
- 1QGIS加载天地图、高德地图
- 2ubuntu20.04搭建lamp环境 +制作网页_ubuntu20.04服务器搭建自己的个人网站
- 3基于机器学习算法和pytorch实现的深度学习模型的中文长文本多分类任务实战_长文本分类
- 4transformer、bert网络_bert模型和transformer区别
- 5【前后端接口AES+RSA混合加解密详解(vue+SpringBoot)附完整源码】_前后端加解密
- 6使用ChatGPT自动编写Python爬虫脚本使用ChatGPT自动编写Python爬虫脚本_chatgpt python 代码
- 7深度学习与神经网络_深度学习神经网络
- 8HarmonyOS鸿蒙开发环境搭建HUAWEI DevEco Studio安装教程_hormony os sdk11
- 9pytorch入门使用及前置知识(2)NLP_深度学习技术中shuffling types术语
- 10HarmonyOS应用事件打点开发指导_打点日志开发
【PyTorch实战演练】AlexNet网络模型构建并使用Cifar10数据集进行批量训练(附代码)_alexnet cifar10
赞
踩
目录
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文的写作目的主要有以下3点:
- 介绍经典卷积神经元网络——AlexNet;
- 基于AlexNet进行改造,使用PyTorch进行编码;
- 使用批量训练的方法,训练Cifar10数据集。
为什么非要对AlexNet进行改造呢?因为我们要训练的数据集Cifar10中的图片尺寸是32×32×3,比AlexNet输入224×224×3还要小。
当然,我们也可以选择先把Cifar10数据集transform成224×224×3的图像,而不用改造AlexNet的网络结构,但是这样有些“浪费”AlexNet的网络结构。
1. Cifar10数据集
Cifar10是一个包含10个类别的图像分类数据集,每个类别包含6000张32x32像素的RGB三通道彩色图像,总计60000张图像,其中50000个图像用于训练网络模型(训练组),10000个图像用于验证网络模型(验证组)。
关于Cifar10数据集的下载及解析,这里不再赘述,之前的文章有过详细说明:【PyTorch实战演练】使用Cifar10数据集训练LeNet5网络并实现图像分类(附代码)
2. AlexNet网络模型
AlexNet是深度学习领域中的一个经典卷积神经网络模型,由Geoffrey Hinton的学生Alex Krizhevsky和Ilya Sutskever在2012年《ImageNet Classification with Deep Convolutional Neural Networks》提出。AlexNet在ImageNet图像分类挑战赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)上获得了远远超过第二名的成绩,它的出现标志着深度学习在计算机视觉领域的爆发。
讲到这里可能有人会疑问本文为什么不直接用ImageNet数据集?因为这个数据集实在是太大了!作为学习实例实在没必要。(主要是我的电脑性能也跟不上……)
ILSVRC2012
|-Training images (Task 1 & 2). 138GB.|-Training images (Task 3). 728MB.|-Validation images (all tasks). 6.3GB.|-Test images (all tasks). 13GB.
相比于另一个经典的卷积神经网络模型LeNet,AlexNet的模型更深更广,这点通过模型参数数量可以直观地比较:LeNet总共有60,840个训练参数,而AlexNet的训练参数多达6000万个!
2.1 AlexNet的网络结构
AlexNet论文原文中的结构图:
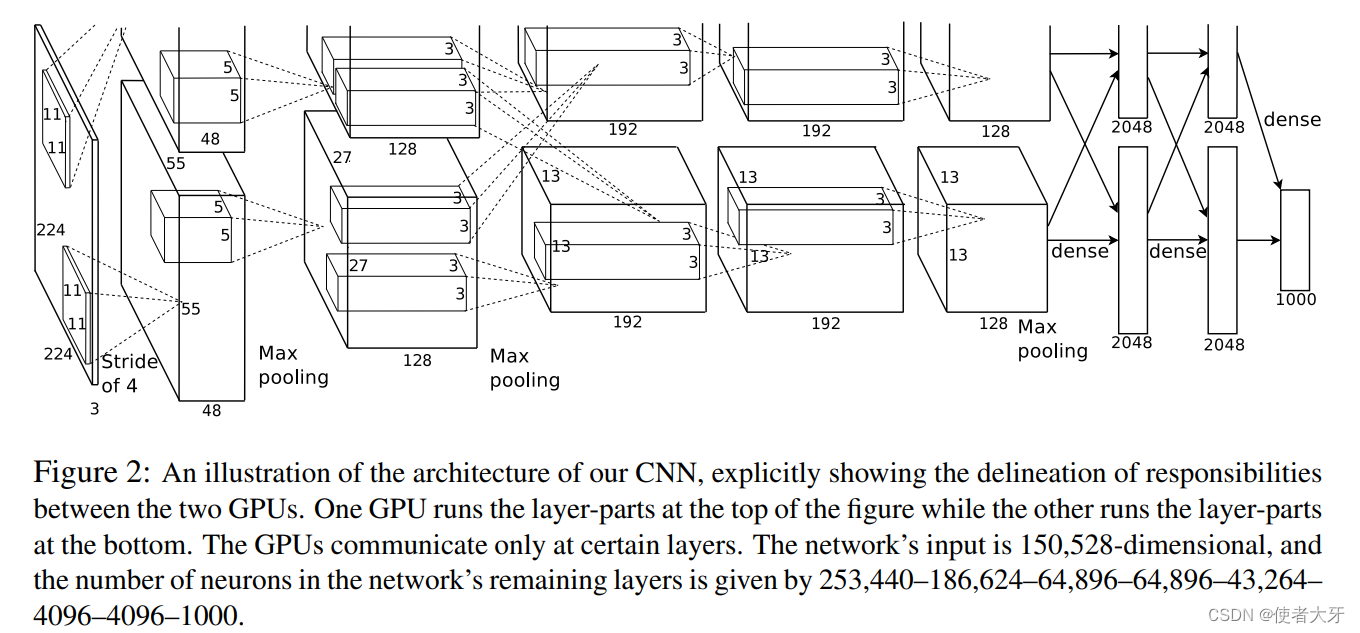
受限于当时GPU的性能,上面的结构图中分为了一模一样的上下两行,这是为了分在两个GPU中训练,而现在我们完全没必要这么做了。
加入每层的具体参数,我整理AlexNet的网络结构以及每层的输入输出张量维度如下:
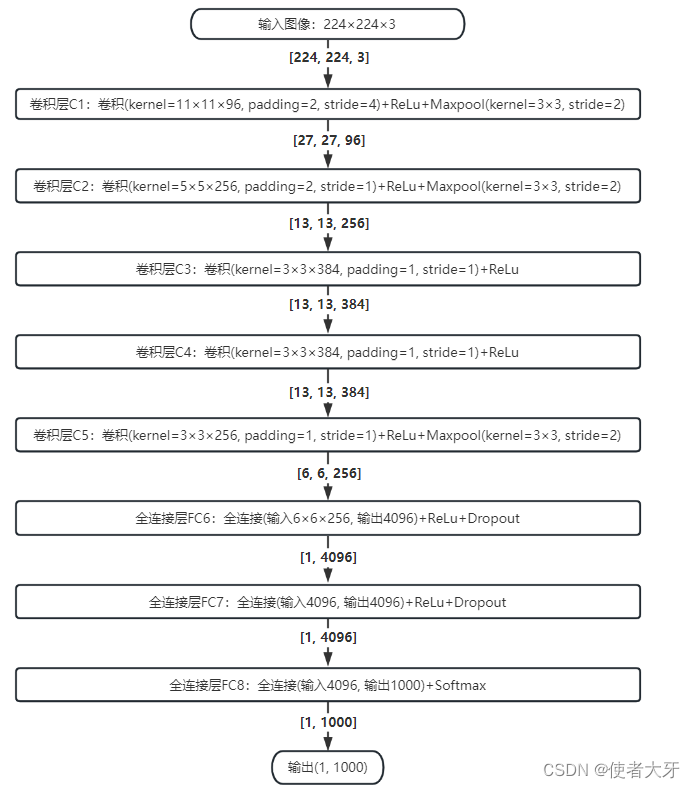
AlexNet网络整体由5个卷积层和3个全连接层构成,网络的输入为224×224的3通道图像,最终输出为长度1000的张量,代表1000个分类的置信度。
只要根据卷积层及池化层输出的特征图尺寸计算公式:
不难计算出过程中每层输出的特征图尺寸,计算结果也已在上图中标注出。
这里有必要说明下卷积层C1,因为按照输入=224,卷积核kernel=11,padding=2,stride=4,按照上面的公式计算的输出应该为55.25,不为整数。这时卷积层会向下取整,输出特征图为55。似乎看起来卷积层C1的卷积核设为kernel=12更为合理。
也有的文章说AlexNet输入图像尺寸为227×227×3,我不清楚这个说法是怎么来的,因为Alex的论文原文已经写明:The first convolutional layer filters the 224×224×3 input image。
2.2 激活函数ReLu
从网络结构上可以看出,除了最后一个全连接层选择Softmax作为激活函数(因为要进行归一化),其他所有层都清一色地选择了ReLu。Alex等人对比了ReLu和Tanh两个激活函数的训练错误率下降速度如下图所示:
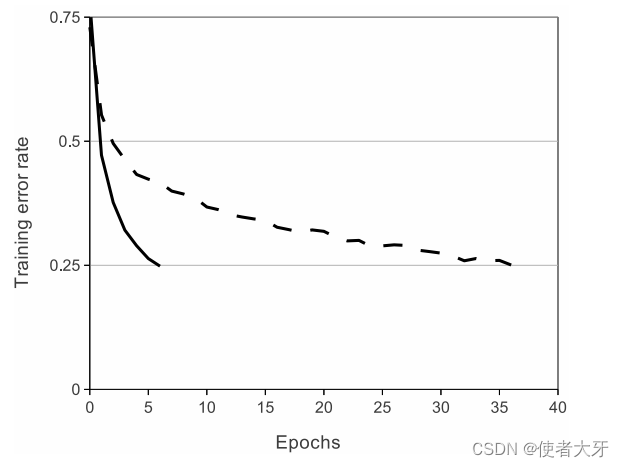
其中实线为ReLu,虚线为Tanh,可见选择ReLu作为激活函数比Tanh训练错误率下降速度要快得多(6倍)。而且这并不是针对某个特定的网络,在同样条件下(选用最快的学习率,不使用任何正则化方法),ReLu方法总是会比饱和神经元方法快几倍!
论文中的原文:The learning rates for each network were chosen independently to make training as fast as possible. No regularization of any kind was employed. The magnitude of the effect demonstrated here varies with network architecture, but networks with ReLUs consistently learn several times faster than equivalents with saturating neurons.
这里需要再解释下饱和神经元(saturating neurons)是指神经元的输出会限制在一定范围,例如Sigmoid限制在(0,1),Tanh限制在(-1,1),采用这些激活函数的神经元即为饱和神经元。不饱和神经元(non-saturating neurons)是指神经元的输出不会限制在某一范围,例如使用激活函数为ReLu的神经元。
2.3 Dropout方法
AlexNet在全连接层FC6和FC7引入了Dropout层,因为拥有6000万个参数的AlexNet算是比较复杂的深度学习网络,使用较小的数据集进行训练时容易出现过拟合的情况。
没错,即便是ILSVRC数据集对AlexNet来说,都只能算是一个“较小的”数据集。
Dropout方法的本质是随机将深度学习网络中某个单元(神经元)丢弃,即将其输出置0。Dropout层的引入提高了网络结构的鲁棒性,因为其使得网络中随机丢失一些神经元之后仍能保证输出的准确性。
Dropout方法的具体使用在此前的基于torch.nn.Dropout通过实例说明Dropout丢弃法(附代码)已详细介绍过了,这里也不在赘述。但是有一点我必须再强调下:
Dropout是一个训练深度学习网络的方法,在验证输出时需要取消Dropout!
顺便提一下,ReLu和Dropout也都是由Alex的老师Hinton提出的,可见有一个牛逼的老板……
Dropout是一种有效抑制过拟合的方法,但这是以牺牲训练速度为代价的。抑制过拟合的根本手段是要增大训练数据集,但是现实情况往往数据集的量十分有限,这时数据增强就非常有必要了!
2.4 数据增强
在AlexNet论文中介绍的数据增强主要有两个方法
- 图像切割和镜像:这个方法非常好理解,即从一个大图像中切割出若干个更小的图像,以及再基于这些图像做镜像。虽然从同一个图像中切割或者镜像出的小图像在训练结果上肯定有高度的相关性,但这仍是一个抑制过拟合的有效手段;
- 调整图像的RGB数值:这个方法操作起来比较复杂,可以简单理解其作用就相当于是给各个图像加了不同的“滤镜”。其详细原理非本文重点,感兴趣的童鞋可以参见:主成分分析(PCA)原理详解
3. 使用GPU加速进行批量训练
由于GPU在并行计算相比CPU有着巨大的优势,因此使用GPU进行批量训练可以节省大量的时间!
关于GPU和CPU的运算时间对比,可以参考我的往期文章:【PyTorch&TensorBoard实战】GPU与CPU的计算速度对比(附代码)
比如在训练Cifar10数据集时,我们可以让Batch_size=256个图片作为一个整体一起进行训练:

注意:这里的图像是我手工排列的,数据的真实size是[256, 3, 32, 32],即[batch_size, channel, H, W]。
使用.DataLoader()方法可以实现数据集的分批,以Cifar10数据为例,在PyTorch中的实现方法为:
- from torchvision import datasets
- import torch.utils.data as data
- import torch
- from torchvision import transforms
-
- batch_size = 256
-
- data_path = 'D:\\DL\\CIFAR10\\CIFAR10\\IMG_file' #数据集路径
- cifar10_train = datasets.CIFAR10(data_path, train=True, download=False,transform=transforms.ToTensor()) #第一次下载download要设定为True
- cifar10_train_loader = data.DataLoader(dataset=cifar10_train, batch_size=batch_size , shuffle=False)
在数据集分批后,使用.cuda()方法把分批后的数据发送到GPU上进行训练。
4. 网络模型构建
为了适配Cifar10数据集的尺寸32×32×3及输出类别只有10类,在AlexNet的网络结构基础上进行改造:

Python代码如下:
- class AlexNet(nn.Module):
- def __init__(self, dropout=0.9):
- super(AlexNet, self).__init__()
-
- self.model = nn.Sequential(
- nn.Conv2d(in_channels=3, out_channels=96, kernel_size=5, stride=1),
- nn.ReLU(),
- nn.Conv2d(in_channels=96, out_channels=256, kernel_size=2, stride=1),
- nn.ReLU(),
- nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=2),
- nn.ReLU(),
- nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
- nn.ReLU(),
- nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
- nn.ReLU(),
- nn.MaxPool2d(kernel_size=3, stride=2),
- nn.Flatten(),
- nn.Linear(in_features=256*6*6,out_features=4096),
- nn.ReLU(),
- nn.Dropout(p=dropout),
- nn.Linear(in_features=4096, out_features=256),
- nn.ReLU(),
- nn.Dropout(p=dropout),
- nn.Linear(in_features=256, out_features=10),
- nn.Softmax()
- )
-
-
- def forward(self,x):
- return self.model(x)
5. 训练过程
训练的损失函数采用交叉熵损失函数,优化器采用Adam,加入余弦退火自调整学习率方法。
自调整学习率方法可以参考【PyTorch实战演练】自调整学习率实例应用(附代码)
- criterion = nn.CrossEntropyLoss()
- opt = torch.optim.Adam(alexnet.parameters(),lr=initial_lr)
- scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=opt,T_max=100,last_epoch=-1)
训练过程如下图所示,整体采用了5段的分段训练,每段的迭代次数epoch以及初始学习率initial_lr已在图中标注出:
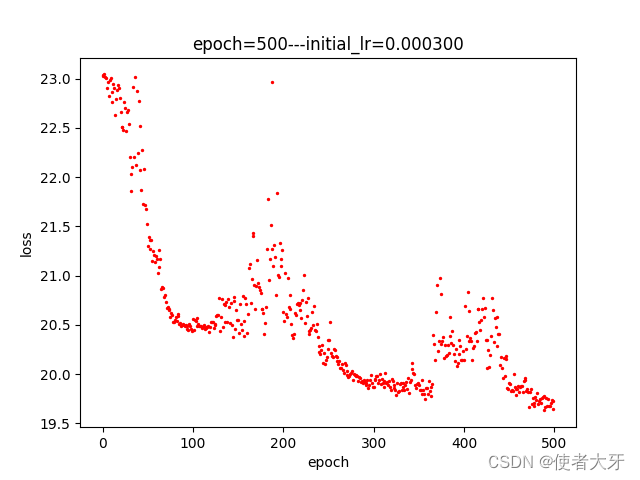
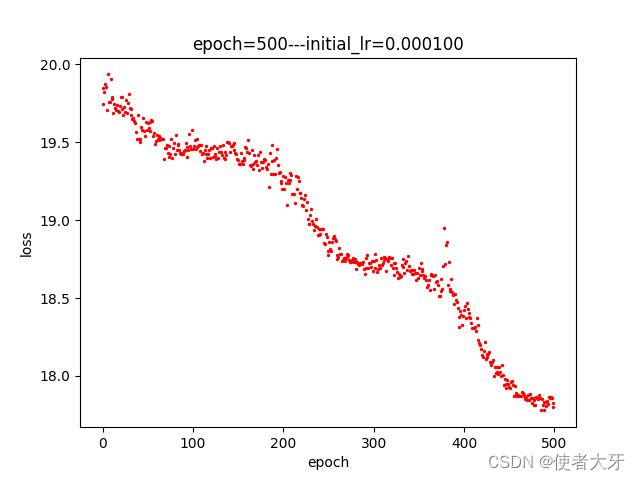


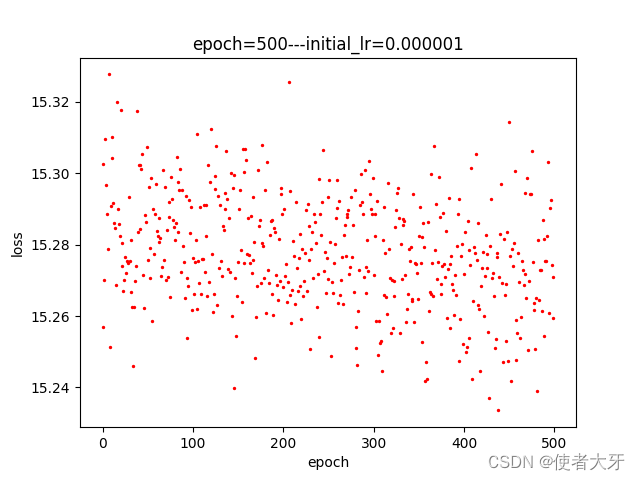
这里有两点需要说明下:
- 受限于电脑性能,我只训练了Cifar10的前2560张图像,即前10个Batch(即使这样整个训练也耗费了大概5~6个小时(T_T))
- 从上面训练过程可以看出,损失值下降到一定范围后,就不再下降,我认为这是dropout导致的。
6. 完整代码
- from torchvision import datasets
- import torch.utils.data as data
- import matplotlib.pyplot as plt
- import torch
- import torch.nn as nn
- from torchvision import transforms
- from tqdm import tqdm
-
- batch_size = 256
-
- data_path = 'D:\\DL\\CIFAR10\\CIFAR10\\IMG_file'
- cifar10_train = datasets.CIFAR10(data_path, train=True, download=False,transform=transforms.ToTensor())
-
- small_cifar10 = []
- for i in range(2560):
- small_cifar10.append(cifar10_train[i])
-
- cifar10_train_loader = data.DataLoader(dataset= small_cifar10, batch_size=batch_size , shuffle=False)
-
- cifar10_train_loader = list(cifar10_train_loader)
-
- class AlexNet(nn.Module):
- def __init__(self, dropout=0.9):
- super(AlexNet, self).__init__()
-
- self.model = nn.Sequential(
- nn.Conv2d(in_channels=3, out_channels=96, kernel_size=5, stride=1),
- nn.ReLU(),
- nn.Conv2d(in_channels=96, out_channels=256, kernel_size=2, stride=1),
- nn.ReLU(),
- nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=2),
- nn.ReLU(),
- nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
- nn.ReLU(),
- nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
- nn.ReLU(),
- nn.MaxPool2d(kernel_size=3, stride=2),
- nn.Flatten(),
- nn.Linear(in_features=256*6*6,out_features=4096),
- nn.ReLU(),
- nn.Dropout(p=dropout),
- nn.Linear(in_features=4096, out_features=256),
- nn.ReLU(),
- nn.Dropout(p=dropout),
- nn.Linear(in_features=256, out_features=10),
- nn.Softmax()
- )
-
-
- def forward(self,x):
- return self.model(x)
-
-
- alexnet = AlexNet(dropout=0.9).cuda()
- alexnet.load_state_dict(torch.load('weight/epoch=2000_initial_lr=0.000020.pth'))
-
- # img,label=cifar10_train_loader[0] #用于测试网络正向传播,正式代码中不用这两行
- # print(alexnet(img))
-
-
- def train(epoch, initial_lr):
-
- criterion = nn.CrossEntropyLoss()
- opt = torch.optim.Adam(alexnet.parameters(),lr=initial_lr)
- scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=opt,T_max=100,last_epoch=-1)
-
- for e in tqdm(range(epoch)):
- print('current %i epoch'%e)
- iter_loss = 0
- opt.zero_grad()
- for iter,(img,label) in enumerate(cifar10_train_loader):
- img = img.cuda()
- label = label.cuda()
- output = alexnet(img)
- loss = criterion(output, label)
-
- loss_plt = loss.detach()
- loss_plt = loss_plt.cpu()
- iter_loss = iter_loss+loss_plt
-
- loss.backward()
- opt.step()
-
- plt.scatter(e, iter_loss,s=2,c='r')
-
- scheduler.step()
-
- if __name__ == '__main__':
-
- epoch = 500
- initial_lr = 1e-6
- train(epoch, initial_lr)
-
- torch.save(alexnet.state_dict(), 'weight/epoch=%i_initial_lr=%f.pth'%(epoch, initial_lr))
-
- plt.title('epoch=%i---initial_lr=%f'%(epoch, initial_lr))
- plt.xlabel('epoch')
- plt.ylabel('loss')
- plt.show()
- plt.savefig('epoch=%i---initial_lr=%f.jpg'%(epoch, initial_lr))

