
- 1LightPicture精致图床PHP系统源码+功能强大_图床源码
- 2uni-app 移动端登录页面
- 3常见的7种深度学习框架对比_不同深度学习框架的区别
- 42020-12-07_english bruce lin博客
- 5机器学习数学基础:常见分布与假设检验_均匀分布检验 假设检验
- 6前端Serverless:面向全栈的无服务架构实战 -- 1.Serverless综述(笔记)_前端 serverless
- 7python使用百度AipOCR来实现图像文字识别_百度ocr代码
- 8PyQt5可视化 7 饼图和柱状图实操案例 ③柱状图的实现【超详解】_pyqt 柱状图
- 9二分查找的模板_二分查找代码模板
- 10GPT指令百科全书,函4.0使用镜像地址_gpts4.0镜像
DBRX~
赞
踩
「太狂野了」。开源大模型王座再易主,1320亿参数DBRX上线,基础、微调模型都有
这是迄今为止最强大的开源大语言模型,超越了 Llama 2、Mistral 和马斯克刚刚开源的 Grok-1。
本周三,大数据人工智能公司 Databricks 开源了通用大模型 DBRX,这是一款拥有 1320 亿参数的混合专家模型(MoE)。
DBRX 的基础(DBRX Base)和微调(DBRX Instruct)版本已经在 GitHub 和 Hugging Face 上发布,可用于研究和商业用途。人们可以自行在公共、自定义或其他专有数据上运行和调整它们,也可以通过 API 的形式使用。
-
基础版:https://huggingface.co/databricks/dbrx-base
-
微调版:https://huggingface.co/databricks/dbrx-instruct
-
GitHub 链接:https://github.com/databricks/dbrx
DBRX 在语言理解、编程、数学和逻辑等方面轻松击败了目前业内领先的开源大模型,如 LLaMA2-70B、Mixtral 和 Grok-1。
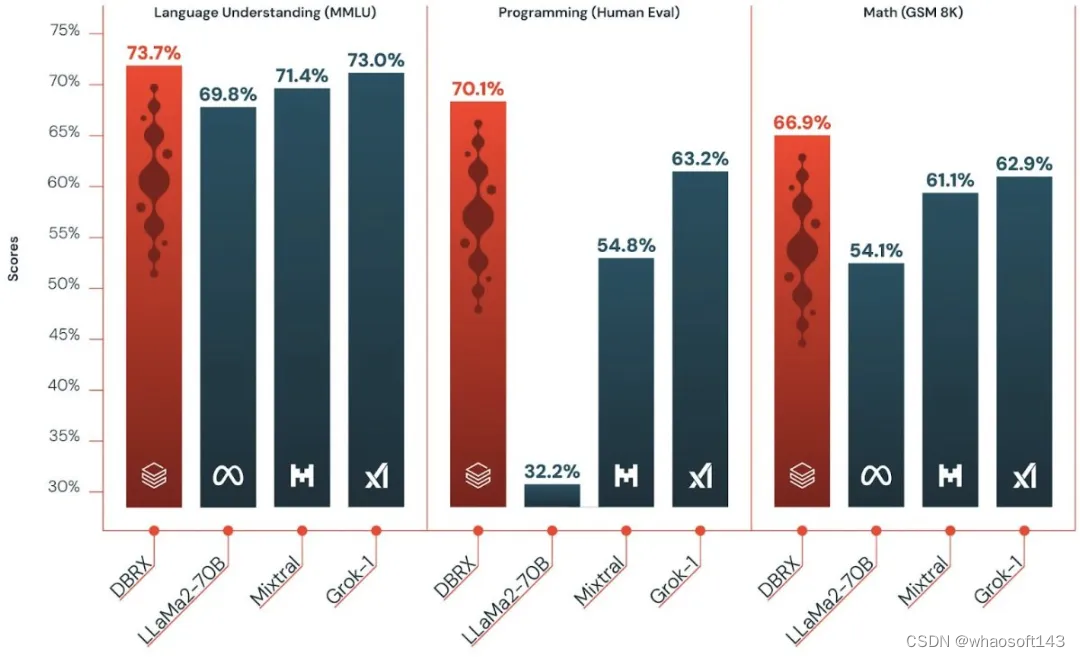
同时,DBRX 也在大多数基准测试上超过了 GPT-3.5,并在质量上可与 Gemini 1.0 Pro 和 Mistral Medium 竞争,同时速度大大加快。托管在 Mosaic AI Model Serving 上时,速度达到了 150 token/s/ 用户。
DBRX 的效率很高,它是基于斯坦福 MegaBlocks 开源项目构建的混合专家模型,平均只用激活 360 亿参数来处理 token,可以实现极高的每秒处理速度。它的推理速度几乎比 LLaMA2-70B 快两倍,总参数和活动参数数量比 Grok 小约 40%。
Databricks NLP 预训练团队负责人 Vitaliy Chiley 介绍道,DBRX 是在 12 万亿 Token 的文本和代码上预训练的 16×12B MoE LLM,它支持的最大上下文长度为 32k Tokens。
Hugging Face 工程师 Vaibhav Srivastav 表示,DBRX 模型「太狂野了」。
很多人第一时间进行了测试,有网友评论道,看起来 DBRX 可以应对非常晦涩的问题,又因为比 Grok 精简了三倍,若进行量化的话有望在 64GB RAM 的机器上运行,总之非常令人兴奋。
也有人直接表示,不贵的话我要付费用了。
除了开源社区、开发者们正在热烈讨论之外,DBRX 引来了各路媒体的报道,《连线》杂志直接将其称为「世界最强大的开源 AI 模型」。
通过一系列基准测试,DBRX 为当前开源大模型领域树立了新标杆。它为开源社区提供了以前仅限于封闭大模型 API 的能力,在基准分数上它超越了 GPT-3.5,与 Gemini 1.0 Pro 不分上下。它是一个强大的代码生成模型,除作为通用 LLM 的优势外,在编程方面超越了 CodeLLaMA-70B 等专业模型。
训练混合专家模型是一件困难的工作,Databricks 表示,它希望公开构建开源模型所涉及的大部分成果,包括 Meta 在 Llama 2 模型上没有公开过的一些关键细节。
DBRX 大模型,使用领先架构
DBRX 是一种基于 Transformer 的仅解码器大语言模型(LLM),使用细粒度的专家混合(MoE)架构,共有 1320 亿参数,其中 36B 个参数在任何输入上都处于激活状态。该模型是在 12T 文本和代码数据 token 上预训练而成,最大上下文长度高达 32k。
与 Mixtral 和 Grok-1 等其他开源 MoE 模型相比,DBRX 是细粒度的,这意味着它使用了更多数量的小型专家。DBRX 有 16 个专家模型,从中选择 4 个使用,而 Mixtral 和 Grok-1 有 8 个专家模型,选择其中 2 个。算下来,DBRX 提供了 65 倍可能的专家组合,这种组合方式的倍增提高了模型质量。
与此同时,DBRX 使用旋转位置编码 (RoPE)、门控线性单元 (GLU) 和分组查询注意力 (GQA) 等技术来提高模型质量。此外,DBRX 还使用了 tiktoken 存储库中提供的 GPT-4 分词器。
DBRX 与开源模型比较
表 1 显示了 DBRX Instruct 和领先的开源模型比较结果。可以看出,DBRX Instruct 在两个综合基准(composite benchmarks)、编程和数学基准以及 MMLU 方面表现优越。具体而言:
综合基准。包括 Hugging Face Open LLM Leaderboard(ARC-Challenge、HellaSwag、MMLU、TruthfulQA、WinoGrande 和 GSM8k 的平均分)以及 Databricks Model Gauntlet(涵盖 6 个领域、超过 30 项任务,包含世界知识、常识推理、语言理解、阅读理解、符号问题和编程) 。
DBRX Instruct 在两个综合基准上得分最高:在 Hugging Face 开源 LLM 排行榜上的得分为 74.5% ,而排名第二的模型 Mixtral Instruct 为 72.7%;在 Databricks Gauntlet 上的表现为 66.8% ,位于第二名的 Mixtral Instruct 为 60.7%。
编程和数学:DBRX Instruct 在编程和数学方面尤其擅长。
在 HumanEval 上的评估结果高于其他开源模型,DBRX Instruct 表现为 70.1%,Grok-1 为 63.2%、 Mixtral Instruct 为 54.8%、性能最好的 LLaMA2-70B 变体为 32.2%。
在 GSM8k 基准上,DBRX Instruct 表现为 66.9%,Grok-1 为 62.9%、 Mixtral Instruct 为 61.1%、性能最好的 LLaMA2-70B 变体为 54.1%。
综合来看,DBRX 的性能优于 Grok-1,后者是这些基准测试中排名第二的模型,尽管 Grok-1 的参数数量是 DBRX 的 2.4 倍。在 HumanEval 上,DBRX Instruct 甚至超越了 CodeLLaMA-70B Instruct(一种专门为编程而构建的模型),尽管 DBRX Instruct 是为通用用途而设计、而不是专为编程构建(据 Meta 在 CodeLLaMA 博客中报道,HumanEval 上的得分为 70.1% vs. 67.8%) 。
MMLU。DBRX Instruct 的得分达到 73.7%,高于其他模型。
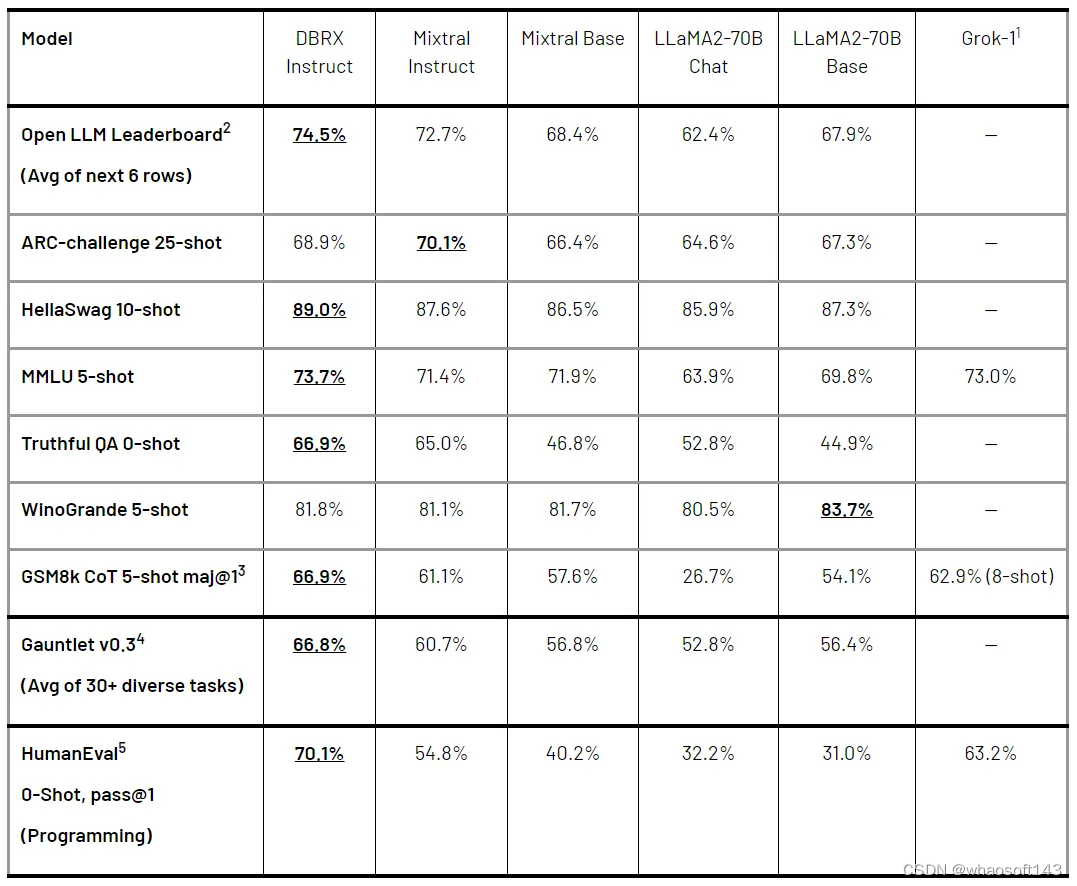
表 1. DBRX Instruct 和领先的开源模型比较。
DBRX 与闭源模型比较
表 2 显示了 DBRX Instruct 和领先的闭源模型比较结果。DBRX Instruct 超越了 GPT-3.5(如 GPT-4 论文中所述),并且与 Gemini 1.0 Pro 和 Mistral Medium 具有相当的竞争力。具体而言:
与 GPT-3.5 的比较。在多个基准测试中,DBRX Instruct 超过了 GPT-3.5,或者在某些基准上与 GPT-3.5 相当。DBRX Instruct 在 MMLU 上关于常识知识的得分为 73.7%,GPT-3.5 为 70.0%;在 HellaSwag 上的得分为 89.0% ,GPT-3.5 为 85.5%;在 WinoGrande 上为 81.8%,GPT-3.5 为 81.6%。根据 HumanEval(70.1% vs. 48.1%)和 GSM8k(72.8% vs. 57.1%)的测量结果表明,DBRX Instruct 尤其擅长编程和数学推理。
与 Gemini 1.0 Pro 和 Mistral Medium 的比较。DBRX Instruct 在与 Gemini 1.0 Pro 和 Mistral Medium 比较后,取得了具有竞争力的结果。DBRX Instruct 在 Inflection Corrected MTBench、MMLU、HellaSwag 和 HumanEval 上的得分高于 Gemini 1.0 Pro,而 Gemini 1.0 Pro 在 GSM8k 上的得分比 DBRX Instruct 要高。DBRX instruction 和 Mistral Medium 在 HellaSwag 上的得分相似,而 Mistral Medium 在 Winogrande 和 MMLU 上更强,DBRX instruction 在 HumanEval、GSM8k 和 Inflection Corrected MTBench 上更强。
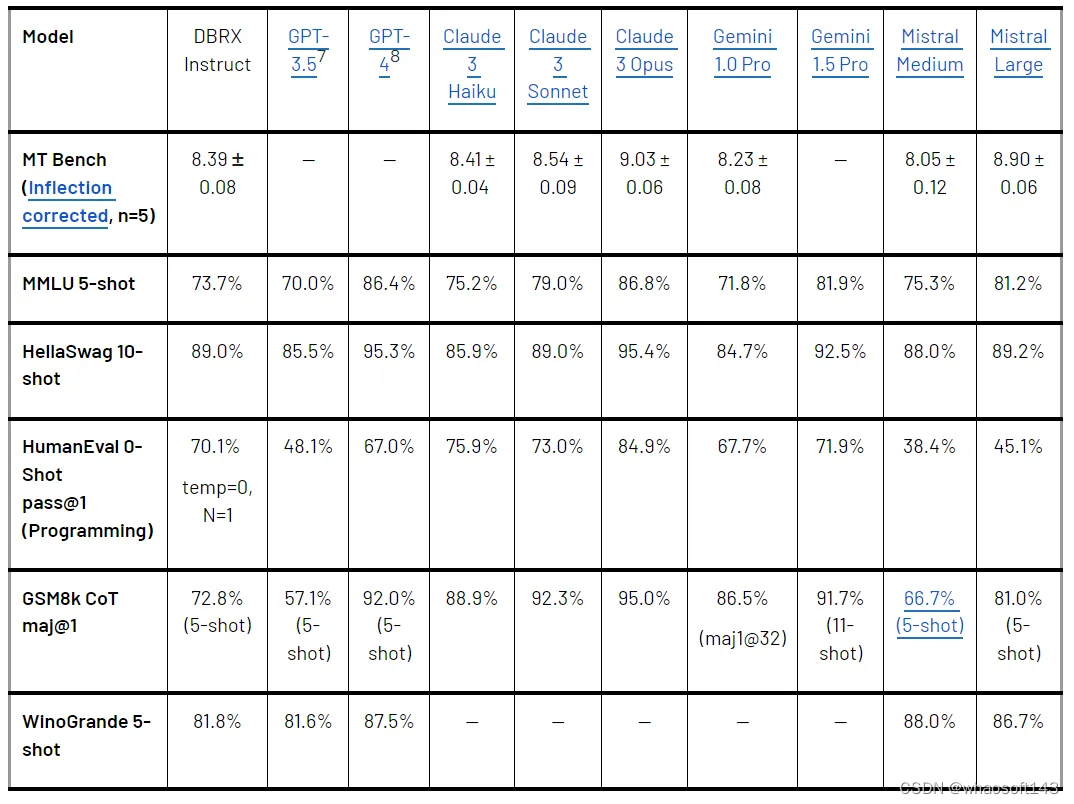
表 2.DBRX Instruct 与闭源模型的比较。
长下文任务和 RAG
DBRX Instruct 训练上下文窗口大小为 32K token。表 3 将其性能与 Mixtral Instruct 以及最新版本的 GPT-3.5 Turbo 和 GPT-4 Turbo API 在一系列长上下文基准测试上进行了比较。结果显示,GPT-4 Turbo 通常是执行这些任务的最佳模型。而 DBRX Instruct 表现比 GPT-3.5 Turbo 好;DBRX Instruct 和 Mixtral Instruct 的整体性能相似。
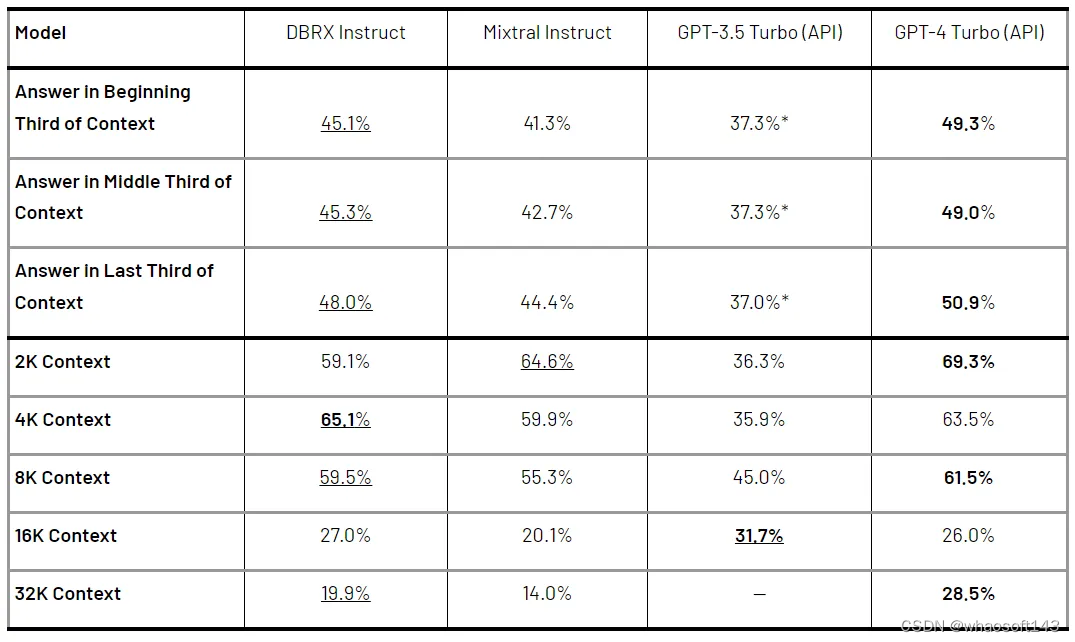
表 3. 在 KV-Pairs 和 HotpotQAXL 基准测试中,模型的平均性能。
表 4 显示了 DBRX 在两个 RAG 基准(Natural Questions 和 HotPotQA)上的质量。结果显示,DBRX Instruct 与 Mixtral Instruct 和 LLaMA2-70B Chat 等开源模型以及当前版本的 GPT-3.5 Turbo 具有竞争力。
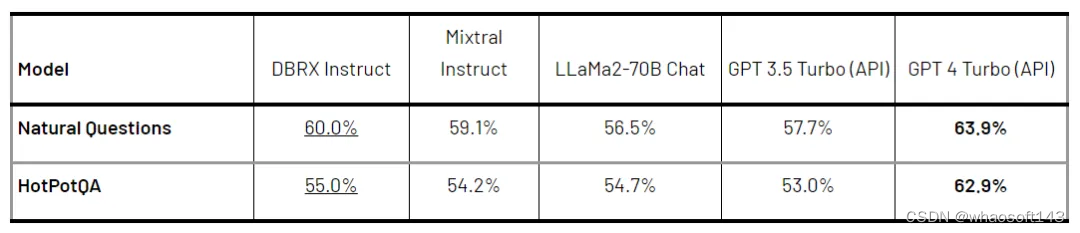
表 4. 模型在两个 RAG 基准上的结果。
训练效率
表现再好的模型也必须考虑训练和效率等因素,在 Databricks 尤其如此。
该研究发现训练混合专家模型可以显著提高训练的计算效率(表 5)。例如,在训练 DBRX 系列中较小的成员模型 DBRX MoE-B(23.5B 参数,6.6B 激活参数)时,在 Databricks LLM Gauntlet 上达到相同的 45.5% 分数 DBRX 所需的 FLOP 比 LLaMA2-13B 少 1.7 倍,而 DBRX MoE-B 只有 LLaMA2-13B 一半的激活参数。
研究人员表示,从整体上看,端到端的 LLM 预训练 pipeline 计算效率在过去十个月中提高了近 4 倍。此前,2023 年 5 月 ,Databricks 发布了 MPT-7B,这是一个在 1T token 上训练的 7B 参数模型,在 Databricks LLM Gauntlet 分数为 30.9%。此次 DBRX 系列的一个成员模型为 DBRX MoE-A(总参数 7.7B,激活参数 2.2B),Databricks Gauntlet 得分为 30.5%,而 FLOP 减少了 3.7 倍。这种效率的提升是建立在各种优化结果的基础上,包括使用 MoE 架构、对网络其他架构的更改、更好的优化策略、更好的 token 化,以及非常重要的更好的预训练数据。
从单个方面来讲,更好的预训练数据对模型质量产生了重大影响。该研究使用 DBRX 预训练数据在 1T token(称为 DBRX Dense-A)上训练了 7B 模型,它在 Databricks Gauntlet 上达到了 39.0%,而 MPT-7B 具有相同的 token 数,得分只有 30.9%。该研究估计,新的预训练数据至少比用于训练 MPT-7B 的数据好两倍,换句话说,达到相同模型质量只需要一半的 token 数量。研究者通过在 500B token 上训练 DBRX Dense-A 来确定这一点;它在 Databricks Gauntlet 上的表现超过了 MPT-7B,达到了 32.1%。除了数据质量更好外,另一个重要的贡献因素可能是 GPT-4 的分词器,它具有大词汇量,并且被认为特别有效率。

表 5.
推理效率
图 2 展示了使用 NVIDIA TensorRT-LLM 以及该研究优化后的服务基础设施,为 DBRX 及其类似模型提供端到端推理效率。
一般来说,MoE 模型的推理速度相比其模型要快。DBRX 在这方面也不例外,DBRX 推理吞吐量比 132B 非 MoE 模型高 2-3 倍。 whaosoft aiot http://143ai.com
众所周知,推理效率和模型质量通常是矛盾的:较大的模型一般质量都会高,但较小的模型推理效率更高。使用 MoE 架构可以在模型质量和推理效率之间实现比密集模型更好的权衡。例如,DBRX 的性能比 LLaMA2-70B 更高,并且由于激活参数数量约为 LLaMA2-70B 的一半,DBRX 推理吞吐量最高可提高 2 倍(图 2)。此外,DBRX 比 Mixtral 小,质量相应较低,但推理吞吐量更高。

图 2. 推理效率。
训练用了 3072 块 H100,这只是个开始
DBRX 开源后,Databricks 的首席科学家 Jonathan Frankle 表示,关于 DBRX 有很多故事可讲,包括我们是如何构建它、选择数据、设计课程、扩展 DBRX、学习 DBRX 的等等。最好的故事从现在开始,因为从此以后社区和企业都会以这种新模式起跑。
DBRX 是通过 3.2Tbps 的 Infiniband 连接 3072 块 NVIDIA H100 进行训练的,训练时间花费超过 3 个月,费用约 1000 万美元。构建 DBRX 的主要过程包括预训练、训练后调整、评估、red team 和精炼等过程。
若想在标准配置中运行 DBRX,你需要一台至少配备四个 Nvidia H100 GPU(或内存共 320GB 的任何其他 GPU 配置)的服务器或 PC。
Databricks 副总裁 Naveen Rao 在接受采访时表示,随着 DBRX 的研发团队 Mosaic Labs 不断推动生成式 AI 研究,Databricks 将持续完善 DBRX 并发布新版本。
参考链接:
https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
https://www.wired.com/story/dbrx-inside-the-creation-of-the-worlds-most-powerful-open-source-ai-model/

