
热门标签
热门文章
- 1【大数据毕设】基于Hadoop的音乐推荐系统的设计和实现(六)_大数据音乐推荐系统教程
- 2凌霄飞控添加灵活格式帧数据传输到上位机_凌霄飞控与openmv通信
- 3python flask 如何读取数据库数据并返回到html_flask查询数据库后返回信息
- 4代码随想录算法训练营day40
- 5Mybatis中实现批量更新的几种姿势,总有一款适合你_mybatis批量更新 sql
- 6Scala学习-函数至简原则_scala定义一个求两个数乘积的函数,并调用函数计算两个数的乘积
- 7Android:ADB各类错误_need apk file on command line
- 8[AIGC] 通过Stable Diffusion生成一致人脸的 5 种方法_dreamshaperxl_turbodpmppsde
- 9Airtable 在线数据库介绍
- 10数据结构——顺序表习题解(I)_求含n(n>1)个元素的顺序表l中的最大元素。要求实现顺序表l=(6,5,7,2,9)的最大
当前位置: article > 正文
spark作业_spark期末作业是什么意思
作者:我家自动化 | 2024-04-10 18:46:09
赞
踩
spark期末作业是什么意思
一、Spark是什么
Spark是一个用来实现快速而通用的集群计算平台。它一个主要特点是能够在内存中进行计算,并且提供了基于Python、Java、Scala和SQL的API,可以和其他大数据工具配合使用。由于Spark的核心引擎有着速度快和通用的特点,因此它还支持各种不同应用场景专门设计的高级组件,比如SQL和机器学习等。组件其实可以理解为Spark针对常见的任务场景而封装好的模块,这些模块提供了各场景的基本功能。组件之间可以相互调用,各组件如图1-1: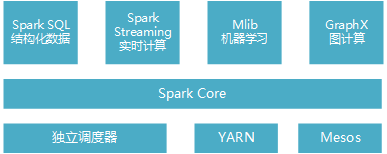
Spark Core实现了任务调度、内存管理、错误恢复、与存储系统交互等模块,并且还包含了对弹性分布式数据集(Resilient Distributed Dataset,简称RDD)的API定义。它主要担任了系统管理员的角色。
Spark SQL 主要用来操作结构化数据的程序包,通过Spark SQL可以使用SQL或者hive版本的HQL来查询数据库。Spark Streaming 主要是对实时数据进行流式计算。MLib提供了很多机器学习算法。GraphX用来操作图,可以并行的进行图计算,支持了图的各种操作。
其中,Spark SQL组件是经常用到的,使用hql语句从hadoop数仓中读取结构化的数据,存为RDD数据集,进行一些操作后分布式存储到hdfs中。
二丶spark的应用
目前大数据处理场景有以下几个类型:
- 复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
-
- 基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
-
- 基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间目前对以上三种场景需求都有比较成熟的处理框架,第一种情况可以用Hadoop的MapReduce来进行批量海量数据处理,第二种情况可以Impala进行交互式查询,对于第三中情况可以用Storm分布式处理框架处理实时流式数据。以上三者都是比较独立,各自一套维护成本比较高,而Spark的出现能够一站式平台满意以上需求。通过以上分析,总结Spark场景有以下几个:lSpark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小l由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合l数据量不是特别大,但是要求实时统计分析需求
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

