
- 1NLP实践——Few-shot事件抽取《Building an Event Extractor with Only a Few Examples》
- 2seetaface人脸识别引擎的windows java 实现,可用于搭建人脸识别java web服务器_seetaface java
- 3微信小程序自动化测试——智能化 Monkey_智能化monkey
- 4无依赖安装sentence-transformers
- 5文心一言 vs gpt-4 全面横向比较
- 6使用Spark清洗统计业务数据并保存到数据库中_spark在spring boot数据清洗
- 7Attention机制详解(深入浅出)
- 8查看transformers和torch版本_查看transformers版本
- 9自然语言处理之语言模型
- 102024最新AI系统ChatGPT商业运营网站源码,支持Midjourney绘画AI绘画,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图_sparkai系统源码
yolov5结果解析_background fp
赞
踩
Confusion matrix
以这种形式给出矩阵的值
| g t c l a s s 1 gt_{class1} gtclass1 | g t c l a s s 2 gt_{class2} gtclass2 | g t c l a s s 3 gt_{class3} gtclass3 | background FP | |
|---|---|---|---|---|
| p r e d c l a s s 1 pred_{class1} predclass1 | ||||
| p r e d c l a s s 2 pred_{class2} predclass2 | ||||
| p r e d c l a s s 3 pred_{class3} predclass3 | ||||
| background FN |
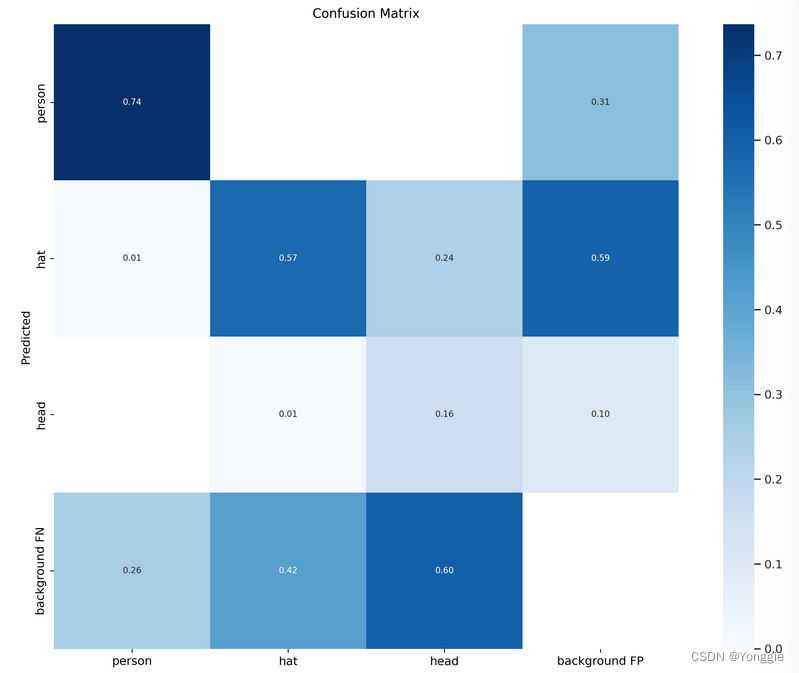 若是分类的完美,则应当只有对角线是高峰,其余都是0(除了最后一行和最后一列).
若是分类的完美,则应当只有对角线是高峰,其余都是0(除了最后一行和最后一列).
根据GitHub上的讨论,background也被列成单独一类,所以也有他的TP、FP、TN、FN等。
最后一列和最后一行都是以background的类别pos的prediction的FN和FP。所以最右下角是没有意义的,没有值。
- 由于最后一列是background的FP,本来不是背景的,被pred分成了背景,漏检了非背景物体
- 由于最后一行是background的FN,本来是背景的,被pred分成了不是背景,虚检了本来没有的物体。
混淆矩阵最后一行和一列是背景类。上面我们知道列是模型预测的结果,行是标签的真实结果。而FP则是表示真实为假预测为真,FN表示真实为真预测为假。可以看到最后一行即backgroundFN出现数值,表示出现了漏检;最后一列即background FP出现数值,则表示出现了虚检
来自 https://blog.csdn.net/m0_66447617/article/details/124180032,
另外可参考github上的讨论,background也被单独划分成了一个类别。
https://github.com/kaanakan/object_detection_confusion_matrix/issues/12
以上面的图为例子的话,可以看到background FN各类都比较高,虚检了很多物体;background FP- hat的相对较高,漏检了很多head类别的物体。而在非背景的类别中,可以看到对角线的值相对大,可见模型能够很好的分清楚这三类谁是谁。
F1 curve
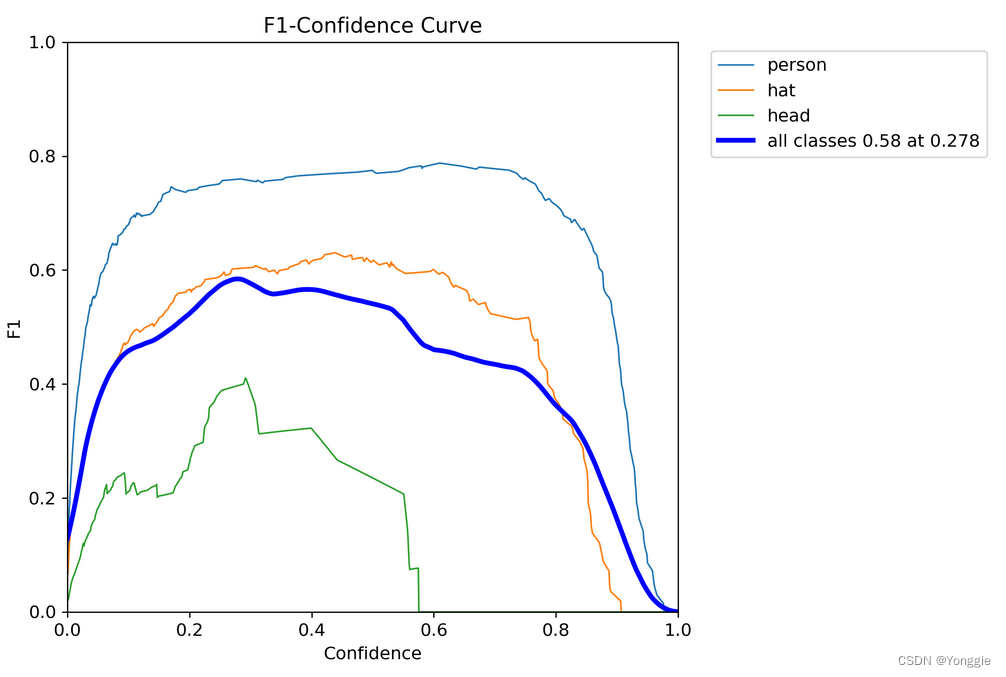 横坐标是置信阈值。
横坐标是置信阈值。
F
1
=
2
∗
1
1
p
r
e
c
i
s
i
o
n
+
1
r
e
c
a
l
l
F1=2*\frac1{\frac1{precision}+\frac1{recall}}
F1=2∗precision1+recall11
此图能够看到什么阈值下什么类别能够达到最好的F1 score,比如绿线在0.27左右,海蓝色在0.8左右。
labels
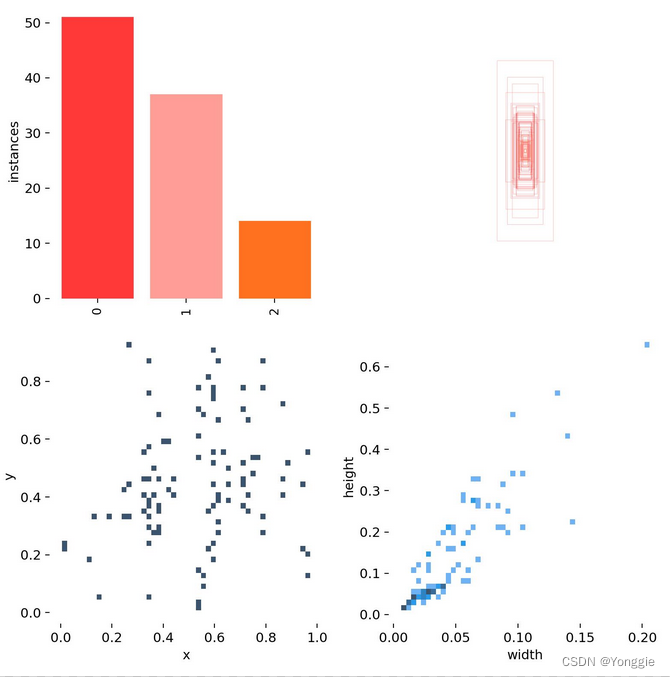
给所提供的label数据进行统计,是4个图,左上是各个物体的数量直方图,右上是中心对齐后各个物体的bounding box,左下角是中心点统计,右下角是方框长、宽统计
results
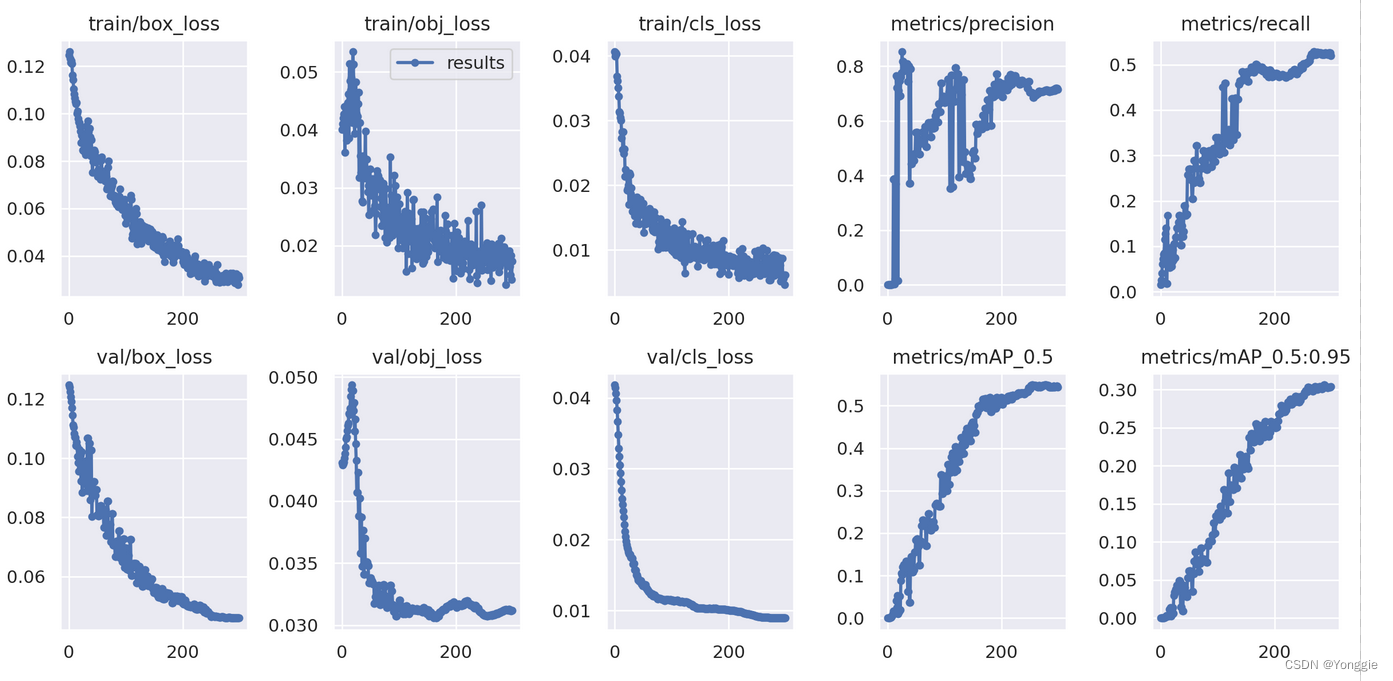 横坐标是epoch,标题比较直观的说了每个图的意思
横坐标是epoch,标题比较直观的说了每个图的意思
剩下一些不需要解释的图
常规曲线
P-R curve
P curve
R curve
batch抽取的case study
这些就是抽取个例查看。

