
- 1leetcode笔记|面试经典150_力扣面试经典150题
- 2如何防止IP泄露,安全匿名上网?
- 3网络安全-BurpSuite安装和使用方法_burpsuite下载安装
- 4使用 Azure OpenAI 打造自己的 ChatGPT_azurechatopenai
- 5计算机专业到底该不该考研?_计算机专业有必要考研
- 6机器人SLAM路径规划总结(1)_slam路径规划算法
- 7大模型微调:推动NLP领域发展的强大引擎_nlp大模型精调与优化
- 8苹果云服务器里的家人共享位置,iPhone手机“家人共享”是什么?苹果手机怎么使用“家人共享”?...
- 9(java毕业设计源码)基于java(springboot)校园求职招聘系统
- 102023年最新PyCharm安装详细教程及pycharm配置ji活_localized pycharm is available switch and restart
python 带属性的tuple_Python入门必看(基础知识总结)
赞
踩

Python基础知识总结
- 基础中的基础
- 列表、元组(tuple)、字典、字符串
- 变量和引用
- 函数
- 面向对象(封装、继承、多态)
- 异常
- 模块、包
- 文件
基础中的基础
- 解释型语言和编译型语言差距;
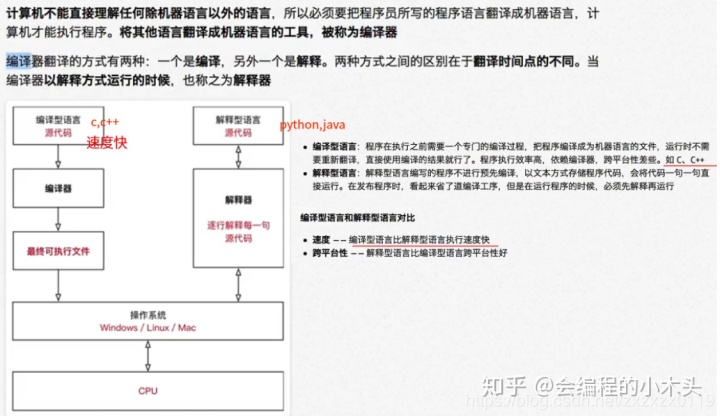
Python概述

解释器执行原理
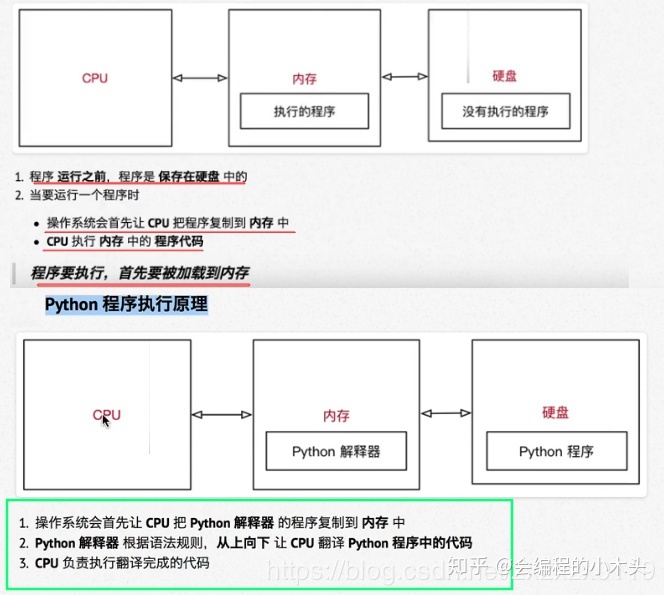
which python3可以查看python3的位置(linux下);
交互式环境中使用exit()或者ctrl+D退出;
9 // 2表示取结果的整数,乘方使用**;
乘法可以用在 字符串中 也就是说 "_ " * 5 会输出5个 “_”;
数据类型分为 数字型和非数字型: (1)数字型 : 整形、浮点型、布尔型、复数型。(2)非数字型: 字符串、列表、元组、字典。type(变量名)查看变量类型;
python3中没有long,只有int;
变量的输入: input()函数。注意: input()函数输入的数据类型都是字符串类型;
在python中,如果变量名需要两个或多个单词组成时,可以按照下面的方式: ①每个单词都是小写;②单词和单词之间使用_下划线连接;③使用驼峰规则;
print函数如果不想输出换行,在后面加上一个end=""(例如print(“a”,end=""));单纯的只想输出一个换行可以使用print()或者print("");
t(制表符(对齐))和n转义字符;
关于函数的注释,写在函数的下面,加上三个"""。以及文档注释,例如:

因为函数体相对比较独立,函数定义的上方,应该和其他代码(包括注释)保留两个空行;
import导入的文件可以python解释器将模块解释成一个pyc二进制文件(类似Java的.class?);
python中关键字后面不需要加括号(如del 关键字);
方法和函数的异同: ①方法和函数类似,同样是封装了独立的功能;②方法需要通过对象来调用,表示针对这个对象要做的操作③函数需要记住,但是方法是对象的"函数",方法不需要记住(IDE提示或者IPython中TAB补全);
变量赋值的几种特殊的方式:

逻辑运算符:and、or、not,成员运算符in、not in,身份运算符is、is not;
列表、元组(tuple)、字典、集合、字符串
- 列表可以嵌套;

元组不同于列表的是: 元组不能修改,用()表示;(不能增删改)
元组一般保存不同类型的数据;
注意: 只有一个元素的元组: single_tuple = (5,) ,也就是说元组中只包含一个元素时,需要在元素后面添加逗号;不能这样写 single_tuple = (5),这样是一个整形的变量;另外,创建元组也可以不加上括号;

输出:

- 元组的用途: ① 作为函数的参数和返回值;②格式化字符串(格式字符串本身就是一个元组);(3)让列表不可以被修改,保护数据安全;
- 格式化字符串和元组的关系,看下面的三个print输出是一样的:

元组和列表可以相互转换 : ①使用list(元组)将元组转换成列表;②使用tuple将列表转换成元组;
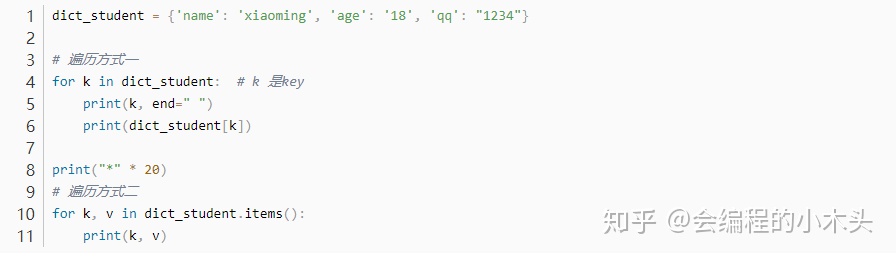
字典: ① 键必须是唯一的 ②值可以取任意类型,但是键只能使用字符串、数字或者元组(键只能是不可变类型)。
**遍历字典的时候for k in dict 中的k是键,而不是值。(普通的for),不过也可以通过items()方法遍历键值对: **
字符串中的转义字符:n表示换行,而r表示回车,字符串中的函数isspace()判断的时候tnr都是表示的空白字符;
isdecimla()、isdigit()、isnumeric()都不能判断字符串中的小数,(可以判断字符串中的整数);
集合set的使用: 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。 集合还有一些方法add()、update()、pop()等;
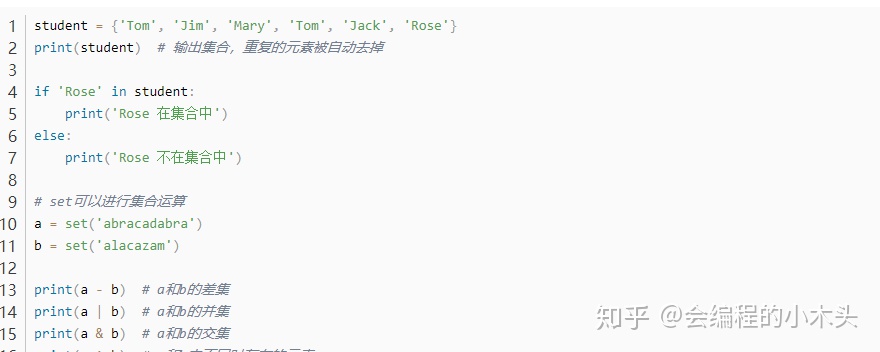
输出:

相关公共方法: len、del、max、min(只会比较字典的key);
in、not in的使用(类似数据库…);
pass关键字的使用: 比如if … 下面没有写语句,python会提示报错,但是你可以写一个pass就不会报错了;也就是说如果在开发程序时,不希望立即编写分支内部的代码,可以使用pass作为一个占位符;可以保证程序代码结构正确;
TODO关键字的使用,在编写程序框架的时候,可以用TODO标示某个地方还没有做某事;
迭代器的使用

输出:

字符串中切片的使用: ①类似截取,但是可以指定步长;②python中支持倒序索引,最后一个是-1,倒数第二个是-2…;


输出:

变量和引用
变量和数据都是保存在内存中的;
在python中函数的参数传递以及返回值都是引用传递的;
变量和数据是分开存储的;
变量中记录数据的地址,就叫做引用;
使用id()函数可以查看变量中保存的数据所在的内存地址;
注意: 如果变量已经被定义,当给一个变量复制的时候,本质上是修改了数据的引用。① 变量不再对之前的数据引用;②变量改为对新复制的数据引用;
可变类型和不可变类型
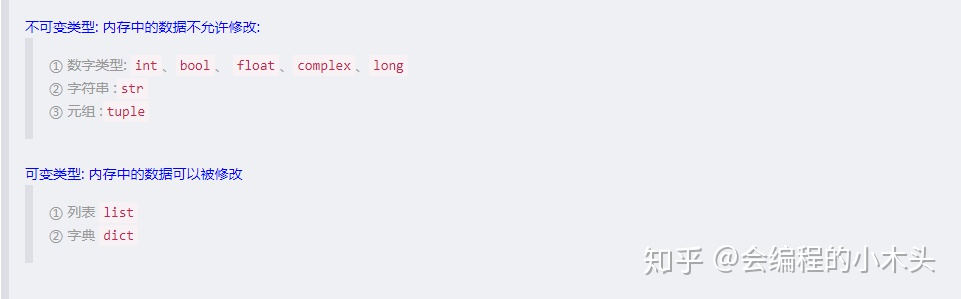
1.可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a;
2.不可变类型: 变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
函数参数传递时注意:
1.不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
2.可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响;
局部变量和全局变量
局部变量:函数内部定义的变量,只能在函数内部使用;全局变量: 函数外部定义的变量,所有函数内部都可以使用这个变量;(不推荐使用)
注意: 在python中,不允许修改全局变量的值,如果修改,会在函数中定义一个局部变量

- 可以使用global关键字修改全局变量的值。
- 全局变量的命名规则: 前面加上
g_或者gl_;
函数
- 函数如果返回的是一个元组就可以省略括号;
- 如果返回的是一个元组,可以使用多个变量直接接收函数的返回结果;(注意变量的个数和返回的元组的个数相同)
例如:

交换两个变量a、b的值的三种解法(第三种python专用)

- 如果在函数中使用赋值语句,并不会影响调用函数时传递的实参变量;无论传递的参数可变还是不可变;
- 只要针对参数使用赋值语句,会在函数内部修改局部变量的引用,不会影响到外部变量的引用;
测试:
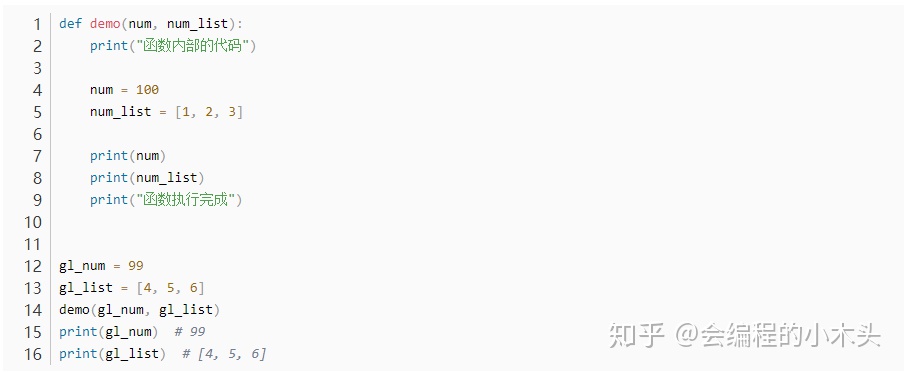
输出:

一张图解释:

如果传递的参数是可变类型,在函数内部,使用方法修改了数据的内容,同样会影响到外部的数据。

示意图:

上面写了,这里再重复一遍可变类型和不可变类型和参数传递的关系:
1.不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
2.可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响;
列表变量调用 += 的时候相当于是调用extend,这个是一个特列;

输出:

缺省参数: ①定义函数时,可以给某个参数指定一个默认值,指定了默认值的参数叫做缺省参数;②一般使用最常见的值作为缺省参数;③缺省参数的定义位置:必须保证带有默认值的缺省参数定义在参数列表的末尾;

还要注意,如果后面有多个参数,且只给具体的某一个指定默认值,就要具体的指定参数的名字:

输出:

这个原理类似降序排序:

多值参数

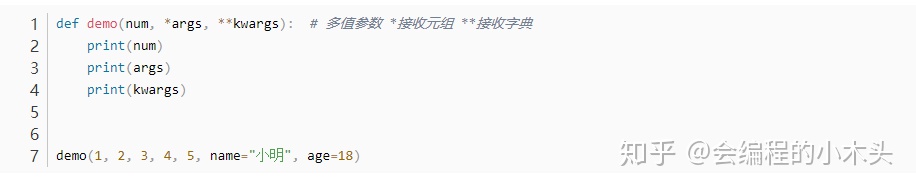
输出:

使用多值参数的好处,例如下面的例子计算求和,如果不使用* args 也就是不使用多值的元组的时候,我们传递参数的时候就需要传递一个元组,但是这样的话就直接传递一串数字就好了。

多值参数元组和字典的拆包

首先看下面代码的输出,这个代码是出乎意料的:

输出:

加上拆包:

输出:

面向对象(封装、继承、多态)
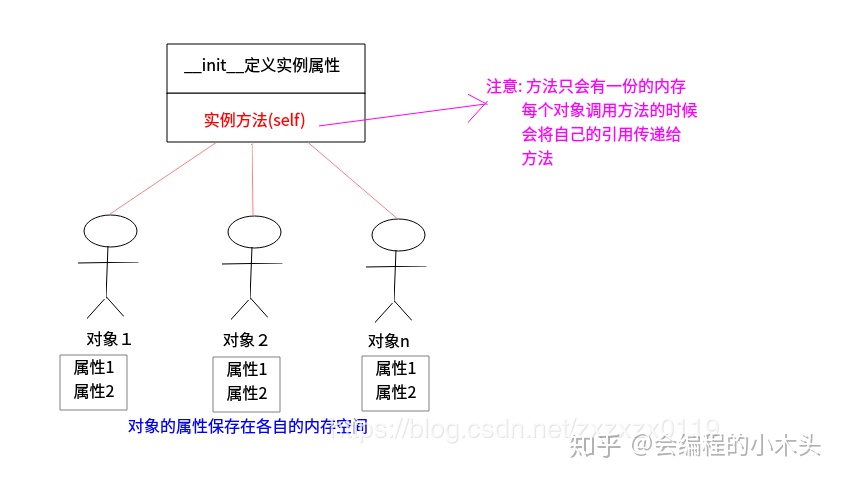
- 类中: ①特征被称为属性;②行为被称为方法;③三要素:类名、属性、方法;
- dir函数可以查看对象的所有方法;
- dir显示的方法中,
__方法名__格式的方法是Python提供的内置方法/属性;

- 类中的方法第一个参数必须是
self(类似Java中的this?);
创建第一个类:

输出:

引用的强调

- Python如果不想修改类,可以直接给对象增加属性(不同于其他语言!)(这种方式不推荐);
- self关键字(Java中的this关键字): 哪一个对象调用的这个方法,self就是哪个对象的引用,可以通过self.访问对象的属性和方法;
- 初始化方法
__init__:

在初始化方法__init__内部定义属性:

使用:

输出:

初始化方法__init__中带参数,构造对象;

__del__方法的调用


输出: (注意: 如果不注释 # del tom,__del__方法的调用就在输出横线的上方)

__str__方法(类似Java中的toString())
在python中,使用print输出对象变量,默认情况下输出这个变量 引用的对象是由哪一个类创建的对象,以及在内存中的地址(16进制表示) ;
如果在开发中,希望使用print输出对象变量时,能够打印自定义内容,就可以利用__str__方法;
注意:__str__方法必须返回一个字符串;

输出:

面向对象案例一 : 房子和家具


输出:

面向对象案例二 : 枪和士兵
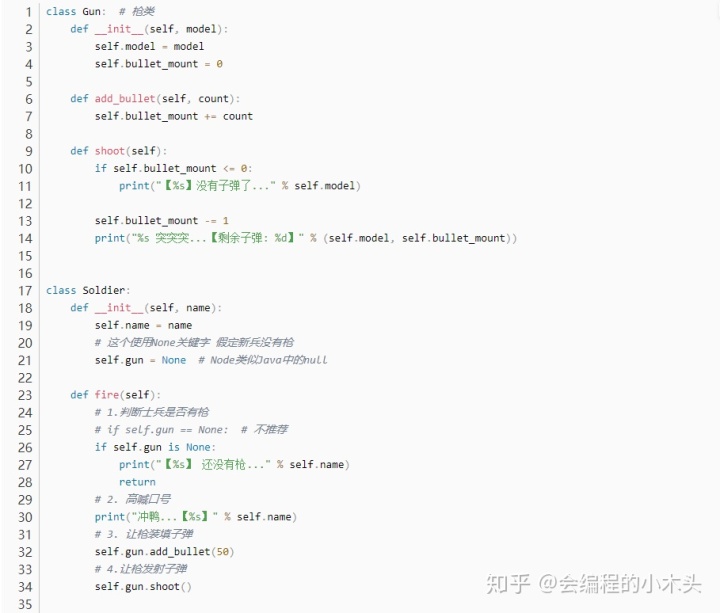

身份运算符(== 类似Java中的equals,而 is(身份运算符) 却类似 java中的 ==);


- 私有属性和私有方法: 只需要在属性名或者方法名前面加上两个下划线(真的6…),私有属性只能在类的内部使用;
- 但是
Python中没有真正意义的私有,这个私有只是伪私有。可以使用_类名__属性或者_类名__方法强制访问私有属性或方法;

输出:

关于继承中的重写,和Java中差不多,直接覆盖即可;
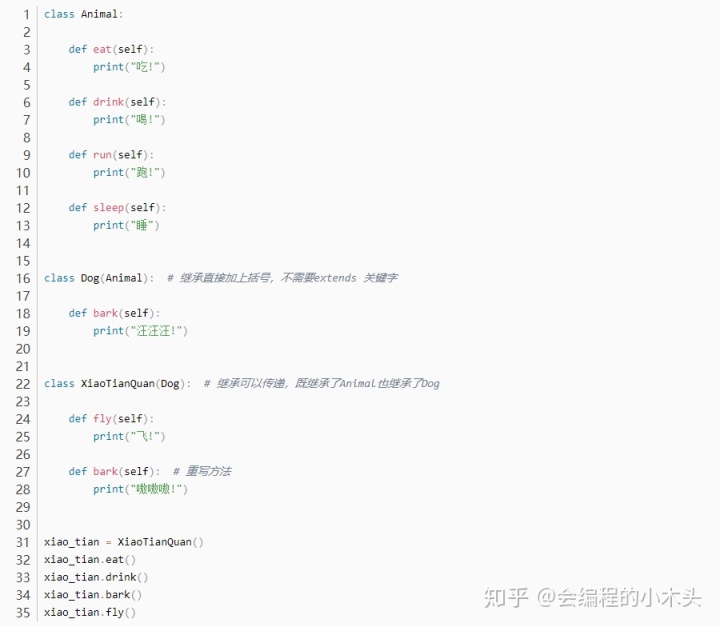
扩展相关方法中使用super()关键字,和Java也差不多;
注意子类不能访问父类的私有属性

但是子类可以通过公有方法间接的来访问父类的私有属性;

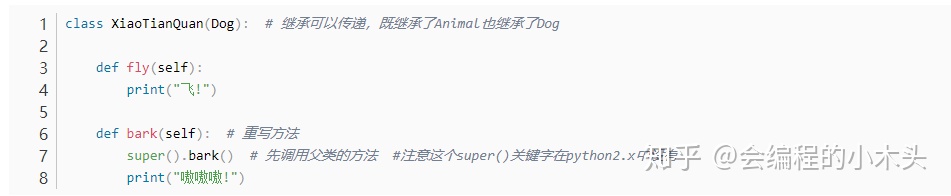
多继承(Java中使用的是接口)
注意,使用多继承的时候,如果两个父类中有相同的方法,尽量避免使用多继承, 避免产生混淆。可以使用__mro__(方法搜索顺序)用于在多继承时,判断方法、属性的调用路径;

输出:

新式类(python3)与旧式类(python2)

- 多态
案例: 人和普通狗和哮天犬玩耍
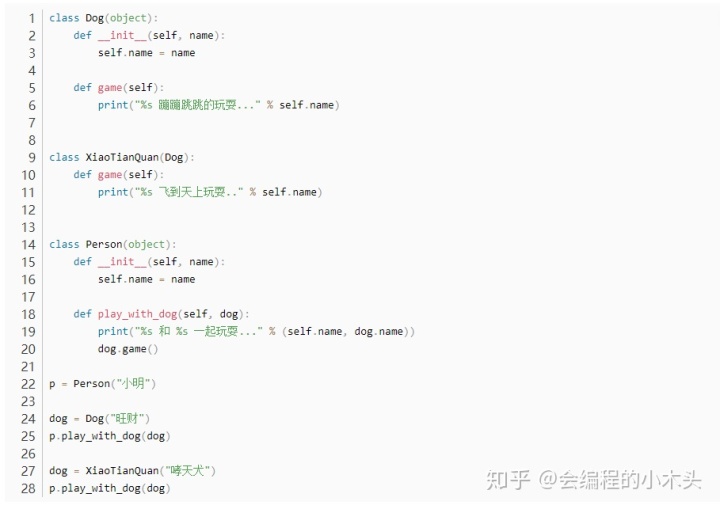
输出:

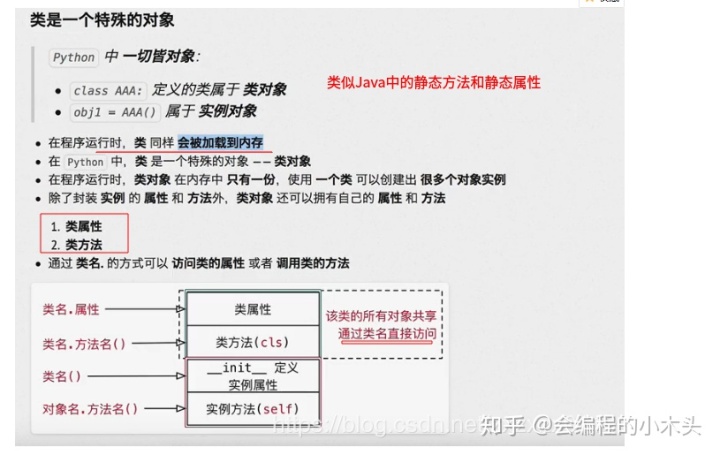
类的结构

类也是一个特殊的对象
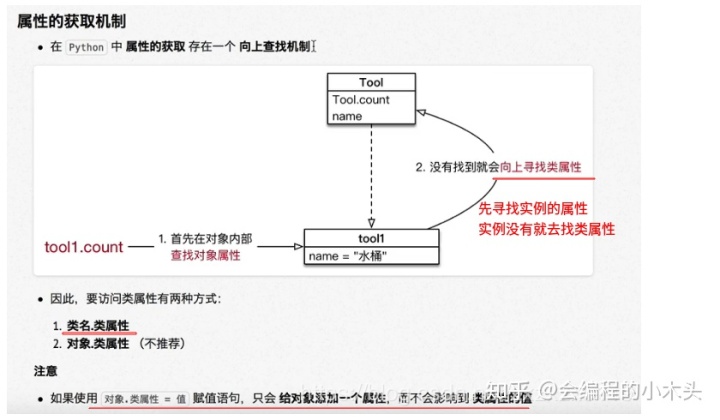
属性的获取机制

定义类属性和类方法

代码:

静态方法

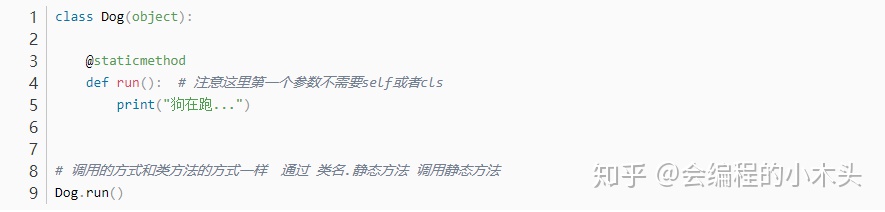
三种方法(静态方法、类方法、实例方法)的综合使用(注意: 如果既要访问类属性,又要访问实例属性,就定义实例方法);

单例模式以及__new__方法
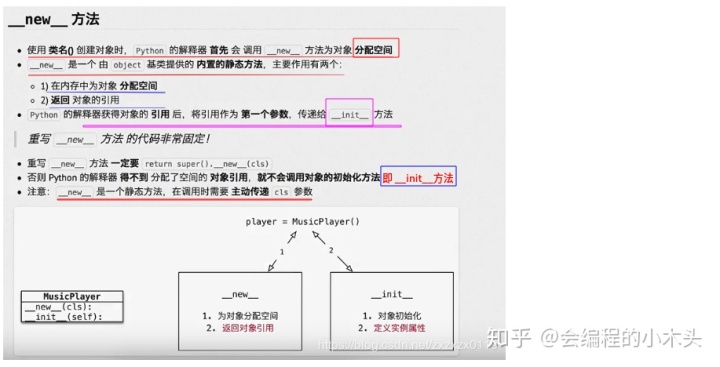

输出:

如果只重写__new__方法,没有返回相关的引用,创建的对象就为None。

输出:

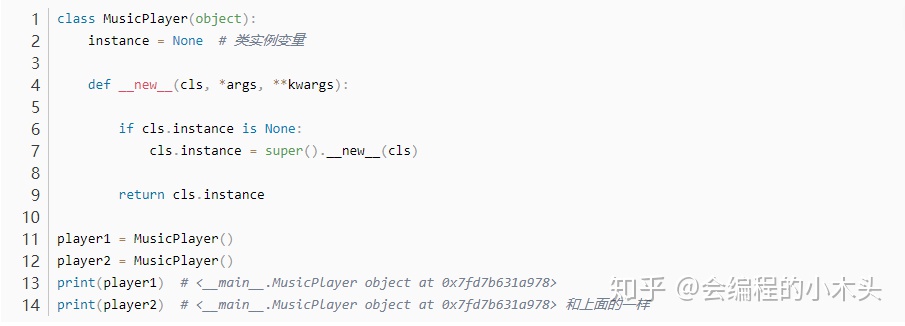
实现单例模式
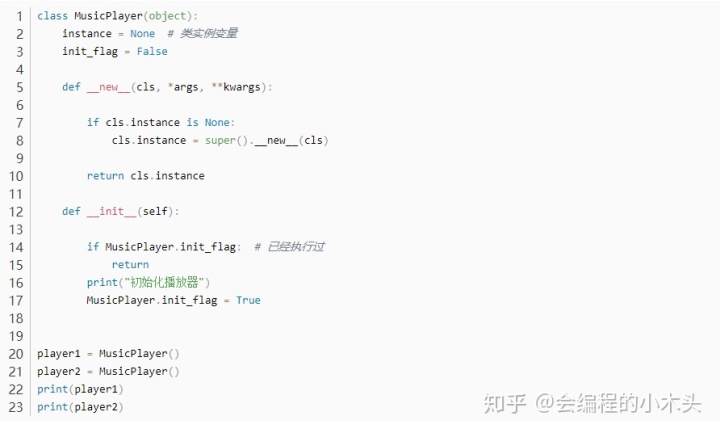
上面的单例模式虽然__new__方法只会执行一次,但是__init__还是会执行多次,如何只让初始化只执行一次呢,可以定义一个类变量记录;
异常
- 异常的语法结构

异常基本语法以及指定异常;

未知错误的异常处理代码演示;

测试:

和Java一样,也有异常的传递性;

测试:

类似Java中的throw关键字,raise抛出异常对象;

运行结果:

模块、包
dir()内置函数可以查看一个模块里面的所有函数名称;
导入模块的时候可以使用as关键字来给模块起一个别名(别名最好使用大驼峰命名法);
from import只导入部分工具,这种方式在调用具体的函数的时候不需要指定模块名.来调用;
如果使用from import导入的模块有两个相同的工具(函数),则后导入的会覆盖前面导入的函数;如果确实想要都用到这两个相同名字的函数,可以使用起别名的方式解决;

from import *的导入方式,这样和直接import 模块名看似是一样的,但是这种方式和from import一样,调用的时候不需要指定 模块名.,还是很方便的,但是开发中不推荐使用,因为有可能多个模块之间有相同的函数,这样也会导致覆盖的问题;
给文件起名千万不要和系统的文件模块名字相同,因为搜索模块的顺序是先从当前目录下搜索模块,最后才是python解释器中的模块;


__name__属性以及导入模块和测试的问题
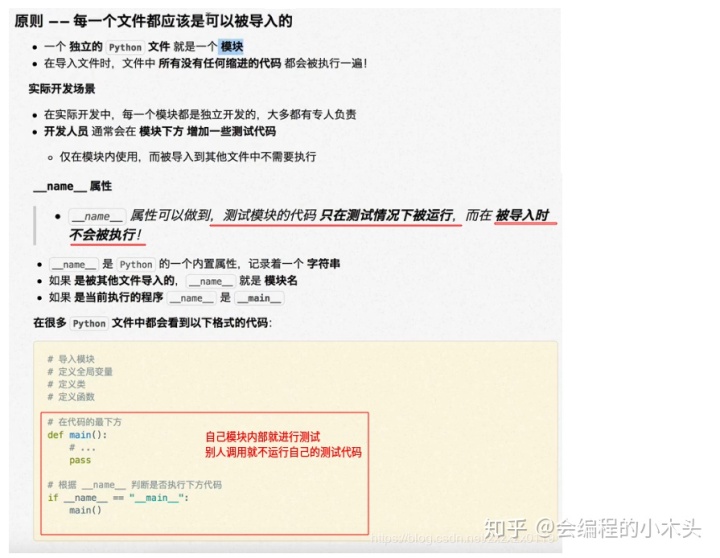
例如在python/exception包下面有两个文件测试模块3.py和py10___name__属性的使用.py两个文件:
py10___name__属性的使用.py代码如下:

测试模块3.py文件:

运行结果不会输出py10___name__属性的使用.py中的测试代码。
包的概念: ①包是含有多个模块的特殊目录;②包下有一个__init__.py文件;
在开发中,希望导入一个包,这个包中有多个模块,这时要使用包中的某个模块,需要在__init__.py中使用from . import 模块名的方式"注册"这个模块,别人才能使用这个模块;

例如:
python/py_message包下面有三个文件: __init__.py、send_message.py、receive_message.py三个文件,外界想使用后面两个文件: 则三个文件的代码如下 :
①__init__.py文件:
- 1.from . import send_message
- 2.from . import receive_message
②send_message.py文件:
- def send(text):
- print("正在发送 %s" % text)
③receive_message.py文件:
- def receive():
- return "这是来自 100XX的短信!";
测试文件(和上面三个文件不在同一个包下):
- import python.py_message # 导入的不是一个模块,而是一个包
-
- python.py_message.send_message.send("hello")
- txt = python.py_message.receive_message.receive()
- print(txt)
- 制作发布压缩包三个步骤: ①创建setup.py文件,关于这个文件格式看官方文档;②构建模块,在终端执行python3 setup.py build;③生成发布压缩包,在终端执行python3 setup.py sdist;
- 安装模块: 可以将包中的模块安装到python系统中,只需要两步: ①解压 tar -zxvf 压缩包名.tar.gz;②安装sudo python3 setup.py install;
- 卸载模块: 直接在安装的目录删除即可(python安装的目录的模块下);
- 安装第三方的包: sudo pip3 installl ...;
文件
- 文件的存储方式

文件基本操作(python中是一个函数(open)+三个方法)

read方法

- # 1. 打开文件 获取文件对象
- file = open("README")
-
- # 2. 读取文件 (默认情况下读取文件的所有内容)
- txt = file.read()
- print(txt)
-
- # 3. 关闭文件
- file.close()
关于文件指针的概念,在读取文件的时候,默认文件指针在文件的开始,在读取文件的时候会不断的移动,读取完之后到达文件的末尾。所以,如果使用read()读取了一次文件之后,再读取一次就不能读取到数据了;
- file = open("README")
- txt = file.read()
- print(txt)
- print(len(txt))
-
- print("*" * 40)
-
- print(file.read()) # 再次读取,因为文件指针已经移动到文件的末尾,所以读取不到
- # 3. 关闭文件
- file.close()
输出:
- 1.hello
- 2.hello
- 3.11
- 4.****************************************
读取文件的方式
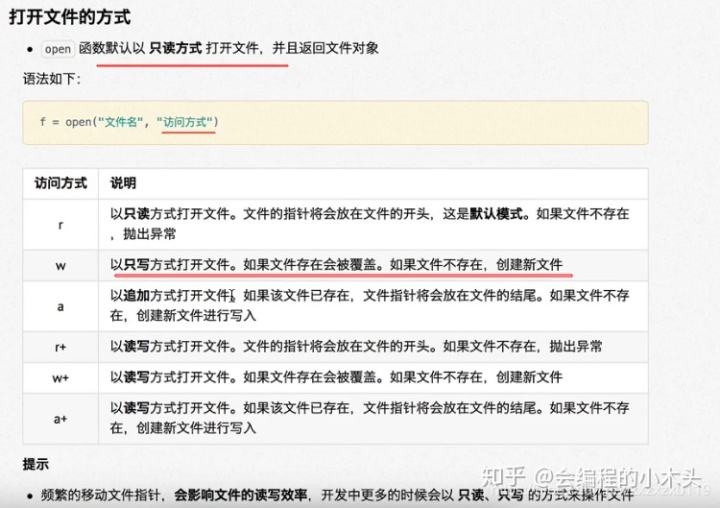
- 1.file=open("README","w")# w代表的是写入文件(覆盖) a代表的是追加
- 2.
- 3.file.write("write hello to README")
- 4.
- 5.file.close()
分行读取文件 : readline : 用来读取大文件的正确姿势。(read方法默认是直接读取整个文件)。readline每次读取一行之后,就会将文件指针往下移动一行;
- 1.file = open("README")
- 2.
- 3.while True:
- 4.txt = file.readline()
- 5.if not txt:
- 6.brea
- 7.print(txt, end="") # 因为读取的时候以及读取了一个空行,这里就输出空行了
- 8.
- 9.file.close()
文件复制案例(小文件)
- 1.file_read = open("README")
- 2.file_write = open("README[复件]", "w")
- 3.
- 4.text = file_read.read()
- 5.file_write.write(text)
- 6.
- 7.file_read.close()
- 8.file_write.close()
大文件复制
- 1.file_read = open("README")
- 2.file_write = open("README[复件]", "w")
- 3.
- 4.while True:
- 5.text = file_read.readline()
- 6.if not text: # 注意判断一下
- 7.break
- 8.file_write.write(text)
- 9.
- 10.file_read.close()
- 11.file_write.close()
- 12.
OS模块的命令使用

让python2也支持中文,只需要在py文件的行首增加一行代码# *-* coding:utf-8 *-*即可(python2默认使用的是ascii码编码);
指定了上面的格式之后,如果遍历字符串,还是会乱码,处理的方式是在字符串前面加上一个u,例如str = u"hello",意思就是按照utf-8编码格式处理;
eval()函数,会将字符串的内容当做表达式处理(python语句);但是不要滥用这个函数,这个函数可以被注入内容(类似sql注入),例如输入__import__('os').system.('ls')等

提取码:60ld
整理不易,分享一些小福利,链接容易被举报过期,如果失效了 这里领取



