
- 1国产大模型KimiChat起飞了!200万字内测开启,AI助手能力大提升!_kimichat是国产吗
- 2IDEA切换JDK版本超详细步骤_idea怎么换sdk
- 3学习 Rust 机器人框架 Dora,来 GOSIM Workshop!
- 4Thinkphp 路由设置和定义_thinkphp8多模块怎么定义路由
- 52D车道线检测算法总结_车道线检测 分割方法综述
- 6抖音api开放平台对接_抖音入局本地生活!将流量变现最大化!
- 7python数据类型之【集合、字典】——集合无序,字典在python3.6之后print时好像变为有序,但二者都不支持索引、集合的运算(并集、交集、差集、异或、union( ) )、集合和列表的区别_python集合无序性
- 8解决Resource u'taggers/averaged_perceptron_tagger/averaged_perceptro n_tagger.pickle' not found._attempted to load taggers/averaged_perceptron_tagg
- 9自然语言处理——学习笔记(5):NLP基础任务——序列标注_序列标注任务
- 10内网穿透工具(全免费)
常用的聚类算法及聚类算法评价指标
赞
踩
作者 | 荔枝boy
来源 | 磐创AI
引用 | 基于图的聚类分析研究—张涛
【导读】:本文介绍了常用的聚类算法及聚类算法评价指标。
1. 典型聚类算法
1.1 基于划分的方法
代表:kmeans算法
·指定k个聚类中心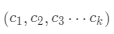
·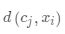 (计算数据点与初始聚类中心的距离)
(计算数据点与初始聚类中心的距离)
·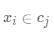 (对于数据点
(对于数据点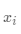 ,找到最近的
,找到最近的 {i}ci(聚类中心),将
{i}ci(聚类中心),将 分配到
分配到 {i}ci中)
{i}ci中)
·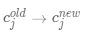 (更新聚类中心点,
(更新聚类中心点,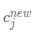 是新类别数值的均值点)
是新类别数值的均值点)
·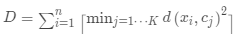 (计算每一类的偏差)
(计算每一类的偏差)
· 返回
返回
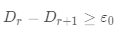 返回第二步
返回第二步
1.2 基于层次的方法
代表:CURE算法
·每个样本作为单独的一个类别
·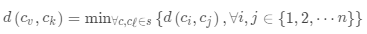
·合并 ,
, 为
为
·遍历完本次样本,合并成新的类别后,若存在多个类别,则返回第二步
·遍历完本次样本,合并成新的类别后,若所有样本为同一类别,跳出循环,输出每层类别
1.3 基于网格的方法
代表:STING算法
·将数据集合X划分多层网格结构,从某一层开始计算
·查询该层网格间的属性值,计算属性值与阈值的关系,判定网格间的相关情况,不相关的网格不作考虑
·如果网格相关,则进入下一层的相关区域继续第二步,直到下一层为最底层
·返回相关网格结果
1.4 基于密度的方法
代表:DBSCAN算法
·输入数据集合X,随机选取一点,并找出这个点的所有高密度可达点
·遍历此点的所有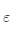 邻域内的点,并寻找这些密度可达点,判定某点
邻域内的点,并寻找这些密度可达点,判定某点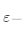 邻域内的点,并寻找这些点密度可达点,判定某点的
邻域内的点,并寻找这些点密度可达点,判定某点的 邻域内的点数是否超过阈值点数,超过则构成核心点
邻域内的点数是否超过阈值点数,超过则构成核心点
·扫描数据集,寻找没有被聚类的数据点,重复第二步
·输出划分的类,并输出异常值点(不和其他密度相连)
1.5 神经网络的方法
代表:SOM算法
·数据集合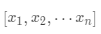 ,权重向量为
,权重向量为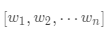 ,
,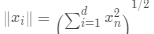 ,归一化处理
,归一化处理
·寻找获胜的神经元,找到最小距离,对于每一个输入数据,找到与之最相匹配的节点
令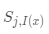 为
为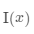 为
为 的距离,更新权重:
的距离,更新权重: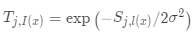
·更新临近节点,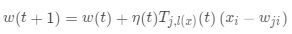 ,其中
,其中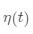 代表学习率
代表学习率
1.6 基于图的聚类方法
代表:谱聚类算法
·计算邻接矩阵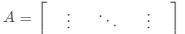 ,度矩阵
,度矩阵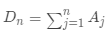 ,
,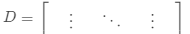
·计算拉普拉及矩阵
·计算归一化拉普拉斯矩阵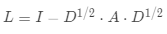
·计算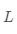 的特征值和特征向量
的特征值和特征向量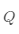
·对Q矩阵进行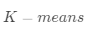 聚类,得到聚类结果
聚类,得到聚类结果
2. 聚类算法的评价指标
一个好的聚类方法可以产生高品质簇,是的簇内相似度高,簇间相似度低。一般来说,评估聚类质量有两个标准,内部质量评价指标和外部评价指标。
2.1 内部质量评价标准
内部评价指标是利用数据集的属性特征来评价聚类算法的优劣。通过计算总体的相似度,簇间平均相似度或簇内平均相似度来评价聚类质量。评价聚类效果的高低通常使用聚类的有效性指标,所以目前的检验聚类的有效性指标主要是通过簇间距离和簇内距离来衡量。这类指标常用的有CH(Calinski-Harabasz)指标等
CH指标
CH指标定义为: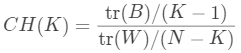
其中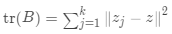 表示类间距离差矩阵的迹,
表示类间距离差矩阵的迹,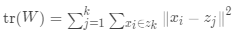 表示类内离差矩阵的迹,
表示类内离差矩阵的迹,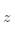 是整个数据集的均值,
是整个数据集的均值,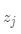 是第
是第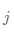 个簇
个簇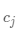 的均值,
的均值,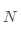 代表聚类个数,
代表聚类个数,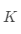 代表当前的类。
代表当前的类。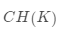 值越大,聚类效果越好,
值越大,聚类效果越好,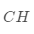 主要计算簇间距离与簇内距离的比值
主要计算簇间距离与簇内距离的比值
簇的凝聚度
簇内点对的平均距离反映了簇的凝聚度,一般使用组内误差平方(SSE)表示: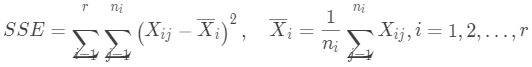
簇的邻近度
簇的邻近度用组间平方和(SSB)表示,即簇的质心 到簇内所有数据点的总平均值
到簇内所有数据点的总平均值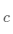 的距离的平方和
的距离的平方和
2.2 外部质量评价标准
外部质量评价指标是基于已知分类标签数据集进行评价的,这样可以将原有标签数据与聚类输出结果进行对比。外部质量评价指标的理想聚类结果是:具有不同类标签的数据聚合到不同的簇中,具有相同类标签的数据聚合相同的簇中。外部质量评价准则通常使用熵,纯度等指标进行度量。
熵:
簇内包含单个类对象的一种度量。对于每一个簇,首先计算数据的类分布,即对于簇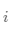 ,计算簇
,计算簇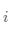 的成员属于类
的成员属于类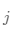 的概率
的概率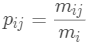
其中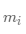 表示簇
表示簇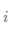 中所有对象的个数,而
中所有对象的个数,而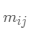 是簇
是簇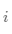 中类
中类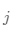 的对象个数。使用类分布,用标准公式:
的对象个数。使用类分布,用标准公式: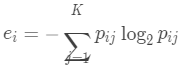
计算每个簇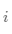 的熵,其中K是类个数。簇集合的总熵用每个簇的熵的加权和计算即:
的熵,其中K是类个数。簇集合的总熵用每个簇的熵的加权和计算即: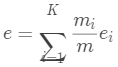
其中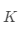 是簇的个数,而
是簇的个数,而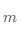 是簇内数据点的总和
是簇内数据点的总和
纯度:
簇内包含单个类对象的另外一种度量。簇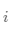 的纯度为
的纯度为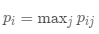 ,而聚类总纯度为:
,而聚类总纯度为:
-------- End --------

精选资料
回复关键词,获取对应的资料:
| 关键词 | 资料名称 |
|---|---|
| 600 | 《Python知识手册》 |
| md | 《Markdown速查表》 |
| time | 《Python时间使用指南》 |
| str | 《Python字符串速查表》 |
| pip | 《Python:Pip速查表》 |
| style | 《Pandas表格样式配置指南》 |
| mat | 《Matplotlib入门100个案例》 |
| px | 《Plotly Express可视化指南》 |
精选视频
可视化: Plotly Express
财经: Plotly在投资领域的应用 | 绘制K线图表
排序算法: 汇总 | 冒泡排序 | 选择排序 | 快速排序 | 归并排序 | 堆排序 | 插入排序 | 希尔排序 | 计数排序 | 桶排序 | 基数排序


