
- 1vue-element-admin项目_vue-elemnt-admin 项目
- 2haproxy 高可用
- 3Opencv+C++之人脸识别_opencv和c++分辨人脸
- 4【PaddleNLP 基于深度学习的自然语言处理】第三次作业--必修|快递单信息识别_train_ds, test_ds = load_dataset('msra_ner', split
- 5Android UI框架 Android UI控件类简介 android5大布局详解
- 6vite插件开发系列1-写一个vite插件自动保存所有成功的ajax请求结果为js文件(供mock)_vite写一个请求
- 7掌握大模型这些优化技术,优雅地进行大模型的训练和推理!_大模型训练与优化
- 8直接快速下载NLTK数据_nltk下载清华镜像
- 9SpringBoot Actuator和Spring boot Admin工具_spring-boot-admin 和actuator
- 10错误处理:IndexError: index out of range in self
大模型上下文学习(ICL)训练和推理两个阶段31篇论文_上下文学习icl推理耗时
赞
踩
大模型都火了这么久了,想必大家对LLM的上下文学习(In-Context Learning)能力都不陌生吧?
以防有的同学不太了解,今天我就来简单讲讲。
上下文学习(ICL)是一种依赖于大型语言模型的学习任务方式,近年来随着大模型能力的提高,它也成为了NLP的一种新范式。ICL无需对模型权重做任何改动,只需要给预训练模型展示一些输入-输出示例,就能解决对应场景下的新问题。
为了更高效地提示大模型,最近很多业内人士都在研究大模型的上下文学习能力,并且也有了不少值得关注的成果。这次我就整理了其中一部分来和大家分享,共31篇,主要分为2大类,包含训练和推理两个阶段。
篇幅原因,解析就不多写了,需要的同学看文末
训练
1.MetaICL: Learning to Learn In Context
学会在上下文中学习
简述:论文介绍了一种新的元训练框架,叫做MetaICL,用于少样本学习。这种框架通过调整预训练的语言模型进行上下文学习。实验证明,MetaICL优于其他基线模型,尤其对于有领域转移的任务。使用多样化的元训练任务能进一步提高性能。

2.OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
通过泛化的视角扩展语言模型指令元学习
简述:指令微调可以改善预训练语言模型对新任务的泛化能力。论文研究了微调过程中的决策对性能的影响,并创建了一个包含2000个任务的基准来评估模型。研究发现,微调决策如基准规模、任务采样、使用演示等都会影响性能。作者训练了两个版本的OPT-IML,它们在四个基准上都优于其他模型。

3.Finetuned Language Models are Zero-Shot Learners
微调语言模型是零样本学习器
简述:这篇文章探索了指令微调提高语言模型零样本学习能力的方法。作者发现,通过在指令描述的数据集上微调模型,可以显著提高对未见任务的性能。作者使用137B参数模型进行指令微调,并评估FLAN在未见任务上的表现,发现它优于零样本175B GPT-3。消融实验表明,指令微调的成功取决于微调数据集数量、模型规模和自然语言指令。

4.Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks
通过1600多个NLP任务的声明性指令实现泛化
简述:作者创建了一个包含1616个任务和专家说明的基准测试,涵盖了76种不同的任务类型,并训练了一个transformer模型Tk-Instruct,该模型可以遵循各种上下文指令。尽管它小一个数量级,但作者发现它在基准测试中比现有的模型表现更好。作者进一步分析了泛化性能如何受到观察任务的数量、每个任务的实例数量和模型大小等因素的影响。

5.Scaling Instruction-Finetuned Language Models
扩展指令微调语言模型的规模
简述:论文探索了在不同任务数量、模型大小和提示设置下进行指令微调的效果。例如,在1.8K个任务上微调Flan-PaLM 540B模型后,性能得到了显著提升,并在多个基准测试中达到了最佳性能。作者还公开了Flan-T5检查点,这些检查点在少样本性能方面表现强劲。

6.Symbol tuning improves in-context learning in language models
符号微调提高了语言模型中的上下文学习效果
简述:论文提出了一种名为“符号微调”的新方法,它使用任意符号替换自然语言标签来微调语言模型。这种方法有助于模型更好地处理未见过且缺乏明确指令的任务,并提高其在算法推理任务上的表现。作者在大型Flan-PaLM模型上进行了实验,发现符号微调可以提高模型对上下文信息的利用能力。

7.Improving In-Context Few-Shot Learning via Self-Supervised Training
通过自我监督训练提高上下文少样本学习效果
简述:这篇论文提出了在预训练和下游少样本学习之间使用自监督学习的中间训练阶段,旨在教会模型进行上下文少样本学习。作者在两个基准测试中提出并评估了四种自监督目标,发现中间的自监督学习阶段产生的模型优于强大的基线。消融研究显示,几个因素影响下游表现,如训练数据量和自监督目标的多样性。人类注释的跨任务监督和自监督是互补的。

8.Pre-training to learn in context
通过预训练来学习上下文
简述:PICL是一种预训练语言模型的方法,旨在提高模型在上下文中的学习能力。通过在大量内在任务上使用简单的语言建模目标进行预训练,PICL鼓励模型根据上下文进行推断和执行任务,同时保持预训练模型的任务泛化能力。实验表明,PICL在各种NLP任务中表现优于其他基线方法,尤其在Super-NaturalInstrctions基准测试中,它优于更大的语言模型。

推理
1.What Makes Good In-Context Examples for GPT-3?
什么让GPT-3具有良好的上下文示例?
简述:GPT-3是一种强大的语言模型,适用于多种NLP任务,包括上下文学习。然而,如何选择上下文示例对于GPT-3的性能至关重要。作者发现,通过检索与测试查询样本语义相似的示例,可以更好地利用GPT-3的上下文学习能力。这种方法在多个基准测试中优于随机选择基线,并且在表格到文本生成和开放领域问答等任务中取得了显著成果。

2.Learning To Retrieve Prompts for In-Context Learning
学习检索上下文学习的提示
简述:上下文学习是一种自然语言理解的新方法,大型预训练语言模型观察测试实例和训练示例作为输入,直接解码输出而不更新参数。这种方法的效果取决于所选择的训练示例(提示)。本文提出了一种新方法,使用带标注的数据和LM来检索提示。给定输入-输出对,估计给定输入和候选训练示例作为提示时输出的概率,并根据该概率标记训练示例。然后训练一个高效的密集检索器,用于测试时检索训练示例作为提示。

3.Demystifying Prompts in Language Models via Perplexity Estimation
基于困惑度估计的语言模型提示解谜
简述:语言模型可以接受各种零样本和少样本学习任务的提示,但性能会因提示而异,我们还不明白原因或如何选择最佳提示。本文分析性能变化的因素,发现模型对提示语言的熟悉程度影响其性能。作者设计了一种新方法来创建提示:首先,使用GPT3和回译自动扩展手动创建的小提示集;然后,选择困惑度最低的提示可显著提高性能。
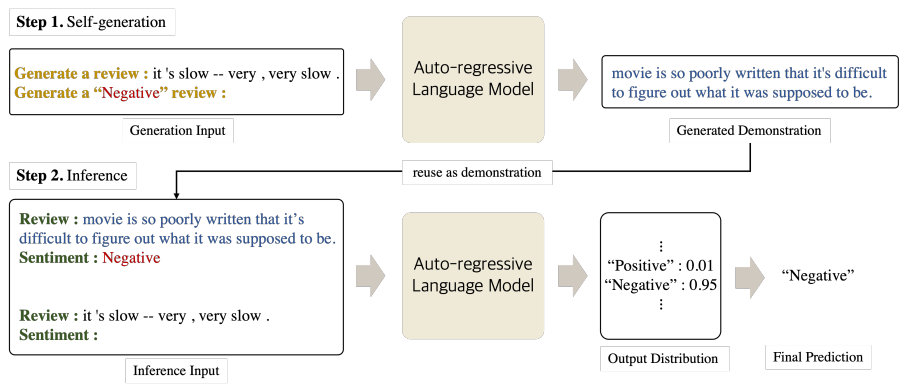
4.Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator
利用自回归语言模型作为演示生成器
简述:本文提出了一种新的方法,即自生成上下文学习(SG-ICL),用于减少大规模预训练语言模型(PLM)对外部演示的依赖。SG-ICL从PLM本身生成演示,以进行上下文学习。作者在四个文本分类任务上进行了实验,并发现SG-ICL的表现优于零样本学习,大致相当于0.6个黄金训练样本。与从训练集中随机选择的演示相比,该生成的演示表现更一致,方差更低。
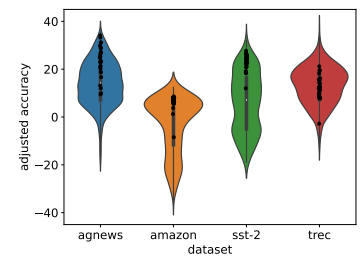
5.An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
无需真实标签的提示工程的信息论方法
简述:现有的提示工程方法需要大量标记数据和访问模型参数。论文介绍了一种新方法,无需标记示例或直接访问模型。作者选择最大化输入和模型输出之间互信息的模板。在8个数据集中,作者发现高互信息的模板任务准确度也高。在最大模型上,使用该方法可使准确度达到最佳的90%,无需真实标签。

6.Active Example Selection for In-Context Learning
上下文学习中的主动范例选择
简述:大型语言模型能够从少量示例中学习执行各种任务,无需微调。但是,上下文学习的性能在示例之间不稳定。论文提出了一种强化学习算法来选择示例,以实现更好的泛化性能。这种方法在GPT-2上表现良好,平均提高了5.8%的性能。尽管在更大的GPT-3模型上改进效果较小,但该方法仍然表明了大型语言模型的能力不断增强。
-
7.Finding supporting examples for in-context learning
-
8.Large language models are implicitly topic models: Explaining and finding good demonstrations for in-context learning
-
9.Unified Demonstration Retriever for In-Context Learning
-
10.Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
-
11.Instruction Induction: From Few Examples to Natural Language Task Descriptions
-
12.Large Language Models Are Human-Level Prompt Engineers
-
13.Self-Instruct: Aligning Language Models with Self-Generated Instructions
-
14.Complexity-based prompting for multi-step reasoning
-
15.Automatic Chain of Thought Prompting in Large Language Models
-
16.Measuring and Narrowing the Compositionality Gap in Language Models
-
17.Small models are valuable plug-ins for large language models
-
18.Iteratively prompt pre-trained language models for chain of thought
-
19.Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
-
20.Noisy Channel Language Model Prompting for Few-Shot Text Classification
-
21.Structured Prompting: Scaling In-Context Learning to 1,000 Examples
-
22.k nn prompting: Learning beyond the context with nearest neighbor inference
-
23.MoT: Memory-of-Thought Enables ChatGPT to Self-Improve
关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

