
- 1php8.0安装拓展amqp_宝塔 php8.0安装rabbitmq扩展
- 2福布斯2024年十大AI趋势预测:颠覆性创新与挑战即将到来(中文概要版)_2024年十大科技趋势
- 3联邦学习后门攻击总结(2019-2022)_联邦学习无目标攻击
- 4AI程序员崛起:人类程序员的未来何去何从?_人工智能时代下程序员何去何从
- 5Appium环境搭建超详细教程
- 6Pytorch~ubuntu20.04搭建_ubuntu20.04下安装pytorch
- 7【网络】传输层TCP协议 | 三次握手 | 四次挥手_tcp报文和tcp伪首部
- 8because it is a JDK dynamic proxy that implements问题 看这一篇就够了_because it is a jdk dynamic proxy that implements:
- 9无锡VALSE 2023感悟收获(NLP方向)_valse2023汇报ppt
- 10安全架构设计理论与实践相关知识总结
YSU-ISBN码识别C++实现_识别isbn码
赞
踩
前言
国际标准书号(International Standard Book Number),简称ISBN,是专门为识别图书等文献而设计的国际编号。随着科技的不断发展,我们早已进入了信息时代,计算机科学正在融入到我们生活的方方面面,而视觉技术的应用也越来越广泛,利用OpenCV并在C++语言的开发下,对ISBN号进行识别就是其中一种应用。
但是,OpenCV对原始图像的识别是非常困难的,所以需要对图像进行预处理。这需要先将图像转为灰度图、进行去噪、图像二值化、边缘检测、角度调整。然后将ISBN号的区域截取出来,进行字符分割。最后将分割出来的字符进行一一匹配,并与正确的ISBN号进行比对,计算识别的正确率和准确率。
正文
研究内容的基本原理
本项目在OpenCV环境下,用C/C++语言并结合Visual Studio开发平台进行开发,基本原理如下:
图像灰度化处理
图像灰度化即是将一幅彩色图像转换为灰度化图像的过程。彩色图像通常包括R、G、B三个分量,分别显示出红绿蓝等各种颜色,灰度化就是使彩色图像的R、G、B三个分量相等的过程。灰度图像中每个像素仅具有一种样本颜色,其灰度是位于黑色与白色之间的多级色彩深度,灰度值大的像素点比较亮,反之比较暗,像素值最大为255(表示白色),像素值最小为0(表示黑色)。在实际应用中,可以采用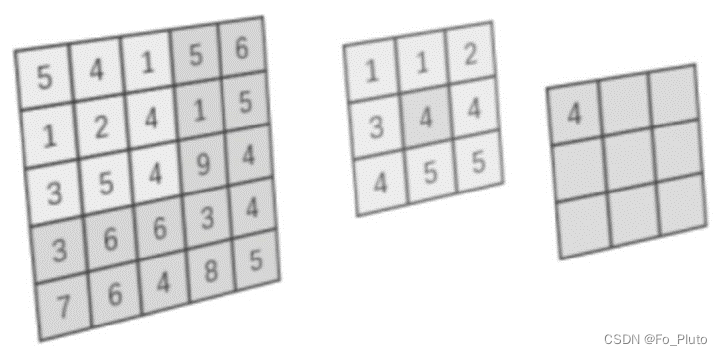
如下公式将彩色图像转换为灰度图像:
其中,Y代表转换后灰度图像的像素值, R、G、B分别代表彩色图像中红、绿、蓝三原色的分量。
中值滤波
中值滤波的原理是将已选择的某一像素点的邻域内的各像素点的值进行排序,并筛选中值作为当前像素点的数值,通过这种方式消除图像中色差、灰度值极大的像素值,从而减少椒盐噪声对图像的干扰。从频域上分析,中值滤波可以减弱或消除图像的高频分量,从而使得图像平滑,达到较好的滤波效果。如图所示,整个5×5的矩形代表滤波前的图像各像素点的灰度值,其中的左上角3×3的区域为选取的邻域。中间的图像为对邻域内灰度值排序的结果,选取其中的中值 4,将其填充到矩形作为滤波后结果。至此,完成针对一个像素点的一次滤波,对所有像素点都进行如上处理后即可完成中值滤波。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NVWmAMXa-1678447405214)(media/4cd76560c6842cbc9fd6d543d3d2aea2.png)]](https://img-blog.csdnimg.cn/de374a7953ef41dc923ca30ab3fd948e.png)
图 1 中值滤波原理图
图像二值化
大津法:该方法目标是求类间方差值,由阈值分割出的前景图像和背景图像这两部分构成了整幅图像,而前景的取值为,概率为,背景的取值,概率为,总均值为,根据方差的计算方法可以得到此式。方差是灰度分布均匀性的一种度量,数值越大越可以反应构成图像的两部分差别大,当部分目标误分为背景或部分背景误分为目标都会导致两部分差别变小,因此使类间方差值大的分割方式就意味着误分概率最小。
自适应阈值法:用于二值化处理图像,对于对比大的图像有较好效果,相对于OpenCV中固定阈值化操作(threshold()),自适应阈值中图像中每一个像素点的阈值是不同的,该阈值由其领域中图像像素带点加权平均决定。这样做的好处:每个像素位置处的二值化阈值不是固定不变的,而是由其周围邻域像素的分布来决定的。亮度较高的图像区域的二值化阈值通常会较高,而亮度较低的图像区域的二值化阈值则会相适应地变小。不同亮度、对比度、纹理的局部图像区域将会拥有相对应的局部二值化阈值。
边界填充
漫水填充算法是一种用特定颜色填充连通区域,通过设置像素上下限及连通方式来达到不同的连通效果。漫水填充经常用来标记或分离图像的一部分,以便于对其进行进一步的处理和分析。也可以从输入图像获取掩码区域,掩码会加速处理过程,或只处理掩码指定的像素点,操作的结果总是某个连续的区域。
Sobel边缘检测
边缘检测是属于图像处理和计算机视觉中的一个基本问题,边缘检测对数字图像中亮度变化明显的点通过线连接起来。图像属性中的显著变化通常是一些要点,包括深度上的不连续、表面方向的不连续,物质属性变化和场景照明变化。边缘检测是图像处理和计算机视觉中特征提取的一个研究领域。
边缘检测的实质是采用算法来提取出图像中对象与背景间的交界线。边缘定义为图像中灰度发生急剧变化的区域边界。灰度的变化情况可以用灰度分布的梯度来反映。在图像分割中,往往只用到一阶和二阶导数,二阶导数能够看出灰度突变的类型。有的时候,如灰度变化均匀的图像,只利用一阶导数可能找不到边界,此时二阶导数就能提供很有用的信息。二阶导数对噪声也比较敏感,解决的方法是先对图像进行平滑滤波,消除部分噪声,再进行边缘检测。
Sobel算子是边缘检测方法里最常用的基本算子之一,在技术上,该算子属于离散的一阶差分算子,用于计算图像亮度函数的近似值。在任何一张图像中使用这个算子作用于相应的对应点时,都会产生一个对应点的梯度向量。Sobel边缘检测的核心在于有两个的矩阵,分别是垂直方向和水平方向的检测模板,当分别使用该模板和图像矩阵做卷积后,可以得到水平和垂直方向的梯度幅值,
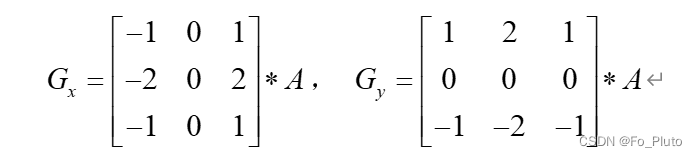
得到图像中每一个点的横向与纵向梯度幅值后,最后通过如下公式来计算梯度值:
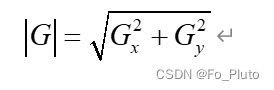
Hough直线检测
在多种直线检测方法中,Hough变换时最常用的方法,其优点在于算法稳定性好,抗噪性能好。Hough变换是一种从二维空间到参数空间的映射,即二维直角坐标系上的某一点到参数空间上的某一条曲线的映射,以对偶性原理为依据来获取直线的相关参数,二维空间内点的共线性对应于参数空间内曲线的共点性。直线在二维空间到参数空间的映射关系表达式为:
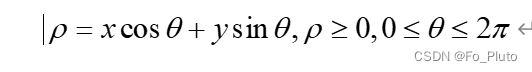
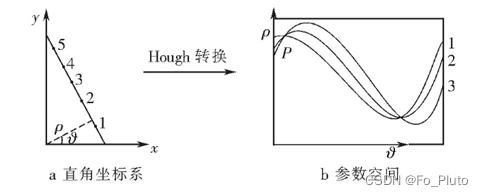
图 2 Hough变换原理图
倾斜修正
设为第条直线的偏转弧度,则平均偏转弧度为,即平均偏转角度为,根据图像偏转角度与直线倾斜角度的关系,可以得出图像偏转角度为.
字符框的截取与字符分割
经过颜色处理和角度旋转之后得到的图像,每一个部分在竖直方向上很好划分。所以说我们采取的方法是遍历图像的每一行,将每一行的白色像素的总数加起来,如果这一行的白点数小于某一个阈值,那么就认为这一行可以作为分割段。
同理,在分割出来所在行之后,我们会发现,我们可以遍历ROI图像的每一列,每一列中计算白色像素点的数量,用数量的变化来分割字符。
模板匹配
使用平方差匹配进行模板匹配,读入预先存好的字符模板,将是别的子图放大到和模板等大,然后进行模板匹配。计算两个图的平方差,记录到数组里,然后找到最小平方差就是当前子图对应的数字。
所采用的研究方法及相关工具
本项目以Visual Studio Code为基本工具,使用OpenCV结合C++进行项目的开发。
Visual Studio Code结合OpenCV较为方便,程序中使用了很多OpenCV中的函数,使得对于图像的处理变得更加容易。项目流程包括读取图像、调整大小、灰度化处理、图像二值化、倾斜修正、字符框的截取、字符分割、模板匹配等,我们使用了多组课程提供的数据集进行测试,并根据结果不断优化参数,以达到更好的效果。
项目的方案设计
本次项目的设计我们采用了类与对象的设计思想,并且写了一个主函数用于测试,主要的对象有两个:
- detectSolution类,此类是一个工具类,里边封装了读取图片,处理图片,识别图片这三个算法,对外接口是一个fit函数,调用fit函数只需要传入处理图片的地址或者所在文件夹,和模板图片所在的文件夹,就可以返回一个char类型的结果。还有一个构造函数,用于初始化参数。
代码概要参考detect.h,算法具体实现请参考detect.cpp。
class detectSolution { private: string sampleImgPath; // 样本图片的路径 Mat src_image; // 输入图片 Mat src_copy_image; // 拷贝输入图片 Mat gray_image; // 处理完成的灰度图像 Mat threshold_image; // 处理之后的二值化图片 Mat rotated_image; // 旋转之后的图像 Mat res_image; // 处理完成的图像,提取兴趣框时用 Mat ROI_image; // 提取兴趣框 vector<int> rows_element; // 行ROI感兴趣区域 vector<Point> points; // 每一行的像素值大于100像素点的数量 vector<PIII> ans; // 存储答案的容器 vector<int> num_area; // 数字的ROI感兴趣区域,即字符分割 vector<PII> num_position; // 数字的位置信息,用于字符分割 vector<Mat> num_ROI_rect; // 数字的Mat,截取数字的结果 std::string res_str; // 最终的答案 double ChNum; // 字符准确度 double StrNum; // 字符串准确度 double average; // 保存平均亮度 Range ROI_range; // y字符兴趣框位置 Range ROI_range_x; // x字符兴趣框位置 private: // 旋转操作 void ImgRectify(Mat& pic, Mat& BinaryFlat); // 获取平均亮度 void get_average_light(Mat _src); // 计算图像像素点值的平均值,用于分类 double CalcImg(Mat inputImg); // 模板匹配的主要函数 char CheckImg(Mat inputImg, int idx); // 水浸操作 void FloodFill(Mat& pic); // 预处理函数, 返回值赋值给res_image,使用自适应阈值 Mat get_res_image(Mat& src_image, int type); // 预处理函数, 返回值赋值给res_image,使用大津法 Mat get_res_image2(Mat& src_image, int type); // resize_stand函数,将图片resize成为较小尺寸,减少计算量 void resize_stand(); // find_ROI函数,用于寻找感兴趣区域 void find_ROI(); public: // 构造函数,初始化三个参数 detectSolution(string sample_path) { this->sampleImgPath = sample_path; this->ROI_range.end = 0, this->ROI_range.start = 0;} // 获取结果 string get_res(); // 获取字符准确度 double getChNum(); // 获取字符串准确度 double getStrNum(); // fit函数,用于整体识别的接口 int fit(string src_path, int model); };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- testSolution类,此类也是一个工具类,里边封装了测试代码字符串准确度和字符准确度的算法,算法主要是对读入图片的路径进行处理并且提取出答案ans。然后再将图片读入进行检测,得到的结果res与ans进行对比。最终算出字符串准确度和字符准确度的算法。
class testSolution {
private:
string sample_path; // 模板的所在文件夹地址
vector<pair<string, string>> ans; // 得到的答案容器
public:
// 构造函数,传入模板路径
testSolution(string sample_path)
{ this->sample_path = sample_path; }
// 测试函数,对外接口
pair<double, double> test(string path);
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
核心代码实现
读入要识别的图像
代码思路:
利用OpenCV中的imread函数即可读入要识别的图像,参数只要填入图像的路径并且将图像拷贝到src_copy_image中备份。
代码如下:
this->src_image = imread(src_path);
if (!this->src_image.data) {
cout << "src_image_empty!" << endl;
return ERROR;
}
- 1
- 2
- 3
- 4
- 5

图 3 输入的图像
调整图像大小
代码思路:
在读入图像之后,为了减少代码的计算量,并且提高代码的运行速度,我们需要对读入的图像的大小进行相应的调整。但是要确保图像的比例,所以我们写了一个函数resize_stand()含义为:将图片resize成为我们认为的标准大小。
代码如下:
// 图像标准化,并进行预处理 接口中调用
this- >resize_stand(); // 使用
// 类中实现代码
void detectSolution::resize_stand() {
double width = 1200; // 将图片resize成为一个1200宽的图像
double height = width * (double)src_image.rows / src_image.cols;
resize(src_image, src_image, cv::Size(width, height));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
灰度化处理
代码思路:
OpenCV对于彩色图的识别有较大的困难,为了减小处理的难度,第二步就需要将图像进行灰度化的处理。
代码如下:
// 灰度化处理
cvtColor(src_image, gray_image, COLOR_RGB2GRAY);
- 1
- 2

图 4 灰度化处理的图
去噪处理
代码思路:
由于有些图像中具有斑点噪声,或者椒盐噪声,如果我们不在灰度化的步骤中处理好这些噪声。将在后续二值化,直线检测,乃至ROI提取的步骤中造成无法正确处理甚至抛异常的结果。
使用中值滤波的原因:
1 . 而中值滤波相比于简单的均值滤波对于去除这些噪声有着很好的效果。
2 . 而如果使用高斯滤波的话,如果图像的噪声不是高斯噪声而是散点噪声,高斯滤波的效果反而没有那么好了。
所以综合上面的两个因素,并且通过实际实验证明,我们决定使用中值滤波进行平滑处理。
然后我们还使用了扩张和腐蚀的操作。这样做主要是为了后续的分割操作做准备。
代码如下:
// 滤波用的核 Mat dilate_image,erode_image; Mat element = getStructuringElement(MORPH_RECT, Size(5, 5)); // 膨胀腐蚀,为了防止后续分割字符连在一块 dilate(gray_image, erode_image, element); erode(erode_image, erode_image, element); // 自己实现的中值滤波,因为效果更好 Mat mid_image, bilateral_image; ImgDenoise(erode_image, mid_image); // 实现代码 void ImgDenoise(Mat& pic, Mat& ImgClear)//中值滤波去噪 { int dx[] = { 0,-1,0,1,-1,1,-1,0,1 }; int dy[] = { 0,1,1,1,0,0,-1,-1,-1 }; ImgClear = Mat(pic.rows, pic.cols, CV_8UC1); int val[10], mid; for (int i = 0; i < pic.rows; i++)//跳过边缘不处理 for (int j = 0; j < pic.cols; j++){ if (i == 0 || j == 0 || i == pic.rows - 1 || j == pic.cols - 1){ ImgClear.at<uchar>(i, j) = pic.at<uchar>(i, j); continue; } for (int k = 0; k < 9; k++) val[k] = pic.at<uchar>(i + dx[k], j + dy[k]); mid = SortMid(val); ImgClear.at<uchar>(i, j) = mid; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28

图 5 中值滤波效果图
图像二值化处理
代码思路:
为了归一化图像的像素点,便于区分边缘,我们需要进行二值化处理。OpenCV库中有两种方法。
方法总结:
第一个方法为大津法:大津法的主要优点是最终的噪点少,但是缺点就是鲁棒性差,对于有些存在阴影的图像,大津法的效果会受阴影影响。
第二个方法为自适应阈值法:本方法的主要优点为鲁棒性好,但是缺点就是噪点较多,很多图片处理完之后会有各种散点噪声。
所以综合考虑,我们决定将两个方法综合起来,最终发现准确率高了很多,所以模型集成是个很好的方法。
代码如下:
// 使用大津法进行二值化处理
threshold(mid_image, threshold_image_OTSU, 0, 255, type | THRESH_OTSU);
// 使用自适应法进行二值化处理
adaptiveThreshold(mid_image, threshold_image_ad, 255, ADAPTIVE_THRESH_MEAN_C, type, 159, 18);
- 1
- 2
- 3
- 4

图 6 二值化处理后的图
调整图像角度
算法设计:
从实际图片上来看,很多图片都是倾斜的,如果直接拿这个图片进行后续处理,会导致图片后续处理识别会出现问题,所以说我们十分有必要先去调整图片的角度,再进行下一步的操作。
我们先是通过霍夫直线检测,检测出来平行于字符串或者垂直与字符串的多条横线,并且计算出这些直线的偏角,并求平均,使用平均偏角调整图像的角度,使得字符串能够正过来。
霍夫直线检测效果见下图绿色直线:

图 7 霍夫直线检测效果图
算法实现:
// 旋转操作 void detectSolution::ImgRectify(Mat& pic, Mat& BinaryFlat) {//图像矫正 Mat pic_edge; Sobel(pic, pic_edge, -1, 0, 1, 5); // 霍夫直线检测(第5个参数是阈值,阈值越大,检测精度越高) vector<Vec2f> Line; HoughLines(pic_edge, Line, 1, CV_PI / 180, 180, 0, 0); // 计算偏转角度 double Angle = 0; int LineCnt = 0; for (int i = 0; i < Line.size(); i++){ if (Line[i][1] < 1.2 || Line[i][1] > 1.8) continue; Angle += Line[i][1]; LineCnt++; } if (LineCnt == 0) Angle = CV_PI / 2; else Angle /= LineCnt; Angle = 180 * Angle / CV_PI - 90; Mat pic_tmp = getRotationMatrix2D(Point(pic.cols / 2, pic.rows / 2), Angle, 1); Size src_size = Size(pic.cols * 1.42, pic.rows); warpAffine(pic, BinaryFlat, pic_tmp, src_size); warpAffine(this->src_copy_image, this->src_copy_image, pic_tmp, src_size); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

图 8 旋转后的图
水漫操作
算法设计:
第6步旋转函数之后使用了一次水漫操作,这一步主要的想法是去除图像边缘颜色变化的影响。
如果不进行水漫操作,图像左边右边将会存在很多的白色边框,很不利于字符串所在行的分割以及字符的分割。下图是没有进行水漫操作的二值化图片:

图 9 没有进行水漫操作的二值化图片
可以看到,二值化之后的图片周围还是有很多的噪声,比如右边左边的白边,这样严重的会导致字符串所在行分割错误。
算法主要采用深度优先搜索的方式进行水漫,定义了队列q用来实现。首先将图像四周的白色点都push到队列q中,然后每个点遍历八个点的子点,如果子点为白点,就将该店设置为0。
实现代码:
//水漫操作 void detectSolution::FloodFill(Mat& pic)//水漫操作 { int dx[] = { -1,0,1,-1,1,-1,0,1 }; int dy[] = { 1,1,1,0,0,-1,-1,-1 }; queue<PII> q; for (int i = 0; i < pic.cols; i++)//上 for (int j = 0; j < 1 || (ROI_range.start < ROI_range.end && j < ROI_range.start); j++) if (pic.at<uchar>(j, i) != 0) q.push({ j,i }); for (int i = 0; i < pic.cols; i++)//下 for (int j = pic.rows - 1; j >= pic.rows - 1; j--) if (pic.at<uchar>(j, i) != 0) q.push({ j,i }); for (int i = 0; i < pic.rows; i++)//左 for (int j = 0; j < 1 || (ROI_range_x.start < ROI_range_x.end && j < ROI_range_x.start); j++) if (pic.at<uchar>(i, j) != 0) q.push({ i,j }); for (int i = 0; i < pic.rows; i++)//右 for (int j = pic.cols - 1; j >= pic.cols - 1; j--) if (pic.at<uchar>(i, j) != 0) q.push({ i,j }); while (!q.empty()) { PII t = q.front(); q.pop(); int x = t.first, y = t.second; for (int i = 0; i < 8; i++) { int nx = x + dx[i]; int ny = y + dy[i]; // 如果越过字符所在行,直接跳过循环 bool f1 = false, f2 = false; if(ROI_range.start < ROI_range.end && (nx >= ROI_range.start && nx <= ROI_range.end)) { f1 = true; } if(ROI_range_x.start < ROI_range_x.end && (ny >= ROI_range_x.start && ny <= ROI_range_x.end)) { f2 = true; } if(f1 && f2) continue; if (nx < 0 || ny < 0 || nx >= pic.rows || ny >= pic.cols) continue; if (pic.at<uchar>(nx, ny) != 0) { pic.at<uchar>(nx, ny) = 0; q.push({ nx,ny }); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45

图 10 进行水漫操作的二值化图片
提取图像ROI区域与字符分割
算法设计:
通过以上的图像预处理,我们得到了一个适合用来提取字符所在行和字符分割的图像:

图 11 准备提取字符所在行和字符分割的图像
然后通过观察处理完成的图像,我们可以发现,经过颜色处理和角度旋转之后得到的图像,每一个部分在竖直方向上很好划分。所以说我们采取的方法是遍历图像的每一行,将每一行的白色像素的总数加起来,如果这一行的白点数小于某一个阈值(32),那么就认为这一行可以作为分割段。
这里我可视化了一下每一行的白点数量**(参考下图蓝色线段)**,蓝色的线越靠右边,则表示白色像素点越多。越靠左边,则说明这一行基本没有白色点,可以作为分割行。

图 12 竖直直方图
可以看到,有数字的那一段的每一行都有着更多的白点数量。跟其他的段完全分割开来,也证明了这一方法的可行性。
然后可以思考,从上面往下面找会有点困难,因为上面的噪点会降低识别的鲁棒性,所以我们可以从中间开始往上面找。
同理,在分割出来所在行之后,我们会发现,我们可以遍历ROI图像的每一列,每一列中计算白色像素点的数量,用数量的变化来分割字符。
算法实现:
void detectSolution::find_ROI() { // 先将上次的工作清除 ans.clear(); points.clear(); rows_element.clear(); for (int i = 0; i < res_image.rows; i++) { int sum = 0; uchar * ff = res_image.ptr(i); for (int j = 0; j < res_image.cols; j++) { if (*(ff + j) >= 100) sum++; } rows_element.push_back(sum); points.push_back(Point(sum / 2, i)); if (i) line(src_copy_image, points[max(0, i - 1)], points[i], Scalar(255, 0, 0), 2); } int idx = -1; for (int i = 0; i < rows_element.size() / 2; i++) { if (rows_element[i] >= 35) { PIII item = { ++idx, {i, 0} }; ans.push_back(item); int idx = i; while (rows_element[idx] >= 35) idx++; ans[item.first].second.second = idx; i = ++idx; } } int _begin = ans[max(0, (int)ans.size() - 2)].second.first, _end = ans[max(0, (int)ans.size() - 2)].second.second; priority_queue<double> heap; // 最大堆 if(_end - _begin >= 400 || _end - _begin <= 40){ ans.clear(); idx = -1; for (int i = 0; i < rows_element.size() / 2; i++) { if (rows_element[i] >= 35 && (!heap.size() | | heap.top() - rows_element[i] <= 300)) { heap.push(rows_element[i]); PIII item = { ++idx, {i, 0} }; ans.push_back(item); int idx = i; while (rows_element[idx] >= 35 && heap.top() - rows_element[idx] <= 300){ heap.push(rows_element[idx ++]); } ans[item.first].second.second = idx; i = ++idx; } else { while(heap.size()) heap.pop(); } } _begin = ans[max(0, (int)ans.size() - 2)].second.first, _end = ans[max(0, (int)ans.size() - 2)].second.second; } // 如果没有提取到导致开始小于结尾,或者太大,直接返回 if (_begin >= _end | | _begin > 114514) return; // 保存兴趣框位置 this- >ROI_range = Range(_begin, _end); // 提取兴趣框 this- >ROI_image = res_image(Range(_begin, _end), Range::all()); num_area.clear(); num_position.clear(); for (int i = 0; i < ROI_image.cols; i++) { int num = 0; for (int j = 0; j < ROI_image.rows; j++) { uchar * ch = ROI_image.ptr(j); if ( *(ch + i) >= 103) num++; } num_area.push_back(num); } for (int i = 0; i < num_area.size(); i++) { if (num_area[i] >= 2) { PII item = { max(i - 1, 0), 0 }; int idx = i; while (num_area[idx]) idx++; item.second = idx; i = idx; num_position.push_back(item); } } // 保存x方向的边 this->ROI_range_x.start = num_position[0].first; this->ROI_range_x.end = num_position[num_position.size()-1].second; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80

图 13 字符串所在行提取结果

图 14 字符分割结果
字符识别
算法设计:
通过上面的预处理,我们已经得到了一串很好用来匹配的字符串,接下来就是需要将每一个字符都识别出来,我们采用的方法为模板匹配。模板匹配的主要原理就是预先定制一套字符识别的模板,如下图所示:
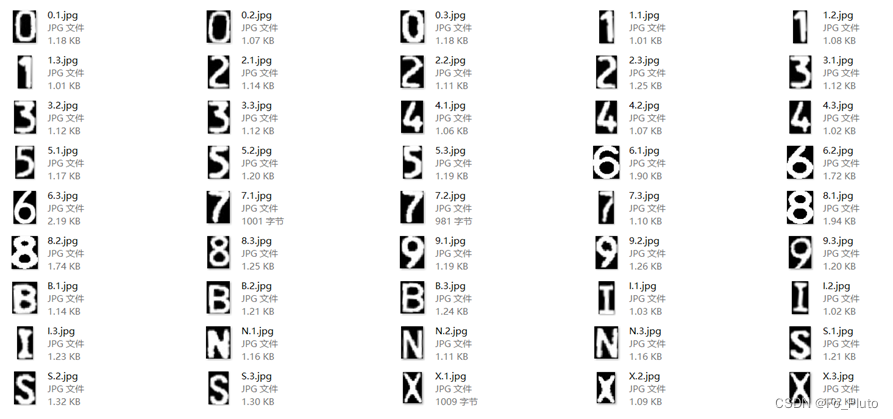
图 15 模板
这些图片每一个都是使用训练集通过上面的预处理并且分割出来的小图片,然后对图片进行人工标注,名称为:a-b,a代表着字符a,b代表着字符a的第b个样本。
得到了模板样本和测试样本,我们接下来就可以开始匹配:
算法实现:
// pair比较函数 bool MCompare(pair<int, double>a, pair<int, double>b) { return a.second < b.second; } //模板匹配的主要函数 char detectSolution::CheckImg(Mat inputImg, int idx) { // cout << "size: " << inputImg.rows * inputImg.cols << endl; // 如果图片过小,就直接返回空格 int S = inputImg.rows * inputImg.cols; if(S <= 630 && (double)inputImg.rows / inputImg.cols < 1) return ' '; //读取模板图片 vector<String> sampleImgFN; glob(sampleImgPath, sampleImgFN, false); int sampleImgNums = sampleImgFN.size(); pair<int, double>* nums = new pair<int, double>[sampleImgNums];//first 记录模板的索引号,second 记录两图像之差 for (int i = 0; i < sampleImgNums; i++) { Mat numImg = imread(sampleImgFN[i], 0); Mat delImg, demo_del_image; resize(inputImg, inputImg, Size(numImg.cols, numImg.rows)); absdiff(numImg, inputImg, delImg); double res; // 尝试使用库函数中的模板匹配 matchTemplate(inputImg, numImg, demo_del_image, CV_TM_SQDIFF_NORMED); nums[i].first = i; // nums[i].second = CalcImg(delImg); nums[i].second = CalcImg(delImg); } sort(nums, nums + sampleImgNums, MCompare);//选择差值最小的模板 int ans_idx = 0; for (int i = 0; i < sampleImgNums; ++i) { if (idx > 5) { // 数字,就不用判断字母了 // 找到最靠前的数字 while (nums[ans_idx].first / 3 >= 10 || nums[ans_idx].first == 14) ans_idx++; } else if (idx < 2) { // 字母 // 找到最靠前的字母 while (nums[ans_idx].first / 3 <= 9 && nums[ans_idx].first != 14) ans_idx++; } } int index = nums[ans_idx].first; index = index / 3; switch (index) { case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7: case 8: case 9: return index + '0'; case 10: return 'B'; case 11: return 'I'; case 12: return 'N'; case 13: return 'S'; case 14: return 'X'; default: return ' '; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
此函数返回了一个char,表示识别到的结果,返回的结果依次存到detectSolution类中的ans容器中,最后再输出一段字符串。
项目测试
算法方案设计:
得到了最后的结果,接下来就是测试上面代码的性能了,这里我们把测试看作一个类,编写了一个testSolution.h和testSolution.cpp文件,设计了一个test类用于测试:
为了得到标签,我们先进行了字符串的处理,我们将图片路径字符串中的数字全部提取出来。
实现代码:
string testItem = testImgFN[i]; // 取出来每个路径字符串 int idx = testItem.find("ISBN", 0); int num_space = 0; while(testItem[idx] < '0' | | testItem[idx] > '9') { idx ++; num_space ++; } string path = testItem; testItem = testItem.substr(idx, testItem.length() - idx - 4); // 实际的答案 string res = ""; // 只取数字 for(int j = 0;j < testItem.size();j++){ if(testItem[j] <= '9' && testItem[j] >= '0'){ res += testItem[j]; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
然后再用该图片通过new出来的detectSolution对象调用fit函数得到图像的结果赋值给ans,同样也值取出来数字作为识别的答案。与第一步得到的字符串进行比较,得到字符准确率和字符串准确率。
detectSolution * detect_item = new detectSolution(this- >sample_path); detect_item- >fit(path, k); string ans = detect_item- >get_res(), ans_temp = ""; // 我们得到的结果 // 只取数字 for(int j = 0;j < ans.length();j++){ if(ans[j] <= '9' && ans[j] >= '0'){ ans_temp += ans[j]; } } // 计算正确数量 int num_temp = 0; for(int oi = 0;oi < res.length() && oi < ans_temp.length();oi++){ if(res[oi] == ans_temp[oi]) num_temp ++; } // 测试文件main.cpp,测试文件是最终用户端调用的代码 #include "testSolution.h" int main() { string test_path = "/home/fo_pluto/opencv_home/test2/ *"; string sample_path = "/home/fo_pluto/opencv_home/datasets/ *"; // 调用最终接口test testSolution * test = new testSolution(sample_path); auto res = test- >test(test_path); // 输出结果 cout << "string P: " << res.first * 100 << "%" << endl; cout << "words P: " << res.second * 100 << "%" << endl; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
最终结果:

图 16 最终结果
研究结果并讨论
通过我们小组的不断学习与探索,我们最终能够识别出了较多的ISBN号。在不断优化该项目的同时,我们小组对于OpenCV的使用变得更加熟悉。也了解了利用OpenCV识别图像的一般步骤和方法。同时,我们也认识到了小组合作的意义,也了解了应该如何高效的合作,这些都将对我们日后的学习与合作有着重要的意义。
结论
主要工作
我们本次项目的主要工作是要识别图书当中的ISBN号。我们小组的主要工具为Visual Studio Code,利用C++语言结合OpenCV,在借助OpenCV中的一些函数的情况下,对含有ISBN号的图片进行一系列的处理并识别。然后检测我们所识别的正确率和准确率。
主要结果
借助于OpenCV,并进行了多组数据测试,我们的程序可以以较高的正确率和准确率识别出ISBN号,并将ISBN号进行输出,测试结果的统计如下图:
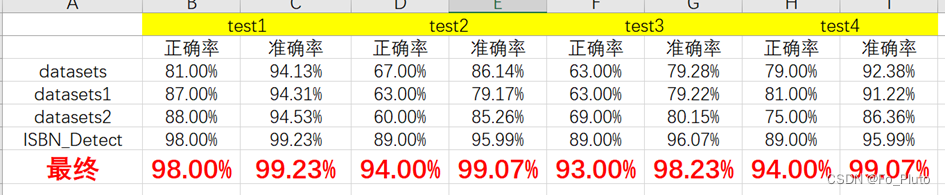
图 17 训练测试结果的统计
对于课程提供的测试集,我们的测试结果如下:

图 18 最终结果
写在最后
本项目是本人大二的课设项目欢迎参考,临时总结的东西,之后再看看有没有错误。
项目所用的编译器为cmake,操作系统linux,也可以使用vs打开。项目代码已开源,开源地址:FOPluto/-ISBN- (github.com)
克隆代码后,请修改模板地址和测试集地址,并且请务必要确保测试集路径字符串没有ISBN这个字符串,别出着错来找我。
燕大的在下面滴滴哦!!

