, in convert
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacty of 7.92 GiB of which 22.75 MiB is free. Including non-PyTorch memory, this process has 7.54 GiB memory in use. Of the allocated memory 7.09 GiB is allocated by PyTorch, and 351.95 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
rootroot@rootroot-X99-Turbo:~/chs/large$
rootroot@rootroot-X99-Turbo:~/chs/large$
https://www.bilibili.com/read/cv27732514/
OpenAI 发布新版开源语音识别模型 whisper-large-v3
https://zhuanlan.zhihu.com/p/618140077
ChatGPT开源的whisper音频生成字幕,可本地搭建环境运行,效果质量很棒
Model = 'large-v2' #@param ['tiny.en', 'tiny', 'base.en', 'base', 'small.en', 'small', 'medium.en', 'medium', 'large', 'large-v2']
https://blog.csdn.net/lusing/article/details/132032965
2023年的深度学习入门指南(24) - 处理音频的大模型 OpenAI Whisper
我们还可以用model参数来选择模型,比如有10GB以上显存就可以选择使用large模型:
whisper va2.mp3 --model large --language Chinese
默认是small模型。还可以选择tiny, base, medium, large-v1和large-v2.
百度:UBUNTU 显存占用
https://www.bmabk.com/index.php/post/162904.html
Ubuntu显卡占用情况实时监控
每隔2s刷新一次内存使用情况
watch -n 2 free -m
watch -n 1 free -m
watch -n 0.5 free -m
https://blog.csdn.net/weixin_44554475/article/details/102909308
ubuntu实时显示网速cpu占用和内存占用率
1、ubuntu实时显示网速cpu占用率和内存占用率参考博客:
https://www.cnblogs.com/hjw1/p/7901048.html
2、ubuntu实时显示显存使用率:
此处的2表示没2秒显示一次显存情况
watch -n 2 nvidia-smi
3、安装htop查看内存情况:
安装:sudo apt-get install htop
启动: htop
4 ubuntu config clash for windows
https://hiif.ong/clash
https://blog.csdn.net/N1CROWN/article/details/122662706?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-122662706-blog-102909308.235^v43^pc_blog_bottom_relevance_base1&spm=1001.2101.3001.4242.1&utm_relevant_index=3
Ubuntu16.04 标题栏显示实时网速、CPU使用率
sudo apt-get install python3-psutil curl git gir1.2-appindicator3-0.1
cd indicator-sysmonitor
sudo make install
nohup indicator-sysmonitor &
https://www.toutiao.com/article/7315080543987597864/?app=news_article×tamp=1706252345&use_new_style=1&req_id=2024012614590561ABBE53940F817BA3B3&group_id=7315080543987597864&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=toutiao_android&utm_campaign=client_share&share_token=e7d4aa95-92fe-45b6-9dc3-6570888672ab&source=m_redirect
Distil Whisper开源,语音识别比Whisper更快更小更准
https://blog.csdn.net/zcxey2911/article/details/134202112?spm=1001.2101.3001.4242.3&utm_medium=distribute.wap_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-4-134202112-blog-130588477.237%5Ev3%5Ewap_relevant_t0_download&share_token=70d15c8b-cc0b-4ca6-8e5b-31a19ce3c062
持续进化,快速转录,Faster-Whisper对视频进行双语字幕转录实践(Python3.10)
https://blog.csdn.net/qq_48424581/article/details/134113540?share_token=53aba00d-104f-4b3b-be19-4da75f7897d7
3.6 模型的选择,参考如下
_MODELS = {
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
"large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt",
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
"large": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
}
https://www.bilibili.com/read/cv20881630/
免费离线语音识别神器whisper安装教程
补充说明:上图中CUDA 11.6和CUDA 11.7都是gpu版本的软件,我一开始下载的也是gpu版本的,但是因为我的电脑显卡的显存比较低,运行whisper模型的时候大模型运行不了。下图是whisper官方给出的运行模型所需显存。
我的显存是4GB,一旦使用whisper运行small模式以上的模型就会报显存不足的错误。为了能运行更大的模型以保证语音识别较高的准确率,我最终只能选择安装cpu版本。 作者:1590856 https://www.bilibili.com/read/cv20881630/ 出处:bilibili
当然还有其他的模型可供选择,可以在命令行运行whisper --help查看帮助。有以下11种模式可供选择。
[--model {tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large-v1,large-v2,large}] 作者:1590856 https://www.bilibili.com/read/cv20881630/ 出处:bilibili
https://blog.csdn.net/nikolay/article/details/128951413?share_token=92623f2c-9ed4-483e-9c79-8fcf83f08221
使用openai-whisper 语音转文字
使用CUDA
执行如下指令,安装带cuda 的pytorch
pip uninstall torch
pip cache purge
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
--device cuda 使用device参数 指定 cuda
whisper 屋顶.mp3 --language zh --model small --device cuda --initial_prompt "以下是普通话的句子。"

