
- 1【计算机毕设文章】旅游信息管理系统_旅游管理系统每个模块的流程图
- 2讯飞人脸在线识别_讯飞 人脸比对 ret" : 20001
- 3第十四篇【传奇开心果系列】Python自动化办公库技术点案例示例:深度解读Python自动化处理图像
- 4开源模型应用落地-工具使用篇-Spring AI-高阶用法(九)_spring ai教程
- 5天星金融细说社保 筑牢民生保障防线
- 6我的Git stash不小心清空了怎么办,提了代码能反悔吗_idea git stash后怎么恢复
- 7大话设计模式之享元模式
- 8从零开始学AI(Python基础)_ai python
- 9阿里云centos下载及安装rabbitmq_rabbitmq下载
- 102022年最新版Android安卓面试题+答案精选(每日20题,持续更新中)【三】_安卓数据库交互面试
大模型 Transformer介绍-Part1_transformer模型属于大模型吗
赞
踩
众所周知,transformer 架构是自然语言处理 (NLP) 领域的一项突破。它克服了 seq-to-seq 模型(如 RNN 等)无法捕获文本中的长期依赖性的局限性。事实证明,transformer 架构是 BERT、GPT 和 T5 及其变体等革命性架构的基石。正如许多人所说,NLP 正处于黄金时代,可以说 transformer 模型是一切的起点。
感兴趣可以一起在社区交流:
https://mp.weixin.qq.com/s/UqR51RIXNZmIXZPIqCN1Gg
Transformer架构
如前所述,需要是发明之母。传统的 seq-to-seq 模型在处理长文本时表现不佳。这意味着模型在处理输入序列的后半部分时往往会忘记从输入序列的前半部分学习的知识。这种信息丢失是不可取的。
尽管像 LSTM 和 GRU 这样的门控架构通过丢弃在记住重要信息的过程中无用的信息,在处理长期依赖性方面表现出一些性能改进,但这仍然不够。世界需要更强大的东西,2015 年,Bahdanau 等人 引入了“注意力机制” 。它们与 RNN/LSTM 结合使用来模仿人类行为,以专注于有选择的事物而忽略其余的事物。Bahdanau 建议为句子中的每个词分配相对重要性,以便模型关注重要词而忽略其余词。对于神经机器翻译任务,它是对编码器-解码器模型的巨大改进,很快,注意力机制的应用也被推广到其他任务中。
Transformer时代
Transformer 模型完全基于注意力机制,也称为“自注意力”。这种架构在 2017 年的论文“ Attention is All You Need ”中被介绍给世界。它由一个编码器-解码器架构组成。
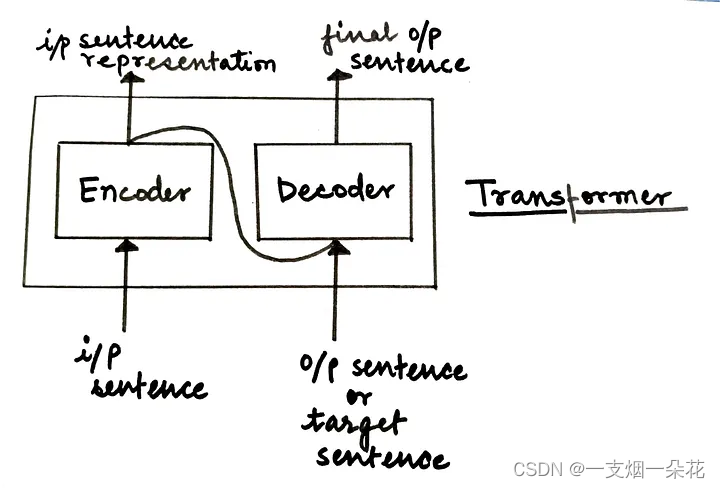
图 Transformer Model Architecture on high-level(来源:作者)
在高层次上,
编码器负责接受输入语句并将其转换为隐藏表示,并丢弃所有无用信息。
解码器接受这个隐藏表示并尝试生成目标句子。
在本文中,我们将深入分析 Transformer 模型的编码器组件。在下一篇文章中,我们将详细介绍解码器组件。开始吧!
Transformer编码器
Transformer 的编码器块由一堆按顺序工作的 N 个编码器组成。一个编码器的输出是下一个编码器的输入,依此类推。最后一个编码器的输出是馈送到解码器块的输入句子的最终表示。
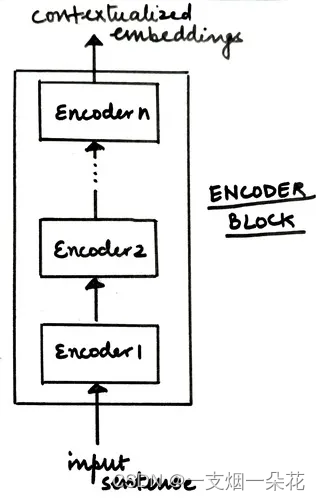
图 带有堆叠编码器的 Enoder 块(来源:作者)
每个编码器块可以进一步拆分为两个组件,如下图所示。
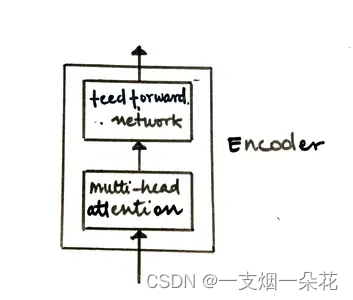
图 Encoder Layer 的组成部分(来源:作者)
让我们一一详细研究这些组件中的每一个,以了解编码器块是如何工作的。编码器块中的第一个组件是多头注意力,但在我们进入细节之前,让我们先了解一个基本概念:自注意力。
Attention机制
大家脑海中可能会冒出第一个问题:attention和self-attention是不同的概念吗?是的,他们是。(呃!)
传统上,如前一节所述,注意力机制是为神经机器翻译任务而存在的。所以本质上是应用注意力机制来映射源句和目标句。由于 seq-to-seq 模型逐个标记地执行翻译任务,注意力机制帮助我们在为目标句子生成标记 x 时识别源句子中的哪些标记需要更多关注。为此,它利用来自编码器和解码器的隐藏状态表示来计算注意力分数,并根据这些分数生成上下文向量作为解码器的输入。如果您想了解有关注意力机制的更多信息,请阅读本文(精彩解释!)。
回到self-attention,主要思想是在将源句子映射到自身的同时计算注意力分数。如果你有这样的句子,
“男孩没有过马路,因为马路太宽了。”
我们人类很容易理解上面句子中“它”这个词指的是“路”,但是我们如何让我们的语言模型也理解这种关系呢?这就是self-attention发挥作用的地方!
在高层次上,将句子中的每个单词与句子中的每个其他单词进行比较,以量化关系并理解上下文。出于代表性的目的,您可以参考下图。
让我们详细看看这种自注意力是如何计算的(实际)。
为输入句子生成嵌入
找到所有单词的嵌入并将它们转换为输入矩阵。这些嵌入可以通过简单的标记化和单热编码生成,也可以通过 BERT 等嵌入算法生成。输入矩阵的维度将等于句子长度 x 嵌入维度。让我们将此输入矩阵称为 X以供将来参考。
将输入矩阵转换为 Q、K 和 V
为了计算自注意力,我们需要将 X(输入矩阵)转换为三个新矩阵:
- Query (Q)
- Key (K)
- Value (V)
为了计算这三个矩阵,我们将随机初始化三个权重矩阵,即Wq、Wk 和 Wv。输入矩阵 X 将与这些权重矩阵 Wq、Wk 和 Wv 相乘,分别获得 Q、K 和 V 的值。在此过程中将学习权重矩阵的最佳值,以获得更准确的 Q、K 和 V 值。
计算Q和K转置的点积
从上图可以看出,qi、ki、vi 代表了句子中第 i 个词的 Q、K、V 的值。
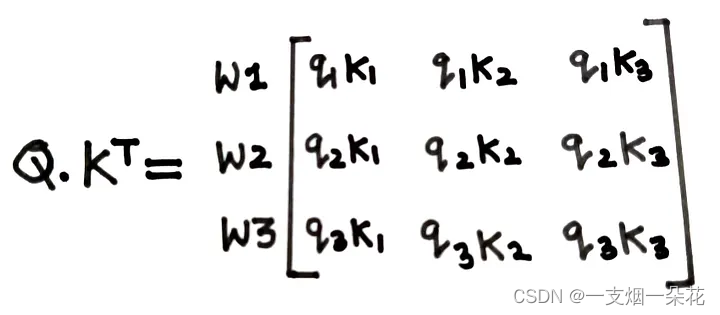
图 Q 和 K 转置的点积示例(来源:作者)
输出矩阵的第一行将使用点积告诉您 q1 表示的 word1 与句子中其余单词的关系。点积的值越高,单词越相关。直觉上为什么要计算这个点积,可以从信息检索的角度理解Q(query)和K(key)矩阵。所以在这里,
- Q 或 Query = 您正在搜索的术语
- K 或 Key = 您搜索引擎中的一组关键字,Q 将与之进行比较和匹配。
缩放点积
与上一步一样,我们正在计算两个矩阵的点积,即执行乘法运算,该值可能会爆炸。为了确保不会发生这种情况并稳定梯度,我们将 Q 和 K-转置的点积除以嵌入维度 (dk) 的平方根。
使用 softmax 规范化值
使用 softmax 函数的归一化将导致值介于 0 和 1 之间。具有高尺度点积的单元格将进一步提高,而低值将减少,从而使匹配的词对之间的区别更加清晰。得到的输出矩阵可以被视为得分矩阵 S。
计算注意力矩阵Z
将值矩阵或V乘以从上一步获得的分数矩阵S来计算注意力矩阵Z。
但是等等,为什么要乘法?
假设,Si = [0.9, 0.07, 0.03] 是句子中第 i 个词的得分矩阵值。该向量与 V 矩阵相乘以计算 Zi(第 i 个词的注意力矩阵)。
子 = [0.9 * V1 + 0.07 * V2 + 0.03 * V3]
我们是否可以说为了理解第 i 个词的上下文,我们应该只关注词 1(即 V1),因为 90% 的注意力分数值来自 V1?我们可以清楚地定义重要的词,应该更加注意理解第 i 个词的上下文。
因此,我们可以得出结论,一个词在 Zi 表示中的贡献越高,这些词之间的关键性和相关性就越高。
现在我们知道如何计算自注意力矩阵,让我们了解多头注意力机制的概念。
多头Attention机制
如果你的分数矩阵偏向于特定的词表示会发生什么?它会误导你的模型,结果不会像我们预期的那样准确。让我们看一个例子来更好地理解这一点。
S1:“一切都很好”
Z(孔)= 0.6 * V(全部)+ 0.0 * v(是)+ 0.4 * V(孔)
S2:“狗吃了食物因为它饿了”
Z(it) = 0.0 * V(the) + 1.0 * V(dog) + 0.0 * V(ate) + …… + 0.0 * V(hungry)
在 S1 情况下,在计算 Z(well) 时,更重视 V(all)。它甚至超过了 V(well) 本身。无法保证这将有多准确。
在 S2 的情况下,在计算 Z(it) 时,所有重要性都赋予 V(dog),而其余单词的分数为 0.0,包括 V(it)。这看起来可以接受,因为“它”这个词是模棱两可的。将它更多地与另一个词相关联而不是与该词本身相关联是有意义的。这就是计算自我注意力的练习的全部目的。处理输入句子中歧义词的上下文。
换句话说,我们可以说,如果当前词是有歧义的,那么在计算自注意力时给予其他词更多的重要性是可以的,但在其他情况下,它可能会对模型产生误导。所以我们现在怎么办?
如果我们计算多个注意力矩阵而不是计算一个注意力矩阵并从中推导出最终的注意力矩阵会怎么样?
这正是多头注意力的全部意义所在!我们计算注意力矩阵 z1、z2、z3、……、zm 的多个版本并将它们连接起来以得出最终的注意力矩阵。这样我们就可以对我们的注意力矩阵更有信心。
继续下一个重要概念,
位置编码
在 seq-to-seq 模型中,输入句子被逐字输入网络,这使得模型能够跟踪单词相对于其他单词的位置。
但在变压器模型中,我们采用不同的方法。它们不是逐字输入,而是并行输入,这有助于减少训练时间和学习长期依赖性。但是用这种方法,词序就丢失了。然而,要正确理解句子的意思,词序是极其重要的。为了克服这个问题,引入了一种称为“位置编码”(P)的新矩阵。
该矩阵 P 与输入矩阵 X 一起发送,以包含与词序相关的信息。由于显而易见的原因,X 和 P 矩阵的维数相同。
为了计算位置编码,使用下面给出的公式。
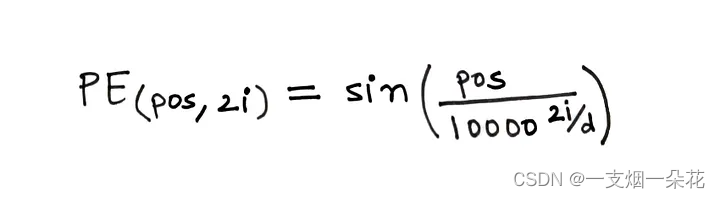
图.计算位置编码的公式(来源:作者)
在上面的公式中,
pos = 单词在句子中的位置
d = 单词/标记嵌入的维度
i = 表示嵌入中的每个维度
在计算中,d 是固定的,但 pos 和 i 是变化的。如果 d=512,则 i ∈ [0, 255],因为我们取 2i。
如果您想了解更多信息,该视频将深入介绍位置编码。
Transformer 神经网络视觉指南——(第 1 部分)位置嵌入
我正在使用上面视频中的一些视觉效果用我的话来解释这个概念。
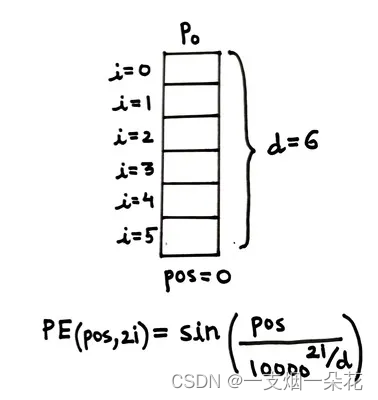
Fig. Positional Encoding Vector Representation(来源:作者)
上图显示了一个位置编码向量的示例以及不同的变量值。
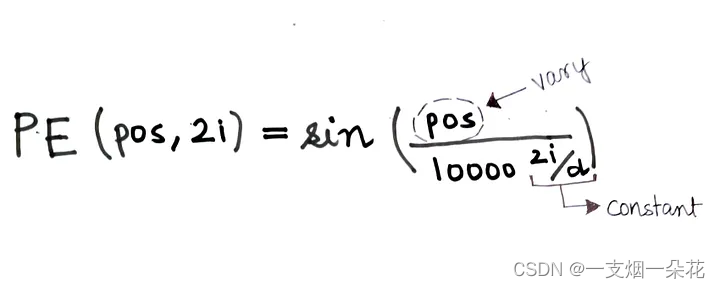
图. 具有常量 i 和 d 的位置编码向量(来源:作者)
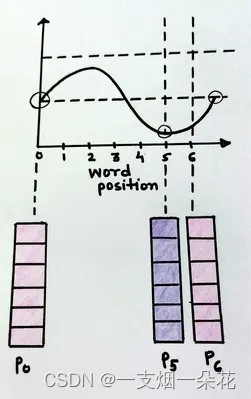
图. 具有常量 i 和 d 的位置编码向量(来源:作者)
上图显示了如果 i 不变且只有 pos 变化,PE(pos, 2i)的值将如何变化。正如我们所知,正弦波是一种周期性函数,往往会在固定间隔后自行重复。我们可以看到 pos = 0 和 pos = 6 的编码向量是相同的。这是不可取的,因为我们希望对不同的 pos 值使用不同的位置编码向量。
这可以通过改变正弦波的频率来实现。
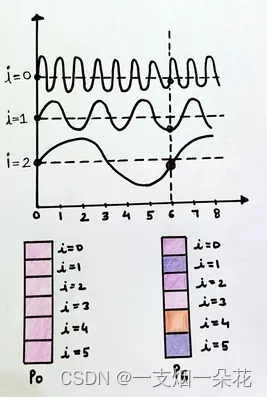
图 pos 和 i 不同的位置编码向量(来源:作者)
随着 i 值的变化,正弦波的频率也会发生变化,从而导致不同的波,从而导致每个位置编码向量的值不同。这正是我们想要实现的。
位置编码矩阵 § 添加到输入矩阵 (X) 并馈送到编码器。
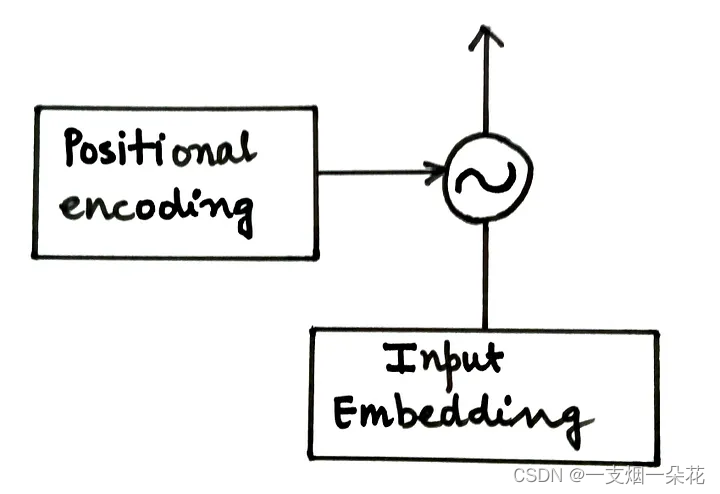
图. 将位置编码添加到输入嵌入中(来源:作者)
编码器的下一个组件是前馈网络。
前馈网络
编码器块中的这个子层是具有两个密集层和 ReLU 激活的经典神经网络。它接受来自多头注意力层的输入,对其执行一些非线性变换,最后生成上下文向量。全连接层负责考虑每个注意力头并从中学习相关信息。由于注意力向量彼此独立,因此可以以并行方式将它们传递给变换器网络。
Encoder 块的最后一个组件是Add & Norm 组件。
添加&规范组件
这是一个残差层,然后是层归一化。残差层确保在处理过程中不会丢失与子层输入相关的重要信息。而规范化层促进更快的模型训练并防止值发生重大变化。
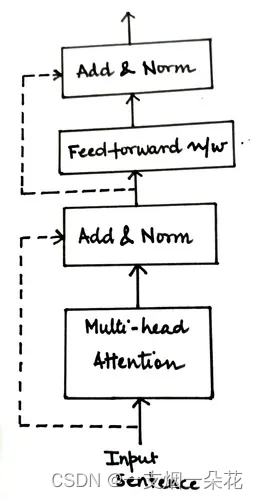
图。包含添加和规范层的编码器组件(来源:作者)
在编码器中,有两个添加和规范层:
将多头Attention子层的输入连接到它的输出
将前馈网络子层的输入连接到它的输出
至此,我们总结了编码器的内部工作。为了总结这篇文章,让我们快速回顾一下编码器使用的步骤:
生成输入句子的嵌入或标记化表示。这将是我们的输入矩阵 X。
生成位置嵌入以保留与输入句子的词序相关的信息,并将其添加到输入矩阵 X。
随机初始化三个矩阵:Wq、Wk 和 Wv, 即查询、键和值的权重。这些权重将在 transformer 模型的训练过程中更新。
将输入矩阵 X 与 Wq、Wk 和 Wv 中的每一个相乘以生成 Q(查询)、K(键)和 V(值)矩阵。
计算 Q 和 K-transpose 的点积,通过将乘积除以 dk 的平方根或嵌入维度来缩放乘积,最后使用 softmax 函数对其进行归一化。
通过将 V 或值矩阵与 softmax 函数的输出相乘来计算注意力矩阵 Z。
将此注意力矩阵传递给前馈网络以执行非线性转换并生成上下文嵌入。
在下一篇文章中,我们将了解 Transformer 模型的 Decoder 组件是如何工作的。

