
【最新汇总】市面上的医学大模型和他们的问题:不是各位卷死在下,就是在下卷死各位_healthcaremagic-200k
赞
踩
市面上的医学大模型
- CMB - 医学大模型测评榜
- 医学 LLM 汇总 与 概览
- PubMedGPT 2022-12-15
- ChatDoctor 2023-03-24
- DoctorGLM 2023-04-03
- MedicalGPT-zh 2023-04-08
- Chinese-Vicuna-Medical 2023-04-11
- 华佗(HuaTuo)
- OpenBioMed 2023-04-17
- ChatMed 2023-04-19
- 扁鹊(BianQue) 2023-04-22
- PMC-LLaMA 2023-04-27
- NHS-LLM 2023-05-11
- 启真医学大模型 2023-05-23
- MedicalGPT 2023-06-05
- CareGPT (关怀GPT)
- 复旦 DISC - MedLLM
- 商汤 大医
- 医联 MedGPT
- 数坤 ShuKunGPT
- 百川 baichuan
- 这些医学 LLM 都有一个共同问题
- ChatDoctor 详解
CMB - 医学大模型测评榜
CMB 链接:https://cmedbenchmark.llmzoo.com/
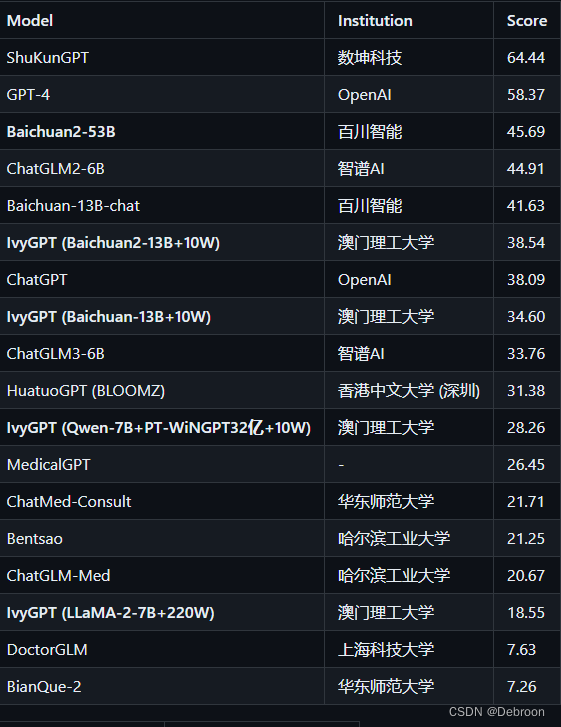
目前第一梯队是:ShuKunGPT、GPT4、Baichuan2-53B、ChatGLM2-6B、Baichuan2-13B
Baichuan2-13B、ChatGLM2-6B 都可以本地部署。
此外,除了 CMB,还有 CBLUE。
医学 LLM 汇总 与 概览
PubMedGPT 2022-12-15
Blog: https://crfm.stanford.edu/2022/12/15/biomedlm.html
Code: https://github.com/stanford-crfm/BioMedLM
基座模型:GPT-2 2.7B
ChatDoctor 2023-03-24
Paper: https://arxiv.org/abs/2303.14070
Code: https://github.com/Kent0n-Li/ChatDoctor
基座模型:LLaMA-7B
数据:
- HealthCareMagic-100k
- icliniq-10k
- GenMedGPT-5k
- disease database
算力:6 x NVIDIA A100 GPUs, 18h, batch size 192, 3 epochs
DoctorGLM 2023-04-03
Paper: https://arxiv.org/abs/2304.01097
Code: https://github.com/xionghonglin/DoctorGLM
基座模型: THUDM/chatglm-6b
数据:
- CMD
- Surgical (116K)
- Obstetrics and Gynecology (229K)
- Pediatrics (117K)
- Internal Medicine (307K)
- Andriatria (113K)
- MedDialog (3.4M)
- ChatDoctor (5.4K)
- HealthCareMagic (200K)
算力:1 x NVIDIA A100 GPU 80GB, 13h
MedicalGPT-zh 2023-04-08
Code: https://github.com/MediaBrain-SJTU/MedicalGPT-zh
基座模型: ChatGLM-6B
数据:
- 28科室的中文医疗共识与临床指南文本
- 情景对话 (52K)
- 知识问答 (130K)
算力:4 x NVIDIA 3090 GPUs
Chinese-Vicuna-Medical 2023-04-11
Code: https://github.com/Facico/Chinese-Vicuna/blob/master/docs/performance-medical.md
基座模型:Chinese-Vicuna-7B
数据:cMedQA2
算力:70w of data, 3 epochs, a 2080Ti about 200h
华佗(HuaTuo)
Paper: https://arxiv.org/abs/2304.06975
Code: https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
基座模型:LLaMA-7B, Chinese-LLaMA-Alpaca, ChatGLM-6B
数据:
- 公开和自建的中文医学知识库,主要参考了cMeKG
- 2023年关于肝癌疾病的中文医学文献,利用GPT3.5接口围绕医学文献多轮问答数据
算力:A100-SXM-80GB,10 epochs, 2h17m, batch_size=128
OpenBioMed 2023-04-17
Paper: https://arxiv.org/abs/2305.01523 (2023-04-17)
Paper: https://arxiv.org/abs/2306.04371 (2023-06-07)
Code: https://github.com/BioFM/OpenBioMed
模型:BioMedGPT-1.6B
数据:DeepDTA
ChatMed 2023-04-19
Code: https://github.com/michael-wzhu/ChatMed
基座模型:LLaMA-7B + Chinese-LLaMA-Alpaca
数据:
- 中文医疗在线问诊数据集ChatMed_Consult_Dataset的50w+在线问诊+ChatGPT回复作为训练集
- 中医药指令数据集ChatMed_TCM_Dataset
- 中医药知识图谱
- ChatGPT得到11w+的围绕中医药的指令数据
算力:4 x NVIDIA 3090 GPUS
扁鹊(BianQue) 2023-04-22
Code: https://github.com/scutcyr/BianQue
基座模型:
- v1: 元语智能
- v2: ChatGLM-6B
数据:
- 中文医疗问答指令与多轮问询对话混合数据集包含了超过900万条样本
- 扁鹊健康大数据BianQueCorpus
- 扩充了药品说明书指令
- 医学百科知识指令
- ChatGPT蒸馏指令等数据
- MedDialog-CN
- IMCS-V2
- CHIP-MDCFNPC
- MedDG
- cMedQA2
- Chinese-medical-dialogue-data
算力:8张 NVIDIA RTX 4090显卡上微调了1个epoch,大约16天
PMC-LLaMA 2023-04-27
Paper: https://arxiv.org/abs/2304.14454
Code: https://github.com/chaoyi-wu/PMC-LLaMA
基座模型: LLaMA-13B
数据:PubmedCentral papers (4.8M)
NHS-LLM 2023-05-11
Blog: https://aiforhealthcare.substack.com/p/a-large-language-model-for-healthcare
Code: https://github.com/CogStack/opengpt
基座模型:LLaMA-13B
数据:
- NHS UK Q/A, 24,665 问答对
- NHS UK Conversations, 2,354 unique conversations
- Medical Task/Solution, 4,688 pairs generated via OpenGPT using GPT-4
启真医学大模型 2023-05-23
Code: https://github.com/CMKRG/QiZhenGPT
License: GPL-3.0
基座模型:ChatGLM-6B, CaMA-13B, Chinese-LLaMA-Plus-7B
数据:
- 启真医学知识库
- 真实医患知识问答数据
- 在启真医学知识库的药品文本知识基础上,通过对半结构化数据设置特定的问题模板构造的指令数据
- 药品适应症评测数据集
算力:7 x NVDIA A800 GPU 80GB
MedicalGPT 2023-06-05
Code: https://github.com/shibing624/MedicalGPT
基座模型:Ziya-LLaMA-13B-v1 等
医疗数据:
- 240万条中文医疗数据集(包括预训练、指令微调和奖励数据集):shibing624/medical
- 22万条中文医疗对话数据集(华佗项目):FreedomIntelligence/HuatuoGPT-sft-data-v1
通用数据:
- 50万条中文ChatGPT指令Belle数据集:BelleGroup/train_0.5M_CN
- 100万条中文ChatGPT指令Belle数据集:BelleGroup/train_1M_CN
- 5万条英文ChatGPT指令Alpaca数据集:50k English Stanford Alpaca dataset
- 2万条中文ChatGPT指令Alpaca数据集:shibing624/alpaca-zh
- 69万条中文指令Guanaco数据集(Belle50万条+Guanaco19万条):Chinese-Vicuna/guanaco_belle_merge_v1.0
- 5万条英文ChatGPT多轮对话数据集:RyokoAI/ShareGPT52K
- 80万条中文ChatGPT多轮对话数据集:BelleGroup/multiturn_chat_0.8M
- 116万条中文ChatGPT多轮对话数据集:fnlp/moss-002-sft-data
奖励数据:
- 原版的oasst1数据集:OpenAssistant/oasst1
- 2万条多语言oasst1的reward数据集:tasksource/oasst1_pairwise_rlhf_reward
- 11万条英文hh-rlhf的reward数据集:Dahoas/full-hh-rlhf
- 9万条英文reward数据集(来自Anthropic’s Helpful Harmless dataset):Dahoas/static-hh
- 7万条英文reward数据集(来源同上):Dahoas/rm-static
- 7万条繁体中文的reward数据集(翻译自rm-static)liswei/rm-static-m2m100-zh
- 7万条英文Reward数据集:yitingxie/rlhf-reward-datasets
- 3千条中文知乎问答偏好数据集:liyucheng/zhihu_rlhf_3k
CareGPT (关怀GPT)
链接:https://github.com/WangRongsheng/CareGPT
复旦 DISC - MedLLM
官网:https://med.fudan-disc.com/
代码:https://github.com/FudanDISC/DISC-MedLLM
商汤 大医
注册链接:https://chat.sensetime.com/wb/login?redirect_uri=https://sensecare-chat.sensetime.com/main
申请一下,大概 3 天过。
医联 MedGPT
使用链接:https://medgpt.co/
注册邮箱即可,这个邮箱是不验的,可以乱填。
数坤 ShuKunGPT
官网:https://www.shukun.net/
百川 baichuan
官网:https://www.baichuan-ai.com/home
通用大模型,但也经过医学微调,Baichuan2 的 CMB测评分数也不错。
Baichuan3 就更强了,医疗数据集Token数超千亿,医疗能力逼近GPT-4。
为了给Baichuan3注入丰富的医疗知识,百川智能在模型预训练阶段构建了超过千亿Token的医疗数据集,包括医学研究文献、真实的电子病历资料、医学领域的专业书籍和知识库资源、针对医疗问题的问答资料等。
数据集涵盖了从理论到实际操作,从基础理论到临床应用等各个方面的医学知识。
这些医学 LLM 都有一个共同问题
ChatDoctor 详解
110K真实医患对话样本+5KChatGPT生成数据进行指令微调,底座使用 llama。
论文:https://arxiv.org/ftp/arxiv/papers/2303/2303.14070.pdf
地址:https://github.com/Kent0n-Li/ChatDoctor
【训练数据】
>通用数据集(掌握对话能力)和医患对话数据集(保障领域质量)组成。
>通用数据集:Stanford Alpaca, 52K instruction-following的数据。
>医患对话数据集:InstructorDoctor-205k数据集,包含5000个生成的医患对话和20万个真实的医患对话
>5000次医患对话,包括700多种疾病及其相应的症状、所需的医学检查和推荐的药物。
>为了提高数据和模型质量,疾病数据库中的元组(疾病的名称、相应的症状等等)将被输入到ChatGPTAPl
中以自动生成指令和对话数据,即生成患者和医生之间的对话。
>20万个真实的医患对话
>从在线医疗问答网站"Health Care Magic."中收集了约20万份真实的医患对话
>会删除医生和患者的名字,并使用语言工具来纠正回答中的语法错误等操作
【训练成本】
>分步骤训练,先基于Stanford Alpaca,后进行nstructorDoctor-205k训练
>使用6个A100训练18小时
>batch size为192, learning rate为2×10-5,训练3个epoch
>最大长度为512个token,warmup为0.03,没有weight decay
为了提高医学领域内大型语言模型(LLMs)的准确性和实用性,ChatDoctor的研究围绕着 — 如何有效地增强这些模型在处理医学咨询方面的能力展开。
-
子问题: 通用的LLMs缺乏针对医学领域的专业知识。
- 子解法1: ChatDoctor通过在真实世界的患者-医生对话数据上进行微调,提高模型对医学领域知识的理解和应用能力。
- 微调后效果更好,真实的医患对话能够提供丰富的医学术语、情景以及专业知识,这有助于模型学习如何在具体医学情景下做出准确回应。
-
子问题: LLMs在回答医学问题时,无法访问最新的在线或离线医学知识,可能导致提供的信息过时或不准确。
- 子解法2: ChatDoctor 整合一个自主信息检索机制,允许模型能够访问和利用来自在线来源(如Wikipedia)和经过策划的离线医学数据库的实时信息。
- 实时获取最新医学知识和研究成果对于提供准确的医学建议至关重要,尤其是对于新出现的疾病和治疗方法。
不使用解法前: 如果LLM被问到关于一个新兴疾病的问题,比如Mpox,它可能会基于在训练数据中的信息(可能已经过时)来生成回答,从而可能提供了不准确或陈旧的治疗建议。
使用解法后: 当ChatDoctor被问及同样的问题时,它会使用其自主信息检索机制来从最新的医学数据库和在线资源中获取关于Mpox的最新治疗信息,从而提供更准确、基于最新医疗研究的建议。
-
子问题: 现有的LLMs在进行医学咨询时容易产生错误和幻觉(不准确的生成内容)。
- 子解法3: ChatDoctor 开发一个能够检索在线和离线医学领域知识的自主ChatDoctor模型,以回答有关最新医学术语和疾病的问题。
- 通过提供对最新医学信息的访问,模型可以减少错误和提高回答的准确性和可靠性。
ChatDoctor使用的离线疾病数据库的样本。
数据库包含了关于各种疾病的详细条目,列出了症状、可能需要进行的额外诊断测试和潜在的治疗选项。
例如,它概述了阑尾炎是什么,它的症状,诊断测试,以及治疗协议。
数据库作为ChatDoctor模型的参考,以确保它提供的医疗建议基于可靠的医学信息。

不使用解法前: 一个患者可能询问关于罕见病症的治疗方法,传统的LLM可能因为缺乏准确的最新医学信息而生成一个错误的或者不完全的回答。
使用解法后: ChatDoctor模型会自动从其知识库中检索与这个罕见病症相关的最新治疗方法,确保提供的回答基于最新的医学研究和实践。
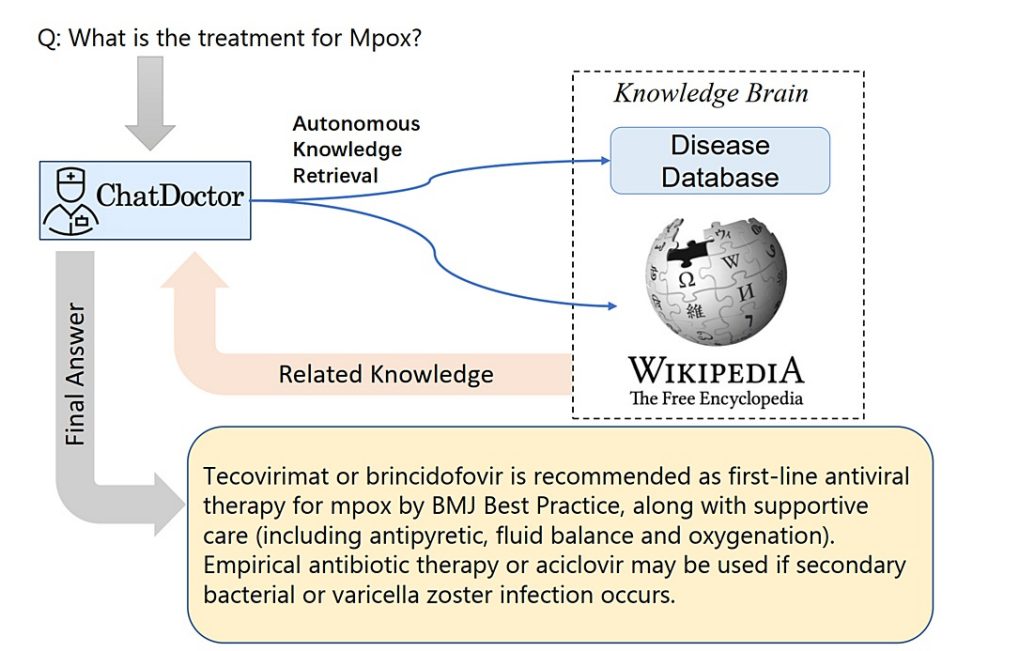
当询问关于医疗状况的问题,例如Mpox时,ChatDoctor使用一个自主知识检索过程来咨询一个外部知识库,该知识库包括一个策划的疾病数据库和Wikipedia。
然后,它整合信息以提供最终答案。,确保ChatDoctor的回应准确无误,并且是基于最新的医学知识。
就是根据用户输入,找到相关信息(Related Knowledge),再给大模型用更专业和精准的词汇表达(专业名词),看起来更加有用;同时判断哪些比较准确和重要。
这是 GPT 做不到的:
GPT说:对这个名词(Mpox)不熟悉,需要更多的背景信息,或者回答也不专业。
ChatDoctor 模型的工作流程:
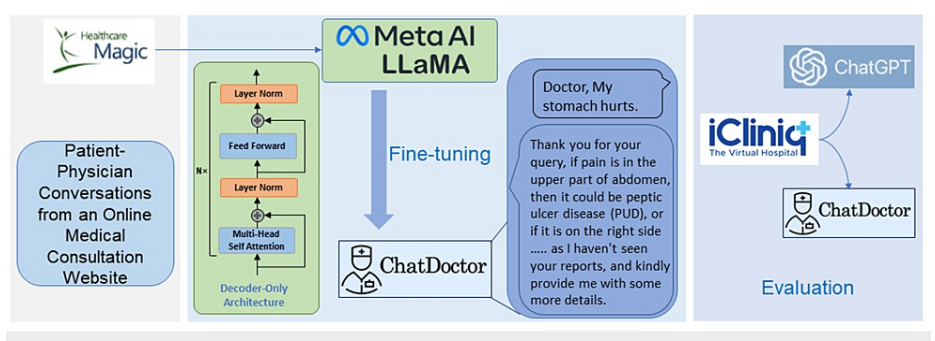
起始于从在线医疗咨询网站HealthcareMagic收集患者-医生对话。
这些对话用于微调 LLaMA 提供的语言模型。
微调后,模型使用来自另一个医疗咨询网站iCliniq的额外对话进行测试,以评估ChatDoctor模型的性能。
它是数据收集、模型训练和评估过程的高层次描述。
华佗详解
论文:https://arxiv.org/abs/2304.06975
代码:https://github.com/PharMolix/OpenBioMed
怎么从医学指南、医学教材中抽取数据,变成大模型训练数据?
华佗为了让回答准确,从中文医学知识图谱 CMeKG:https://github.com/king-yyf/CMeKG_tools 中提取医学知识。
指令:回答下列关于肝炎的问题。
输入:肝炎的常见症状有哪些?
输出:肝炎的常见症状包括黄疸、疲劳、深色尿液、腹痛以及食欲不振等。
- 1
- 2
- 3
但我看了华佗给的数据集,输入都没:
instruction:"肝炎的常见症状有哪些?"
input:""
output:"肝炎的常见症状包括黄疸、疲劳、深色尿液、腹痛以及食欲不振等。"
- 1
- 2
- 3
结构化的医学知识图谱:
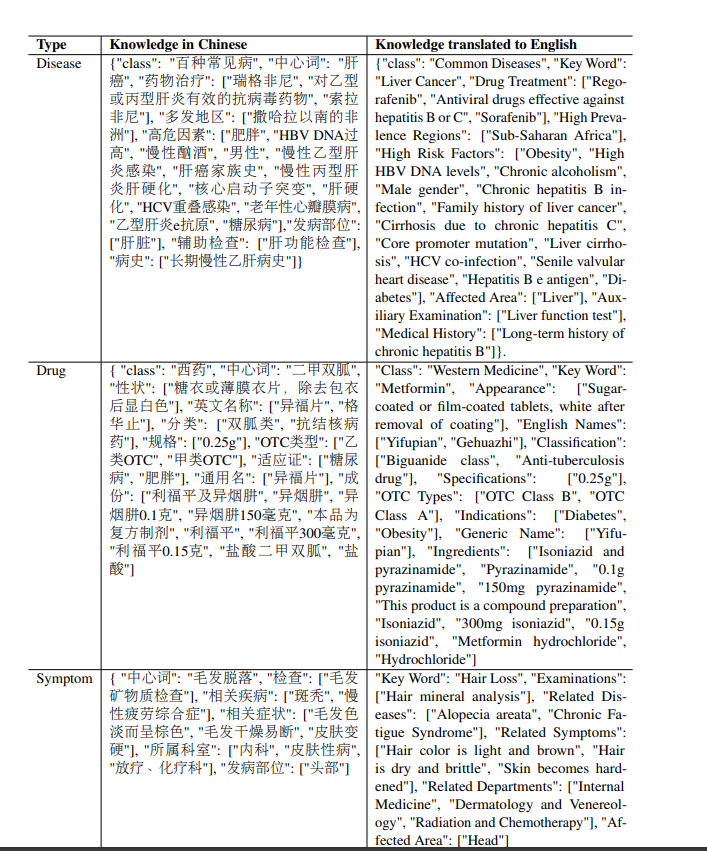
华佗是通过 openai api 把上文的知识图谱,按照特定格式变成数据集的。

