
- 1前端通过导入editor.md库实现markdown功能
- 2ECharts 点击非图表区域的点击事件不触发问题_chart.getzr()不起作用
- 3保洁行业上门预约小程序源码系统 轻松预约 避免排队 源码开源可二开 带完整部署教程_预约服务平台源码
- 4python编写小游戏详细教程,用python制作一个小游戏_python制作移动图片小游戏
- 5influxdb使用tz报错ERR: error parsing query: unable to find time zone Asia/Shanghai_org.influxdb.influxdbexception: error parsing quer
- 6ubuntu20.04 安装TeamViewer_nx ubuntu20.04安装teamviewer host
- 7Jenkins详细安装配置部署_jenkins安装
- 8ICLR 2024 | 图领域首个通用框架!任意数据集、分类问题都可搞定!华盛顿大学&北大&京东出品...
- 9探索Kimi模型AI:革新人工智能的未来
- 10pytorch技术栈
ElasticSearch篇——初始、认识、拿下ElasticSearch,一篇文章带你入门ES,涵盖ES概念,对比Solr,ES核心概念以及常见工具head、kibana安装和使用,保姆级教程!!!_es入门
赞
踩
为什么要学习ElasticSearch
一、学习背景
曾经,如果我们在网页上查询某些数据,在输入框中输入部分内容,后台默认可能是通过SQL的模糊查询进行操作的。
但是在现今的大数据时代,有几百万条数据,那么常规的模糊查询就非常的缓慢了,慢慢的演进出来了索引,但是还是达不到大数据的要求。
那么,就有必要学习一款分布式全文搜索引擎。那么ElasticSearch主要功能就是搜索,如果在某个网站上需要用到搜索功能基本上都是用的ElasticSearch
二、ES的起源
首先需要了解Lucene,是一套信息检索工具包,就是一个jar包,但是不包含搜索引擎。她里面有一些索引结构(相当于数据库中的表)、读写索引的工具、排序、搜索规则等等工具类
那么我们的ES就是基于Lucene工具包做了一些增强和封装,上手十分简单!
三、ES概述
ES是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RestFul API来隐藏Lucene的复杂性,从而让全文检索变得简单。
现今,ES已经是全世界排名第一的搜索引擎类应用!
ES和Solr对比
一、相同点
1、两者都是基于Lucene,做了一些封装
二、不同点
1、ES提供的是RestFul的API;solr提供的是Web-Service的API,两者的风格不同,而在如今的时代,RestFul会更加推荐
2、Solr用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr根据XML文档添加、删除、更新索引,Solr搜索只需要发送HTTP GET请求,然后对Solr返回XML、Json等格式的查询结果进行解析,组织页面布局,Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
三、二者对比
1、
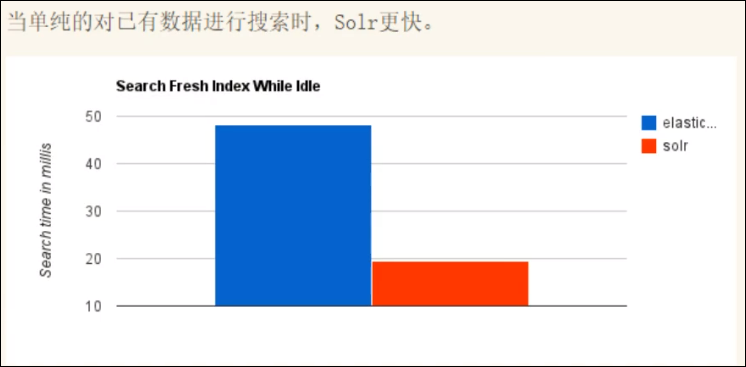
2、
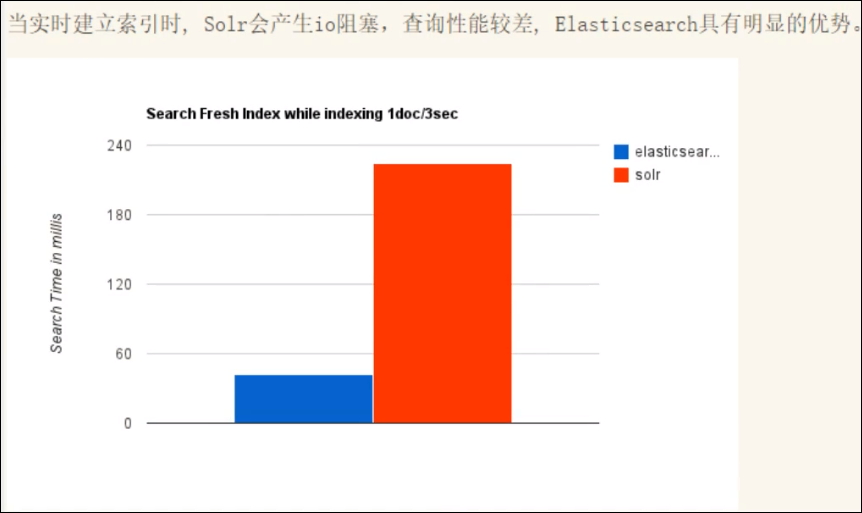
3、
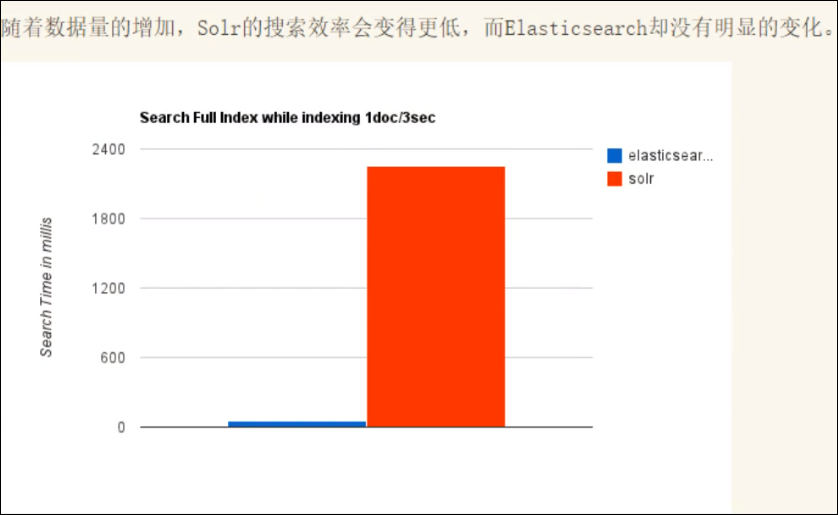
四、ES VS Solr总结
1、ES基本是开箱即用(解压下来就能用),非常简单,Solr安装稍微上复杂一些
2、Solr利用Zookeeper进行分布式管理,而ES自身带有分布式协调管理功能
3、Solr支持更多格式的数据,比如Json、XML、CSV,而ES仅支持json文件格式
4、Solr官方提供的功能更多,而ES本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、Solr查询快,但更新索引时慢(即插入慢删除慢),常用于电商等查询较多的应用
(1)ES建立索引快,即实时查询快,用于FaceBook、新浪等搜索
(2)Solr时传统搜索应用的有利解决方案,但ES更适用于新型的实时搜索应用
6、Solr比较成熟,有一个更大、更成熟的用户、开发和贡献者社区,而ES相对开发维护较少,更新太快,学习使用成本较高!
Elasticsearch核心概念
一、ES和关系型数据库的对比
ES是面向文档的!一切都是Json,ES(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表)(表再慢慢被弃用),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列) 
二、物理设计
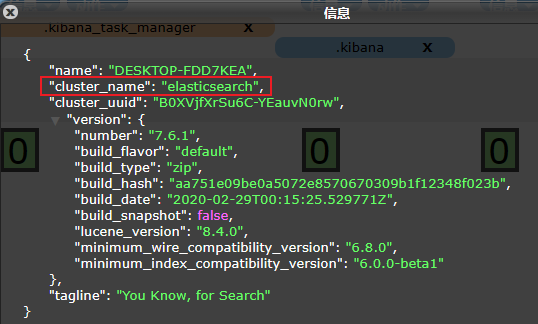
ES在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移,一个人就是一个集群,默认的集群名称就是elasticsearch
三、逻辑设计
1、文档
就是表中的一条条数据

2、类型
类似于数据库表中字段的类型
3、索引
就是数据库。索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后他们被存储到了各个分片上
四、节点和分片是怎么工作的
一个集群中至少有一个节点,而一个节点就是一个elasticsearch进程,节点可以有多个默认的索引,如果创建索引,那么索引将会有5个分片(primary shard,又称主分片)构成的,每一个主分片都会有一个副本(replica shard,又称复制分片)
(1)创建索引(数据库),索引将会有默认的5个分片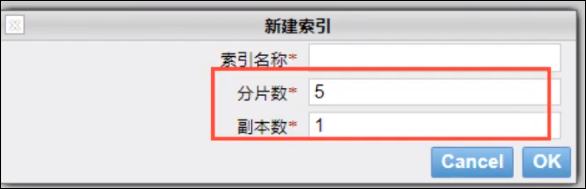

此图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内(P0和P1、P2不在一个节点中!),这样有利于某个节点挂了,数据也不至于丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你那些文档包含特定的关键字。接下来还需要学习什么是倒排索引!
五 、倒排索引
通俗的讲,创建一个索引数据库,就相当于创建了5个lucene倒排索引,这样搜索的效率会向当高效!
elasticsearch使用的是倒排索引的结构,采用了Lucene倒排索引为底层,这种结构适用于快速的全文搜索,一个索引由全文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
实例一:
例如现在有两个文档,每个文档不包含如下的内容:

为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档中:
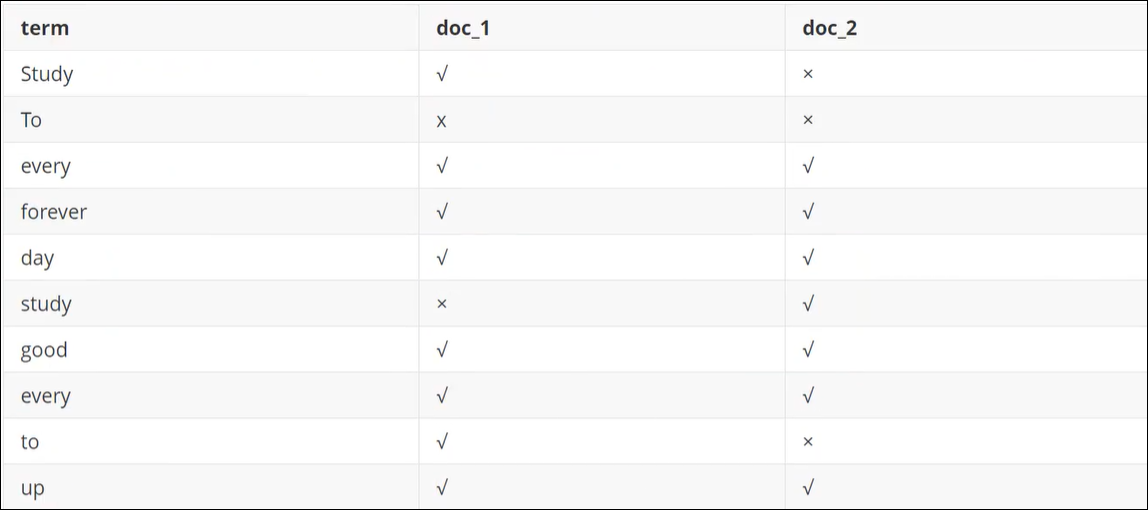
现在,我想搜索一下 to forever,只需要查看包含每个词条的文档即可,后面的total就是权重

两个文档都匹配,但是第一个文档比第二个文档的匹配程度会更高。如果没有别的条件,现在这两个包含关键字的文档都将被返回
实例二:
通过博客来搜索博客文章,那么倒排索引就是这样的一个结构
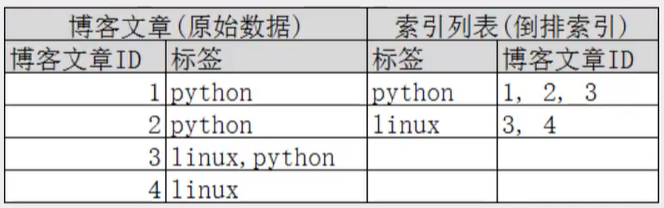
如果要搜索包含python标签的文章,那相对于查找所有原始的数据而言,查找倒排索引后的数据会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可
了解ELK
ELK是Elasticsearch、Logstash、kibana三大开源框架首字母大写简称。市面上也并被称为Elastic Stack。
其中Elasticsearch是一个基于Lucene、分布式、通过RestFul方式进行交互的近实时搜索平台框架。
Logstash是ELK中的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。
kibana可以将Elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
市面上很多 开发只要提到ELK能够一致的说出他是一个日志分析架构技术总栈,但实际上ELK不仅仅适用于日志分析,它还支持其他任何数据分析和收集的场景,日志分析和收集只是更具有代表性而已。
ELK基本上都是拆箱即用,直接解压就可使用!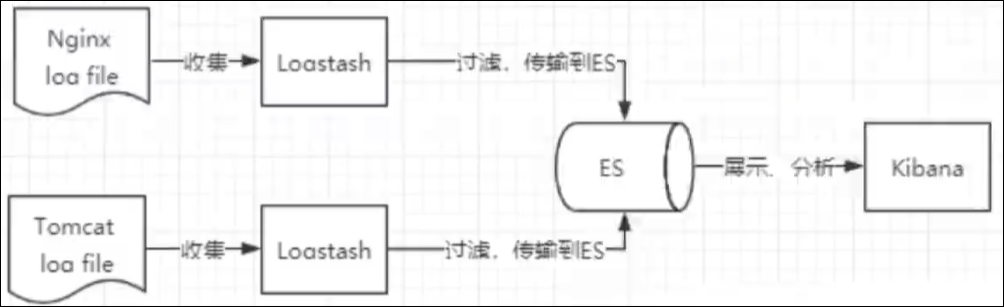
ES安装及head插件安装
首先安装ES,JDK版本至少版本是1.8,后期集成到SpringBoot中,Maven中的ES的版本要和对应的Java核心Jar包版本一致!
一、下载
1、下载地址:Elasticsearch 平台 — 大规模查找实时答案 | Elastic
2、点击立即体验,点击下载
3、windows和Linux选择各自的版本即可
4、将下载好的压缩包解压到本地的环境中,熟悉目录

二、启动
1、打开bin,双击elasticsearch.bat

2、访问9200
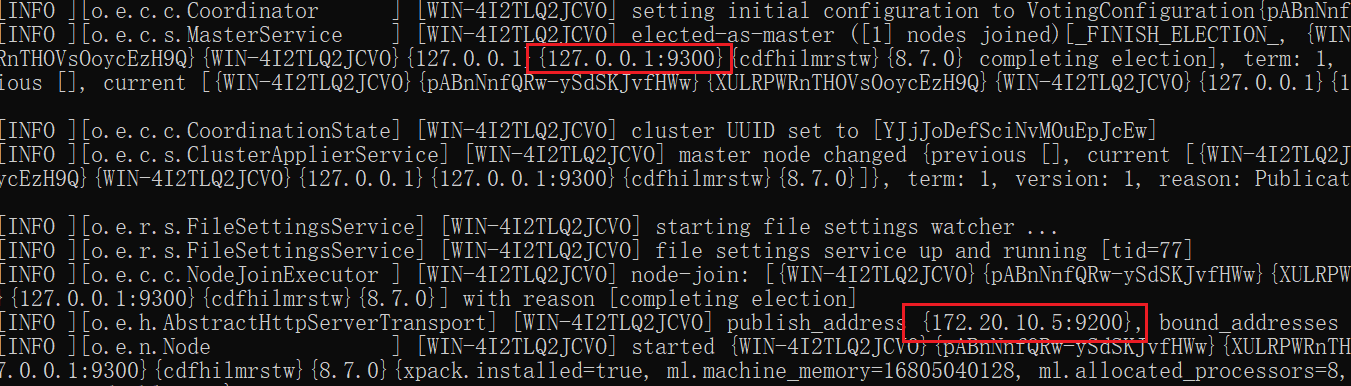
3、启动界面如下
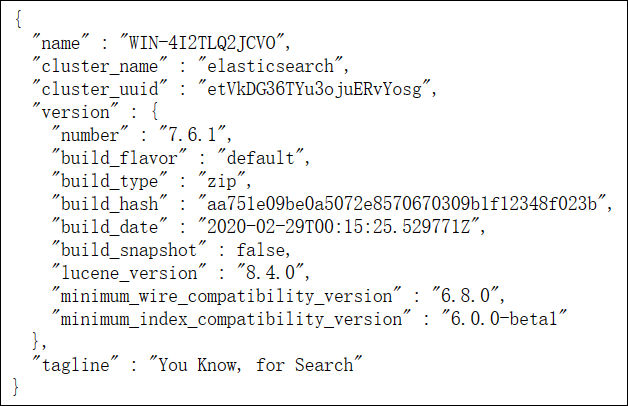
三、安装elasticsearch head可视化界面(数据展示工具)
1、下载地址:GitHub - mobz/elasticsearch-head: A web front end for an elastic search cluster
2、解压到环境中
、在解压目录上打开cmd,执行命令
首先需要安装node.js
cnpm install4、启动可视化界面
npm run start
访问9100可以得到这个界面,但是目前还是需要先解决跨域问题,就是如何从9100跨到ES的9200
5、关掉head和ES的服务,打开ES的config下的elasticsearch.yml配置文件
开启跨域支持,注意不要把单词拼写错误,如果出现错误,ES启动直接闪退!!!
- http.cors.enabled: true
- http.cors.allow-origin: "*"
6、重启ES和head,访问9100,这时候就可以解决跨域问题了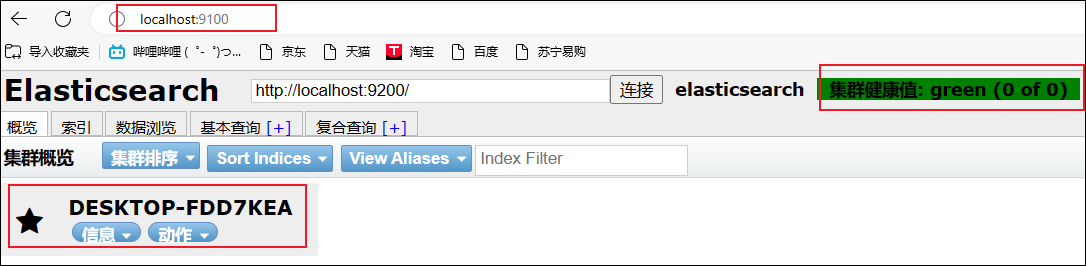
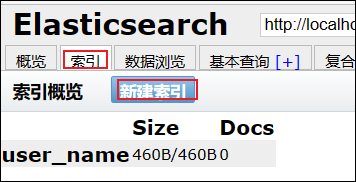
7、尝试新建索引(索引就相当于一个数据库)
kibana安装
安装之前先了解什么是kibana
是一个针对Elasticsearch的开源分析以及可视化平台,用来搜索、查看交互存储在ES索引中的数据。使用kibana,可以通过各种图标进行高级数据分析及展示。kibana让海量的数据更容易理解。它的操作十分简单,基于浏览器的用户界面可以快速的创建仪表板(dashborad)实时显示ES查询动态。设置kibana非常简单,无需编码或者额外的基础架构,几分钟内就可以完成安装并启动ES索引监测
一、官网下载
下载地址:Download Kibana Free | Get Started Now | Elastic
注意kibana的版本要和ES版本一致!
1、下载后解压到ES的环境目录下,解压也是需要一些时间,因为他是一个标准的工程!
二、启动
打开该文件,启动bin下的bat文件
kibbana的默认端口是5601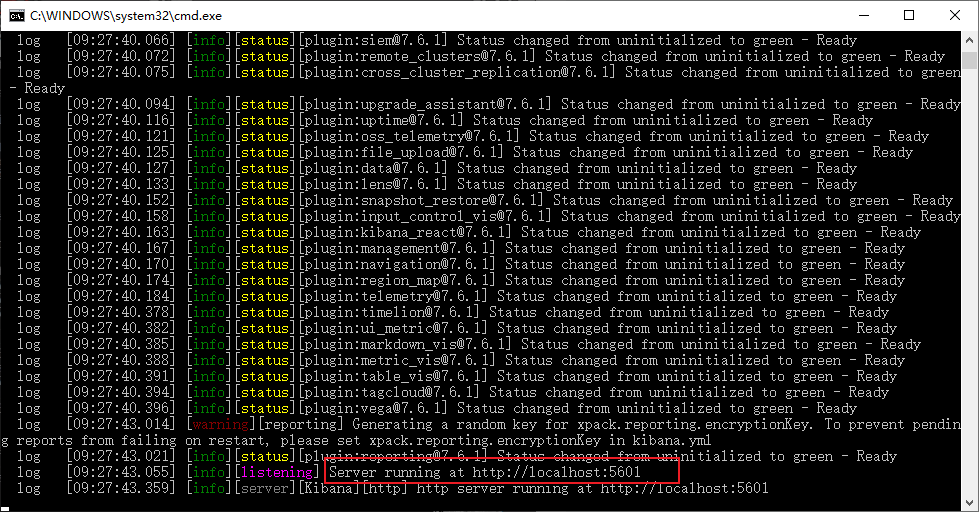
三、浏览器访问localhost:5601
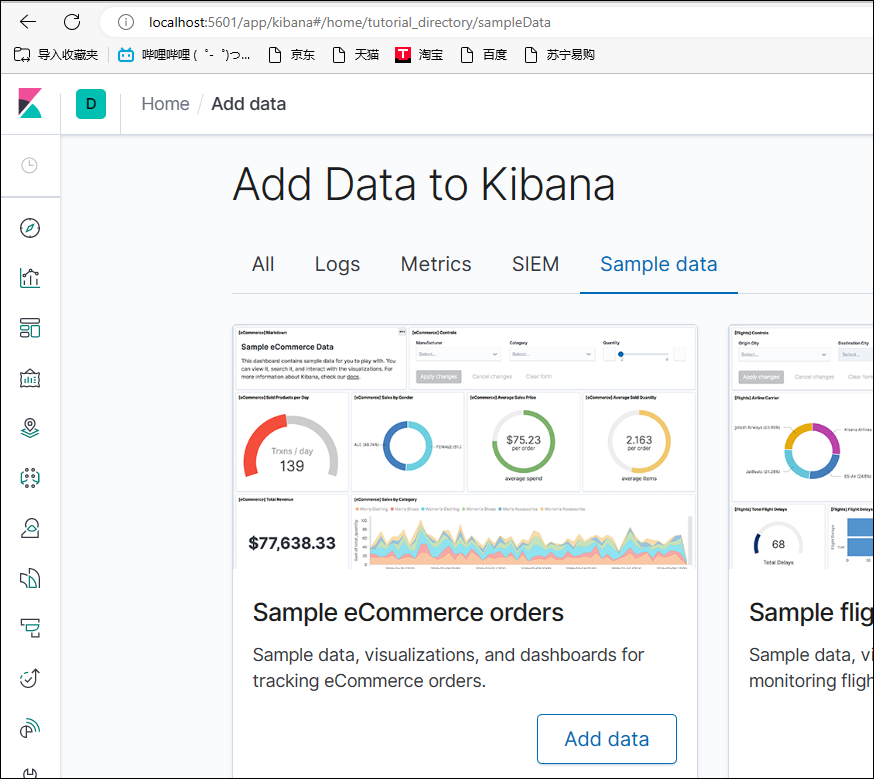
四、测试
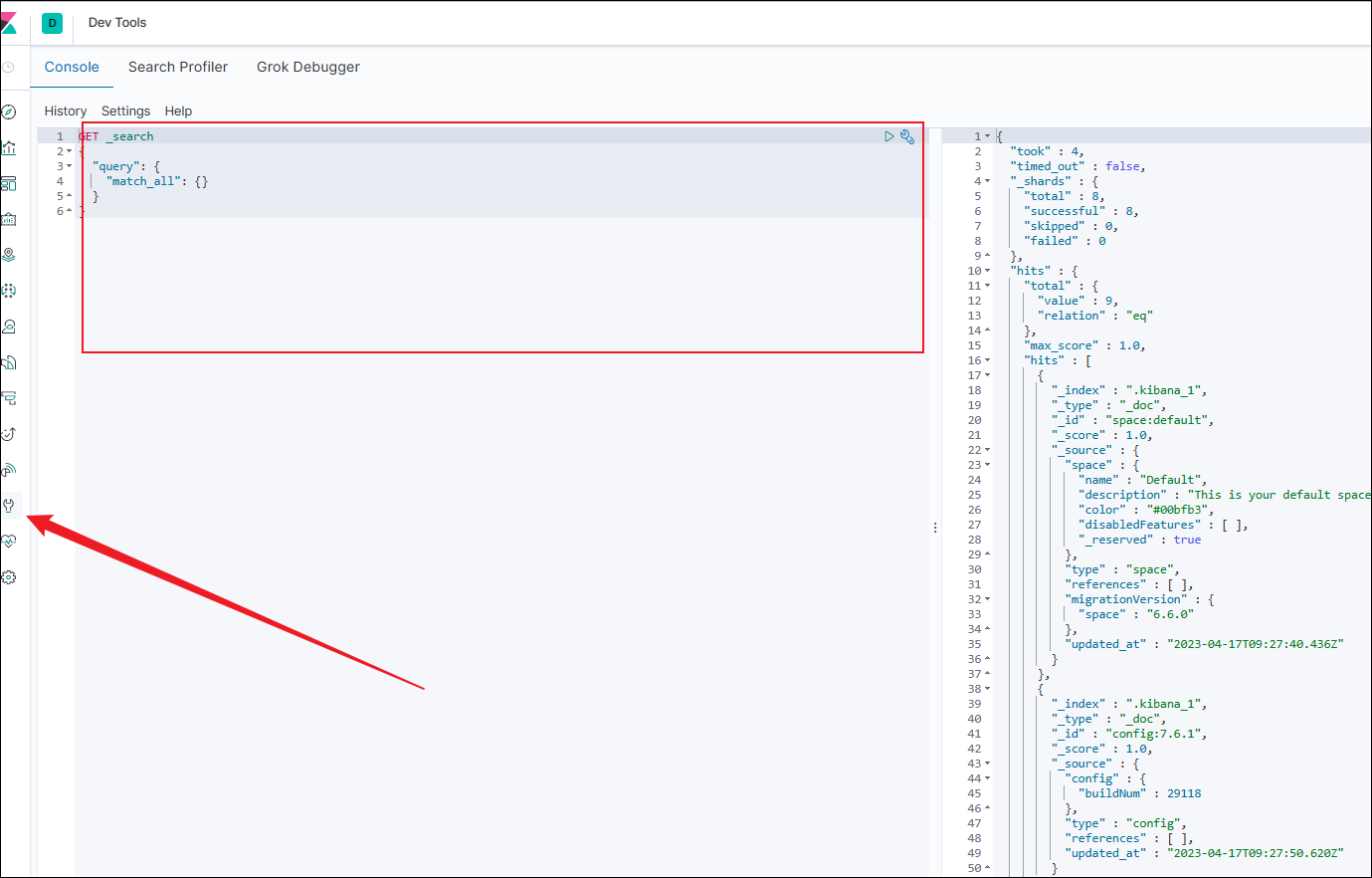
找到开发者工具,将来API的编写会在这个界面编写
五、汉化kibana
在我们的安装包中,有一个中文的 .json文件,这个文件的作用就是汉化
该文件的位置在:F:\MyDownloads\Environment\Elasticsearch\kibana-7.6.1-windows-x86_64\kibana-7.6.1-windows-x86_64\x-pack\plugins\translations\translations\zh-CN.json
1、找到和bin目录同级的config文件,进入后在kibana.yaml配置文件中配置如下(一直划到最下面)
i18n.locale: "zh-CN"2、重启kibana,汉化成功!
至此,关于ES的入门学习任务你已经完成。ES的优势我就不在这里再赘述了,后续还会持续更新关于ES的技术点,敬请期待~~~




