
- 1普通二本,去过阿里外包,到现在年薪40W+的高级测试工程师,我的两年转行心酸经历..._二本去阿里巴巴外包项目
- 2sourceTree安装和使用(windows)
- 3Android Studio APK打包(签名),2024最新安卓大厂面试题来袭
- 4YOLOv5训练自己的数据集并测试(以及踩坑记录)_yolo测试集怎么用
- 5动态规划的常用状态转移方程总结_动态规划状态转移方程
- 6R语言 - 逻辑回归_r语言逻辑回归
- 7用指针实现队列_队列指针
- 8sql server 基础
- 9COIN++: Neural Compression Across Modalities 论文阅读笔记
- 10华为安全-防火墙-双向NAT_华为防火墙双向nat配置
Fiddler 微信小程序抓图教程(傻瓜式|汉化版|狗看了都直呼内行)_提取小程序上的图片
赞
踩
前言
本篇文章主要给大家详细讲解如何用Fiddler爬取微信小程序的图片,内容图文并茂,流程非常简单,我们开始吧。
目录
一、获取软件并打开
二、点击工具设置相关代理
三、如何抓图
四、答疑
五、总结
一、获取软件并打开
1、通过百度网盘下载获取安装包(链接是永久的)
链接:https://pan.baidu.com/s/13POnOw6S3YNeUiHB2v4Elg
提取码:4ayw
2、进入fiddlerhhb文件夹,双击启动 Fiddler.exe
二、点击工具设置相关代理(首次使用才需这一步,熟练使用后直接第三步的流程就行)
1、进入选项
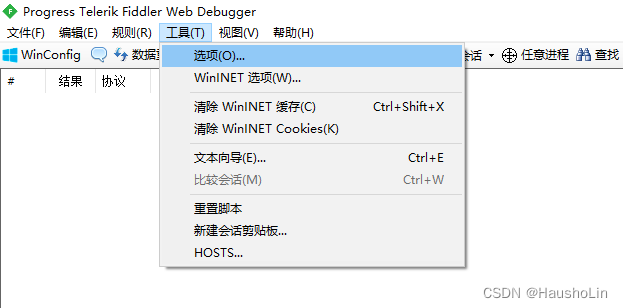
2、勾选完先别关窗口,点击Tab栏的HTTPS
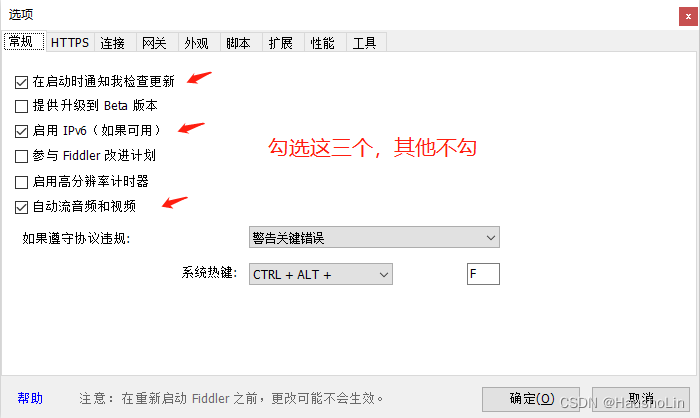
3、进入操作
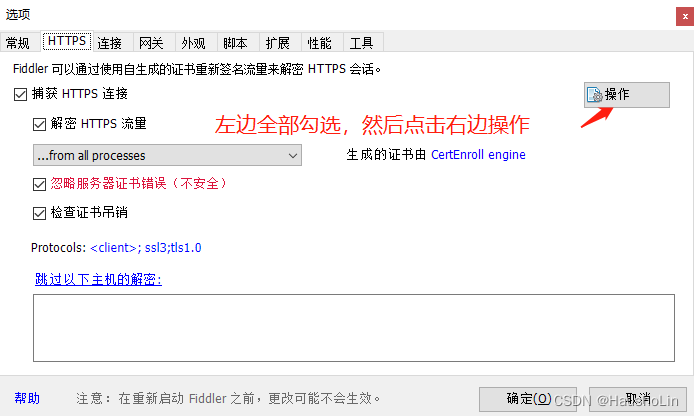
4、信任根证书
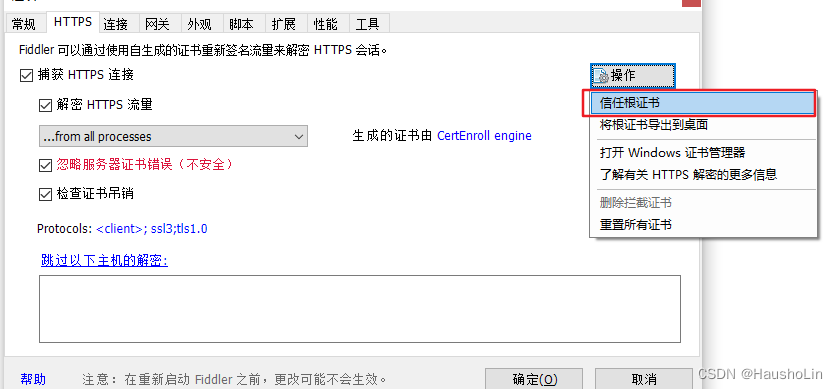
5、确认用新证书

6、添加新签名证书
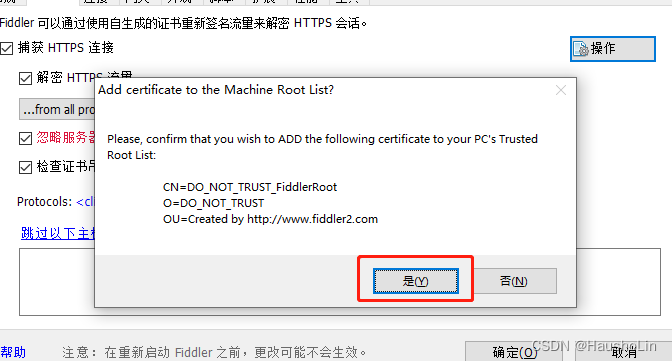
7、出现这个弹框就代表证书配置完毕。(可以正常使用Fiddler工具抓图了)
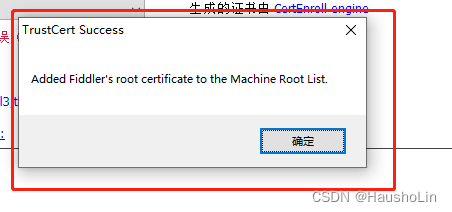
三、如何抓图(准确讲叫抓包,抓对方的数据源)
简略流程:
点击工具栏文件的捕获数据(或者按F12快捷键) -> 小程序在目标商品的上一层点进去 -> 接口数据解码 -> 从字段取图片链接 -> 链接复制到浏览器下载下来 -> 抓图完毕。
原理:
你要获取商品a的信息,就从它的上个页面开启捕获功能,因为进入到详情这个过程中,我们将对方服务器返回给前端的数据进行抓取,从而就可以拿到源数据。
详细流程:
1、清空数据
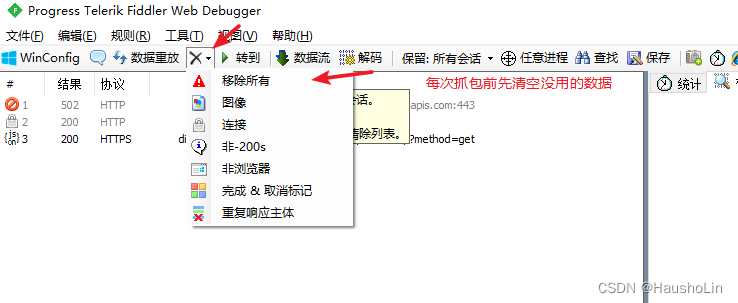
2、点击一下或者按F12
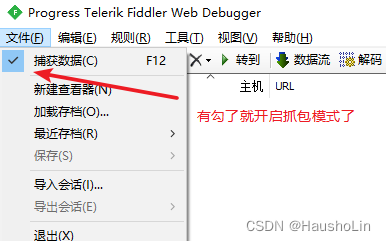
3、假设现在要抓这个商品的详情页所有内容,必须要停留在该商品详情的上个页面,开启捕获数据,然后点进去。
注:此时检查 文件 -> 捕获数据勾选了没有,没勾选给勾选上再点进去。
点击商品进入详情(见下图)

4、捕获数据
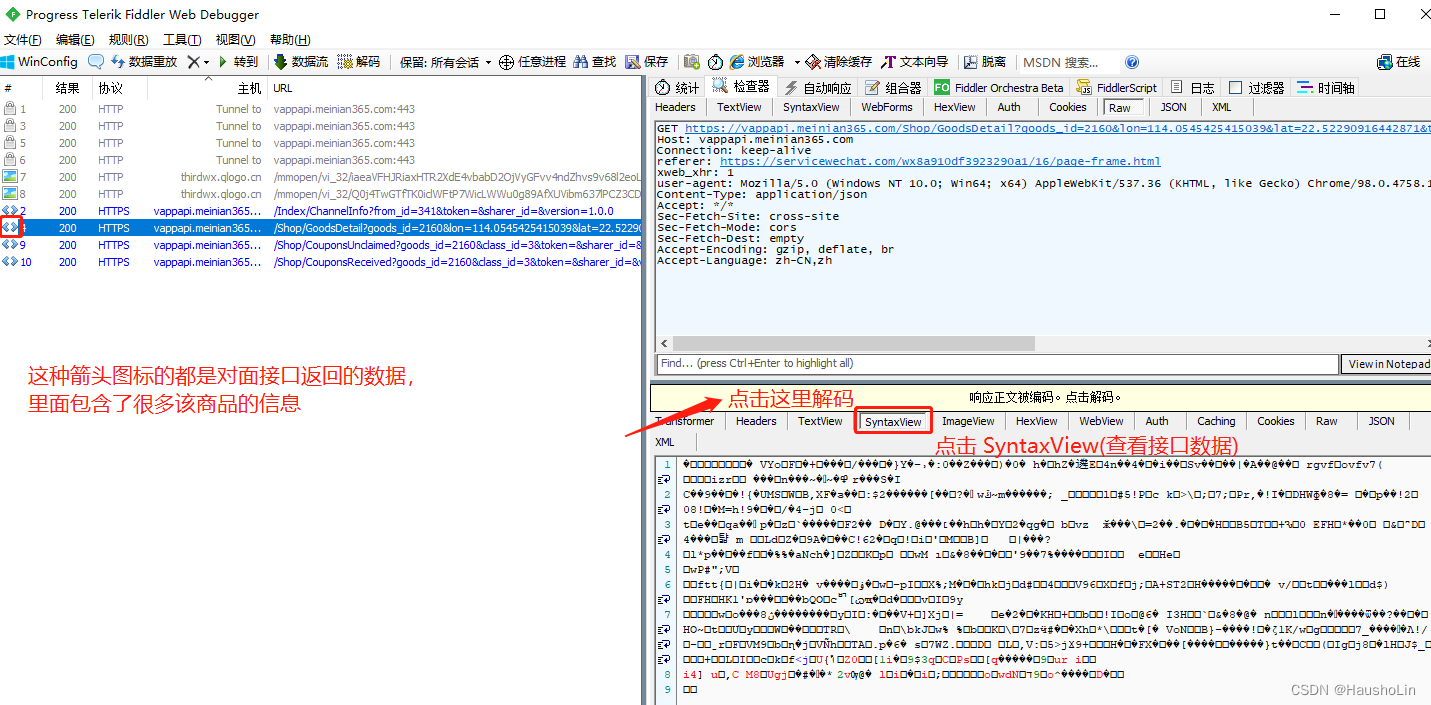
5、数据格式化前
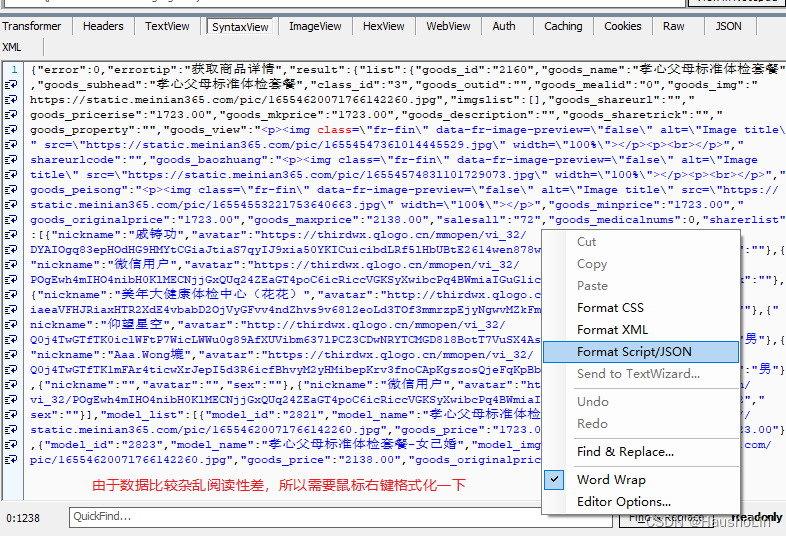
6、数据格式化后
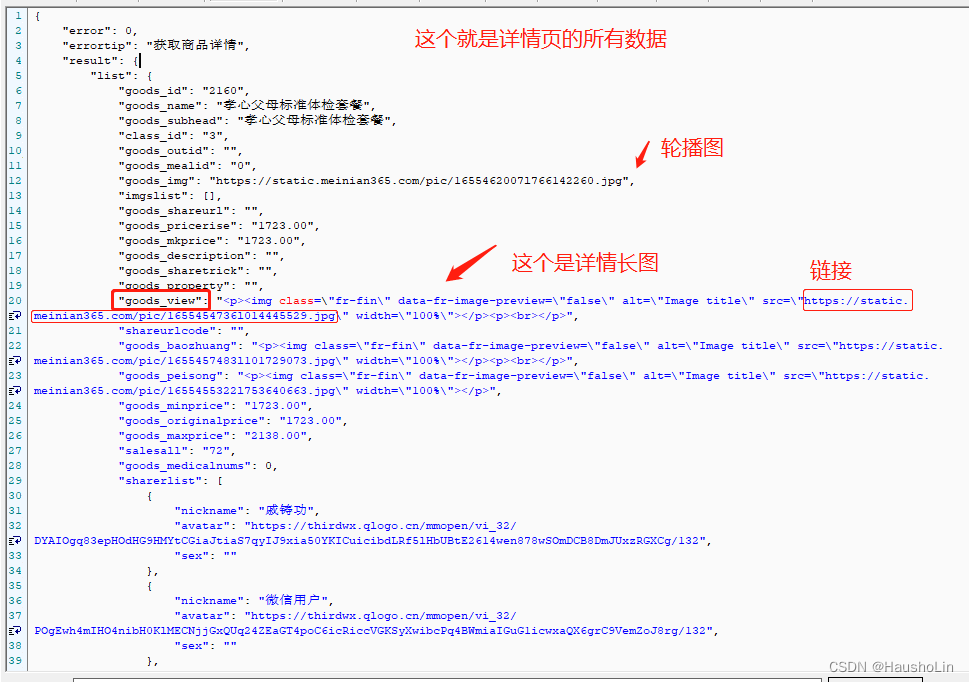
7、将图片链接复制到网页打开,然后把图片下载下来(到这里就能取到图片了)。
8、如果要抓另一个商品,小程序从详情退出来(也就是停留在进详情前的商品列表),重新选择新的产品点进去详情。
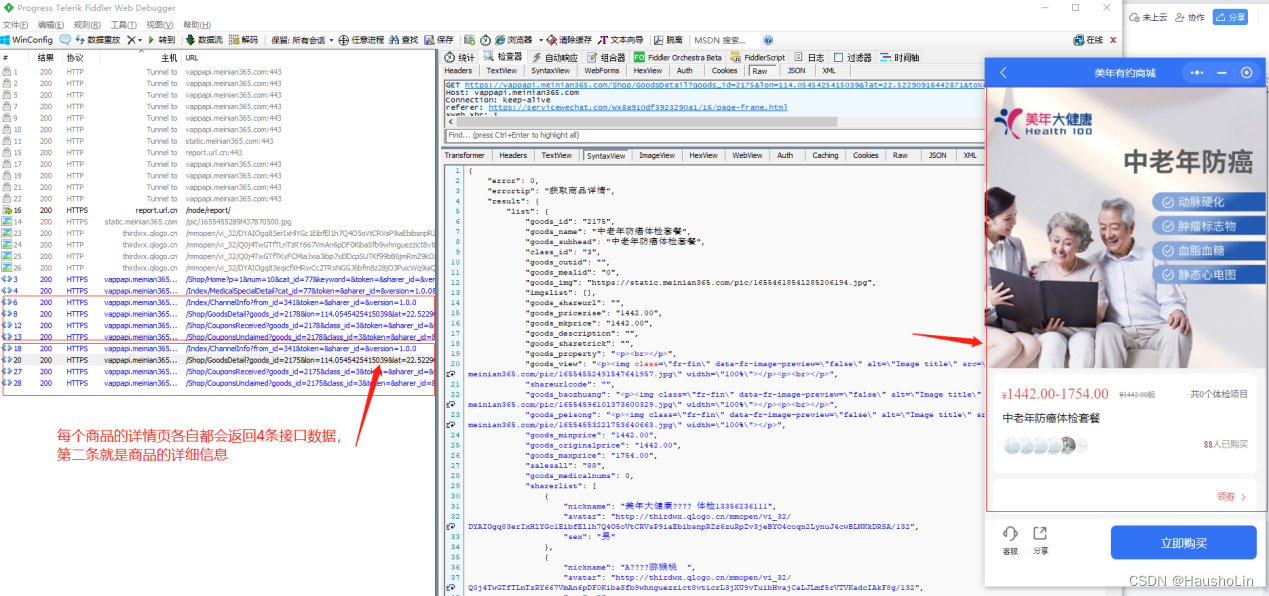
提示:如果左边数据太多,就清空一下数据。
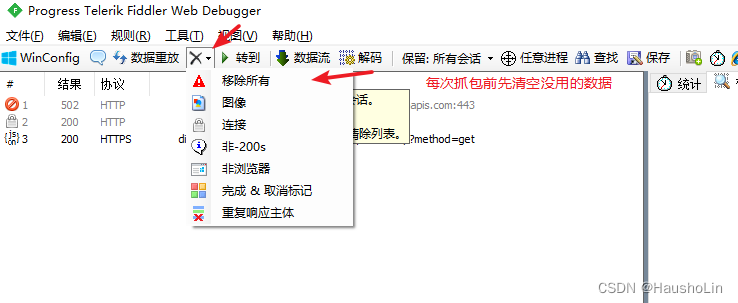
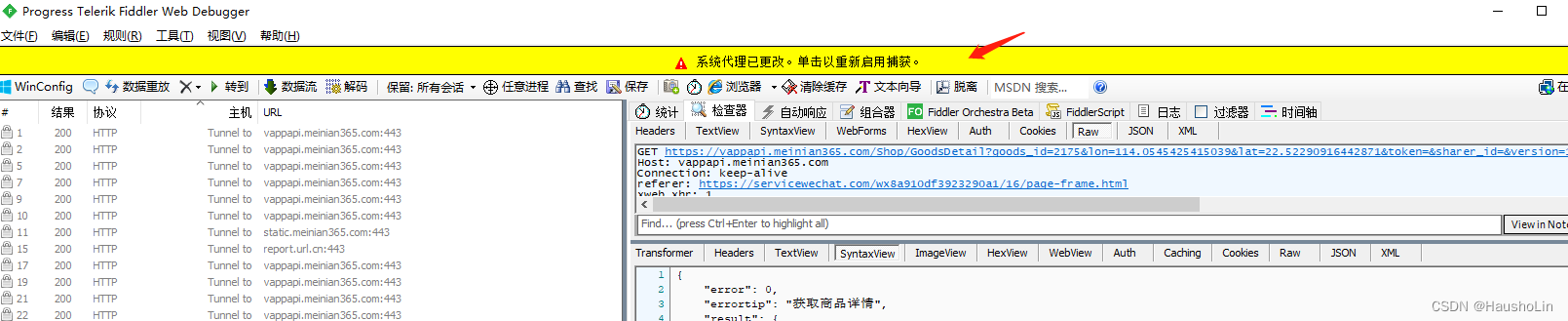
9、如果出现代理已更改,点它一下才可以重新抓包(捕获新的商品数据)
四、答疑
如果工具栏不见怎么恢复?
恢复前:

恢复后:

五、总结
无论抓什么数据,都要从它的上一层页面开启捕获,这样才能拦截到对方的数据。
如果是PC端网页抓取,则只需要F12开启捕获,刷新网页就可以抓了。
提示:该教程只用于正当行为使用,如用于不正当行为被抓与作者无关。

