
- 1IntelliJ IDEA创建一个spark的项目_idea创建javaspark项目
- 2人工智能的落地对行业针对性以及实际运用成本提出更高要求_人工智能成本高
- 3python爬虫去哪儿网上爬取旅游景点14万条,可以做大数据分析的数据基础_去哪儿网景点数据采集
- 4如何选择合适的北斗短报文模块_北斗短报文模组
- 5HarmonyOS Next,你真的足够了解它么?_harmonyos next 开发语言(2)_arkts与仓颉编程语言
- 6kubelet 命令行参数_--enable_load_reader=true
- 7讨论OOV(新词,也叫未登录词,词典之外的词语)问题的解决方案_oov问题
- 8react 低代码图编辑探索
- 9Harmony鸿蒙南向驱动开发-GPIO
- 10【车间调度】基于GA/PSO/SA/ACO/TS优化算法的车间调度比较(Matlab代码实现)_fjsp中 机器只能同时进行一道加工工序吗
【NLP】FastText句子语义深度表示_fasttext 语义相关性
赞
踩
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的
fastText 文本分类(paper:A. Joulin, E. Grave, P. Bojanowski, T. Mikolov,
Bag of Tricks for Efficient Text
Classification(高效文本分类技巧)),
另一部分是词嵌入学习(paper:P.
Bojanowski*, E. Grave*, A. Joulin, T. Mikolov, Enriching Word Vectors
with Subword
Information(使用子字信息丰富词汇向量))。
按论文来说只有文本分类部分才是 fastText,但也有人把这两部分合在一起称为
fastText。笔者,在这即认为词嵌入学习属于FastText项目。
github链接:https://github.com/facebookresearch/fastText
高级词向量三部曲:
1、NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
2、NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
3、NLP︱高级词向量表达(三)——WordRank(简述)
4、其他NLP词表示方法paper:从符号到分布式表示NLP中词各种表示方法综述
一、FastText架构
本节内容参考自:
1、开源中国社区 [http://www.oschina.net] 《Facebook 开源的快速文本分类器 FastTexT》
2、雷锋网文章:《比深度学习快几个数量级,详解Facebook最新开源工具——fastText》
.
1、fastText 架构原理
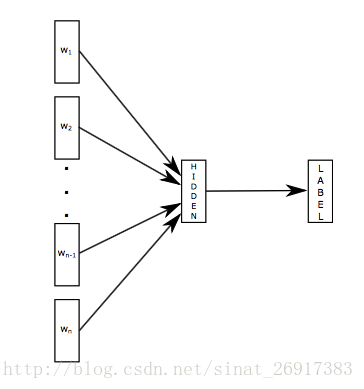
fastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。
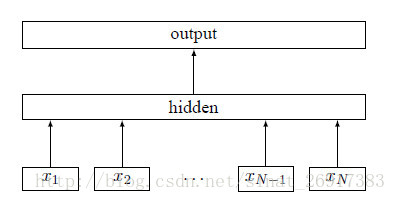
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
.
.
2、改善运算效率——softmax层级
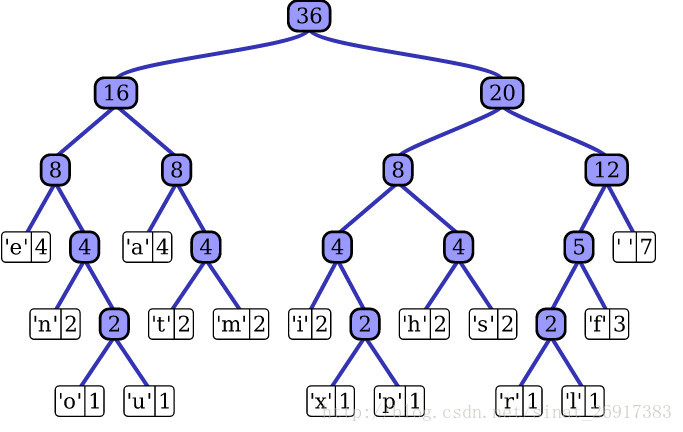
对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。(参考博客)
考虑到线性以及多种类别的对数模型,这大大减少了训练复杂性和测试文本分类器的时间。fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
.
.
.
二、FastText的词向量表征
1、FastText的N-gram特征
常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。
“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。
如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然,为了提高效率,我们需要过滤掉低频的 N-gram。
在 fastText 中一个低维度向量与每个单词都相关。隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。这类表征被称为词袋(bag of words)(此处忽视词序)。在 fastText中也使用向量表征单词 n-gram来将局部词序考虑在内,这对很多文本分类问题来说十分重要。
举例来说:fastText能够学会“男孩”、“女孩”、“男人”、“女人”指代的是特定的性别,并且能够将这些数值存在相关文档中。然后,当某个程序在提出一个用户请求(假设是“我女友现在在儿?”),它能够马上在fastText生成的文档中进行查找并且理解用户想要问的是有关女性的问题。
.
.
2、FastText词向量优势
(1)适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”,特别是与深度模型对比,fastText能将训练时间由数天缩短到几秒钟。使用一个标准多核 CPU,得到了在10分钟内训练完超过10亿词汇量模型的结果。此外, fastText还能在五分钟内将50万个句子分成超过30万个类别。
(2)支持多语言表达:利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。它还使用了一种简单高效的纳入子字信息的方式,在用于像捷克语这样词态丰富的语言时,这种方式表现得非常好,这也证明了精心设计的字符 n-gram 特征是丰富词汇表征的重要来源。FastText的性能要比时下流行的word2vec工具明显好上不少,也比其他目前最先进的词态词汇表征要好。
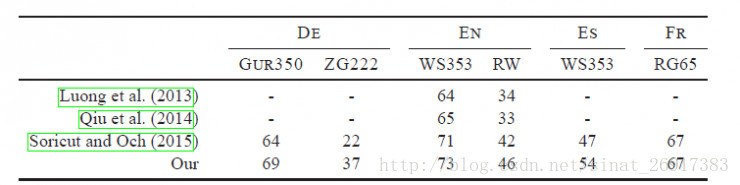
(3)fastText专注于文本分类,在许多标准问题上实现当下最好的表现(例如文本倾向性分析或标签预测)。FastText与基于深度学习方法的Char-CNN以及VDCNN对比:

(4)比word2vec更考虑了相似性,比如 fastText 的词嵌入学习能够考虑 english-born 和 british-born 之间有相同的后缀,但 word2vec 却不能(具体参考paper)。
.
.
3、FastText词向量与word2vec对比
本节来源于博客:fasttext
FastText= word2vec中 cbow + h-softmax的灵活使用
灵活体现在两个方面:
1. 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是 分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用;
2. 模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容;
两者本质的不同,体现在 h-softmax的使用。
Wordvec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax 也会生成一系列的向量,但最终都被抛弃,不会使用。
fasttext则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)
相关文章:Jupyter notebooks:Comparison of FastText and Word2Vec
.
.转载自:http://blog.csdn.net/flyfrommath/article/details/78601619?locationNum=9&fps=1

