
- 1《特别推荐》10套精美的免费网站后台管理系统模板_前端 好看的后台网页demo
- 21.JavaEE进阶篇 - 为什么要学习SpringBoot呢?
- 3闲聊机器人之Seq2Seq模型的原理_seq2seq模型原理
- 4BERT实战(1):使用DistilBERT作为词嵌入进行文本情感分类,与其它词向量(FastText,Word2vec,Glove)进行对比
- 5NLP-文本向量化:Word Embedding 一般步骤【字符串->分词->词汇序列化->词汇向量化】
- 6本地部署Gemma-7b_gemma 7b
- 7max31865模块 PT100测温 PT1000测温 接线说明要点说明 使用说明 程序 单片机_max31865中文手册
- 8pytorch学习(4)——图片变换Transforms使用_transform函数输入一个图像产生几个图像
- 9c语言飞机大战
- 10NLP-python-马尔科夫链(markov)-文本句子生成器实现_markov模型处理文字
Image Segmentation Using Deep Learning: A Survey 论文精读
赞
踩
Image Segmentation Using Deep Learning: A Survey
Abstract
Image segmentation is a key topic in image processing and computer vision with applications(应用) such as scene understanding(场景理解), medical image analysis(医学图像分析), robotic perception(机器人感知), video surveillance(视频监视), augmented reality(AR), and image compression(图像理解), among many others. Various algorithms for image segmentation have been developed in the literature(文献). Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of(大量的) works aimed at developing image segmentation approaches using deep learning models. In this survey(综述), we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum(范围) of pioneering works(开创性工作) for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks(全卷积像素标签网络), encoder-decoder architectures(编码-解码结构), multi-scale and pyramid based approaches(基于金字塔和多尺度方法), recurrent networks(循环网络), visual attention models(注意力机制moxing), and generative models in adversarial settings(生成式对抗网络的设置). We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.
图像分割在图像处理和计算机视觉中扮演着关键的角色,在许多应用中发挥着重要的作用,例如: 场景理解、医学图像分析、机器人感知、视频监视、AR和图像理解等领域。在众多文献中已经提出了各种各样的图像分割算法。最近,由于深度学习模型在广泛的视觉应用中的成功,已有大量的工作致力于使用深度学习模型优化图像分割方法。在这篇综述中,我们在撰写时对文献进行了全面的回顾,这些文献涵盖了广泛的语义和实例分割的开创性工作,包括全卷积像素标签网络、编码-解码(encoder-decoder)结构、基于金字塔和多尺度方法、循环网络、视觉注意力模型、·生成式对抗网络的设置。我们研究了这些深度学习模型的相似性、优点和挑战,使用最广泛的数据集进行测试,得出其性能表现,并讨论这领域中在未来有发展前途的方向。
Index Terms—Image segmentation, deep learning, convolutional neural networks, encoder-decoder models, recurrent models, generative models, semantic segmentation, instance segmentation, medical image segmentation.
1 Introduction
IMAGE segmentation is an essential component in many visual understanding systems. It involves partitioning(part 分隔) images (or video frames) into multiple segments or objects [1]. Segmentation plays a central role in a broad range of applications [2], including medical image analysis (e.g., tumor肿瘤 boundary边界 extraction提取 and measurement测量,计算 of tissue volumes), autonomous vehicles (e.g., navigable可通行的 surface and pedestrian行人 detection检测), video surveillance, and augmented reality to count a few. Numerous image segmentation algorithms have been developed in the literature, from the earliest methods(最简单的,早期的), such as thresholding(阈值计算) [3], histogram-based bundling, regiongrowing (基于直方图的边缘检测、区域增长)[4], k-means clustering(k-means聚类) [5], watersheds(分水岭算法) [6], to more advanced algorithms(先进算法) such as active contours(动态轮廓) [7], graph cuts(图切割) [8], conditional and Markov random fields(条件和马尔科夫随机场) [9], and sparsitybased [10]- [11] methods(基于稀少量方法). Over the past few years, however, deep learning (DL) models have yielded a new generation of image segmentation models with remarkable performance improvements — often achieving the highest accuracy rates on popular benchmarks(现有的基准) — resulting in a paradigm shift in the field. For example, Figure 1 presents image segmentation outputs of a popular deep learning model, DeepLabv3 [12].
图像分割在众多视觉理解系统中是一个必不可少的任务。其涉及将图像或视频分割成多个区域部分或物体。在许多应用中分割扮演着重要的角色,包括医学图像分析(例如肿瘤边界提取和病变组织体积测量)、自动驾驶(表面可航性和行人检测)、视频监视、AR。文献中已经提出了大量的图像分割算法,从最早期的方法,例如阈值计算(thresholding)、基于直方图的边缘检测、区域增长(region-growing)、k-means聚类、分水岭算法等;再到更多改进后的算法,例如动态轮廓(active contours)、图切割、条件和马尔科夫随机场(conditional and Markov random fields)、基于稀少量方法(sparsity-based)。在过去的几年,深度学习网络催生出新一代的图像分割模型,其有更显著的性能提升,经常在现有的基准上达到最高的准确率,因此很多人认为此领域迎来了新的时代。例如,图1展示了性能优秀的深度学习模型DeepLabv3的图像分割结果。

Fig. 1. Segmentation results of DeepLabV3 [12] on sample images.
图1:模型DeepLabv3的图像分割结果样例图片
Image segmentation can be formulated(归结) as a classification problem of pixels(像素级) with semantic labels (semantic segmentation) or partitioning of individual objects (instance segmentation). Semantic segmentation performs(标记) pixel-level labeling with a set of object categories (e.g., human, car, tree, sky) for all image pixels, thus it is generally a harder undertaking than image classification, which predicts a single label for the entire image. Instance segmentation(实例分割) extends semantic segmentation scope further by detecting and delineating each object of interest in the image (e.g., partitioning of individual persons).
图像分割可以归结于具有语义标签(语义分割)或单个对象分区(实例分割)的像素级分类问题。语义分割要在整个图像像素中标注出一系列物体类别(例如人类、车、树、天空)的像素级的标签,因此语义分割一般来说比图像分类要更加困难,图像分类只需要为整个图像预测出单个的标签。实例分割比语义分割的范围更广泛,它需要进一步地在图像中识别与勾勒出每个感兴趣的图像(例如分割出每个独立的人)。
Our survey covers the most recent literature in image segmentation and discusses more than a hundred deep learning-based segmentation methods proposed until 2019. We provide a comprehensive review and insights on different aspects of these methods, including the training data, the choice of network architectures, loss functions, training strategies, and their key contributions. We present a comparative summary of the performance of the reviewed methods and discuss several challenges and potential future directions for deep learning-based image segmentation models.
我们的综述涵盖了图像分割领域中最新的文献,并讨论了在2019年之前提出的上百个基于深度学习的分割方法。我们对这些方法在不同角度提供了一个全面的视角,包括其训练数据、网络结构的选择、损失函数、训练策略和它们的关键贡献。我们对这些方法的性能做一个比较性总结,并讨论基于深度学习的图像分割模型的一些挑战和未来有潜力的方向。
We group deep learning-based works into the following categories based on their main technical contributions:
我们根据基于深度学习方法的主要技术贡献,将其分为如下几类:
1) Fully convolutional networks 全卷积网络
2) Convolutional models with graphical models 具有图形模型的卷积模型
3) Encoder-decoder based models 基于编码器-解码器模型
4) Multi-scale and pyramid network based models 基于多尺度与金字塔网络模型
5) R-CNN based models (for instance segmentation) 用于实例分割的R-CNN模型
6) Dilated convolutional models and DeepLab family 空洞卷积模型和Deeplab系列
7) Recurrent neural network based models 基于循环神经网络的模型
8) Attention-based models 注意力机制模型
9) Generative models and adversarial training 生成模型和对抗式训练
10) Convolutional models with active contour models 具有动态轮廓的卷积模型
11) Other models其他模型
Some the key contributions of this survey paper can be summarized as follows:
本调查论文的一些主要贡献可总结如下:
◎ This survey covers the contemporary literature with respect to segmentation problem, and overviews more than 100 segmentation algorithms proposed till 2019, grouped into 10 categories.
本调查涵盖了当代有关分割问题的文献,并概述了截至2019年提出的100多种分割算法,分为10类。
◎ We provide a comprehensive review and an insightful analysis of different aspects of segmentation algorithms using deep learning, including the training data, the choice of network architectures, loss functions, training strategies, and their key contributions.
我们对使用深度学习的分割算法的不同方面进行了全面的回顾和深入的分析,包括训练数据,网络架构的选择,损失函数、训练策略及其关键贡献。
◎ We provide an overview of around 20 popular image segmentation datasets, grouped into 2D, 2.5D (RGB- D), and 3D images.
我们提供了大约20个流行的图像分割数据集的概述,分为2D、2.5D(RGB-D)和3D图像。
◎ We provide a comparative(比较的 compare-comparative) summary of the properties(属性) and performance(性能) of the reviewed methods for segmentation purposes, on popular benchmarks(基准).
我们在流行的基准上提供了一个关于分割方法的属性和性能的比较总结。
◎ We provide several challenges and potential(潜在的) future directions for deep learning-based image segmentation.
我们为基于深度学习的图像分割提供了几个挑战和潜在的未来方向。
The remainder of this survey is organized as follows: Section 2 provides an overview of popular deep neural network architectures that serve as the backbone(支柱) of many modern segmentation algorithms. Section 3 provides a comprehensive overview of the most significant state-of-the- art deep learning based segmentation models, more than 100 till 2020. We also discuss their strengths and contributions over previous works here. Section 4 reviews some of the most popular image segmentation datasets and their characteristics. Section 5.1 reviews popular metrics for evaluating deep-learning-based segmentation models. In Section 5.2, we report the quantitative results and experimental performance of these models. In Section 6, we discuss the main challenges and future directions for deep learning-based segmentation methods. Finally, we present our conclusions in Section 7.
这篇论文的余下部分结构如下所示:Section 2展示了当前流行的深度神经网络结构的概述,这些网络结构是许多现代分割算法的支柱(backbone);Section 3全面地概括了2019年前上百个最重要的基于深度学习的分割模型,同时讨论它们较于以往研究的优势与贡献;Section 4说明了一些流行的图像分割数据集和其特征;Section 5.1介绍了衡量深度学习语义分割模型的指标,Section 5.2 我们展示了这些模型的定量结果和实验性能;Section 6讨论了关于深度学习分割算法的主要挑战和未来的方向。最后,我们在Section 7展示我们的结论。
2 Overview of Deep Neural Networks
This section provides an overview of some of the most prominent(重要的,杰出的) deep learning architectures used by the computer vision community, including convolutional neural networks (CNNs) [13], recurrent neural networks (RNNs) and long short term memory (LSTM) [14], encoder-decoders [15], and generative adversarial networks (GANs) [16]. With the popularity of deep learning in recent years, several other deep neural architectures have been proposed, such as transformers, capsule networks, gated recurrent units, spatial transformer networks, etc., which will not be covered here.
在这个部分主要提供了一些用于计算机视觉的著名深度学习结构的简要概述,包括卷积神经网络(convolutional neural networks, CNNs)、循环神经网络(recurrent neural networks, RNNs)和长短期记忆网络(long short term memory, LSTM)、编码器-解码器(encoder-decoder)和生成式对抗网络(generative adversarial networks, GANs)。近些年来随着深度学习的流行,学术界又提出了其他更多的深度神经结构,例如: transformer、胶囊网络(capsule networks)、门控循环单元(gated recurrent units)、空间变换网络(spatial transformer networks)等,这些这里不包括。
It is worth mentioning that in some cases the DL-models can be trained from scratch on new applications/datasets (assuming a sufficient(足够的) quantity of labeled training data), but in many cases there are not enough labeled data available to train a model from scratch and one can use transfer learning to tackle(解决) this problem. In transfer learning, a model trained on one task is re-purposed on another (related) task, usually by some adaptation process toward the new task. For example, one can imagine adapting an image classification model trained on ImageNet to a different task, such as texture classification, or face recognition. In image segmentation case, many people use a model trained on ImageNet (a larger dataset than most of image segmentation datasets), as the encoder part of the network, and re-train their model from those initial weights. The assumption here is that those pre-trained models should be able to capture the semantic information of the image required for segmentation, and therefore enabling them to train the model with less labeled samples.
值得一提的是,在某些情况下,深度学习模型(DL-models)可以在新的应用程序/数据集上从头开始进行训练(假设有足够数量的标记训练数据),但在许多情况下确实有没有足够的标记数据可以从头开始训练一个模型,我们可以使用迁移学习(transfer learning)来解决这个问题。在迁移学习中,在一个任务上训练的模型被重新用在另一个任务上(相关的)任务,通常是通过对新任务的一些适应过程。例如,我们可以想象,用ImageNet训练的图像分类模型来适应不同的任务,比如纹理克隆人脸识别。在图像分割的情况下,许多人使用在ImageNet(比大多数图像分割数据集更大的数据集)上训练的模型,如网络的编码器部分,并从这些初始权重重新训练他们的模型。这里的假设是,那些预先训练过的模型应该能够捕获所需用于分割的图片的语义信息,因此使他们能够用更少的标记样本来训练模型。
2.1 Convolutional Neural Networks (CNNs)
CNNs are among the most successful and widely used architectures in the deep learning community(领域), especially for computer vision tasks. CNNs were initially proposed by Fukushima in his seminal paper on the “Neocognitron" [17], based on the hierarchical receptive field model of the visual cortex proposed by Hubel and Wiesel. Subsequently(随后), Waibel et al. [18] introduced(引入) CNNs with weights shared among temporal receptive fields and backpropagation training for phoneme recognition, and LeCun et al. [13] developed a CNN architecture for document recognition (Figure 2).
CNNs是在深度学习领域内最为成功和用途最为广泛的结构之一,特别是在计算机视觉任务中更为重要。CNNs由Fukushima在他开创性的论文首先提出,是基于Hubel和Wiesel提出的视觉皮层的层次感应域原理。随后Waibel等人引入了具有在时间感应域之间共享权重和反向传播训练的CNNs用于语音识别。LeCun(CNN之父、“深度学习三巨头”之一、2019图灵奖得主之一)提出了一种用于文本识别的CNN结构,如图2所示:

Fig. 2. Architecture of convolutional neural networks. From [13].
图2:卷积神经网络的结构
CNNs mainly consist of three type of layers:
- convolutional layers, where a kernel (or filter) of weights is convolved in order to extract features;
- nonlinear layers, which apply an activation function on feature maps (usually elementwise) in order to enable the modeling of non-linear functions by the network; and
- pooling layers, which replace a small neighborhood of a feature map with some statistical information (mean, max, etc.) about the neighborhood and reduce spatial resolution.
The units in layers are locally connected; that is, each unit receives weighted inputs from a small neighborhood, known as the receptive field(感受域), of units in the previous layer. By stacking layers(堆叠神经网络) to form multi-resolution pyramids(多分辨率金字塔), the higher-level layers learn features from increasingly wider receptive fields. The main computational advantage of CNNs is that all the receptive fields in a layer share weights, resulting in a significantly smaller number of parameters than fully-connected neural networks. Some of the most well-known CNN architectures include: AlexNet [19], VGGNet [20], ResNet [21], GoogLeNet [22], MobileNet [23], and DenseNet [24].
CNN重要由以下三种网络层结构构成:
i)卷积层(convolutional layers),其中,为了可以进行特征抽取,对权重内核(kernel, 或过滤器filter)进行卷积操作。
ii)非线性层(nonliner layers),其在特征映射上使用激活函数(activation function),以便通过网络来增强模型的非线性能力。
iii)池化层(pooling layers),其使用一些关于邻域的统计信息数值(如均值、最大值等)代替特征映射的一个小邻域,并降低空间分辨率。
这些层内的单元相互连接,每个单元从其前一层的一个小邻域中接受权重输入,我们将其称之为感受域(视野)。通过堆叠神经网络层来形成多分辨率金字塔,较高层次的神经网络层从更广泛的感受野中学习特征。CNNs其主要的计算优势是在同一层中的所有感受野都共享权重,因此相较于全连接神经网络(fully-connected neural networks),CNNs的参数数量更少。一些著名的CNN结构有: AlexNet、VGGNet、ResNet、GoogleNet、MobileNet和DenseNet等。
2.2 Recurrent Neural Networks (RNNs) and the LSTM
RNNs [25] are widely used to process sequential data(处理线性->序列型数据), such as speech, text, videos, and time-series, where data at any given time/position depends on previously encountered data(相关数据). At each time-stamp(时间戳) the model collects the input from the current time Xi and the hidden state from the previous step hi-1, and outputs a target value and a new hidden state (Figure 3).
RNNs广泛用于处理序列型数据,例如语音、文本、视频和时间序列相关的问题,这些数据在任何给定的时间/位置上取决于以前相关的数据。在每个时间戳内,模型从当前时间Xi和前一步骤的隐层状态hi-1中得到输入数据,输出目标值和新的隐层状态(如图3所示)。
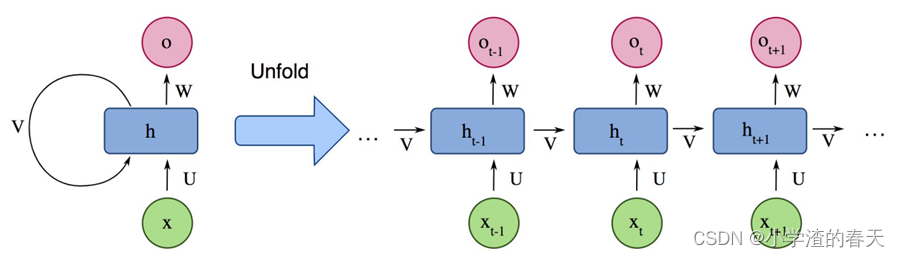
Fig. 3. Architecture of a simple recurrent neural network.
图3:一个简单的循环神经网络结构
RNNs are typically problematic(造成困难的) with long sequences(长序列) as they cannot capture long-term dependencies(长期依赖关系) in many real-world applications (although they exhibit(展出,显示出) no theoretical limitations in this regard(在这一点上)) and often suffer from gradient(梯度) vanishing(弥散) or exploding(爆炸) problems. However, a type of RNNs called Long Short Term Memory (LSTM) [14] is designed to avoid these issues. The LSTM architecture (Figure 4) includes three gates (input gate, output gate, forget gate), which regulate the flow of information into and out from a memory cell, which stores values over arbitrary time intervals.
在处理长序列数据时,RNNs通常存在一些问题,因为RNNs不能获取许多现实世界应用中的长期的依赖关系(即使他们在这方面的理论没有显示出其局限性),同时RNNs还经常会出现梯度弥散或爆炸等问题。因此,研究学者设计出了一种称之为长短期记忆网络(Long Short Term Memory, LSTM)的RNN网络,来解决以上问题。LSTM的结构如图四所示,其包含了三种门控: 输入门、输出门、遗忘门(input gate, output gate, forget gate),这些门控机制调节信息流进出记忆细胞(memory cell),记忆细胞以一定量的时间间隔对值进行存储。

Fig. 4. Architecture of a standard LSTM module. Courtesy of Karpathy
图4:标准LSTM模型结构
2.3 Encoder-Decoder and Auto-Encoder Models
Encoder-Decoder models are a family of(一系列) models which learn to map data-points from an input domain(域) to an output domain via a two-stage network: The encoder, represented by an encoding function z=f(x), compresses(压缩) the input into a latent-space(隐空间、潜在空间) representation; the decoder, y=gz, aims to predict the output from the latent space representation [15], [26]. The latent representation here essentially refers to a feature (vector) representation, which is able to capture the underlying(根本的,潜在的) semantic information of the input that is useful for predicting the output. These models are extremely popular in image-to-image translation problems, as well as for sequence-to-sequence models in NLP. Figure 5 illustrates(描述) the block-diagram of a simple encoder-decoder model. These models are usually trained by minimizing the reconstruction loss Ly,y, which measures the differences between the ground-truth output y and the subsequent reconstruction y. The output here could be an enhanced version of the image (such as in image de-blurring, or super-resolution), or a segmentation map. Auto-encoders are special case of encoder-decoder models in which the input and output are the same.
编码器-解码器模型是一个网络系列,其通过两阶段网络学习将数据点从输入域映射到输出域: 编码器由编码函数z=f(x)所表示,将输入压缩为潜在空间(latent-space)表示;解码器由函数y=gz表示,其目的是为了从潜在空间表示中预测出输出。这里的潜在表示在本质上是指特征(向量)表示,能够从输入中捕捉潜在的语义信息,有助于对输出的预测。这些模型在图像-图像翻译问题和NLP的序列模型问题中非常流行。图5描述了编码器-解码器模型的一个简单样例。这些模型通常以最小化重构函数(reconstruction loss)Ly,y来进行训练,重构损失函数描述了真值输出y和重构序列y之间的差异。这里的输出也可以是图像的增强版本(例如去模糊的图像或者超像素),或是语义映射。
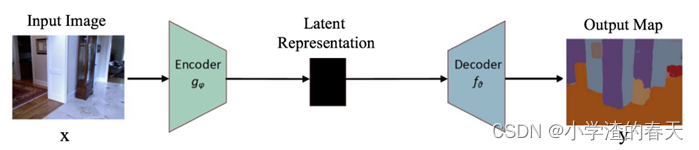
Fig. 5. The architecture of a simple encoder-decoder model.
图5:一个简单的编码-解码模型结构
2.4 Generative Adversarial Networks (GANs)
GANs are a newer family of deep learning models [16]. They consist of two networks—a generator and a discriminator (Figure 6). The generator network in the conventional GAN learns a mapping from noise z (with a prior distribution) to a target distribution y, which is similar to the “real” samples. The discriminator network D attempts to distinguish the generated samples (“fakes”)from the “real” ones. The GAN loss function may be written as
We can regard the GAN as a minimax game between G and D, where D is trying to minimize its classification error in distinguishing fake samples from real ones, hence maximizing the loss function, and G is trying to maximize the discriminator network’ s error, hence minimizing the loss function. After training the model, the trained generator model would be . In practice(事实上), this function may not provide enough gradient for effectively training G, specially initially (when D can easily discriminate fake samples from real ones). Instead of minimizing
, a possible solution is to train it to maximize
.
GANs是一种更新的深度学习模型体系。如图6所示,GANs包含两种网络: 生成器(generator)和判别器(discriminator)。在传统的GANs中,生成网络 学习从具有先验分布的噪声数据z到目标分布y的映射,类似于“真实”样本。判别器网络D从真实样本中区分出那些被生成的假样本。GANs的损失函数写为:
我们可以将GAN视为求G和D之间的极值策略,其中D试图去最小化从真实样例中区分假样本的分类误差,从而最大化损失函数;G最大化判别器网络的误差,进而最小化损失函数。在对模型进行训练之后,已训练过的生成器模型将成为。事实上,此损失函数并未提供足够的梯度来有效地训练G,尤其是初始化。除了最小化
,一种可行的解决方法是最大化
Since the invention of GANs, researchers have endeavored(努力,尽力,试图) to improve/modify GANs several ways. For example, Radford et al. [27] proposed(提出) a convolutional GAN model, which works better than fully-connected networks when used for image generation. Mirza [28] proposed a conditional GAN model that can generate images conditioned on class labels, which enables one to generate samples with specified labels. Arjovsky et al. [29] proposed a new loss function based on the Wasserstein (a.k.a. earth mover's distance) to better estimate the distance for cases in which the distribution of real and generated samples are non-overlapping (hence the Kullback-Leiber divergence is not a good measure of the distance). For additional works, we refer the reader to [30].
自从GANs被提出以来,研究学者试图从不同方面提升或改进GANs。例如,Radford等人提出了一种卷积GAN模型,当用于图像生成时这种模型比全连接网络的效果更好。Mirza提出了条件GAN模型,这种模型可以生成基于类标签的图像,即生成指定标签的样本。Arjovsky等人提出了一种基于Wasserstein距离的新型损失函数,可以更好的去估计实际样本和生成样本的分布在不重叠情况下的距离。
3 DL-Based Image Segmentation Models
This section provides a detailed review of more than a hundred deep learning-based segmentation methods proposed until 2019, grouped into 10 categories (based on their model architecture). It is worth mentioning that there are some pieces that are common among many of these works, such as having encoder and decoder parts(编码和解码部分), skip-connections(跳跃连接), multi-scale analysis(多尺度分析), and more recently the use of dilated convolution(空洞卷积). Because of this, it is difficult to mention the unique contributions of each work, but easier to group them based on their underlying architectural contribution over previous works. Besides the architectural categorization of these models, one can also group them based on the segmentation goal into: semantic, instance, panoptic(全景), and depth segmentation categories. But due to the big difference in terms of volume of work in those tasks, we decided to follow the architectural grouping.
本节详细回顾了截至2019年提出的一百多种基于深度学习的分割方法,分为10类(基于他们的模型架构)。值得一提的是,在这些工作中,有一些是常见的,例如有编码器和解码器部分,跳跃连接,多尺度分析,以及最近使用的空洞卷积。正因为如此,很难提及每个作品的独特贡献,但更容易根据它们在先前作品中的底层架构贡献对它们进行分组。除了这些模型的架构分类之外,还可以根据分割目标将它们分组为:语义、实例、全景和深度分割类别。但是由于这些任务在工作量方面的巨大差异,我们决定遵循架构分组。
3.1 Fully Convolutional Networks
Long et al. [31] proposed one of the first deep learning works for semantic image segmentation, using a fully convolutional network (FCN). An FCN (Figure 7) includes only convolutional layers, which enables it to take an image of arbitrary size and produce a segmentation map of the same size. The authors modified existing CNN architectures, such as VGG16 and GoogLeNet, to manage non-fixed sized input and output, by replacing all fully-connected layers with the fully-convolutional layers. As a result, the model outputs a spatial segmentation map instead of classification scores.
Long等人提出了第一个用于语义图像分割的深度学习工作,使用全卷积网络( FCN )。一个FCN (图7 )只包含卷积层,这使得它能够输入任意大小的图像并产生相同大小的分割图。作者修改了现有的CNN架构,如VGG16和GoogLeNet,通过将所有全连接层替换为全卷积层来管理非固定大小的输入和输出。因此,模型输出一个空间分割映射而不是分类得分。
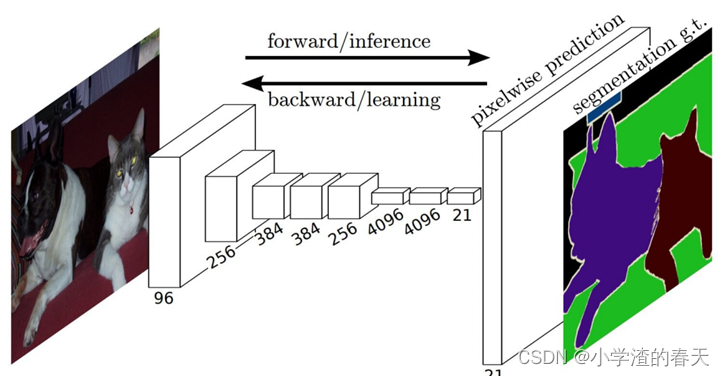
Fig. 7. A fully convolutional image segmentation network. The FCN learns to make dense, pixel-wise predictions. From [31].
图7 .一个全卷积图像分割网络。FCN学习进行密度、像素级的预测
Through the use of skip connections in which feature maps from the final layers of the model are up-sampled and fused with feature maps of earlier layers (Figure 8), the model combines semantic information (from deep, coarse layers) and appearance information (from shallow, fine layers) in order to produce accurate and detailed segmentations. The model was tested on PASCAL VOC, NYUDv2, and SIFT Flow, and achieved state-of-the-art segmentation performance.
通过使用跳跃连接,将模型最终层的特征图进行上采样,并与早期层的特征图进行融合(图8 ),模型结合了语义信息(从深层,粗糙的层)和外观信息(从浅的,精细的层),以产生准确和详细的分割。该模型在PASCAL VOC、NYUDv2和SIFT Flow上进行了测试,取得了最先进的分割性能。
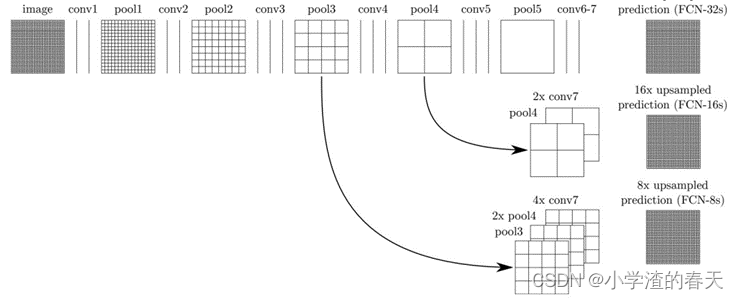
Fig. 8. Skip connections combine coarse, high-level information and fine, low-level information.
图8 .跳跃连接结合了粗粒度、高层次的信息和细粒度、低层次的信息。
This work is considered a milestone(里程碑) in image segmentation, demonstrating(示范; 论证; 演示;) that deep networks can be trained for semantic segmentation in an end-to-end manner(方式) on variable-sized(大小可变的) images. However, despite its popularity and effectiveness, the conventional FCN model has some limitations—it is not fast enough for real-time inference(实时推断), it does not take into account the global context information in an efficient way, and it is not easily transferable to 3D images. Several efforts have attempted to overcome some of the limitations of the FCN.
这项工作被认为是图像分割中的一个里程碑,表明可以在可变大小的图像上以端到端的方式训练深度网络进行语义分割。然而,尽管它的流行和有效性,传统的FCN模型有一些限制——它不够快的实时推断,它没有考虑到全球上下文信息的有效方式,并不容易转移到3D图像。一些努力试图克服FCN的一些局限性。
For instance, Liu et al. [32] proposed a model called ParseNet, to address an issue with FCN— ignoring global context information(全局上下文信息). ParseNet adds global context to FCNs by using the average feature for a layer to augment the features at each location. The feature map for a layer is pooled over the whole image resulting in a context vector. This context vector is normalized and unpooled to produce new feature maps of the same size as the initial ones. These feature maps are then concatenated. In a nutshell, ParseNet is an FCN with the described module replacing the convolutional layers (Figure 9).
例如,Liu等[ 32 ]提出了一种称为ParseNet的模型,以解决FCN忽略全局上下文信息的问题。ParseNet通过使用一个层的平均特性来增加每个位置的特性,从而将全局上下文添加到FCN中。一个图层的特征图被池化在整个图像上,形成一个上下文向量。此上下文向量被规范化和取消池化,以生成与初始特征图相同大小的新特征图。然后将这些特征图进行拼接。简而言之,ParseNet是一个FCN,其描述的模块取代了卷积层(图9 )。
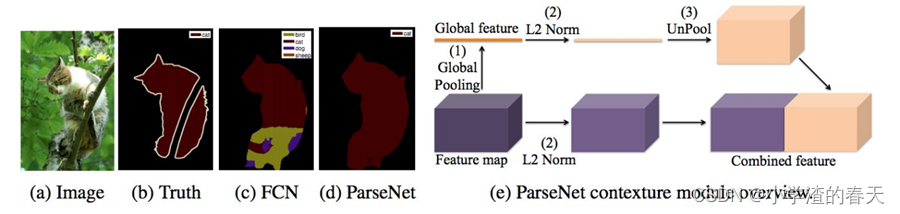
Fig. 9. ParseNet, showing the use of extra global context to produce smoother segmentation (d) than an FCN (c).
图9。ParseNet,展示了使用额外的全局上下文来产生比FCN ( c )更平滑的分割( d )。
FCNs have been applied to a variety of segmentation problems, such as brain tumor segmentation [33], instance-aware semantic segmentation [34], skin lesion segmentation [35], and iris segmentation [36].
FCNs已被应用于多种分割问题,如脑肿瘤分割[ 33 ]、实例感知语义分割[ 34 ]、皮肤病变分割[ 35 ]、虹膜分割[ 36 ]等。
3.2 Convolutional Models With Graphical Models
As discussed, FCN ignores potentially useful scene-level semantic context. To integrate(集成) more context, several approaches incorporate(结合,混合) probabilistic(概率的,随机的) graphical models, such as Conditional Random Fields (CRFs) and Markov Random Field (MRFs), into DL architectures.
如前所述,FCN忽略了潜在有用的场景级语义上下文。为了集成更多的上下文,一些方法将概率图形模型(如条件随机场( CRFs )和马尔可夫随机场( MRFs ) )集成到DL体系结构中。
Chen et al. [37] proposed a semantic segmentation algorithm based on the combination of CNNs and fully connected CRFs(条件随机场) (Figure 10). They showed that responses from the final layer of deep CNNs are not sufficiently localized for accurate object segmentation (due to the invariance properties that make CNNs good for high level tasks such as classification). To overcome the poor localization property of deep CNNs, they combined the responses at the final CNN layer with a fully-connected CRF. They showed that their model is able to localize segment boundaries at a higher accuracy rate than it was possible with previous methods.
Chen等[ 37 ]提出了一种基于卷积神经网络和全连接条件随机场(CRFs)相结合的语义分割算法(图10 )。他们表明,来自深层CNNs的最后一层的响应对于准确的对象分割(由于具有不变性,使得卷积神经网络适用于分类等高层次任务)没有足够的定位。为了克服深度CNN较差的本地化特性,他们将最终CNN层的响应与完全连接的条件随机场结合起来。他们表明,他们的模型能够以比以前的方法更高的准确率定位段边界。
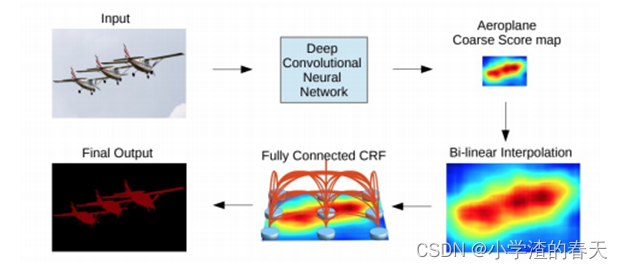
Fig. 10. A CNN+CRF model. The coarse score map of a CNN is upsampled via interpolated interpolation(插值), and fed to a fully-connected CRF to refine the segmentation result. From [37].
图10 .一个CNN+CRF模型。CNN的粗分数图通过插值进行上采样,并送入完全连接的CRF以改进分割结果。从[ 37 ]。
Schwing and Urtasun [38] proposed a fully-connected deep structured network for image segmentation. They presented a method that jointly(联合地) trains CNNs and fully- connected CRFs for semantic image segmentation, and achieved encouraging results on the challenging PASCAL VOC 2012 dataset. In [39], Zheng et al. proposed a similar semantic segmentation approach integrating CRF with CNN.
施温和Urtasun [ 38 ]提出了一种用于图像分割的全连接深度结构化网络。他们提出了一种联合训练CNN和全连接CRF用于语义图像分割的方法,并在具有挑战性的PASCAL VOC 2012数据集上取得了令人鼓舞的结果。在[ 39 ]中,Zheng等人提出了一种类似的融合CRF和CNN的语义分割方法。
In another relevant work, Lin et al. [40] proposed an efficient algorithm for semantic segmentation based on contextual deep CRFs. They explored “patch-patch” context (between image regions) and “patch-background" context to improve semantic segmentation through the use of contextual information.
在另一项相关工作中,Lin等人[ 40 ]提出了一种基于上下文深度CRFs(条件随机场)的高效语义分割算法。他们探索了“patch-patch”上下文(图像区域之间)和“patch-background”上下文,通过使用上下文信息来改进语义分割。
Liu et al. [41] proposed a semantic segmentation algorithm that incorporates rich information into MRFs, including high-order relations and mixture of label contexts. Unlike previous works that optimized MRFs using iterative algorithms, they proposed a CNN model, namely a Parsing Network, which enables deterministic end-to-end computation in a single forward pass.
Liu等人[ 41 ]提出了一种语义分割算法,将丰富的信息融入MRFs(马尔可夫随机场)中,包括高阶关系和标签上下文的混合。与以往使用迭代算法优化MRFs(马尔可夫随机场)的工作不同,他们提出了一个CNN模型,即一个解析网络,它可以在单个前向通道中实现确定性的端到端计算。
3.3 Encoder-Decoder Based Models
Another popular family of deep models for image segmentation is based on the convolutional encoder-decoder architecture. Most of the DL-based segmentation works use some kind of encoder-decoder models. We group these works into two categories, encoder-decoder models for general segmentation, and for medical image segmentation (to better distinguish between applications).
用于图像分割的另一个流行的深度模型家族是基于卷积编码器-解码器架构的。基于深度学习的分割工作大多使用某种编码器-解码器模型。我们将这些工作分为两类,用于一般分割的编码器-解码器模型和用于医学图像分割的(为了更好的区分应用)。
3.3.1 Encoder-Decoder Models for General Segmentation
Noh et al. [42] published an early paper on semantic segmentation based on deconvolution(反卷积) (a.k.a. transposed convolution). Their model (Figure 11) consists of two parts, an encoder using convolutional layers adopted(采用) from the VGG 16-layer network and a deconvolutional network that takes the feature vector as input and generates a map of pixel-wise class probabilities. The deconvolution network is composed of deconvolution and unpooling layers, which identify pixel-wise class labels and predict segmentation masks.
Noh等人[ 42 ]发表了一篇关于基于反卷积( a.k.a.转置卷积)的语义分割的早期论文。他们的模型(图11 )由两部分组成,一个使用来自VGG 16层网络的卷积层的编码器和,一个以特征向量为输入并生成像素级类别概率图的反卷积网络。反卷积网络由反卷积层和去池化层组成,它们识别像素级的类别标签并预测分割掩码。

Fig. 11. Deconvolutional semantic segmentation. Following a convolution network based on the VGG 16-layer net, is a multi-layer deconvolution network to generate the accurate segmentation map. From [42].
图11 .反卷积语义分割。在基于VGG 16层网络的卷积网络之后,是一个多层反卷积网络来生成精确的分割图。从[ 42 ]。
This network achieved promising performance on the PASCAL VOC 2012 dataset, and obtained the best accuracy (72.5%) among the methods trained with no external data at the time.
该网络在PASCAL VOC 2012数据集上取得了较好的性能,在当时没有外部数据训练的方法中获得了最好的准确率( 72.5 % )。
In another promising work known as SegNet, Badri Narayanan et al. [15] proposed a convolutional encoder-decoder architecture for image segmentation (Figure 12). Similar to the deconvolution network, the core trainable segmentation engine of SegNet consists of an encoder network, which is topologically(在拓扑上) identical to the 13 convolutional layers in the VGG16 network, and a corresponding decoder network followed by a pixel-wise classification layer. The main novelty(新颖) of SegNet is in the way the decoder upsamples its lower resolution(低分辨率) input feature map(s); specifically, it uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear up-sampling. This eliminates the need for learning to up-sample. The (sparse) up-sampled maps are then convolved with trainable filters to produce dense feature maps. SegNet is also significantly smaller in the number of trainable parameters than other competing architectures. A Bayesian version of SegNet was also proposed by the same authors to model the uncertainty inherent to the convolutional encoder-decoder network for scene segmentation [43].
在另一个被称为SegNet的有前途的工作中,Badri纳拉亚南等人[ 15 ]提出了一种用于图像分割的卷积编码器-解码器架构(图12 )。与反卷积网络类似,SegNet的核心可训练分割引擎由一个与VGG16网络中13个卷积层拓扑相同的编码器网络和一个对应的解码器网络以及一个像素级的分类层组成。SegNet的主要新颖之处在于解码器对其低分辨率输入特征图进行上采样;具体来说,它使用在对应编码器的最大池化步骤中计算的池化指标来执行非线性上采样。这消除了学习上采样的需要。然后将(稀疏的)上采样映射与可训练的滤波器进行卷积,以生成密集的特征映射。SegNet在可训练参数的数量上也明显少于其他竞争架构。同样的作者也提出了一个贝叶斯版本的SegNet来建模用于场景分割的卷积编码器-解码器网络所固有的不确定性[ 43 ]。
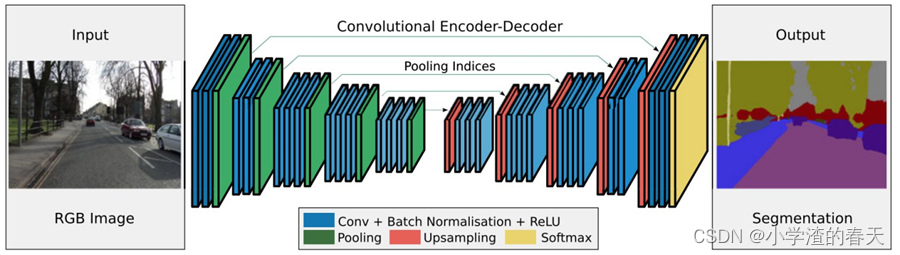
Fig. 12. SegNet has no fully-connected layers; hence, the model is fully convolutional. A decoder up-samples its input using the transferred pool indices from its encoder to produce a sparse feature map(s). From [15].
图12。SegNet没有全连接层;因此,该模型是全卷积的。解码器使用其编码器中传输的池索引对其输入进行上采样,以生成稀疏特征图。从[ 15 ]。
Another popular model in this category is the recently-developed segmentation network, high-resolution network (HRNet) [44] Figure 13. Other than recovering high-resolution representations as done in DeConvNet, SegNet, U-Net and V-Net, HRNet maintains high-resolution representations through the encoding process by connecting the high-to-low resolution convolution streams in parallel, and repeatedly exchanging the information across resolutions. Many of the more recent works on semantic segmentation use HRNet as the backbone by exploiting contextual models, such as self-attention and its extensions.
另一种比较流行的模型是最近发展起来的分割网络,高分辨率网络( HRNet ) [ 44 ],如图13所示。除了恢复反卷积、SegNet、U-Net和V-Net中的高分辨率表示外,HRNet通过并行连接高、低分辨率卷积流,并在不同分辨率之间反复交换信息,通过编码过程保持高分辨率表示。最近关于语义分割的许多工作使用HRNet作为骨干,利用上下文模型,如自注意力及其扩展。

Fig. 13. Illustrating the HRNet architecture. It consists of parallel high-to-low resolution convolution streams with repeated information exchange across multi-resolution steams. There are four stages. The 1st stage consists of high-resolution convolutions. The 2nd (3rd, 4th) stage repeats two-resolution (three-resolution, four-resolution) blocks. From [44].
图13。说明Hrnet架构。它由并行的高-低分辨率卷积流组成,通过多分辨率蒸汽进行反复的信息交换。有四个阶段。第1阶段由高分辨率卷积组成。第2个(第3、4次)阶段重复双分辨率(三分辨率,四分辨率)块。从[ 44 ]。
Several other works adopt transposed convolutions, or encoder-decoders for image segmentation, such as Stacked Deconvolutional Network (SDN) [45], Linknet [46], W-Net [47], and locality-sensitive deconvolution networks for RGB-D segmentation [48]. One limitation of Encoder-Decoder based models is the loss of fine-grained information of the image, due to the loss of high-resolution representations through the encoding process. This issue is however addressed in some of the recent architectures such as HR-Net.
其他一些工作采用转置卷积或编码器-解码器进行图像分割,如堆叠反卷积网络( SDN ) [ 45 ],Linknet [ 46 ],W-Net [ 47 ]和局部敏感的反卷积网络用于RGB - D分割[ 48 ]。基于Encoder - Decoder的模型的一个局限性是由于编码过程丢失了高分辨率的表示,导致图像的细粒度信息丢失。但这一问题在近期出现的一些架构如HR-Net中都有涉及。
3.3.2 Encoder-Decoder Models for Medical and Biomedical Image Segmentation
There are several models initially developed for medical/biomedical image segmentation, which are inspired by FCNs and encoder-decoder models. U-Net [49], and V-Net [50], are two well-known such architectures, which are now also being used outside the medical domain.
最初为医学/生物医学图像分割开发了几种模型,其灵感来自FCN和编码器-解码器模型。U-Net [ 49 ]和V - Net [ 50 ]是两个著名的此类架构,现在也被用于医学领域之外。
Ronneberger et al. [49] proposed the U-Net for segmenting biological microscopy images. Their network and training strategy relies on the use of data augmentation to learn from the very few annotated images effectively. The U-Net architecture (Figure 14) comprises two parts, a contracting path to capture context, and a symmetric expanding path that enables precise localization. The down-sampling or contracting part has a FCN-like architecture that extracts features with 3 x 3 convolutions. The up-sampling or expanding part uses up-convolution (or deconvolution), reducing the number of feature maps while increasing their dimensions. Feature maps from the down-sampling part of the network are copied to the up-sampling part to avoid losing pattern information. Finally, a 1 x 1 convolution processes the feature maps to generate a segmentation map that categorizes each pixel of the input image. U-Net was trained on 30 transmitted light microscopy images, and it won the ISBI cell tracking challenge 2015 by a large margin.
龙内贝格尔等人[ 49 ]提出了用于分割生物显微图像的U-Net。他们的网络和训练策略依赖于使用数据增强来有效地从很少的注释图像中学习。U - Net架构(图14 )包括两部分,一个用于捕获上下文的收缩路径和一个能够实现精确定位的对称扩展路径。下采样或收缩部分具有类似FCN的架构,使用3 × 3卷积提取特征。上采样或扩展部分使用上卷积(或反卷积),在增加特征图维度的同时减少特征图的数量。来自网络下采样部分的特征图被复制到上采样部分,以避免丢失模式信息。最后,1 × 1卷积处理特征图,生成对输入图像的每个像素进行分类的分割图。U - Net接受了30幅透射光显微镜图像的训练,并以很大的优势赢得了2015年ISBI细胞跟踪挑战。

Fig. 14. The U-net model. The blue boxes denote feature map blocks with their indicated shapes. From [49].
图. 14 . U - Net模型。蓝色方框表示具有指定形状的特征映射块。从[ 49 ]。
Various extensions of U-Net have been developed for different kinds of images. For example, Cicek [51] proposed a U-Net architecture for 3D images. Zhou et al. [52] developed a nested U-Net architecture. U-Net has also been applied to various other problems. For example, Zhang et al. [53] developed a road segmentation/extraction algorithm based on U-Net.
为不同类型的图像开发了U-Net的各种扩展。例如,Cicek [ 51 ]提出了一种面向3D图像的U - Net架构。Zhou等人[ 52 ]开发了一个嵌套的U-Net体系结构。U - Net也被应用到其他各种问题中。例如,Zhang等人[ 53 ]开发了一种基于U - Net的道路分割/提取算法。
V-Net is another well-known, FCN-based model, which was proposed by Milletari et al. [50] for 3D medical image segmentation. For model training, they introduced a new objective function based on Dice coefficient, enabling the model to deal with situations in which there is a strong imbalance between the number of voxels in the foreground and background. The network was trained end-to-end on MRI volumes of prostate, and learns to predict segmentation for the whole volume at once. Some of the other relevant works on medical image segmentation includes Progressive Dense V-net (PDV-Net) et al. for fast and automatic segmentation of pulmonary lobes from chest CT images, and the 3D-CNN encoder for lesion segmentation [54].
V - Net是另一个著名的基于FCN的模型,由米莱塔里等人[ 50 ]提出,用于三维医学图像分割。在模型训练方面,他们引入了一种新的基于Dice系数的目标函数,使模型能够处理前景和背景中体素数量之间存在较强平衡的情况。该网络在前列腺MRI体积上进行端到端的训练,并学习一次性预测整个体积的分割。其他一些关于医学图像分割的相关工作包括用于从胸部CT图像中快速自动分割肺叶的Progressive Dense V-net ( PDV-Net )等,以及用于病灶分割的3D - CNN编码器[ 54 ]。
3.4 Multi-Scale and Pyramid Network Based Models
Multi-scale analysis, a rather old idea in image processing, has been deployed in various neural network architectures. One of the most prominent models of this sort is the Feature Pyramid Network (FPN) proposed by Lin et al. [55], which was developed mainly for object detection but was then also applied to segmentation. The inherent multi-scale, pyramidal hierarchy of deep CNNs was used to construct feature pyramids with marginal extra cost. To merge low and high resolution features, the FPN is composed of a bottom-up pathway, a top-down pathway and lateral connections. The concatenated feature maps are then processed by a 3 x 3 convolution to produce the output of each stage. Finally, each stage of the top-down pathway generates a prediction to detect an object. For image segmentation, the authors use two multi-layer perceptrons (MLPs) to generate the masks.
多尺度分析是图像处理中一个比较古老的思想,已经被部署在各种神经网络架构中。这类模型中最著名的是Lin等人[ 55 ]提出的特征金字塔网络( Feature Pyramid Network,FPN ),它主要是为目标检测而开发的,但后来也被应用于分割。深度CNN固有的多尺度、金字塔层级结构被用于构建边际额外成本的特征金字塔。为了融合低分辨率和高分辨率特征,FPN由自下而上的路径、自上而下的路径和横向连接组成。然后通过3 × 3卷积对级联后的特征图进行处理,产生每个阶段的输出。最后,自顶向下路径的每个阶段生成一个预测来检测一个对象。对于图像分割,作者使用两个多层感知器( MLP )来生成掩码。
Zhao et al. [56] developed the Pyramid Scene Parsing Network (PSPN), a multi-scale network to better learn the global context representation of a scene (Figure 15). Different patterns are extracted from the input image using a residual network (ResNet) as a feature extractor, with a dilated network. These feature maps are then fed into a pyramid pooling module to distinguish patterns of different scales. They are pooled at four different scales, each one corresponding to a pyramid level and processed by a 1 x 1 convolutional layer to reduce their dimensions. The outputs of the pyramid levels are up-sampled and concatenated with the initial feature maps to capture both local and global context information. Finally, a convolutional layer is used to generate the pixel-wise predictions.
Zhao等人[ 56 ]开发了金字塔场景解析网络( PSPN ),这是一个多尺度网络,用于更好地学习场景的全局上下文表示(图15 )。使用残差网络( ResNet )作为特征提取器,使用扩张网络从输入图像中提取不同的模式。然后将这些特征图输入到金字塔池化模块中,以区分不同尺度的模式。它们被集中在四个不同的尺度,每个尺度对应一个金字塔级别,并由一个1 x 1卷积层处理,以减少它们的维度。金字塔层级的输出进行上采样,并与初始特征图进行拼接,以同时捕获局部和全局上下文信息。最后,使用一个卷积层来生成像素级的预测。
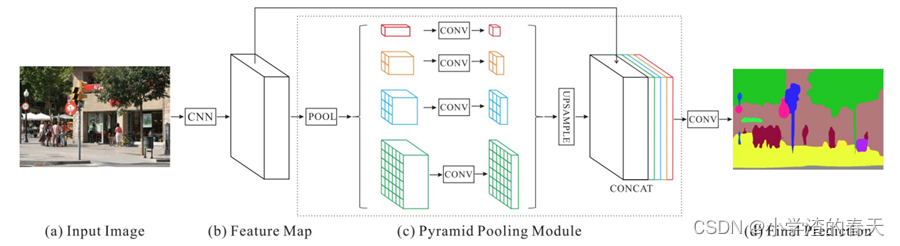
Fig. 15. The PSPN architecture. A CNN produces the feature map and a pyramid pooling module aggregates the different sub-region representations. Up-sampling and concatenation are used to form the final feature representation from which, the final pixel-wise prediction is obtained through convolution. From [56].
图15。PSPN体系结构。CNN产生特征图,金字塔池化模块聚合不同的子区域表示。使用上采样和级联形成最终的特征表示,并通过卷积得到最终的像素级预测。从[ 56 ]。
Ghiasi and Fowlkes [57] developed a multi-resolution reconstruction architecture based on a Laplacian pyramid that uses skip connections from higher resolution feature maps and multiplicative gating to successively refine segment boundaries reconstructed from lower-resolution maps. They showed that, while the apparent spatial resolution of convolutional feature maps is low, the high-dimensional feature representation contains significant sub-pixel localization information.
Ghiasi和福尔克斯[ 57 ]开发了一种基于拉普拉斯金字塔的多分辨率重建架构,该架构使用高分辨率特征图的跳跃连接和乘性选通来依次细化从低分辨率图重建的片段边界。结果表明,虽然卷积特征图的表观空间分辨率较低,但高维特征表示包含了显著的亚像素定位信息。
There are other models using multi-scale analysis for segmentation, such as DM-Net (Dynamic Multi-scale Filters Network) [58], Context contrasted network and gated multi-scale aggregation (CCN) [59], Adaptive Pyramid Context Network (APC-Net) [60], Multi-scale context intertwining (MSCI) [61], and salient object segmentation [62].
还有一些使用多尺度分析进行分割的模型,如DM - Net (动态多尺度滤波器网络) [ 58 ]、Context对比网络和门控多尺度聚合( CCN ) [ 59 ]、自适应金字塔Context网络( APC-Net ) [ 60 ]、多尺度Context交织( MSCI ) [ 61 ]和显著对象分割[ 62 ]。
3.5 R-CNN Based Models (for Instance Segmentation)
The regional convolutional network (R-CNN) and its extensions (Fast R-CNN, Faster R-CNN, Maksed-RCNN) have proven successful in object detection applications. In particular, the Faster R-CNN [63] architecture (Figure 16) developed for object detection uses a region proposal network (RPN) to propose bounding box candidates. The RPN extracts a Region of Interest (RoI), and a RoIPool layer computes features from these proposals in order to infer the bounding box coordinates and the class of the object. Some of the extensions of R-CNN have been heavily used to address the instance segmentation problem; i.e., the task of simultaneously performing object detection and semantic segmentation.
区域卷积网络( R- CNN )及其扩展( Fast R-CNN、Faster R-CNN、Maksed-RCNN)在目标检测应用中取得了成功。特别是,为目标检测开发的Faster R- CNN [ 63 ]体系结构(图16 )使用区域建议网络( RPN )提出边界框候选。RPN提取感兴趣区域( Region of Interest,RoI ),RoIPool层从这些提议中计算特征,以推断目标的边界框坐标和类别。R-CNN的一些扩展已经被大量用于解决实例分割问题;即,同时执行对象检测和语义分割的任务。
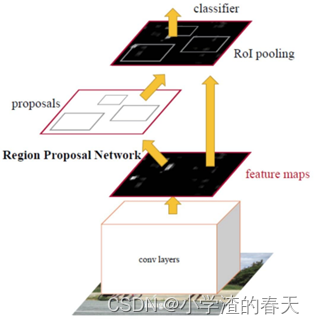
Fig. 16. Faster R-CNN architecture. Courtesy of [63].
图16 .更快速的R - CNN架构。
In one extension of this model, He et al. [64] proposed a Mask R-CNN for object instance segmentation, which beat all previous benchmarks on many COCO challenges. This model efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. Mask R-CNN is essentially a Faster R-CNN with 3 output branches (Figure 17)—the first computes the bounding box coordinates, the second computes the associated classes, and the third computes the binary mask to segment the object. The Mask R-CNN loss function combines the losses of the bounding box coordinates, the predicted class, and the segmentation mask, and trains all of them jointly. Figure 18 shows the Mask-RCNN result on some sample images.
在该模型的一个扩展中,He等人[ 64 ]提出了一个Mask R - CNN用于对象实例分割,在许多COCO挑战上战胜了以前的所有基准。该模型在高效检测图像中物体的同时,为每个实例同时生成高质量的分割掩膜。Mask R - CNN本质上是一个具有3个输出分支的Faster R - CNN (图17 ) -第一个计算边界框坐标,第二个计算关联类,第三个计算二进制掩码来分割目标。Mask R-CNN loss函数结合了边界框坐标、预测类和分割掩码的损失,并联合训练所有这些损失。图18展示了Mask - RCNN在部分样本图像上的结果。

Fig. 17. Mask R-CNN architecture for instance segmentation. From [64].
图17 .屏蔽用于实例分割的R-CNN体系结构。从[ 64 ]。

Fig. 18. Mask R-CNN results on sample images from the COCO test set. From [64].
图18 .掩码R - CNN对来自COCO测试集的样本图像的结果。从[ 64 ]。
The Path Aggregation Network (PANet) proposed by Liu et al. [65] is based on the Mask R-CNN and FPN models (Figure 19). The feature extractor of the network uses an FPN architecture with a new augmented bottom-up pathway improving the propagation of low-layer features. Each stage of this third pathway takes as input the feature maps of the previous stage and processes them with a 3 x 3 convolutional layer. The output is added to the same stage feature maps of the top-down pathway using a lateral connection and these feature maps feed the next stage. As in the Mask R- CNN, the output of the adaptive feature pooling layer feeds three branches. The first two use a fully connected layer to generate the predictions of the bounding box coordinates and the associated object class. The third processes the RoI with an FCN to predict the object mask.
Liu等人[ 65 ]提出的路径聚合网络( Path Aggregation Network,PANet )基于Mask R - CNN和FPN模型(图19 )。该网络的特征提取器使用FPN体系结构,其具有一个新的自底向上扩展路径,以改进低层特征的传播。第三个路径的每个阶段都将上一阶段的特征图作为输入,并使用3 x 3卷积层进行处理。输出结果通过横向连接添加到自上而下通路的相同阶段特征图中,这些特征图为下一阶段提供反馈。与Mask R-CNN一样,自适应特征池化层的输出为三个分支提供信息。前两者使用全连接层来生成边界框坐标和关联对象类的预测。第三个进程使用FCN处理RoI以预测对象掩码。
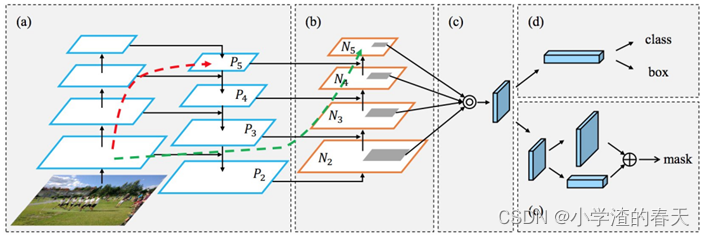
Fig. 19. The Path Aggregation Network. (a) FPN backbone. (b) Bottom- up path augmentation. (c) Adaptive feature pooling. (d) Box branch. (e) Fully-connected fusion. Courtesy of [65].
图19 .路径聚合网络。( a ) Fpn骨架。( b )自底向上的路径增强。( c )自适应特征汇集。( D )箱形分支。( E )全连接融合。礼遇[ 65 ]。
Dai et al. [66] developed a multi-task network for instance- aware semantic segmentation, that consists of three networks, respectively differentiating instances, estimating masks, and categorizing objects. These networks form a cascaded structure, and are designed to share their convolutional features. Hu et al. [67] proposed a new partially-supervised training paradigm, together with a novel weight transfer function, that enables training instance segmentation models on a large set of categories, all of which have box annotations, but only a small fraction of which have mask annotations.
Dai等人[ 66 ]开发了一个多任务网络用于实例感知的语义分割,该网络由三个网络组成,分别是区分实例、估计掩码和分类对象。这些网络形成了级联结构,并被设计为共享其卷积特征。Hu等人[ 67 ]提出了一种新的部分监督训练范式和一种新的权重转移函数,使训练实例分割模型能够在大量类别上进行,所有类别都有框注释,但只有一小部分类别有掩码注释。
Chen et al. [68] developed an instance segmentation model, MaskLab (Figure 20), by refining object detection with semantic and direction features based on Faster R-CNN. This model produces three outputs, box detection, semantic segmentation, and direction prediction. Building on the Faster- RCNN object detector, the predicted boxes provide accurate localization of object instances. Within each region of interest, MaskLab performs foreground/background segmentation by combining semantic and direction prediction.
Chen等人[ 68 ]开发了一个实例分割模型MaskLab (图20 ),通过基于Faster R - CNN的语义和方向特征改进目标检测。该模型产生三个输出,框检测、语义分割和方向预测。基于Faster - RCNN对象检测器,预测框提供对象实例的准确定位。在每个感兴趣区域内,MaskLab通过结合语义和方向预测执行前景/背景分割。

Fig. 20. The MaskLab model. MaskLab generates three outputs—refined box predictions (from Faster R-CNN), semantic segmentation logits for pixel-wise classification, and direction prediction logits for predicting each pixel's direction toward its instance center. From [68].
图20 . Masklab模型。MaskLab生成三个输出——改进的框预测(取自Faster R - CNN)、用于逐像素分类的语义分割logits和用于预测每个像素朝其实例中心方向的方向预测logits。从[ 68 ]。
Another interesting model is Tensormask, proposed by Chen et al. [69], which is based on dense sliding window instance segmentation. They treat dense instance segmentation as a prediction task over 4D tensors and present a general framework that enables novel operators on 4D tensors. They demonstrate that the tensor view leads to large gains over baselines and yields results comparable to Mask R-CNN. TensorMask achieves promising results on dense object segmentation.
另一个有趣的模型是Tensormask,由Chen等人[ 69 ]提出,它基于密集滑动窗口实例分割。他们将密集实例分割视为4D张量上的预测任务,并提出了一个通用框架,使4D张量上的新运算符成为可能。他们证明张量视图在基线上取得了很大的增益,并产生了与Mask R - CNN相当的结果。TensorMask在密集对象分割上取得了有希望的结果。
Many other instance segmentation models have been developed based on R-CNN, such as those developed for mask proposals, including R-FCN [70], DeepMask [71], PolarMask [72], boundary-aware instance segmentation [73], and CenterMask [74]. It is worth noting that there is another promising research direction that attempts to solve the instance segmentation problem by learning grouping cues for bottom-up segmentation, such as Deep Watershed Transform [75], real-time instance segmentation [76], and Semantic Instance Segmentation via Deep Metric Learning [77].
许多其他的基于R - CNN的实例分割模型已经被开发出来,例如针对掩码提案开发的模型,包括R-FCN [ 70 ]、DeepMask [ 71 ]、PolarMask [ 72 ]、边界感知的实例分割[ 73 ]和CenterMask [ 74 ]。值得注意的是,还有一个很有前途的研究方向,试图通过学习分组线索自下而上的分割来解决实例分割问题,如深度分水岭变换[ 75 ]、实时实例分割[ 76 ]、基于深度度量学习的语义实例分割[ 77 ]等。
3.6 Dilated Convolutional Models and DeepLab Family
Dilated convolution (a.k.a. “atrous” convolution) introduces another parameter to convolutional layers, the dilation rate. The dilated convolution (Figure 21) of a signal is defined as
, where
is the dilation rate that defines a spacing between the weights of the kernel w. For example, a 3 x 3 kernel with a dilation rate of 2 will have the same size receptive field as a 5 x 5 kernel while using only 9 parameters, thus enlarging the receptive field with no increase in computational cost. Dilated convolutions have been popular in the field of real-time segmentation, and many recent publications report the use of this technique. Some of most important include the DeepLab family [78], multiscale context aggregation [79], dense upsampling convolution and hybrid dilated convolution (DUC-HDC) [80], densely connected Atrous Spatial Pyramid Pooling (DenseASPP) [81], and the efficient neural network (ENet) [82].
膨胀卷积( a.k.a. ' atrous '卷积)为卷积层引入了另一个参数- -膨胀率。信号 的扩张卷积(图21 )定义为
,其中r 是扩张率,它定义了核w的权重之间的间距。例如,一个扩张率为2的3 × 3核,在仅使用9个参数的情况下,将具有与5 × 5核相同大小的感受野,从而在不增加计算成本的情况下扩大感受野。膨胀卷积在实时分割领域已经非常流行,最近的许多出版物报道了这种技术的使用。其中最重要的包括DeepLab家族[ 78 ]、多尺度上下文聚合[ 79 ]、密集上采样卷积和混合空洞卷积( DUC-HDC ) [ 80 ]、密集连接的空洞空间金字塔池化( DenseASPP ) [ 81 ]和高效神经网络( ENet ) [ 82 ]。

Fig. 21. Dilated convolution. A 3 x 3 kernel at different dilation rates.
图21。扩张的卷积。不同膨胀率下的3 × 3核。
DeepLabv1 [37] and DeepLabv2 [78] are among some of the most popular image segmentation approaches, developed by Chen et al.. The latter has three key features. First is the use of dilated convolution to address the decreasing resolution in the network (caused by max-pooling and striding). Second is Atrous Spatial Pyramid Pooling (ASPP), which probes an incoming convolutional feature layer with filters at multiple sampling rates, thus capturing objects as well as image context at multiple scales to robustly segment objects at multiple scales. Third is improved localization of object boundaries by combining methods from deep CNNs and probabilistic graphical models. The best DeepLab (using a ResNet-101 as backbone) has reached a 79.7% mIoU score on the 2012 PASCAL VOC challenge, a 45.7% mIoU score on the PASCAL-Context challenge and a 70.4% mIoU score on the Cityscapes challenge. Figure 22 illustrates the Deeplab model, which is similar to [37], the main difference being the use of dilated convolution and ASPP.
Deep Labv1 [ 37 ]和Deep Labv2 [ 78 ]是由Chen等人开发的一些最流行的图像分割方法。后者具有三个关键特征。首先是使用空洞卷积来解决网络(由最大池化和起跨引起)中分辨率下降的问题。第二种是融合空洞卷积金字塔( ASPP ),它在多个采样率下使用过滤器探测传入的卷积特征层,从而捕获多个尺度下的对象和图像上下文,从而在多个尺度下鲁棒地分割对象。第三是通过结合深度CNN和概率图模型的方法来改进对象边界的定位。最好的Deep Lab (使用ResNet - 101作为骨干网络)在2012年PASCAL VOC挑战赛上达到了79.7 %的m Io U得分,在PASCAL - Context挑战赛上达到了45.7 %的m Io U得分,在Cityscapes挑战赛上达到了70.4 %的m Io U得分。图22展示了Deeplab模型,它类似于[ 37 ],主要区别在于使用了空洞卷积和ASPP。
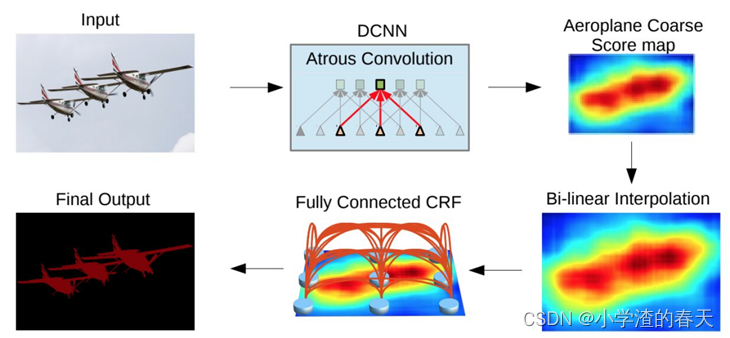
Fig. 22. The DeepLab model. A CNN model such as VGG-16 or ResNet- 101 is employed in fully convolutional fashion, using dilated convolution. A bilinear interpolation stage enlarges the feature maps to the original image resolution. Finally, a fully connected CRF refines the segmentation result to better capture the object boundaries. From [78]
图22 . Deeplab模型。全卷积方式采用VGG-16或ResNet-101等CNN模型,使用空洞卷积。双线性插值阶段将特征映射放大到原始图像分辨率。最后,一个全连接的CRF优化分割结果,以更好地捕获对象边界。从[ 78 ]
Subsequently, Chen et al. [12] proposed DeepLabv3, which combines cascaded and parallel modules of dilated convolutions. The parallel convolution modules are grouped in the ASPP. A 1 x 1 convolution and batch normalization are added in the ASPP. All the outputs are concatenated and processed by another 1 x 1 convolution to create the final output with logits for each pixel.
随后,Chen等人[ 12 ]提出了DeepLabv3,它结合了扩张卷积的级联和并行模块。在ASPP中对并行卷积模块进行分组。在ASPP中增加了1 × 1卷积和批量归一化。所有的输出都被串联起来,并由另一个1 x 1卷积来处理,以创建每个像素的最终输出。
In 2018, Chen et al. [83] released Deeplabv3+, which uses an encoder-decoder architecture (Figure 23), including atrous separable convolution, composed of a depthwise convolution (spatial convolution for each channel of the input) and pointwise convolution (1 x 1 convolution with the depthwise convolution as input). They used the DeepLabv3 framework as encoder. The most relevant model has a modified Xception backbone with more layers, dilated depthwise separable convolutions instead of max pooling and batch normalization. The best DeepLabv3+ pretrained on the COCO and the JFT datasets has obtained a 89.0% mIoU score on the 2012 PASCAL VOC challenge.
2018年,Chen等人[ 83 ]发布了Deeplabv3 +,使用编码器-解码器架构(图23 ),包括空洞可分离卷积,由深度卷积(对输入的每个通道进行空间卷积)和点卷积(以深度卷积为输入的1 × 1卷积)组成。他们使用DeepLabv3框架作为编码器。最相关的模型有一个修改的Xception主干,它具有更多的层,扩展的深度可分离卷积,而不是最大池化和批归一化。在COCO和JFT数据集上预训练的最佳Deep Labv3 +在2012年PASCAL VOC挑战赛上获得了89.0 %的mIoU分数。
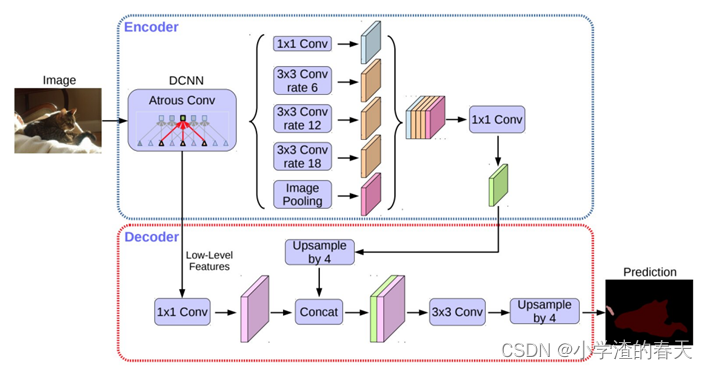
Fig. 23. The DeepLabv3+ model. From [83].
图23 . Deeplabv3 +模型。从[ 83 ]。
3.7 Recurrent Neural Network Based Models
While CNNs are a natural fit for computer vision problems, they are not the only possibility. RNNs are useful in modeling the short/long term dependencies among pixels to (potentially) improve the estimation of the segmentation map. Using RNNs, pixels may be linked together and processed sequentially to model global contexts and improve semantic segmentation. One challenge, though, is the natural 2D structure of images.
虽然CNN非常适合计算机视觉问题,但它们不是唯一的可能性。RNNs在建模像素之间的短期/长期依赖关系方面很有用,以(潜在)改善分割图的估计。使用RNNs,像素可以链接在一起,并按顺序处理,以建模全局上下文并改进语义分割。然而,一个挑战是图像的自然2D结构。
Visin et al. [84] proposed an RNN-based model for semantic segmentation called ReSeg. This model is mainly based on another work, ReNet [85], which was developed for image classification. Each ReNet layer is composed of four RNNs that sweep the image horizontally and vertically in both directions, encoding patches/activations, and providing relevant global information. To perform image segmentation with the ReSeg model (Figure 24), ReNet layers are stacked on top of pre-trained VGG-16 convolutional layers that extract generic local features. ReNet layers are then followed by up-sampling layers to recover the original image resolution in the final predictions. Gated Recurrent Units (GRUs) are used because they provide a good balance between memory usage and computational power.
Visin等[ 84 ]提出了一种基于RNN的语义分割模型Re Seg。该模型主要基于另一项工作ReNet [ 85 ],该工作是针对图像分类而开发的。每个ReNet层由四个RNN组成,它们在两个方向上水平和垂直扫描图像,编码补丁/激活,并提供相关的全局信息。为了使用Re Seg模型进行图像分割(图24 ),在提取通用局部特征的预训练VGG - 16卷积层上堆叠Re Net层。ReNet层之后是上采样层,以在最终预测中恢复原始图像分辨率。使用门控循环单元( GRU )是因为它们在内存使用和计算能力之间提供了良好的平衡。

Fig. 24. The ReSeg model. The pre-trained VGG-16 feature extractor network is not shown. From [84].
图24 . Reseg模型。预训练的VGG - 16特征提取器网络没有展示。从[ 84 ]。
In another work, Byeon et al. [86] developed a pixel-level segmentation and classification of scene images using long-short-term-memory (LSTM) network. They investigated two-dimensional (2D) LSTM networks for images of natural scenes, taking into account the complex spatial dependencies of labels. In this work, classification, segmentation, and context integration are all carried out by 2D LSTM networks, allowing texture and spatial model parameters to be learned within a single model.
在另一项工作中,Byeon等人[ 86 ]使用长短期记忆( LSTM )网络开发了一种像素级的场景图像分割和分类。他们研究了用于自然场景图像的二维( 2D ) LSTM网络,同时考虑到标签的复杂空间依赖性。在这项工作中,分类、分割和上下文集成都是通过2D LSTM网络进行的,允许在单个模型中学习纹理和空间模型参数。
Liang et al. [87] proposed a semantic segmentation model based on the Graph Long Short-Term Memory (Graph LSTM) network, a generalization of LSTM from sequential data or multidimensional data to general graph-structured data. Instead of evenly dividing an image to pixels or patches in existing multi-dimensional LSTM structures (e.g., row, grid and diagonal LSTMs), they take each arbitrary-shaped superpixel as a semantically consistent node, and adaptively construct an undirected graph for the image, where the spatial relations of the superpixels are naturally used as edges. Figure 25 presents a visual comparison of the traditional pixel-wise RNN model and graph-LSTM model. To adapt the Graph LSTM model to semantic segmentation (Figure 26) ,LSTM layers built on a super-pixel map are appended on the convolutional layers to enhance visual features with global structure context. The convolutional features pass through 1 x 1 convolutional filters to generate the initial confidence maps for all labels. The node updating sequence for the subsequent Graph LSTM layers is determined by the confidence-drive scheme based on the initial confidence maps, and then the Graph LSTM layers can sequentially update the hidden states of all superpixel nodes.
Liang等人[ 87 ]提出了一种基于图长短期记忆( Graph LSTM )网络的语义分割模型,它是LSTM从序列数据或多维数据到一般图结构数据的推广。在现有的多维LSTM结构(例如,行、网格和对角LSTM)中,它们没有将图像均匀地划分为像素或块,而是将每个任意形状的超像素作为语义一致的节点,并自适应地为图像构造一个无向图,其中超像素的空间关系自然地用作边缘。图25给出了传统的逐像素RNN模型和图- LSTM模型的可视化对比。为了使Graph LSTM模型适应语义分割(图26 ),在卷积层上添加了构建在超像素地图上的LSTM层,以增强具有全局结构上下文的视觉特征。卷积特征通过1 × 1卷积滤波器生成所有标签的初始置信图。后续Graph LSTM层的节点更新顺序由基于初始置信图的置信驱动方案确定,然后Graph LSTM层可以依次更新所有超像素节点的隐藏状态。

Fig. 25. Comparison between the graph-LSTM model and traditional pixel-wise RNN models. From [87].
图25 .图LSTM模型和传统的像素级RNN模型之间的比较。从[ 87 ]。

Fig. 26. The graph-LSTM model for semantic segmentation. From [87].
图26 .用于语义分割的图- LSTM模型。从[ 87 ]。
Xiang and Fox [88] proposed Data Associated Recurrent Neural Networks (DA-RNNs), for joint 3D scene mapping and semantic labeling. DA-RNNs use a new recurrent neural network architecture for semantic labeling on RGB-D videos. The output of the network is integrated with mapping techniques such as Kinect-Fusion in order to inject semantic information into the reconstructed 3D scene.
Xiang和Fox [ 88 ]提出了数据关联循环神经网络( DA-RNNs ),用于联合3D场景映射和语义标注。DA - RNNs使用一种新的循环神经网络架构对RGB - D视频进行语义标注。网络的输出与Kinect - Fusion等映射技术集成,以便为重建的3D场景注入语义信息。
Hu et al. [89] developed a semantic segmentation algorithm based on natural language expression, using a combination of CNN to encode the image and LSTM to encode its natural language description. This is different from traditional semantic segmentation over a predefined set of semantic classes, as, e.g., the phrase “two men sitting on the right bench” requires segmenting only the two people on the right bench and no one standing or sitting on another bench. To produce pixel-wise segmentation for language expression, they propose an end-to-end trainable recurrent and convolutional model that jointly learns to process visual and linguistic information (Figure 27). In the considered model, a recurrent LSTM network is used to encode the referential expression into a vector representation, and an FCN is used to extract a spatial feature map from the image and output a spatial response map for the target object. An example segmentation result of this model (for the query “people in blue coat”) is shown in Figure 28.
Hu等人[ 89 ]开发了一种基于自然语言表达的语义分割算法,使用CNN编码图像和LSTM编码其自然语言描述。这与传统的语义分割在预定义的语义类集合上是不同的,例如"坐在右边长凳上的两个人"这个短语只要求分割右边长凳上的两个人,而没有人站在另一个长凳上。为了对语言表达进行像素级分割,他们提出了一种端到端的可训练的循环和卷积模型,共同学习处理视觉和语言信息(图27 )。在所考虑的模型中,使用循环LSTM网络将参考表达式编码为向量表示,并使用FCN从图像中提取空间特征图并输出目标对象的空间响应图。该模型(对于查询"穿蓝色外套的人")的实例分割结果如图28所示。
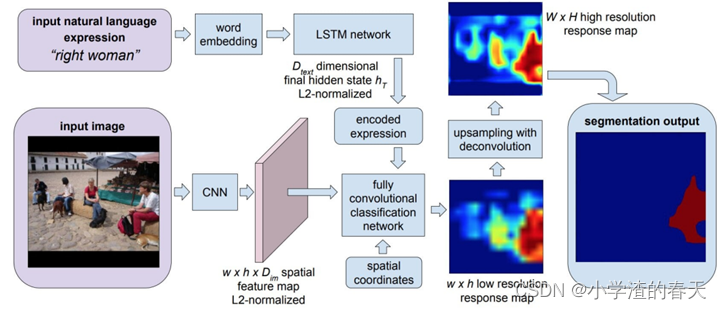
Fig. 27. The CNN+LSTM architecture for segmentation from natural language expressions. From [89]
图27 .用于从自然语言表达式分割的CNN + LSTM架构。从[ 89 ]。
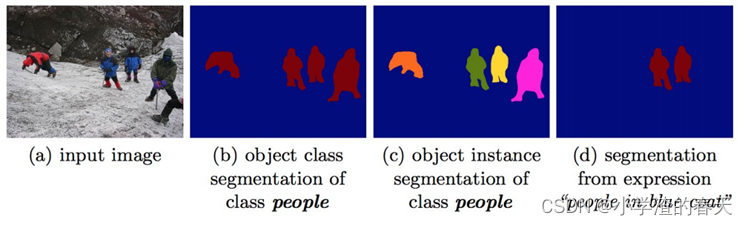
Fig. 28. Segmentation masks generated for the query “people in blue coat”. From [89].
图28 .为查询"穿蓝色外套的人"生成的分割掩码。从[ 89 ]。
One limitation of RNN based models is that, due to the sequential nature these models, they will be slower than their CNN counterpart, since this sequential calculation cannot be parallelized easily.
基于RNN的模型的一个限制是,由于这些模型的顺序性,它们将比它们的CNN对应模型慢,因为这种顺序计算不能很容易地并行化。
3.8 Attention-Based Models
Attention mechanisms have been persistently explored in computer vision over the years, and it is therefore not surprising to find publications that apply such mechanisms to semantic segmentation.
多年来,注意力机制一直在计算机视觉中被探索,因此发现将这种机制应用于语义分割的出版物并不奇怪。
Chen et al. [90] proposed an attention mechanism that learns to softly weight multi-scale features at each pixel location. They adapt a powerful semantic segmentation model and jointly train it with multi-scale images and the attention model (Figure 29). The attention mechanism outperforms average and max pooling, and it enables the model to assess the importance of features at different positions and scales.
Chen等人[ 90 ]提出了一种注意力机制,该机制学习在每个像素位置对多尺度特征进行软加权。他们采用一个强大的语义分割模型,并与多尺度图像和注意力模型联合训练(图29 )。注意力机制优于平均和最大池化,它使模型能够评估不同位置和规模的特征的重要性。
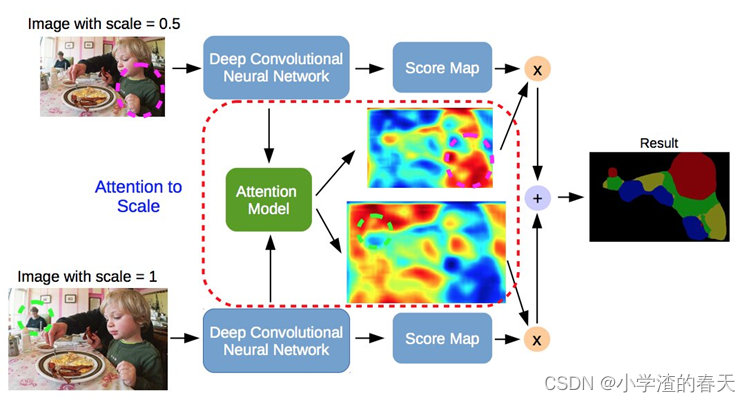
Fig. 29. Attention-based semantic segmentation model. The attention model learns to assign different weights to objects of different scales; e.g., the model assigns large weights on the small person (green dashed circle) for features from scale 1.0, and large weights on the large child (magenta dashed circle) for features from scale 0.5. From [90].
图29 .基于注意力的语义分割模型。注意力模型学习为不同尺度的对象分配不同的权重;例如,模型为小人物(绿色虚线圆)分配较大的权重,用于刻度1.0的特征;为大孩子(洋红色虚线圆圈)分配较大的权重,用于刻度0.5的特征。从[ 90 ]。
In contrast to other works in which convolutional classifiers are trained to learn the representative semantic features of labeled objects, Huang et al. [91] proposed a semantic segmentation approach using reverse attention mechanisms. Their Reverse Attention Network (RAN) architecture (Figure 30) trains the model to capture the opposite concept (i.e., features that are not associated with a target class) as well. The RAN is a three-branch network that performs the direct, and reverse-attention learning processes simultaneously.
与其他通过训练卷积分类器来学习标注对象的代表性语义特征的工作不同,Huang等人[ 91 ]提出了一种使用反向注意力机制的语义分割方法。他们的反向注意力网络( Reverse Attention Network,RAN )架构(图30 )也训练模型来捕获相反的概念(即,与目标类不相关联的特性)。RAN是一个三分支网络,同时执行直接和反向注意力学习过程。
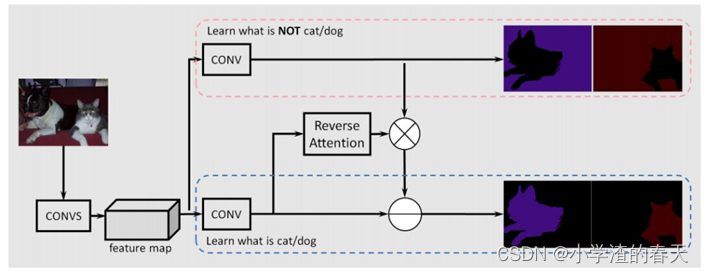
Fig. 30. The reverse attention network for segmentation. From [91].
图30 .用于分割的反向注意力网络。从[ 91 ]。
Li et al. [92] developed a Pyramid Attention Network for semantic segmentation. This model exploits the impact of global contextual information in semantic segmentation. They combined attention mechanisms and spatial pyramids to extract precise dense features for pixel labeling, instead of complicated dilated convolutions and artificially designed decoder networks.
Li等人[ 92 ]开发了用于语义分割的金字塔注意力网络。该模型利用了语义分割中全局上下文信息的影响。它们结合了注意力机制和空间金字塔来提取精确的稠密特征用于像素标记,而不是复杂的扩张卷积和人为设计的解码器网络。
More recently, Fu et al. [93] proposed a dual attention network for scene segmentation, which can capture rich con-textual dependencies based on the self-attention mechanism.
最近,Fu等[ 93 ]提出了一种用于场景分割的双注意力网络,该网络基于自注意力机制可以捕获丰富的上下文依赖关系。

Fig. 31. The GAN for semantic segmentation. From [100].
图31 .用于语义分割的GAN。从[ 100 ]。
Specifically, they append two types of attention modules on top of a dilated FCN which models the semantic interdependencies in spatial and channel dimensions, respectively. The position attention module selectively aggregates the feature at each position by a weighted sum of the features at all positions.
具体来说,他们在一个扩展的FCN之上附加了两种类型的注意力模块,分别在空间和通道维度上建模语义相互依赖。位置注意力模块通过对所有位置的特征进行加权求和,选择性地聚合每个位置的特征。
Various other works explore attention mechanisms for semantic segmentation, such as OCNet [94] which proposed an object context pooling inspired by self-attention mechanism, Expectation-Maximization Attention (EMANet) [95], Criss-Cross Attention Network (CCNet) [96], end-to-end instance segmentation with recurrent attention [97], a pointwise spatial attention network for scene parsing [98], and a discriminative feature network (DFN) [99], which comprises two sub-networks: a Smooth Network (that contains a Channel Attention Block and global average pooling to select the more discriminative features) and a Border Network (to make the bilateral features of the boundary distinguishable).
其他许多工作探索了语义分割的注意力机制,例如OCNet [ 94 ],它提出了一种受自注意力机制启发的对象上下文池化,期望最大化注意力( EMANet ) [ 95 ],交叉注意力网络( CCNet ) [ 96 ],带循环注意力的端到端实例分割[ 97 ],用于场景解析的逐点空间注意力网络[ 98 ],以及区分性特征网络( DFN ) [ 99 ],它包括两个子网络:平滑网络(包含通道注意力块和全局平均池化来选择更具判别性的特征)和边界网络(使边界的双边特征具有可区分性)。
3.9 Generative Models and Adversarial Training
Since their introduction, GANs have been applied to a wide range tasks in computer vision, and have been adopted for image segmentation too.
自提出以来,GAN已被应用于计算机视觉中的各种任务,也被用于图像分割。
Luc et al. [100] proposed an adversarial training approach for semantic segmentation. They trained a convolutional semantic segmentation network (Figure 31), along with an adversarial network that discriminates ground-truth seg-mentation maps from those generated by the segmentation network. They showed that the adversarial training approach leads to improved accuracy on the Stanford Background and PASCAL VOC 2012 datasets.
Luc等人[ 100 ]提出了一种用于语义分割的对抗训练方法。他们训练了一个卷积语义分割网络(图31 ),并训练了一个对抗网络,将ground-truth分割图与分割网络生成的分割图区分开来。实验结果表明,对抗训练方法在斯坦福大学背景数据集和PASCAL VOC 2012数据集上的准确率得到了提高。
Souly et al. [101] proposed semi-weakly supervised semantic segmentation using GANs. It consists of a generator network providing extra training examples to a multi-class classifier, acting as discriminator in the GAN framework, that assigns sample a label y from the K possible classes or marks it as a fake sample (extra class).
Souly等人[ 101 ]提出了使用GAN的半弱监督语义分割。它由一个生成器网络提供额外的训练样本给一个多类分类器,充当GAN框架中的判别器,它从K个可能的类中为样本分配一个标签y或将其标记为假样本(额外类)。
In another work, Hung et al. [102] developed a framework for semi-supervised semantic segmentation using an adversarial network. They designed an FCN discriminator to differentiate the predicted probability maps from the ground truth segmentation distribution, considering the spatial resolution. The considered loss function of this model contains three terms: cross-entropy loss on the segmentation ground truth, adversarial loss of the discriminator network, and semi-supervised loss based on the confidence map; i.e., the output of the discriminator.
在另一项工作中,Hung等人[ 102 ]开发了一个使用对抗网络的半监督语义分割框架。考虑到空间分辨率,他们设计了一个FCN判别器来区分预测概率图和真实分割分布。该模型考虑的损失函数包含三项:分割基真值上的交叉熵损失、判别器网络的对抗损失和基于置信图的半监督损失;即,判别器的输出。
Xue et al. [103] proposed an adversarial network with multi-scale L1 Loss for medical image segmentation. They used an FCN as the segmentor to generate segmentation label maps, and proposed a novel adversarial critic network with a multi-scale L1 loss function to force the critic and segmentor to learn both global and local features that capture long and short range spatial relationships between pixels.
Xue等人[ 103 ]提出了一种多尺度L1损失的对抗网络用于医学图像分割。他们使用FCN作为分割器生成分割标签图,并提出了一种新的带有多尺度L1损失函数的对抗评价网络,以迫使评价器和分割器同时学习全局和局部特征,以捕获像素之间的长和短程空间关系。
Various other publications report on segmentation models based on adversarial training, such as Cell Image Segmentation Using GANs [104], and segmentation and generation of the invisible parts of objects [105].
其他各种出版物报告了基于对抗训练的分割模型,如使用GAN的细胞图像分割[ 104 ],以及分割和生成物体的不可见部分[ 105 ]。
3.10 CNN Models With Active Contour Models
The exploration of synergies between FCNs and Active Contour Models (ACMs) [7] has recently attracted research interest. One approach is to formulate new loss functions that are inspired by ACM principles. For example, inspired by the global energy formulation of [106], Chen et aL [107] proposed a supervised loss layer that incorporated area and size information of the predicted masks during training of an FCN and tackled the problem of ventricle segmentation in cardiac MRI.
探索FCN和活动轮廓模型( ACM )之间的协同作用[ 7 ]最近引起了研究兴趣。一种方法是受ACM原则的启发,构造新的损失函数。例如,受全局能量公式[ 106 ]的启发,Chen等人[ 107 ]提出了一个有监督的损失层,在FCN的训练过程中融合了预测掩膜的面积和大小信息,解决了心脏MRI中的心室分割问题。
A different approach initially sought to utilize the ACM merely as a post-processor of the output of an FCN and several efforts attempted modest co-learning by pre-training the FCN. One example of an ACM post-processor for the task of semantic segmentation of natural images is the work by Le et al. [108] in which level-set ACMs are implemented as RNNs. Deep Active Contours by Rupprecht et al. [109], is another example. For medical image segmentation, Hatamizadeh et al. [110] proposed an integrated Deep Active Lesion Segmentation (DALS) model that trains the FCN backbone to predict the parameter functions of a novel, locally- parameterized level-set energy functional. In another relevant effort, Marcos et al. [111] proposed Deep Structured Active Contours (DSAC), which combines ACMs and pre-trained FCNs in a structured prediction framework for building instance segmentation (albeit with manual initialization) in aerial images. For the same application, Cheng et al. [112] proposed the Deep Active Ray Network (DarNet), which is similar to DSAC, but with a different explicit ACM formulation based on polar coordinates to prevent contour self-intersection. A truly end-to-end backpropagation trainable, fully-integrated FCN-ACM combination was recently introduced by Hatamizadeh et al. [113], dubbed Deep Convolutional Active Contours (DCAC).
一种不同的方法最初只是寻求将ACM用作FCN输出的后处理器,并尝试通过对FCN进行预训练来进行少量的共同学习。用于自然图像语义分割任务的ACM后处理器的一个例子是Le等人[ 108 ]的工作,其中水平集ACM被实现为RNN。另一个例子是鲁普雷希特等[ 109 ]提出的深度活动轮廓。在医学图像分割方面,Hatamizadeh等[ 110 ]提出了一个集成的深度活动病灶分割( Deep Active Lesion Segmentation,DALS )模型,该模型训练FCN主干来预测一个新颖的、局部参数化的水平集能量泛函的参数函数。在另一项相关工作中,Marcos等人[ 111 ]提出了深度结构化活动轮廓( Deep Structured Active Contours,DSAC ),它将ACM和预训练的FCN结合在一个结构化预测框架中,用于在航拍图像中构建实例分割(尽管有手动初始化)。针对同样的应用,Cheng等人[ 112 ]提出了深度活动射线网络( DarNet ),它与DSAC类似,但使用了不同的基于极坐标的显式ACM公式来防止轮廓自交。最近,Hatamizadeh等人[ 113 ]提出了一种真正的端到端反向传播可训练的全集成FCN - ACM组合,称为深度卷积活动轮廓( Deep Convolutional Active Contours,DCAC )。
3.11 Other Models
In addition to the above models, there are several other popular DL architectures for segmentation, such as the following: Context Encoding Network (EncNet) that uses a basic feature extractor and feeds the feature maps into a Context Encoding Module [114]. RefineNet [115], which is a multi-path refinement network that explicitly exploits all the information available along the down-sampling process to enable high-resolution prediction using long-range residual connections. Seednet [116], which introduced an automatic seed generation technique with deep reinforcement learning that learns to solve the interactive segmentation problem. "Object-Contextual Representations” (OCR) [44], which learns object regions under the supervision of the ground-truth, and computes the object region representation, Exfuse (enhancing low-level and high-level features fusion) [120], Feedforward-Net [121], saliency-aware models for geodesic video segmentation [122], dual image segmentation (DIS) [123], FoveaNet (Perspective-aware scene parsing) [124], Ladder DenseNet [125], Bilateral segmentation network (BiSeNet) [126], Semantic Prediction Guidance for Scene Parsing (SPGNet) [127], Gated shape CNNs [128], Adaptive context network (AC-Net) [129], Dynamic- structured semantic propagation network (DSSPN) [130], symbolic graph reasoning (SGR) [131], CascadeNet [132], Scale-adaptive convolutions (SAC) [133], Unified perceptual parsing (UperNet) [134], segmentation by re-training and self-training [135], densely connected neural architecture search [136], hierarchical multi-scale attention [137].
除了上述模型,还有其他几种流行的DL架构用于分割,例如:上下文编码网络( EncNet ),它使用一个基本的特征提取器,并将特征图输入到上下文编码模块[ 114 ]。RefineNet [ 115 ]是一种多路径精化网络,它显式地利用了下采样过程中的所有可用信息,从而能够使用远程残差连接进行高分辨率预测。Seednet [ 116 ]引入了深度强化学习的自动种子生成技术,学习解决交互式分割问题。对象级别检索上下文表示( OCR ) [ 44 ],在真实背景的监督下学习目标区域,并计算目标区域表示,Exfuse (增强低层和高层特征融合) [ 120 ],Feedforward-Net [ 121 ],显著性感知模型用于测地视频分割[ 122 ],双图像分割( DIS ) [ 123 ],FoveaNet (视角感知的场景解析) [ 124 ],Ladder DenseNet [ 125 ],双边分割网络( BiSeNet ) [ 126 ],语义预测指导场景解析( SPGNet ) [ 127 ],门控形状CNNs [ 128 ],自适应上下文网络( AC-Net ) [ 129 ],动态语义结构化传播网络( DSSPN ) [ 130 ],符号化图( SAC-GRNets ) [ 132 ],通过再训练和自训练进行分割[ 135 ],密集连接的神经结构搜索[ 136 ],分层多尺度注意力[ 137 ]。
Panoptic segmentation [138] is also another interesting segmentation problem with rising popularity, and there are already several interesting works on this direction, including Panoptic Feature Pyramid Network [139], attention-guided network for Panoptic segmentation [140], Seamless Scene Segmentation [141], panoptic deeplab [142], unified panoptic segmentation network [143], efficient panoptic segmentation [144].
全景分割[ 138 ]也是另一个越来越受欢迎的有趣的分割问题,关于这个方向已经有几个有趣的工作,包括全景特征金字塔网络[ 139 ],注意力引导的全景分割网络[ 140 ],无缝场景分割[ 141 ],全景深度实验室[ 142 ],统一全景分割网络[ 143 ],高效全景分割[ 144 ]。
Figure 32 illustrates the timeline of popular DL-based works for semantic segmentation, as well as instance segmentation since 2014. Given the large number of works developed in the last few years, we only show some of the most representative ones.
图32展示了自2014年以来流行的基于DL的语义分割和实例分割的工作时间表。鉴于在过去几年中开发的大量作品,我们只展示一些最具代表性的作品。
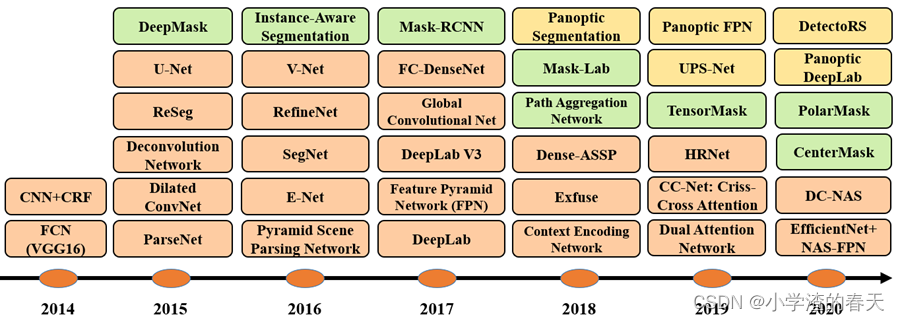
Fig. 32. The timeline of DL-based segmentation algorithms for 2D images, from 2014 to 2020. Orange, green, andn yellow blocks refer to semantic, instance, and panoptic segmentation algorithms respectively.
图32 .基于DL的二维图像分割算法的时间轴,从2014年到2020年。橙色、绿色和黄色块分别指语义、实例和全景分割算法。
4 IMAGE SEGMENTATION DATASETS
In this section we provide a summary of some of the most widely used image segmentation datasets. We group these datasets into 3 categories—2D images, 2.5D RGB-D (color+depth) images, and 3D images—and provide details about the characteristics of each dataset. The listed datasets have pixel-wise labels, which can be used for evaluating model performance.
在本节中,我们提供了一些最广泛使用的图像分割数据集的摘要。我们将这些数据集分为3类——2D图像、2.5 D RGB-D (颜色+深度)图像和3D图像——并详细介绍了每个数据集的特点。列出的数据集具有像素级标签,可用于评估模型性能。
It is worth mentioning that some of these works, use data augmentation to increase the number of labeled samples, specially the ones which deal with small datasets (such as in medical domain). Data augmentation serves to increase the number of training samples by applying a set of transformation (either in the data space, or feature space, or sometimes both) to the images (i.e., both the input image and the segmentation map). Some typical transformations include translation, reflection, rotation, warping, scaling, color space shifting, cropping, and projections onto principal components. Data augmentation has proven to improve the performance of the models, especially when learning from limited datasets, such as those in medical image analysis. It can also be beneficial in yielding faster convergence, decreasing the chance of over-fitting, and enhancing generalization. For some small datasets, data augmentation has been shown to boost model performance more than 20%.
值得一提的是,其中一些工作使用数据增强来增加标记样本的数量,特别是处理小数据集(例如在医疗领域)的标记样本。数据增强是通过对图像(即,输入图像和分割图)施加一组变换(要么在数据空间,要么在特征空间,有时两者兼而有之)来增加训练样本的数量。一些典型的变换包括平移、反射、旋转、扭曲、缩放、颜色空间平移、裁剪和投影到主成分上。事实证明,数据增强可以提高模型的性能,特别是当从有限的数据集学习时,例如在医学图像分析中。它还有助于产生更快的收敛,减少过拟合的机会,并提高泛化能力。对于一些小型数据集,数据增强已经被证明可以提高模型性能超过20 %。

图32 .基于DL的二维图像分割算法的时间轴,从2014年到2020年。橙色、绿色和黄色块分别指语义、实例和全景分割算法。
4.1 2D Datasets
The majority of image segmentation research has focused on 2D images; therefore, many 2D image segmentation datasets are available. The following are some of the most popular:
图像分割的研究大多集中于二维图像;因此,许多2D图像分割数据集是可用的。以下是一些最受欢迎的:
PASCAL Visual Object Classes (VOC) [145] is one of most popular datasets in computer vision, with annotated images available for 5 tasks—classification, segmentation, detection, action recognition, and person layout. Nearly all popular segmentation algorithms reported in the literature have been evaluated on this dataset. For the segmentation task, there are 21 classes of object labels—vehicles, household, animals, aeroplane, bicycle, boat, bus, car, motorbike, train, bottle, chair, dining table, potted plant, sofa, TV/monitor, bird, cat, cow, dog, horse, sheep, and person (pixel are labeled as background if they do not belong to any of these classes). This dataset is divided into two sets, training and validation, with 1,464 and 1,449 images, respectively. There is a private test set for the actual challenge. Figure 33 shows an example image and its pixel-wise label.
PASCAL Visual Object Classes( VOC ) [ 145 ]是计算机视觉中最流行的数据集之一,其标注图像可用于分类、分割、检测、动作识别和人物布局5个任务。文献中报道的几乎所有流行的分割算法都在这个数据集上进行了评估。对于分割任务,有21类对象标签——车辆、家庭、动物、飞机、自行车、船、公共汽车、汽车、摩托车、火车、瓶子、椅子、餐桌

Fig. 33. An example image from the PASCAL VOC dataset. From [146]
图33 .来自PASCAL VOC数据集的示例图像。由[ 146 ]
PASCAL Context [147] is an extension of the PASCAL VOC 2010 detection challenge, and it contains pixel-wise labels for all training images. It contains more than 400 classes (including the original 20 classes plus backgrounds from PASCAL VOC segmentation), divided into three categories (objects, stuff, and hybrids). Many of the object categories of this dataset are too sparse and; therefore, a subset of 59 frequent classes are usually selected for use.
PASCAL Context [ 147 ]是对PASCAL VOC 2010检测挑战的扩展,它包含所有训练图像的像素级标签。它包含400多个类(包括原始的20类加上来自PASCAL VOC的背景分割),分为三类(对象、事物和杂合体)。该数据集的很多对象类别过于稀疏和;因此,通常选择59个频繁类的子集进行使用。
Microsoft Common Objects in Context (MS COCO) [148] is another large-scale object detection, segmentation, and captioning dataset. COCO includes images of complex everyday scenes, containing common objects in their natural contexts. This dataset contains photos of 91 objects types, with a total of 2.5 million labeled instances in 328k images. Figure 34 shows the difference between MS-COCO labels and the previous datasets for a given sample image. The detection challenge includes more than 80 classes, providing more than 82k images for training, 40.5k images for validation, and more than 80k images for its test set.
Microsoft Common Objects in Context ( MS COCO ) [ 148 ]是另一个大规模的目标检测、分割和描述数据集。COCO包括复杂的日常场景的图像,包含在其自然上下文中的常见对象。这个数据集包含91个对象类型的照片,在328k图像中总共有250万个标记实例。图34显示了给定示例图像的MS-COCO标签和以前的数据集之间的差异。检测挑战包括超过80类,提供超过82k张图像用于训练,40.5 k张图像用于验证,以及超过80k张图像用于测试集。

Fig. 34. A sample image and its segmentation map in COCO, and its comparison with previous datasets. From [148].
图34 .一个样本图像及其在COCO中的分割图,以及与先前数据集的比较。从[ 148 ]。
Cityscapes [149] is a large-scale database with a focus on semantic understanding of urban street scenes. It contains a diverse set of stereo video sequences recorded in street scenes from 50 cities, with high quality pixel-level annotation of 5k frames, in addition to a set of 20k weakly annotated frames. It includes semantic and dense pixel annotations of 30 classes, grouped into 8 categories—flat surfaces, humans, vehicles, constructions, objects, nature, sky, and void. Figure 35 shows four sample segmentation maps from this dataset.
Cityscapes [ 149 ]是一个大型数据库,侧重于城市街道场景的语义理解。它包含了来自50个城市的街道场景中记录的多样化的立体视频序列集,具有5k帧的高质量像素级标注,此外还有一组20k弱标注帧。它包括语义和密集像素注释的30类,分为8类——平面,人类,车辆,建筑,物体,自然,天空,和空隙。图35显示了来自这个数据集的四个样本分割图。

Fig. 35. Three sample images with their corresponding segmentation maps from the Cityscapes dataset. From [149].
图35 .来自Cityscapes数据集的三个示例图像及其相应的分割图。从[ 149 ]。
ADE20K/MIT Scene Parsing (SceneParsel50) offers a standard training and evaluation platform for scene parsing algorithms. The data for this benchmark comes from the ADE20K dataset [132], which contains more than 20K scenecentric images exhaustively annotated with objects and object parts. The benchmark is divided into 20K images for training,2K images for validation, and another batch of images for testing. There are 150 semantic categories in this dataset.
ADE20K / MIT Scene Parsing ( Scene Parsel50 )为场景解析算法提供了标准的训练和评估平台。这个基准测试程序的数据来自ADE20K数据集[ 132 ],该数据集包含超过20K的以场景为中心的图像,这些图像用对象和对象部件进行了详尽的标注。将基准分为20K张图像用于训练,2K张图像用于验证,另外一批图像用于测试。这个数据集中有150个语义类别。
SiftFlow [150] includes 2,688 annotated images from a subset of the LabelMe database. The 256 x 256 pixel images are based on 8 different outdoor scenes, among them streets, mountains, fields, beaches, and buildings. All images belong to one of 33 semantic classes.
SiftFlow [ 150 ]包括2,688张来自LabelMe数据库子集的标注图像。256 × 256像素的图像基于8种不同的室外场景,其中包括街道、山脉、田野、海滩和建筑物。所有图像属于33个语义类中的一个。
Stanford background [151] contains outdoor images of scenes from existing datasets, such as LabelMe, MSRC, and PASCAL VOC. It contains 715 images with at least one foreground object. The dataset is pixel-wise annotated, and can be used for semantic scene understanding. Semantic and geometric labels for this dataset were obtained using Amazon's Mechanical Turk (AMT).
Stanford background[ 151 ]包含来自现有数据集的室外场景图像,例如LabelMe、MSRC和PASCAL VOC。它包含至少一个前景对象的715个图像。该数据集是逐像素标注的,可用于语义场景理解。使用Amazon的研究工具( AMT )获得了该数据集的语义和几何标签。
Berkeley Segmentation Dataset (BSD) [152] contains 12,000 hand-labeled segmentations of 1,000 Corel dataset images from 30 human subjects. It aims to provide an empirical basis for research on image segmentation and boundary detection. Half of the segmentations were obtained from presenting the subject a color image and the other half from presenting a grayscale image.
伯克利分割数据集( Berkeley Segmentation Dataset,BSD ) [ 152 ]包含12,000个手工标注的来自30个人类被试的1,000张Corel数据集图像的分割。旨在为图像分割和边界检测的研究提供实证基础。一半的分割是通过呈现一个彩色图像获得的,另一半是通过呈现一个灰度图像获得的。
Youtube-Objects [153] contains videos collected from YouTube, which include objects from ten PASCAL VOC classes (aeroplane, bird, boat, car, cat, cow, dog, horse, motorbike, and train). The original dataset did not contain pixel-wise annotations (as it was originally developed for object detection, with weak annotations). However, Jain et al. [154] manually annotated a subset of 126 sequences, and then extracted a subset of frames to further generate semantic labels. In total, there are about 10,167 annotated 480x360 pixel frames available in this dataset.
Youtube-Objects [ 153 ]包含从YouTube上收集的视频,其中包含来自十个PASCAL VOC类(飞机、鸟、船、车、猫、牛、狗、马、摩托车、火车等)的对象。原始数据集不包含像素级注释(因为它最初是为了目标检测而开发的,带有弱注释)。然而,Jain等人[ 154 ]手动标注了126个序列的子集,然后提取了框架的子集来进一步生成语义标签。总的来说,这个数据集中大约有10,167个带注释的480x360像素帧。
KITTI [155] is one of the most popular datasets for mobile robotics and autonomous driving. It contains hours of videos of traffic scenarios, recorded with a variety of sensor modalities (including high-resolution RGB, grayscale stereo cameras, and a 3D laser scanners). The original dataset does not contain ground truth for semantic segmentation, but researchers have manually annotated parts of the dataset for research purposes. For example, Alvarez et al. [156] generated ground truth for 323 images from the road detection challenge with 3 classes, road, vertical, and sky.
KITTI [ 155 ]是移动机器人和自动驾驶领域最流行的数据集之一。它包含数小时的交通场景视频,使用多种传感器模态(包括高分辨率RGB、灰度立体相机和三维激光扫描仪)进行记录。原始数据集不包含用于语义分割的基本事实,但研究人员出于研究目的对数据集的部分内容进行了人工标注。例如,Alvarez等[ 156 ]通过道路、垂直和天空3类道路检测挑战,为323张图像生成了地面真值。
Other Datasets are available for image segmentation purposes too, such as Semantic Boundaries Dataset (SBD) [157], PASCAL Part [158], SYNTHIA [159], and Adobe's Portrait Segmentation [160].
其他数据集也可用于图像分割,如语义边界数据集( Semantic Boundaries Dataset, SBD ) [ 157 ]、PASCAL Part [ 158 ]、PASCAL Part[ 159 ]和Adobe Portrait Segmentation [ 160 ]。
4.2 2.5D Datasets
With the availability of affordable range scanners, RGB-D images have became popular in both research and industrial applications. The following RGB-D datasets are some of the most popular:
随着买的起的范围扫描仪可以使用,RGB-D图像在研究和工业应用中都变得流行。下面的RGB - D数据集是一些最流行的:
NYU-D V2 [161] consists of video sequences from a variety of indoor scenes, recorded by the RGB and depth cameras of the Microsoft Kinect. It includes 1,449 densely labeled pairs of aligned RGB and depth images from more than 450 scenes taken from 3 cities. Each object is labeled with a class and an instance number (e.g., cup1, cup2, cup3, etc.). It also contains 407,024 unlabeled frames. This dataset is relatively small compared to other existing datasets. Figure 36 shows a sample image and its segmentation map.
NYU-D V2 [ 161 ]由来自各种室内场景的视频序列组成,由Microsoft Kinect的RGB和深度相机记录。它包括来自3个城市的450多个场景的1,449个密集标记的对齐RGB和深度图像。每个对象都标注一个类和一个实例编号(例如, cup1、cup2、cup3等。)。它还包含407,024个未标记帧。与现有的其他数据集相比,该数据集相对较小。图36所示为样本图像及其分割图。

Fig. 36. A sample from the NYU V2 dataset. From left: the RGB image, pre-processed depth, and set of labels. From [161].
图36 .来自NYU V2数据集的示例。从左边:RGB图像、预处理的深度和一组标签。从[ 161 ]。
SUN-3D [162] is a large-scale RGB-D video dataset that contains 415 sequences captured for 254 different spaces in 41 different buildings; 8 sequences are annotated and more will be annotated in the future. Each annotated frame comes with the semantic segmentation of the objects in the scene, as well as information about the camera pose.
SUN - 3D [ 162 ]是一个大规模的RGB - D视频数据集,包含415个序列,在41个不同的建筑物中捕获254个不同的空间;有8个序列被注释,将来还会有更多的序列被注释。每个带注释的帧都带有场景中对象的语义分割,以及关于相机姿态的信息。
SUN RGB-D [163] provides an RGB-D benchmark for the goal of advancing the state-of-the-art in all major scene understanding tasks. It is captured by four different sensors and contains 10,000 RGB-D images at a scale similar to PASCAL VOC. The whole dataset is densely annotated and includes 146,617 2D polygons and 58,657 3D bounding boxes with accurate object orientations, as well as the 3D room category and layout for scenes.
SUN RGB-D [ 163 ]为在所有主要的场景理解任务中提升最先进的目标提供了一个RGB - D基准。它由四个不同的传感器捕获,包含10,000个RGB - D图像,其比例与PASCAL VOC相似。整个数据集有密集的注释,包括146,617个2D多边形和58,657个3D边界框,有准确的物体方向,以及3D房间类别和场景布局。
UW RGB-D Object Dataset [164] contains 300 common household objects recorded using a Kinect style 3D camera. The objects are organized into 51 categories, arranged using WordNet hypernym-hyponym relationships (similar to ImageNet). This dataset was recorded using a Kinect style 3D camera that records synchronized and aligned 640 x 480 pixel RGB and depth images at 30 Hz. This dataset also includes 8 annotated video sequences of natural scenes, containing objects from the dataset (the UW RGB-D Scenes Dataset).
UW RGB-D Object Dataset [ 164 ]包含使用Kinect风格的3D相机记录的300个常见家庭对象。对象被组织成51个类别,使用词网上下位关系(类似于ImageNet)排列。该数据集使用Kinect风格的3D相机以30 Hz的频率记录同步和对齐的640 × 480像素RGB和深度图像。这个数据集还包括8个自然场景的带注释的视频序列,包含来自数据集( UW RGB - D场景数据集)的对象。
ScanNet [165] is an RGB-D video dataset containing 2.5 million views in more than 1,500 scans, annotated with 3D camera poses, surface reconstructions, and instance-level semantic segmentations. To collect these data, an easy- to-use and scalable RGB-D capture system was designed that includes automated surface reconstruction, and the semantic annotation was crowd-sourced. Using this data helped achieve state-of-the-art performance on several 3D scene understanding tasks, including 3D object classification, semantic voxel labeling, and CAD model retrieval.
ScanNet [ 165 ]是一个RGB - D视频数据集,包含超过1500次扫描中的250万个视图,带有3D相机姿态、表面重建和实例级语义分割的注解。为了收集这些数据,设计了一个易于使用和可扩展的RGB - D采集系统,其中包括自动表面重建,语义注释是众源的。使用这些数据有助于在一些3D场景理解任务上实现最先进的性能,包括3D对象分类、语义体素标记和CAD模型检索。
4.3 3D Datasets
3D image datasets are popular in robotic, medical image analysis, 3D scene analysis, and construction applications. Three dimensional images are usually provided via meshes or other volumetric representations, such as point clouds. Here, we mention some of the popular 3D datasets.
3D图像数据集在机器人、医学图像分析、3D场景分析和建筑应用中非常流行。三维图像通常通过网格或其他体积表示提供,例如点云。在这里,我们提到了一些流行的3D数据集。
Stanford 2D-3D: This dataset provides a variety of mutually registered modalities from 2D, 2.5D and 3D domains, with instance-level semantic and geometric annotations [166], and is collected in 6 indoor areas. It contains over 70,000 RGB images, along with the corresponding depths, surface normals, semantic annotations, global XYZ images as well as camera information.
斯坦福2D - 3D:该数据集提供了来自2D、2.5 D和3D域的多种相互注册的模态,具有实例级语义和几何注释[ 166 ],并在6个室内区域收集。它包含超过70,000张RGB图像,以及相应的深度、表面法线、语义标注、全局XYZ图像和相机信息。
ShapeNet Core: ShapeNetCore is a subset of the full ShapeNet dataset [167] with single clean 3D models and manually verified category and alignment annotations [168]. It covers 55 common object categories with about 51,300 unique 3D models.
Shape Net Core:Shape Net Core是全Shape Net数据集的子集[ 167 ],包含单个干净的三维模型和人工验证的类别和对齐标注[ 168 ]。它涵盖了55个常见的物体类别,约有51300个独特的三维模型。
Sydney Urban Objects Dataset: This dataset contains a variety of common urban road objects, collected in the central business district of Sydney, Australia. There are 631 individual scans of objects across classes of vehicles, pedestrians, signs and trees [169].
Sydney Urban Objects数据集:该数据集包含在澳大利亚悉尼市中心商业区收集的各种常见城市道路对象。在车辆、行人、标志和树木的类别中,有631个物体的单独扫描[ 169 ]。
5 Performance Review
In this section, we first provide a summary of some of the popular metrics used in evaluating the performance of segmentation models, and then we provide the quantitative performance of the promising DL-based segmentation models on popular datasets.
在本节中,我们首先总结了一些用于评估分割模型性能的流行指标,然后我们在流行的数据集上提供了有前途的基于DL的分割模型的定量性能。
5.1 Metrics For Segmentation Models
Ideally, a model should be evaluated in multiple respects, such as quantitative accuracy, speed (inference time), and storage requirements (memory footprint). However, most of the research works so far, focus on the metrics for evaluating the model accuracy. Below we summarize the most popular metrics for assessing the accuracy of segmentation algorithms. Although quantitative metrics are used to compare different models on benchmarks, the visual quality of model outputs is also important in deciding which model is best (as human is the final consumer of many of the models developed for computer vision applications).
理想情况下,一个模型应该在多个方面进行评估,例如量化精度、速度(推断时间)和存储需求(内存占用)。然而,迄今为止的大多数研究工作都集中在评估模型准确性的指标上。下面我们总结了用于评估分割算法准确性的最流行的度量。虽然在基准测试集上使用定量的指标来比较不同的模型,但是模型输出的视觉质量也是决定哪个模型是最好的(因为人类是为计算机视觉应用开发的许多模型的最终消费者)的重要因素。
Pixel accuracy simply finds the ratio of pixels properly classified, divided by the total number of pixels. For K + 1 classes (K foreground classes and the background) pixel accuracy is defined as Eq 1:
像素精度只是找到正确分类的像素的比例,除以像素总数。对于K + 1类,( K个前景类和背景)像素精度定义为式( 1 ):
where pij is the number of pixels of class i predicted as belonging to class j.
其中pij是第i类预测为属于第j类的像素的数目。
Mean Pixel Accuracy (MPA) is the extended version of PA, in which the ratio of correct pixels is computed in a per-class manner and then averaged over the total number of classes, as in Eq 2:
平均像素精度( MPA )是PA的扩展版本,其中正确像素的比例按类计算,然后在总类数上平均,如公式2所示:
Intersection over Union (IoU) or the Jaccard Index is one of the most commonly used metrics in semantic segmentation. It is defined as the area of intersection between the predicted segmentation map and the ground truth, divided by the area of union between the predicted segmentation map and the ground truth:
交并比(Intersection over Union,IoU,常常用来衡量目标检测任务中,预测结果的位置信息的准确程度。 )或Jaccard指数是语义分割中最常用的度量指标之一。它定义为预测分割图与地面真值的交集面积除以预测分割图与地面真值的并集面积:
(用数学中集合的语言来说,也就是两个区域的“交集”, 除以两个区域的“并集”)
where A and B denote the ground truth and the predicted segmentation maps, respectively. It ranges between 0 and 1.
式中:A和B分别表示地面真值和预测分割图。其范围在0到1之间。
Mean-IoU is another popular metric, which is defined as the average IoU over all classes. It is widely used in reporting the performance of modern segmentation algorithms.
Mean - IoU是另一种流行的度量方法,它定义为所有类的平均IoU。它被广泛用于报告现代分割算法的性能。
Precision/ Recall /F1 score are popular metrics for reporting the accuracy of many of the classical image segmentation models. Precision and recall can be defined for each class, as well as at the aggregate level, as follows:
Precision / Recall / F1 score是衡量许多经典图像分割模型精度的常用指标。精确率和召回率可以为每个类以及聚合级别定义,如下所示:
where TP refers to the true positive fraction, FP refers to the false positive fraction, and FN refers to the false negative fraction. Usually we are interested into a combined version of precision and recall rates. A popular such a metric is called the F1 score, which is defined as the harmonic mean of precision and recall:
其中TP为真阳性分数,FP为假阳性分数,FN为假阴性分数。通常我们感兴趣的是精确率和召回率的组合版本。一个流行的这样的度量被称为F1分数,它被定义为精确率和召回率的调和平均值:
Dice coefficient is another popular metric for image segmentation (and is more commonly used in medical image analysis), which can be defined as twice the overlap area of predicted and ground-truth maps, divided by the total number of pixels in both images. The Dice coefficient is very similar to the IoU:
Dice系数是另一种流行的图像分割度量指标(在医学图像分析中较为常用),它可以定义为预测图和真实图重叠区域的两倍,除以两幅图像中的像素总数。Dice系数与IoU非常相似:
When applied to boolean data (e.g., binary segmentation maps), and referring to the foreground as a positive class, the Dice coefficient is essentially identical to the F1 score, defined as Eq 7:
当应用于布尔型数据(例如,二值分割图),并将前景作为正类时,Dice系数与F1分数基本相同,定义为式( 7 ):
5.2 Quantitative Performance of DL-Based Models
In this section we tabulate the performance of several of the previously discussed algorithms on popular segmentation benchmarks. It is worth mentioning that although most models report their performance on standard datasets and use standard metrics, some of them fail to do so, making across-the-board comparisons difficult. Furthermore, only a small percentage of publications provide additional information, such as execution time and memory footprint, in a reproducible way, which is important to industrial applications of segmentation models (such as drones, self-driving cars, robotics, etc.) that may run on embedded consumer devices with limited computational power and storage, making fast, light-weight models crucial.
在本节中,我们列出了前面讨论的几种算法在流行的分割基准上的性能。值得一提的是,尽管大多数模型在标准数据集上报告了它们的性能,并使用了标准的度量标准,但其中一些模型却没有这样做,这使得全面的比较变得困难。此外,只有一小部分出版物以可重复的方式提供额外的信息,如执行时间和内存占用,这对于在计算能力和存储有限的嵌入式消费设备上运行的分割模型(如无人机、自动驾驶汽车、机器人等。)的工业应用非常重要,这使得快速、轻量级的模型变得至关重要。
The following tables summarize the performances of several of the prominent DL-based segmentation models on different datasets. Table 1 focuses on the PASCAL VOC test set. Clearly, there has been much improvement in the accuracy of the models since the introduction of the FCN, the first DL-based image segmentation model. Table 2 focuses on the Cityscape test dataset. The latest models feature about 23% relative gain over the initial FCN model on this dataset. Table 3 focuses on the MS COCO stuff test set. This dataset is more challenging than PASCAL VOC, and Cityescapes, as the highest mIoU is approximately 40%. Table 4 focuses on the ADE20k validation set. This dataset is also more challenging than the PASCAL VOC and Cityescapes datasets.
下表总结了几个著名的基于DL的分割模型在不同数据集上的性能。表1重点介绍了PASCAL VOC测试集。显然,自从引入第一个基于DL的图像分割模型FCN以来,模型的精度有了很大的提高。表2重点介绍了Cityscape测试数据集。最新的模型在该数据集上比初始FCN模型有约23 %的相对增益。表3重点介绍了MS COCO素材测试集。该数据集比PASCAL VOC和Cityescapes更具挑战性,最高mIoU约为40 %。表4重点介绍了ADE20k验证集。该数据集也比PASCAL VOC和Cityescapes数据集更具挑战性。
Table 5 provides the performance of prominent instance segmentation algorithms on COCO test-dev 2017 dataset, in terms of average precision, and their speed. Table 6 provides the performance of prominent panoptic segmentation algo-rithms on MS-COCO val dataset, in terms of panoptic quality [138]. Finally, Table 7 summarizes the performance of several prominent models for RGB-D segmentation on the NYUD-v2 and SUN-RGBD datasets.
表5给出了突出实例分割算法在COCO test-dev 2017数据集上的平均精度和运行速度。表6提供了在MS - COCO val数据集上突出的全景分割算法在全景质量方面的性能[ 138 ]。最后,表7总结了几个显著的RGB - D分割模型在NYUD - v2和SUN - RGBD数据集上的性能。
To summarize the tabulated data, there has been significant progress in the performance of deep segmentation models over the past 5-6 years, with a relative improvement of 25%-42% in mIoU on different datasets. However, some publications suffer from lack of reproducibility for multiple reasons—they report performance on non-standard benchmarks/databases, or they report performance only on arbitrary subsets of the test set from a popular benchmark, or they do not adequately describe the experimental setup and sometimes evaluate the model performance only on a subset of object classes. Most importantly, many publications do not provide the source-code for their model implementations. However, with the increasing popularity of deep learning models, the trend has been positive and many research groups are moving toward reproducible frameworks and open-sourcing their implementations.
总结表中数据,在过去的5 ~ 6年中,深度分割模型的性能有了显著的进步,在不同数据集上的mIoU相对提高了25 % ~ 42 %。然而,一些出版物由于多种原因而缺乏可重复性——它们报告了在非标准基准/数据库上的性能,或者仅报告了在流行基准测试集中的任意子集上的性能,或者没有充分描述实验设置,有时仅在对象类的子集上评估模型性能。最重要的是,许多出版物并没有为它们的模型实现提供源代码。然而,随着深度学习模型的日益普及,这一趋势一直是积极的,许多研究小组正朝着可复制的框架和开源的实现方向发展。
TABLE 1
表1
分割模型在PASCAL VOC测试集上的准确率。( *指在另一个数据集上预训练的模型(如MS - COCO、ImageNet或JFT - 300M )) . )。
| Method | Backbone | mIoU |
| FCN [31] | VGG-16 | 62.2 |
| CRF-RNN [39] | 72.0 | |
| CRF-RNN* [39] | 74.7 | |
| BoxSup* [117] | 75.1 | |
| Piecewise* [40] | 78.0 | |
| DPN* [41] | 77.5 | |
| DeepLab-CRF [78] | ResNet-101 | 79.7 |
| GCN* [118] | ResNet-152 | 82.2 |
| RefineNet [115] | ResNet-152 | 84.2 |
| Wide ResNet [119] | WideResNet-38 | 84.9 |
| PSPNet [56] | ResNet-101 | 85.4 |
| DeeplabV3 [12] | ResNet-101 | 85.7 |
| PSANet [98] | ResNet-101 | 85.7 |
| EncNet [114] | ResNet-101 | 85.9 |
| DFN* [99] | ResNet-101 | 86.2 |
| Exfuse [120] | ResNet-101 | 86.2 |
| SDN* [45] | DenseNet-161 | 86.6 |
| DIS [123] | ResNet-101 | 86.8 |
| DM-Net* [58] | ResNet-101 | 87.06 |
| APC-Net* [60] | ResNet-101 | 87.1 |
| EMANet [95] | ResNet-101 | 87.7 |
| DeeplabV3+ [83] | Xception-71 | 87.8 |
| Exfuse [120] | ResNeXt-131 | 87.9 |
| MSCI [61] | ResNet-152 | 88.0 |
| EMANet [95] | ResNet-152 | 88.2 |
| DeeplabV3+* [83] | Xception-71 | 89.0 |
| EfficientNet+NAS-FPN [135] | - | 90.5 |
TABLE 2
Accuracies of segmentation models on the Cityescapes dataset.
表2
分割模型在Cityescapes数据集上的准确性。
| Method | Backbone | mIoU |
| FCN-8s [31] | - | 65.3 |
| DPN [41] | - | 66.8 |
| Dilation10 [79] | - | 67.1 |
| DeeplabV2 [78] | ResNet-101 | 70.4 |
| RefineNet [115] | ResNet-101 | 73.6 |
| FoveaNet [124] | ResNet-101 | 74.1 |
| Ladder DenseNet [125] | Ladder DenseNet-169 | 73.7 |
| GCN [118] | ResNet-101 | 76.9 |
| DUC-HDC [80] | ResNet-101 | 77.6 |
| Wide ResNet [119] | WideResNet-38 | 78.4 |
| PSPNet [56] | ResNet-101 | 85.4 |
| BiSeNet [126] | ResNet-101 | 78.9 |
| DFN [99] | ResNet-101 | 79.3 |
| PSANet [98] | ResNet-101 | 80.1 |
| DenseASPP [81] | DenseNet-161 | 80.6 |
| SPGNet [127] | 2xResNet-50 | 81.1 |
| DANet [93] | ResNet-101 | 81.5 |
| CCNet [96] | ResNet-101 | 81.4 |
| DeeplabV3 [12] | ResNet-101 | 81.3 |
| AC-Net [129] | ResNet-101 | 82.3 |
| OCR [44] | ResNet-101 | 82.4 |
| GS-CNN [128] | WideResNet | 82.8 |
| HRNetV2+OCR (w/ASPP) [44] | HRNetV2-W48 | 83.7 |
| Hierarchical MSA [137] | HRNet-OCR | 85.1 |
TABLE 3
Accuracies of segmentation models on the MS COCO stuff dataset.
表3
MS COCO材料数据集上分割模型的精度。
| Method | Backbone | mIoU |
| RefineNet [115] | ResNet-101 | 33.6 |
| CCN [59] | Ladder DenseNet-101 | 35.7 |
| DANet [93] | ResNet-50 | 37.9 |
| DSSPN [130] | ResNet-101 | 37.3 |
| EMA-Net [95] | ResNet-50 | 37.5 |
| SGR [131] | ResNet-101 | 39.1 |
| OCR [44] | ResNet-101 | 39.5 |
| DANet [93] | ResNet-101 | 39.7 |
| EMA-Net [95] | ResNet-50 | 39.9 |
| AC-Net [129] | ResNet-101 | 40.1 |
| OCR [44] | HRNetV2-W48 | 40.5 |
TABLE4
Accuracies of segmentation models on the ADE20k validation dataset.
表4
分割模型在ADE20k验证数据集上的准确性。
| Method | Backbone | mIoU |
| FCN [31] | - | 29.39 |
| DilatedNet [79] | - | 32.31 |
| CascadeNet [132] | - | 34.9 |
| RefineNet [115] | ResNet-152 | 40.7 |
| PSPNet [56] | ResNet-101 | 43.29 |
| PSPNet [56] | ResNet-269 | 44.94 |
| EncNet [114] | ResNet-101 | 44.64 |
| SAC [133] | ResNet-101 | 44.3 |
| PSANet [98] | ResNet-101 | 43.7 |
| UperNet [134] | ResNet-101 | 42.66 |
| DSSPN [130] | ResNet-101 | 43.68 |
| DM-Net [58] | ResNet-101 | 45.5 |
| AC-Net [129] | ResNet-101 | 45.9 |
TABLE 5
Instance Segmentation Models Performance on COCO test-dev 2017
实例分割模型在 COCO test-dev 2017 上的表现
| Method | Backbone | FPS | AP |
| YOLACT-550 [76] | R-101-FPN | 33.5 | 29.8 |
| YOLACT-700 [76] | R-101-FPN | 23.8 | 31.2 |
| RetinaMask [170] | R-101-FPN | 10.2 | 34.7 |
| TensorMask [69] | R-101-FPN | 2.6 | 37.1 |
| SharpMask [171] | R-101-FPN | 8.0 | 37.4 |
| Mask-RCNN [64] | R-101-FPN | 10.6 | 37.9 |
| CenterMask [74] | R-101-FPN | 13.2 | 38.3 |
TABLE 6
Panoptic Segmentation Models Performance on the MS-COCO val dataset. * denotes use of deformable convolution.
表6
全景分割模型在MS - COCO val数据集上的性能。*表示使用可变形卷积。
| Method | Backbone | PQ |
| Panoptic FPN [139] | ResNet-50 | 39.0 |
| Panoptic FPN [139] | ResNet-101 | 40.3 |
| AU-Net [140] | ResNet-50 | 39.6 |
| Panoptic-DeepLab [142] | Xception-71 | 39.7 |
| OANet [172] | ResNet-50 | 39.0 |
| OANet [172] | ResNet-101 | 40.7 |
| AdaptIS [173] | ResNet-50 | 35.9 |
| AdaptIS [173] | ResNet-101 | 37.0 |
| UPSNet* [143] | ResNet-50 | 42.5 |
| OCFusion* [174] | ResNet-50 | 41.3 |
| OCFusion* [174] | ResNet-101 | 43.0 |
| OCFusion* [174] | ResNeXt-101 | 45.7 |
TABLE 7
Performance of segmentation models on the NYUD-v2, and SUN-RGBD datasets, in terms of mIoU, and mean Accuracy (mAcc).
表7
分割模型在NYUD - v2和SUN - RGBD数据集上的m Io U和平均准确率( mAcc )。
| NYUD-v2 | SUN-RGBD | |||
| Method | m-Acc | m-IoU | m-Acc | m-IoU |
| Mutex [175] | - | 31.5 | - | - |
| MS-CNN [176] | 45.1 | 34.1 | - | - |
| FCN [31] | 46.1 | 34.0 | - | - |
| Joint-Seg [177] | 52.3 | 39.2 | - | - |
| SegNet [15] | - | - | 44.76 | 31.84 |
| Structured Net [40] | 53.6 | 40.6 | 53.4 | 42.3 |
| B-SegNet [43] | - | - | 45.9 | 30.7 |
| 3D-GNN [178] | 55.7 | 43.1 | 57.0 | 45.9 |
| LSD-Net [48] | 60.7 | 45.9 | 58.0 | - |
| RefineNet [115] | 58.9 | 46.5 | 58.5 | 45.9 |
| D-aware CNN [179] | 61.1 | 48.4 | 53.5 | 42.0 |
| RDFNet [180] | 62.8 | 50.1 | 60.1 | 47.7 |
| G-Aware Net [181] | 68.7 | 59.6 | 74.9 | 54.5 |
| MTI-Net [181] | 68.7 | 59.6 | 74.9 | 54.5 |
6 CHALLENGES AND OPPORTUNITIES
There is not doubt that image segmentation has benefited greatly from deep learning, but several challenges lie ahead. We will next introduce some of the promising research directions that we believe will help in further advancing image segmentation algorithms.
毫无疑问,图像分割从深度学习中获益良多,但仍面临若干挑战。下面我们将介绍一些我们认为有助于进一步推进图像分割算法的有前景的研究方向。
6.1 More Challenging Datasets
Several large-scale image datasets have been created for semantic segmentation and instance segmentation. However, there remains a need for more challenging datasets, as well as datasets for different kinds of images. For still images, datasets with a large number of objects and overlapping objects would be very valuable. This can enable training models that are better at handling dense object scenarios, as well as large overlaps among objects as is common in real-world scenarios.
已经创建了多个用于语义分割和实例分割的大规模图像数据集。然而,仍然需要更具挑战性的数据集,以及针对不同类型图像的数据集。对于静止图像,包含大量物体和重叠物体的数据集将非常有价值。这可以使训练模型能够更好地处理密集对象场景,以及在实际场景中常见的对象之间的大重叠。
With the rising popularity of 3D image segmentation, especially in medical image analysis, there is also a strong need for large-scale 3D images datasets. These datasets are more difficult to create than their lower dimensional counterparts. Existing datasets for 3D image segmentation available are typically not large enough, and some are synthetic, and therefore larger and more challenging 3D image datasets can be very valuable.
随着三维图像分割的日益普及,特别是在医学图像分析中,对大规模三维图像数据集的需求也越来越强烈。这些数据集比它们的低维数据集更难创建。现有的用于三维图像分割的数据集通常不够大,而且有些是合成的,因此更大规模和更具挑战性的三维图像数据集可能非常有价值。
6.2 Interpretable Deep Models
While DL-based models have achieved promising performance on challenging benchmarks, there remain open questions about these models. For example, what exactly are deep models learning? How should we interpret the features learned by these models? What is a minimal neural architecture that can achieve a certain segmentation accuracy on a given dataset? Although some techniques are available to visualize the learned convolutional kernels of these models, a concrete study of the underlying behavior/dynamics of these models is lacking. A better understanding of the theoretical aspects of these models can enable the development of better models curated toward various segmentation scenarios.
虽然基于DL的模型在具有挑战性的基准测试集上取得了良好的性能,但这些模型仍然存在一些问题。例如,深度模型学习到底是什么?我们应该如何解释这些模型学习到的特征?什么是能够在给定数据集上达到一定分割精度的最小神经架构?虽然有一些技术可以可视化这些模型的学习卷积核,但缺乏对这些模型潜在行为/动力学的具体研究。更好地理解这些模型的理论方面,可以针对不同的分割场景开发更好的模型。
6.3 Weakly-Supervised and Unsupervised Learning
Weakly-supervised (a.k.a. few shot learning) [182] and un-supervised learning [183] are becoming very active research areas. These techniques promise to be specially valuable for image segmentation, as collecting labeled samples for segmentation problem is problematic in many application domains, particularly so in medical image analysis. The transfer learning approach is to train a generic image segmentation model on a large set of labeled samples (perhaps from a public benchmark), and then fine-tune that model on a few samples from some specific target application. Self-supervised learning is another promising direction that is attracting much attraction in various fields. There are many details in images that that can be captured to train a segmentation models with far fewer training samples, with the help of self-supervised learning. Models based on reinforcement learning could also be another potential future direction, as they have scarcely received attention for image segmentation. For example, MOREL [184] introduced a deep reinforcement learning approach for moving object segmentation in videos.
弱监督( a.k.a.小样本学习) [ 182 ]和无监督学习[ 183 ]正成为非常活跃的研究领域。这些技术对于图像分割具有特殊的价值,因为在许多应用领域,特别是医学图像分析中,为分割问题收集标记样本是一个难题。迁移学习方法是在大量标记样本(也许从一个公共基准)上训练一个通用的图像分割模型,然后在一些特定目标应用的少量样本上微调该模型。自监督学习是另一个很有前景的方向,在各个领域都引起了广泛的关注。在自监督学习的帮助下,图像中存在许多细节可以被捕获,以训练一个训练样本少得多的分割模型。基于强化学习的模型也可能是另一个潜在的未来方向,因为它们很少受到图像分割的关注
6.4 Real-time Models for Various Applications
In many applications, accuracy is the most important factor; however, there are applications in which it is also critical to have segmentation models that can run in near real-time, or at least near common camera frame rates (at least 25 frames per second). This is useful for computer vision systems that are, for example, deployed in autonomous vehicles. Most of the current models are far from this frame-rate; e.g., FCN- 8 takes roughly 100 ms to process a low-resolution image. Models based on dilated convolution help to increase the speed of segmentation models to some extent, but there is still plenty of room for improvement.
在许多应用中,精度是最重要的因素;然而,在一些应用中,拥有能够运行在近实时,或至少接近普通相机帧率(每秒至少25帧)的分割模型也是至关重要的。这对于部署在自动驾驶汽车中的计算机视觉系统是有用的。目前的大多数模型都与这个帧率相差甚远;例如,FCN - 8处理一幅低分辨率图像大约需要100 ms。基于空洞卷积的模型在一定程度上有助于提高分割模型的速度,但仍有很大的提升空间。
6.5 Memory Efficient Models
Many modern segmentation models require a significant amount of memory even during the inference stage. So far, much effort has been directed towards improving the accuracy of such models, but in order to fit them into specific devices, such as mobile phones, the networks must be simplified. This can be done either by using simpler models, or by using model compression techniques, or even training a complex model and then using knowledge distillation techniques to compress it into a smaller, memory efficient network that mimics the complex model.
许多现代分割模型即使在推理阶段也需要大量的内存。迄今为止,人们一直致力于提高这类模型的准确性,但为了将它们拟合到特定的设备中,如手机,必须对网络进行简化。这可以通过使用更简单的模型来完成,也可以通过使用模型压缩技术来完成,甚至可以训练一个复杂的模型,然后使用知识蒸馏技术将其压缩到一个较小的、内存有效的网络中,以模拟复杂的模型。
6.6 3D Point-Cloud Segmentation
Numerous works have focused on 2D image segmentation, but much fewer have addressed 3D point-cloud segmentation. However, there has been an increasing interest in point-cloud segmentation, which has a wide range of applications, in 3D modeling, self-driving cars, robotics, building modeling, etc. Dealing with 3D unordered and unstructured data such as point clouds poses several challenges. For example, the best way to apply CNNs and other classical deep learning architectures on point clouds is unclear. Graph-based deep models can be a potential area of exploration for point-cloud segmentation, enabling additional industrial applications of these data.
大量的工作集中于二维图像分割,而对三维点云分割的研究较少。然而,点云分割在三维建模、无人驾驶汽车、机器人、建筑物建模等方面有着广泛的应用,引起了人们越来越多的兴趣。处理点云等三维无序、非结构化数据带来了若干挑战。例如,CNNs和其他经典深度学习架构在点云上的最佳应用方式尚不清楚。基于图的深度模型可以成为点云分割的潜在探索领域,从而实现这些数据的附加工业应用。
6.7 Application Scenarios
In this section, we briefly investigate some application scenarios of recent DL-based segmentation methods, and some challenges ahead. Most notably, these methods have been successfully applied to segment satellite images in the field of remote sensing [185], including techniques for urban planning [186] or precision agriculture [187]. Remote sensing images collected by airborne platforms [188] and drones [189] have also been segmented using DL-based techniques, offering the opportunity to address important environmental problems such as those involving climate change. The main challenges of segmenting this kind of images are related to the very large dimensionality of the data (often collected by imaging spectrometers with hundreds or even thousands of spectral bands) and the limited ground-truth information to evaluate the accuracy of the results obtained by segmentation algorithms. Another very important application field for DL- based segmentation has been medical imaging [190]. Here, an opportunity is to design standardized image databases that can be used to evaluate fast spreading new diseases and pandemics. Last but not least, we should also mention DL-based segmentation techniques in biology [191] and evaluation of construction materials [192], which offer the opportunity to address highly relevant application domains but are subject to challenges related to the massive volume of the related image data and the limited reference information for validation purposes.
在本节中,我们简要调研了近期基于DL的分割方法的一些应用场景,以及面临的一些挑战。最值得注意的是,这些方法已经成功应用于遥感领域的卫星图像分割[ 185 ],包括用于城市规划[ 186 ]或精准农业[ 187 ]的技术。机载平台[ 188 ]和无人机[ 189 ]收集的遥感图像也已使用基于DL的技术进行分割,为解决涉及气候变化等重要环境问题提供了机会。分割这类图像的主要挑战与数据(常被光谱波段数百甚至上千的成像光谱仪采集)的维度非常大以及用于评价分割算法所得结果准确性的地物信息有限有关。基于DL分割的另一个非常重要的应用领域是医学成像[ 190 ]。在这里,一个机会是设计标准化的图像数据库,可用于评估快速传播的新疾病和流行病。最后,我们还应该提到生物学中基于DL的分割技术[ 191 ]和建筑材料的评估[ 192 ],它们提供了解决高度相关的应用领域的机会,但也面临着相关图像数据的海量性和用于验证的参考信息有限的挑战。
7 CONCLUSIONS
We have surveyed more than 100 recent image segmentation algorithms based on deep learning models, which have achieved impressive performance in various image segmentation tasks and benchmarks, grouped into ten categories such as: CNN and FCN, RNN, R-CNN, dilated CNN, attention-based models, generative and adversarial models, among others. We summarized quantitative performance analyses of these models on some popular benchmarks, such as the PASCAL VOC, MS COCO, Cityscapes, and ADE20k datasets. Finally, we discussed some of the open challenges and potential research directions for image segmentation that could be pursued in the coming years.
我们调查了 100 多种基于深度学习模型的最新图像分割算法,它们在各种图像分割任务和基准测试中取得了令人印象深刻的性能,分为十类,例如:CNN 和 FCN、RNN、R-CNN、dilated CNN、attention 基于模型、生成模型和对抗模型等。 我们总结了这些模型在一些流行基准上的定量性能分析,例如 PASCAL VOC、MS COCO、Cityscapes 和 ADE20k 数据集。 最后,我们讨论了未来几年可以追求的图像分割的一些开放挑战和潜在研究方向。
ACKNOWLEDGMENTS
The authors would like to thank Tsung-Yi Lin from Google Brain, and Jingdong Wang and Yuhui Yuan from Microsoft Research Asia, for reviewing this work, and providing very helpful comments and suggestions.
作者要感谢来自 Google Brain 的 Tsung-Yi Lin 和来自微软亚洲研究院的 Jingdong Wang 和 Yuhui Yuu 审阅了这项工作,并提供了非常有帮助的意见和建议。

