
- 1mac虚拟机crossover 23.6破解版带来全新功能_crossover crack
- 2贝叶斯网络_贝叶斯网络因果方向
- 3《大数据系统与编程》常用的HBase操作实验报告_hbase数据库:hbase表设计和操作实验报告
- 4CrossOver (Mac安装Windows应用) v23.7中文激活版2024最新图文安装教程_crossover23.7安装包
- 5module ‘numpy‘ has no attribute_module 'numpy' has no attribute 'typedict
- 6动态规划算法_)动态规划(dynamic programming)算法的核心思想是:将大问题划分为小问题进行
- 7Redis数据类型及常用命令_了解redis存储的基本类型和使用命令
- 8rebasing状态、找回commit时候的代码
- 9PGD_Towards deep learning models resistant to adversarial attacks_CSDN
- 10MacBook(m1)配置Python注意事项(自用,持续更新)_m1安装sklearn
【无门槛】机器学习 —— Amazon SageMaker Canvas 【供应链准时交付(场景)】_canvas数据集
赞
踩
继上一篇博客
【无门槛】机器学习——Amazon SageMaker Canvas 【实验配置篇】
我们可以接下根据不同的数据集做不同场景下的机器学习来分析数据。
好了废话不多讲,直接开撸。
一、场景概述
在本实验室中,您将扮演物流业公司的业务分析师角色。您的目标是预测货物到达的估计时间(天数)。您将使用零售领域的一个著名数据集 - Shipping Logs数据集。该数据集包含所有已交付产品的完整运输数据,包括估计的优先发运时间、承运人和发货地。该数据集约含有10000行,12个特性列,数据模式如下所示:

二、将数据集上次到S3存储桶
第一步就是下载我们将使用的数据集。该数据集包含两个文件,您可以点击以下链接下载:
Shipping Logs(运输日志)
Product Description(产品说明)
进入S3,选择我们之前的sagemaker-studio-xxxxxxxx存储桶
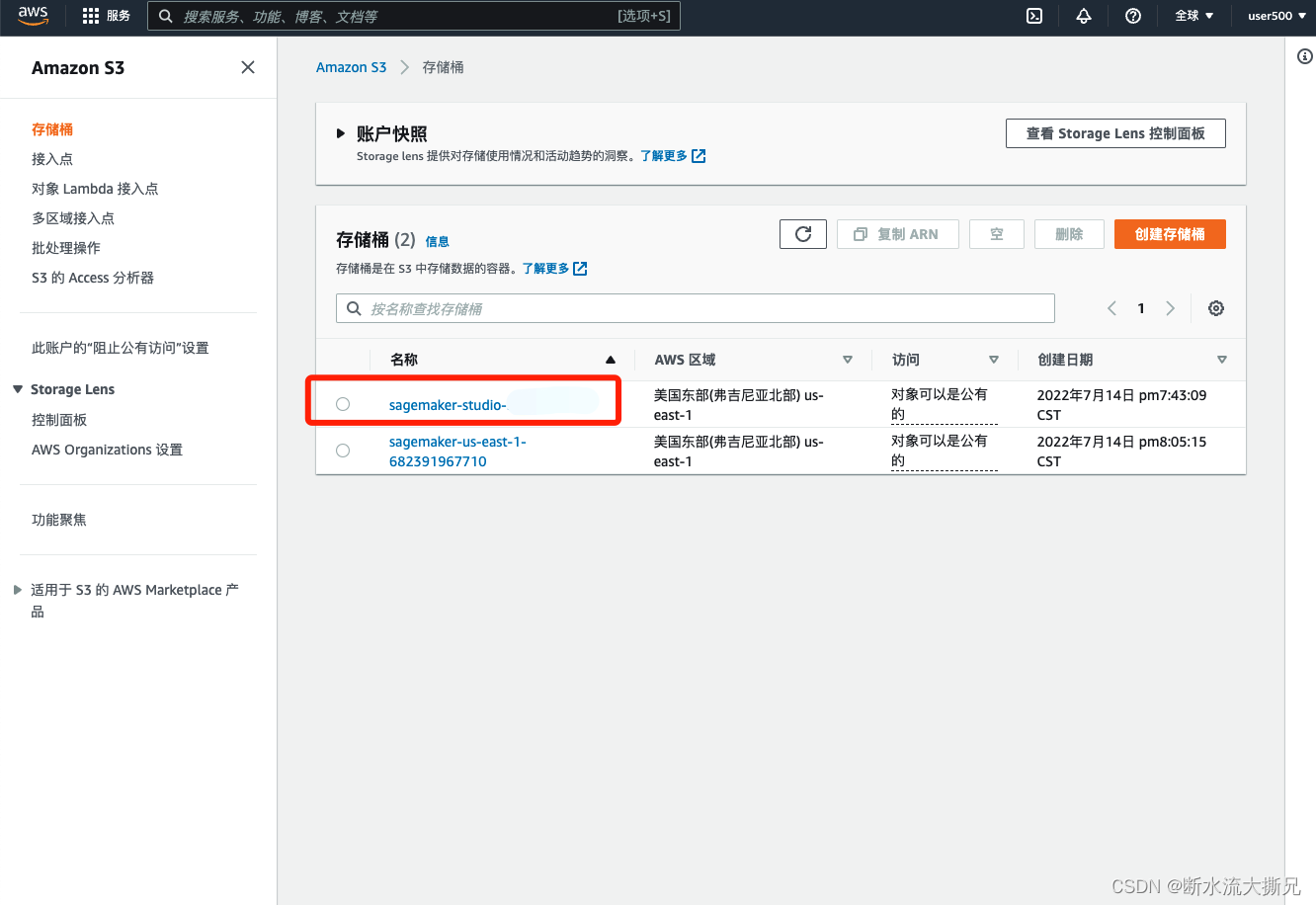
点击然后进行文件上传
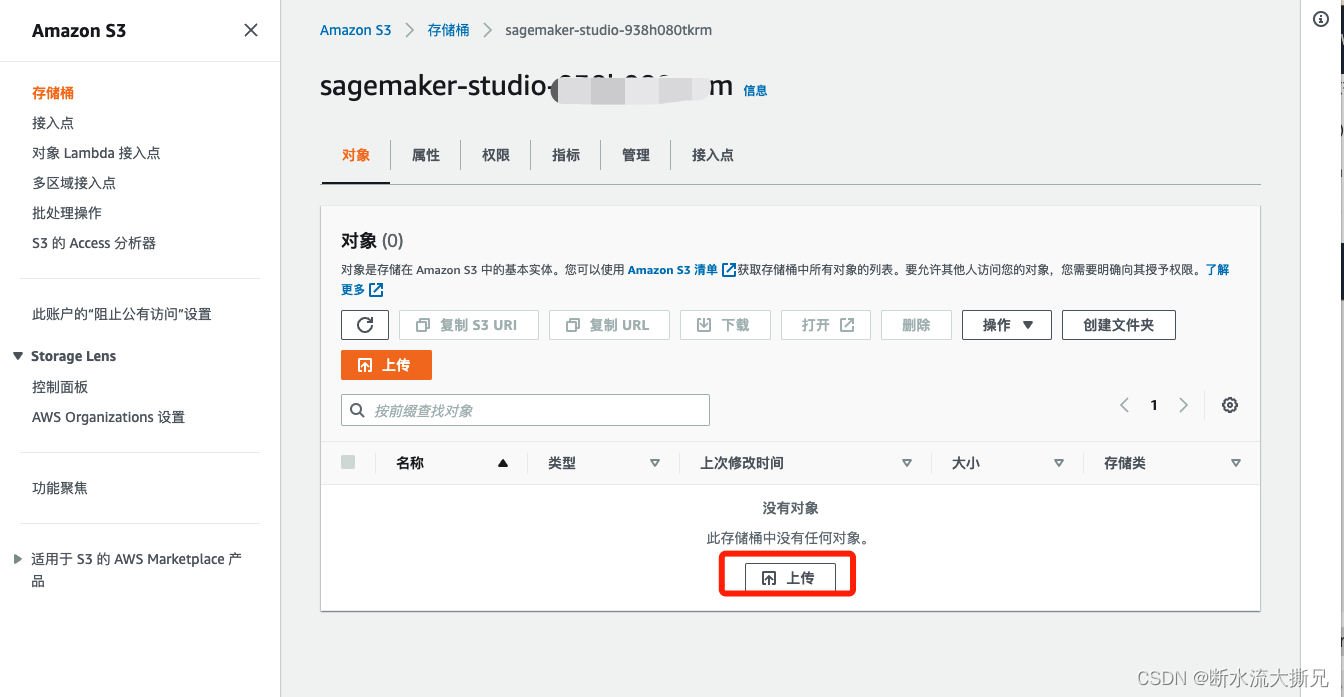
选择刚刚下载的两个文件,然后上传
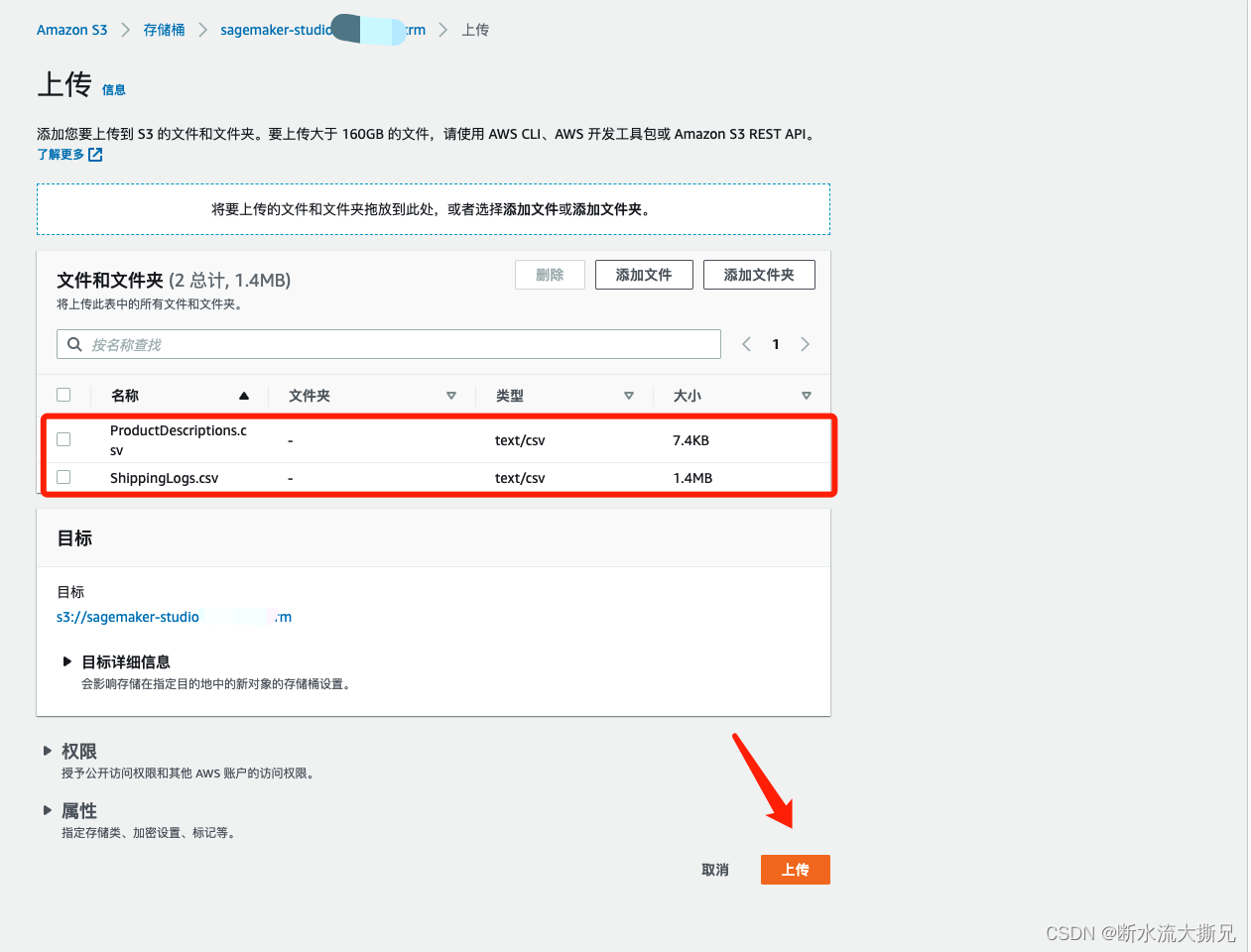
这样,数据集我们就准备好了。接下来我们准备开始正式操作Canvas
三、在Amazon SageMaker Canvas中导入数据集
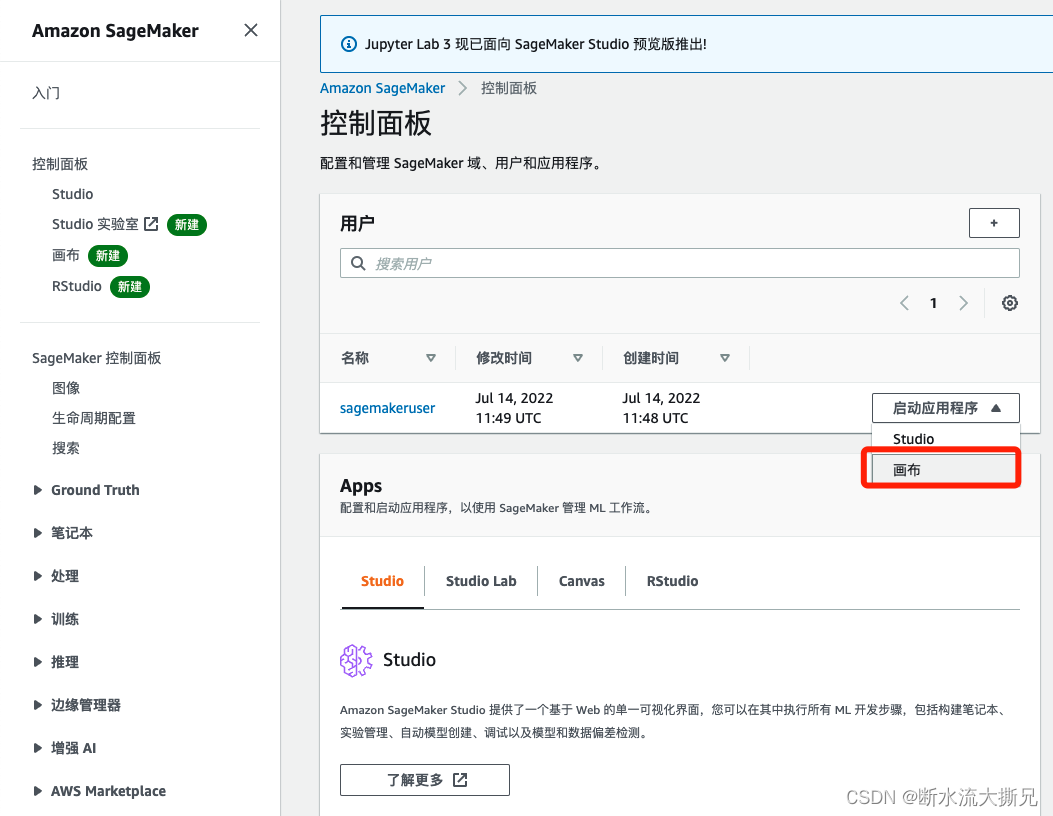
从这里进入 Canvas
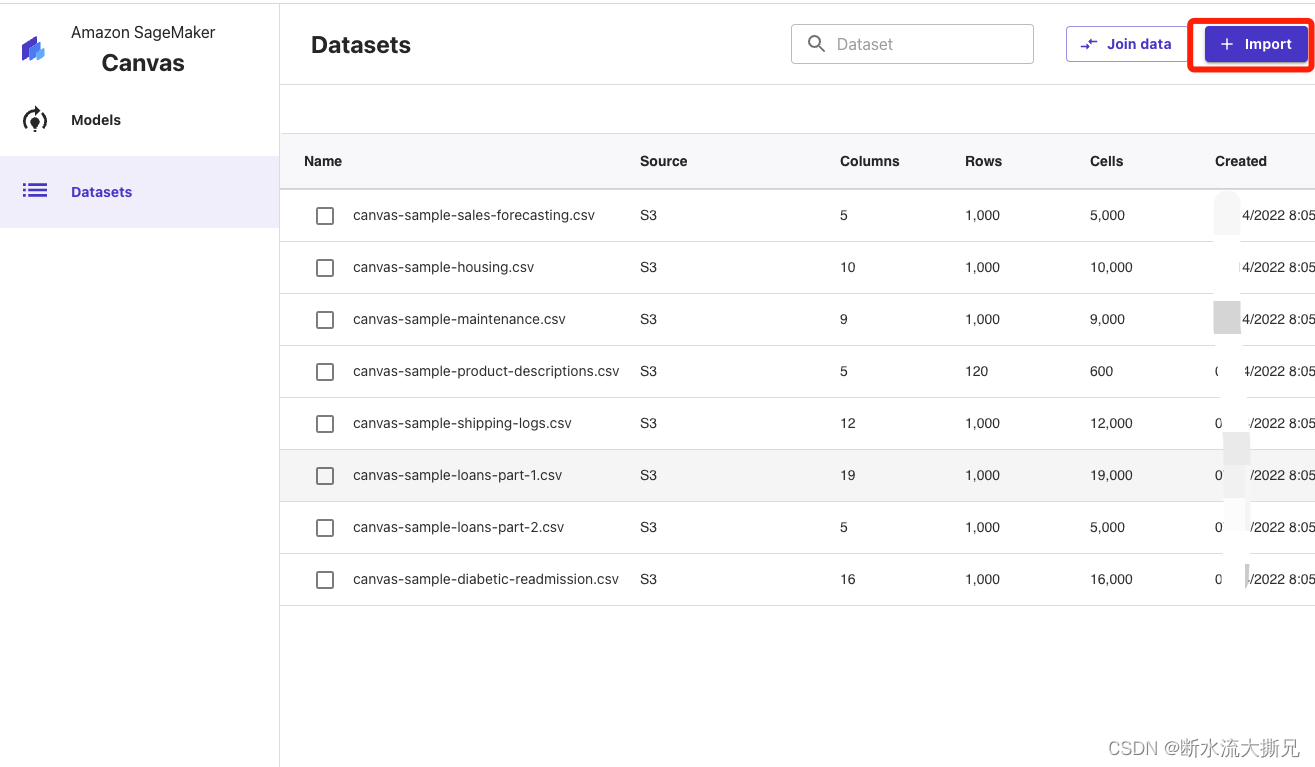
点击导入
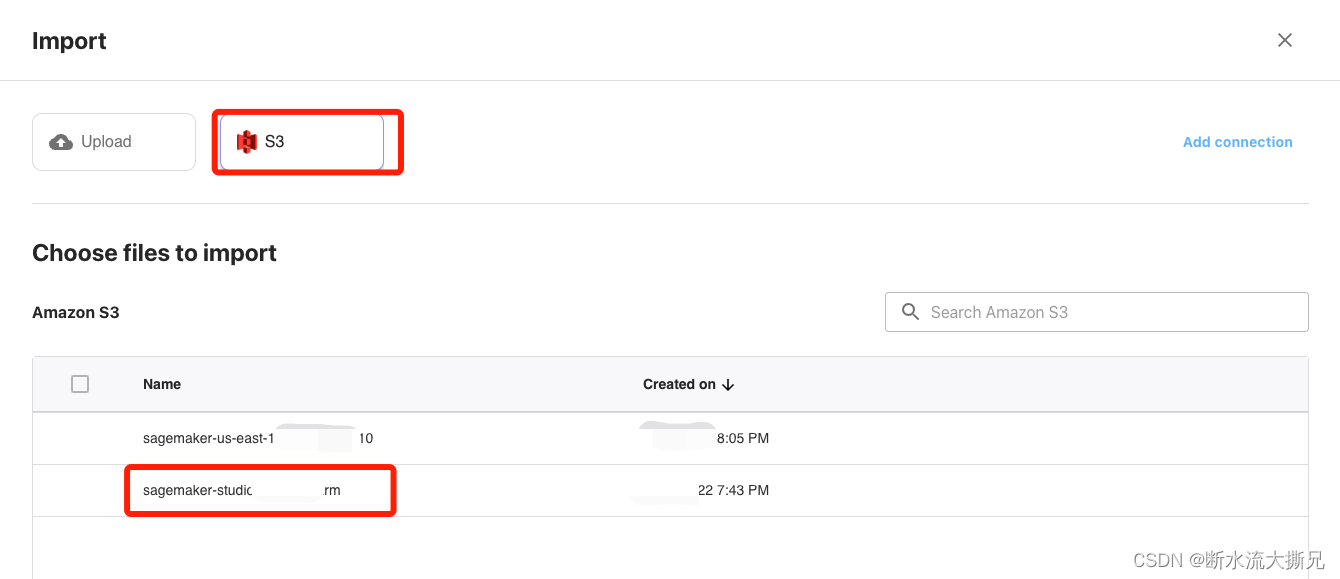
选择S3,点击刚刚我们操作的那个S3桶
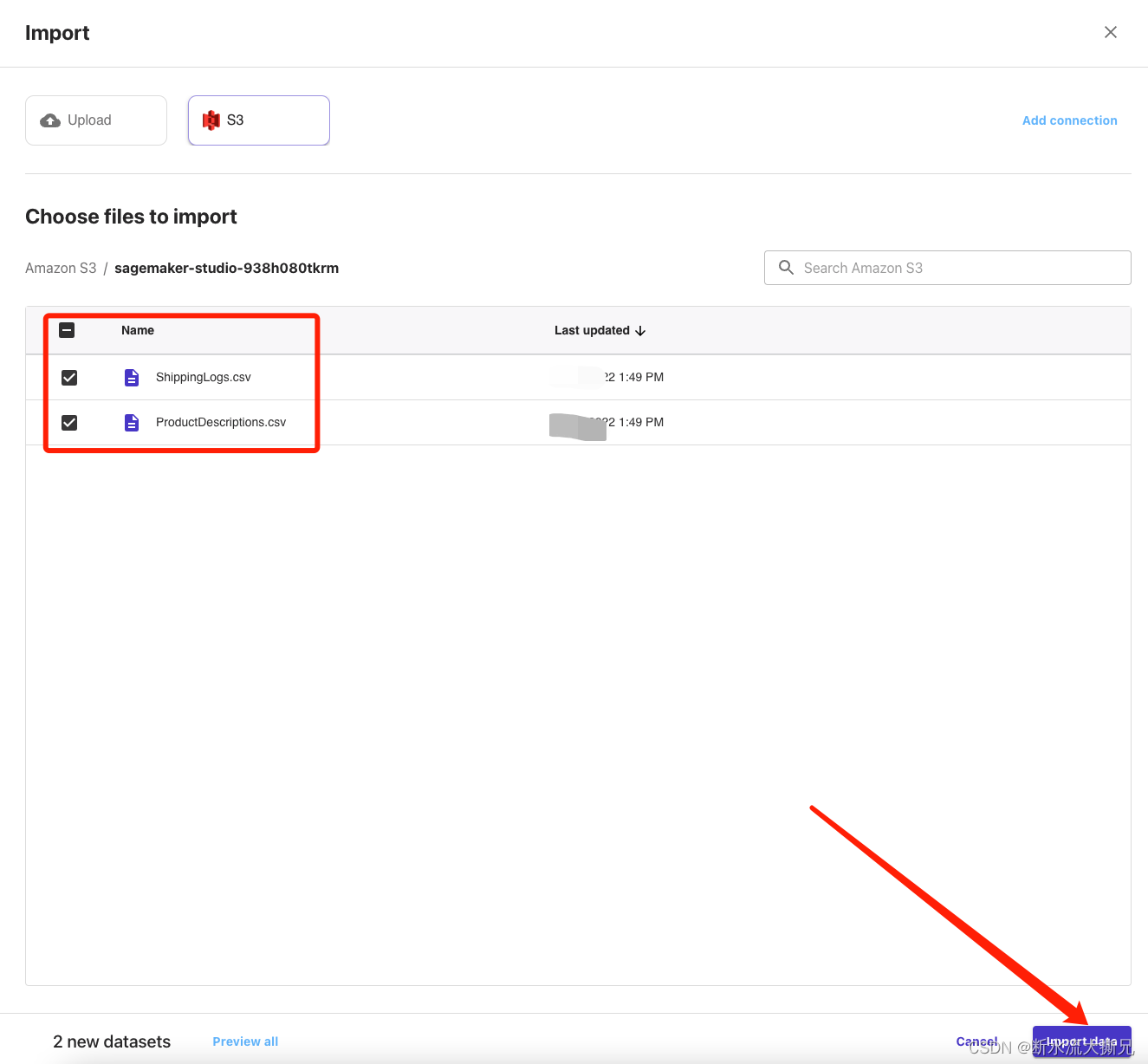
勾选两个数据集后,我们选择 导入数据
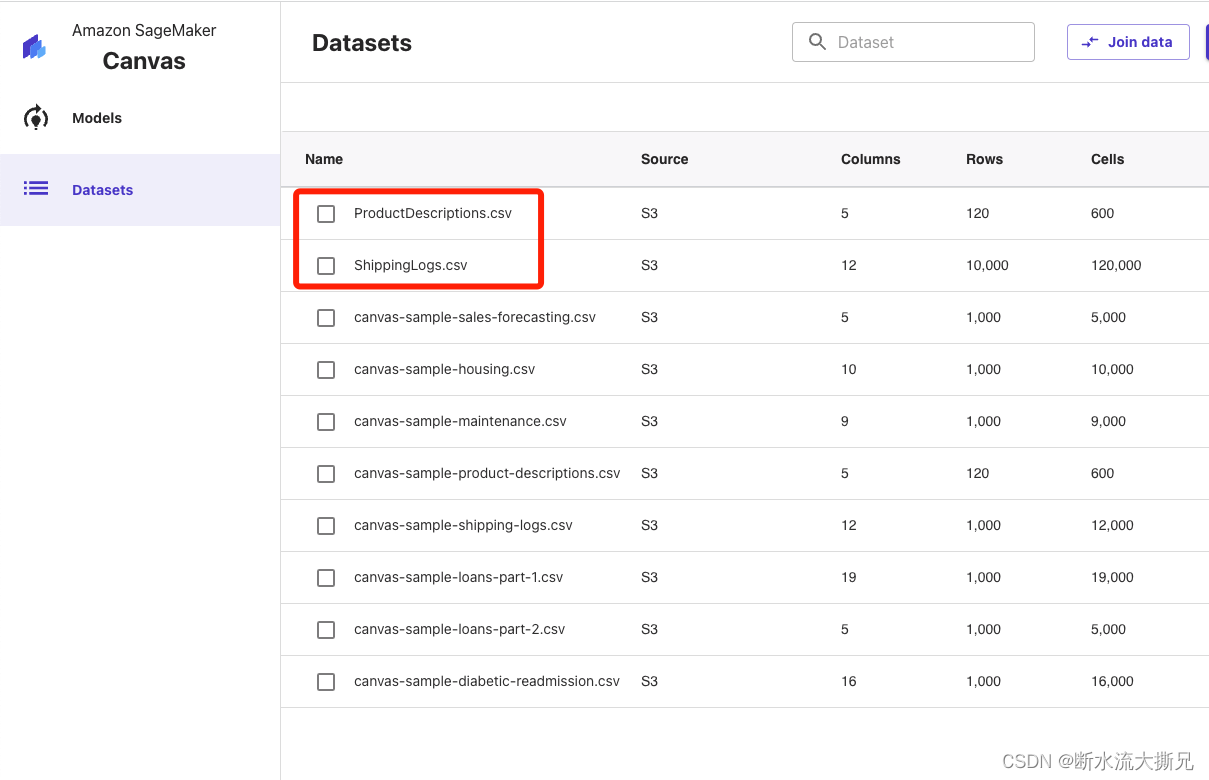
操作完成后,数据首页就有我们刚刚操作的两个数据集了,有兴趣的可以点击进去看看数据模型和数据数量
比如我们点击这个日志数据
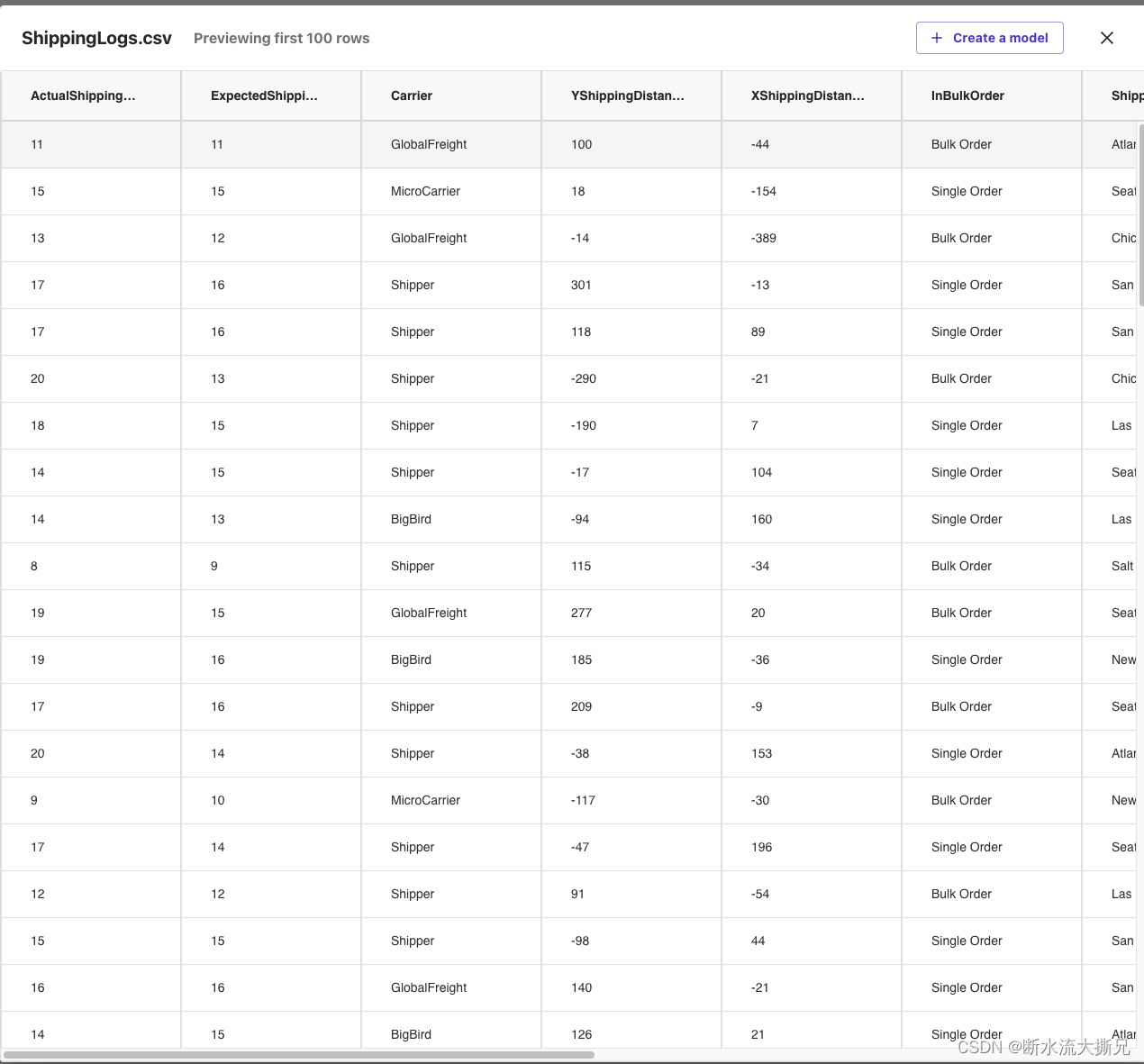
注意: 前面的表格中有每个字段的意思,你可以结合看一下,这样能更加了解我们在做什么,并且后面也可以根据不同的字段进行数据分析
由于是对两个表进行分析,一个是产品说明表,一个是日志表,我们需要将两个表的关联Key进行关系绑定
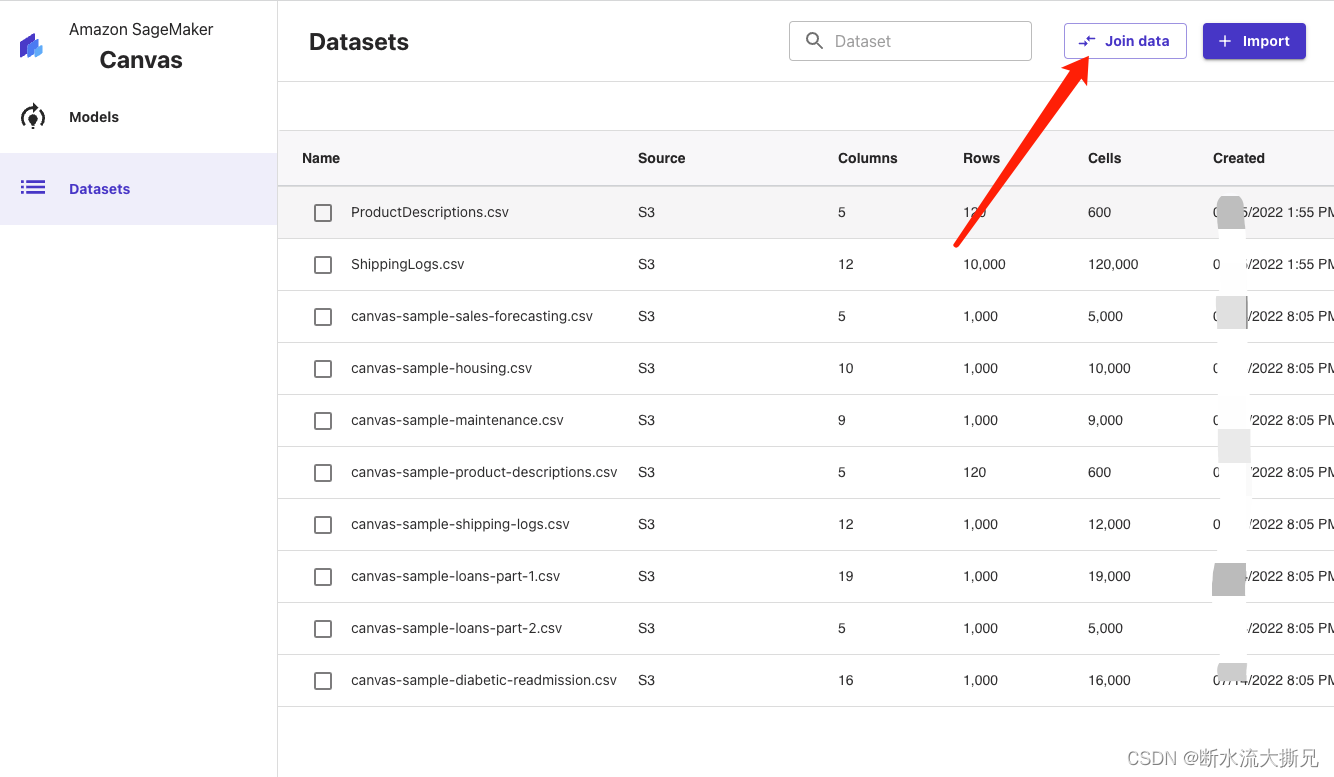
点击关联数据
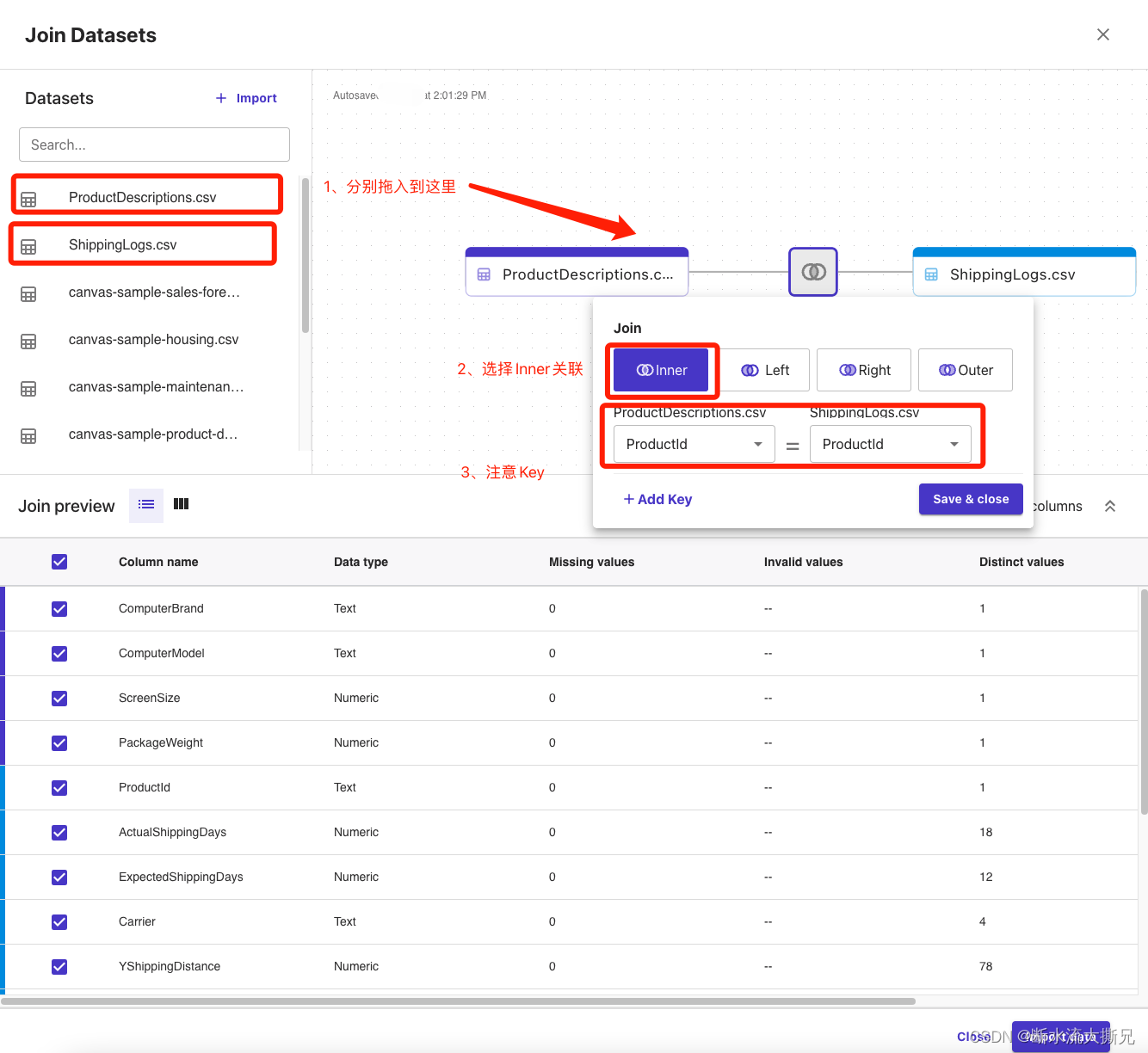
看图操作怎么管理两个数据集数据
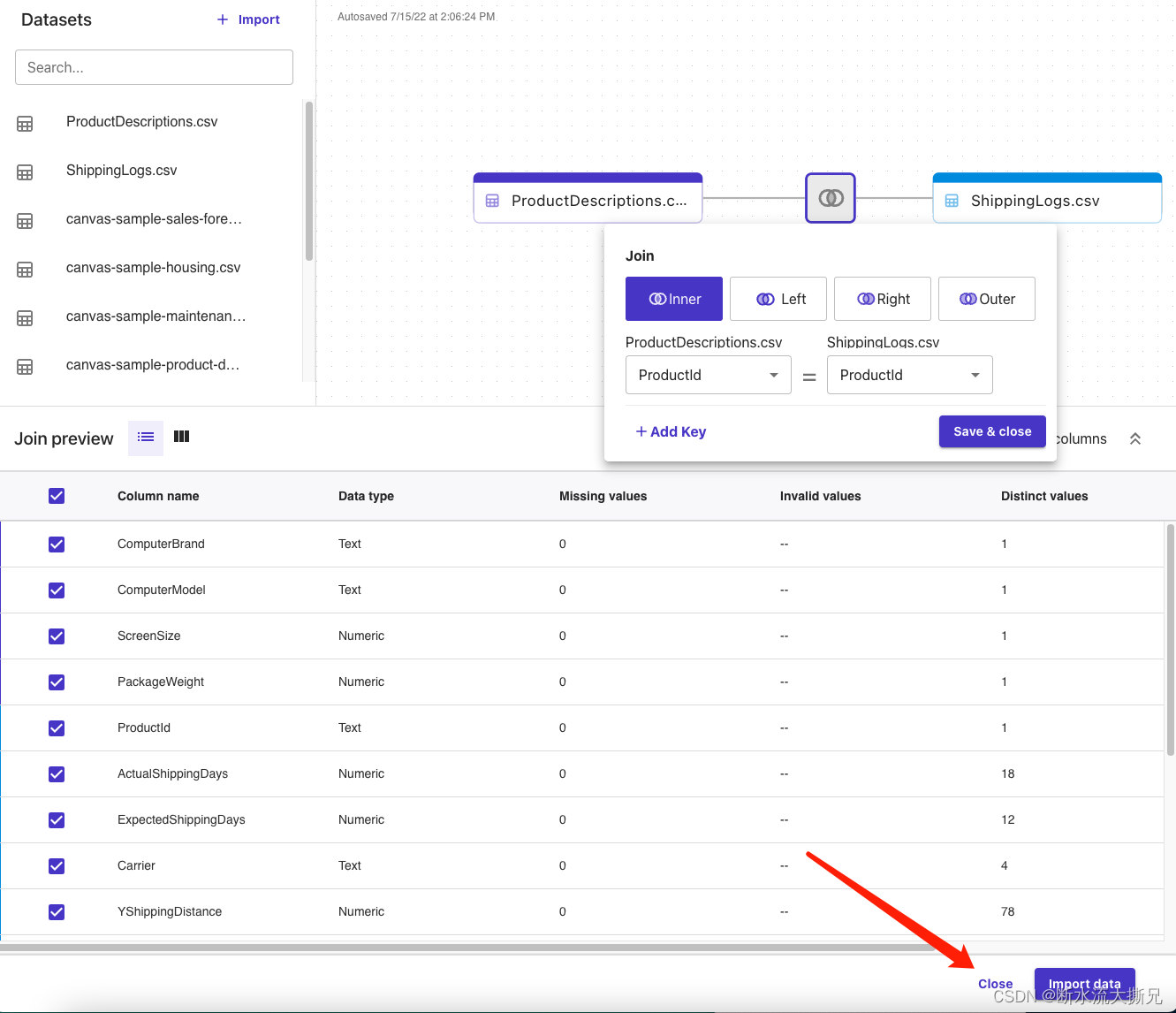
关联完成后 直接Close就行。
至此,我们已经把数据导入到Amazon SageMaker Canvas,并且让两个表的数据关联上了。
到目前为止应该不难吧。
接下来,我们模型训练
四、构建与模型训练
首先我们先训则到Canvas的 模型界面
点击新建模型
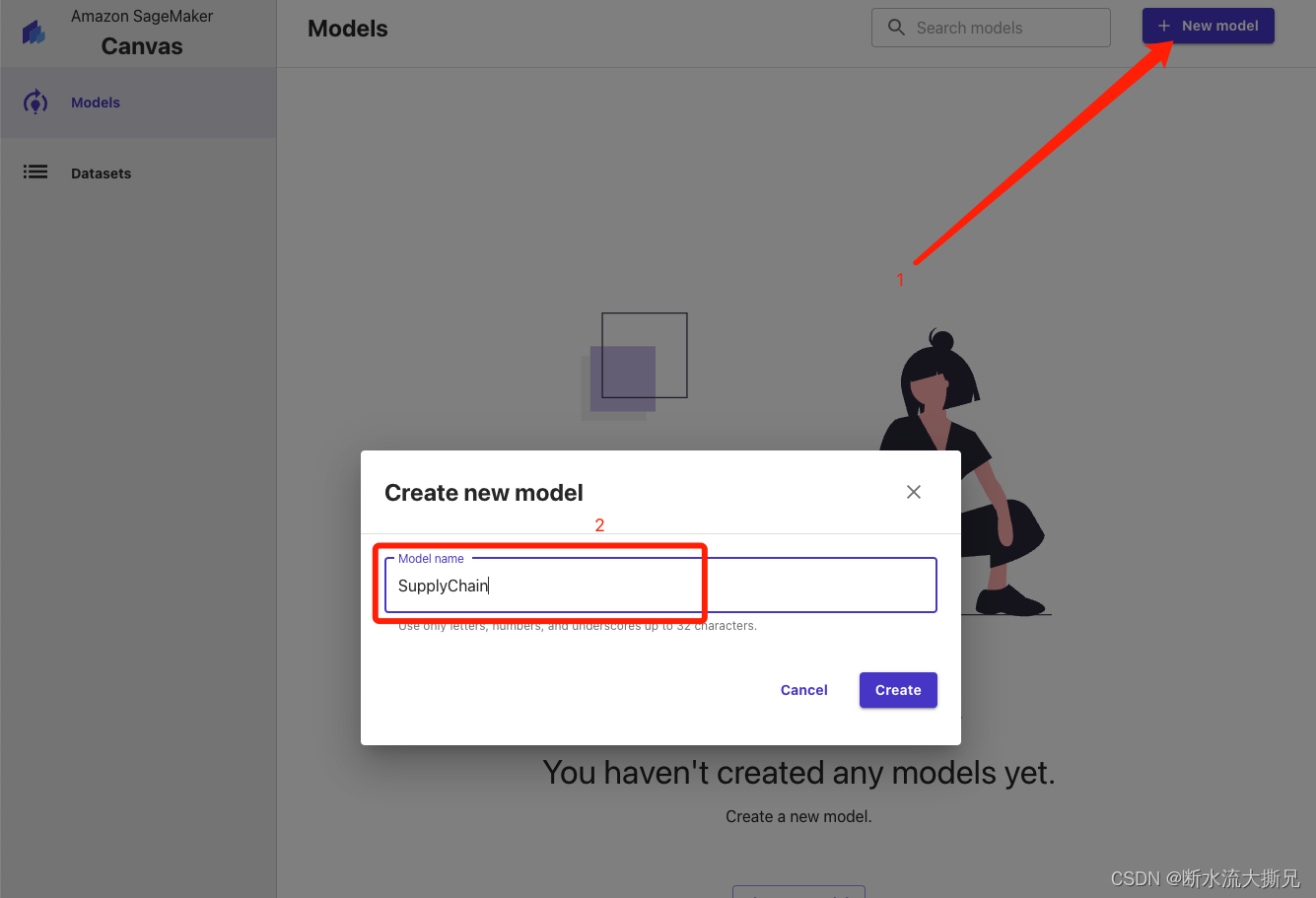
我们起一个SupplyChain(供应链)的名字
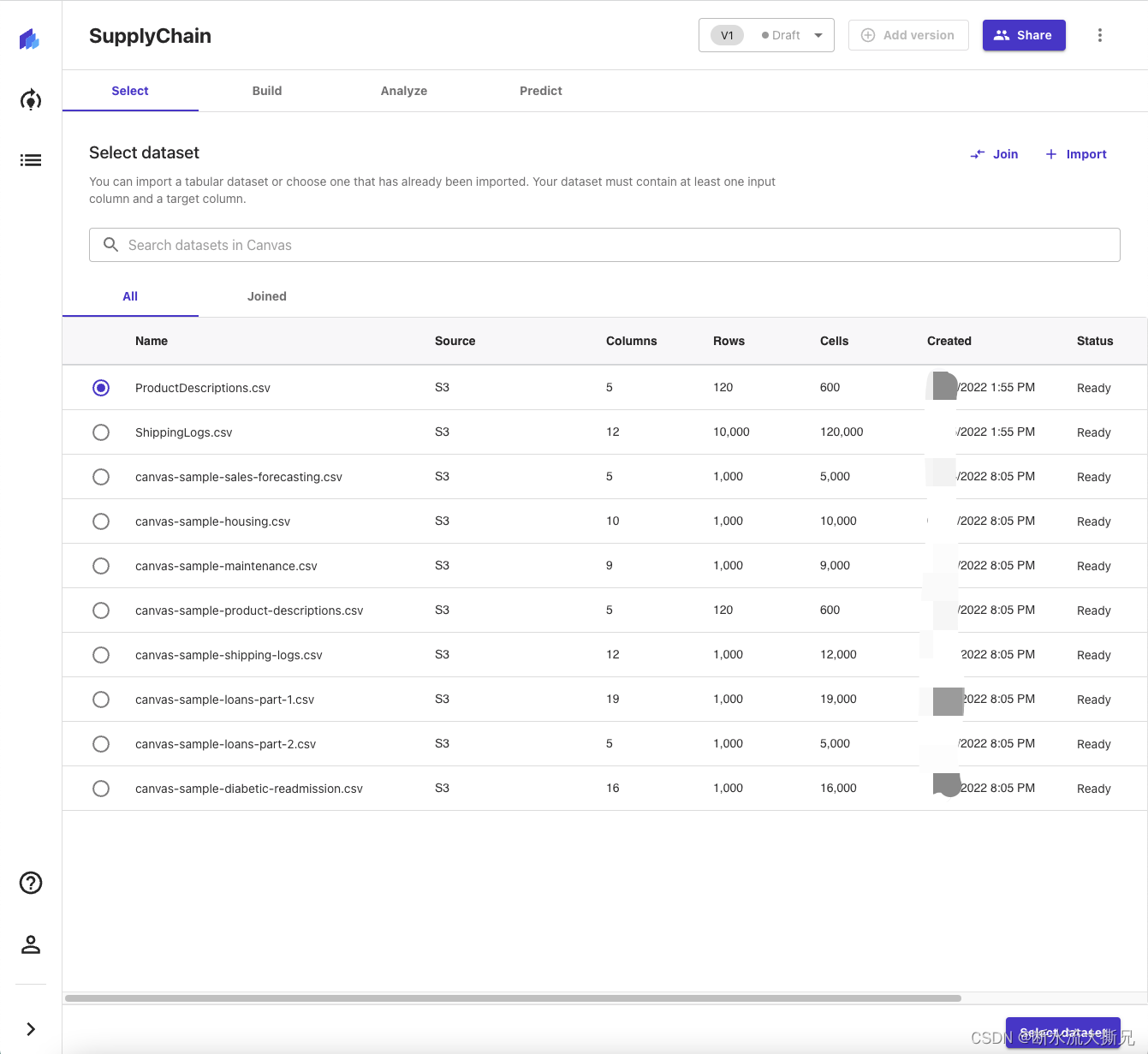
创建完成后你应该进入了一个这样的页面
在模型视图中,您会看到四个选项卡,分别对应构建模型并用来生成预测的四个步骤: Select(选择)、 Build(构建)、 Analyze(分析)、 Predict(预测)。在第一个 Select 选项卡中,点击单选按钮
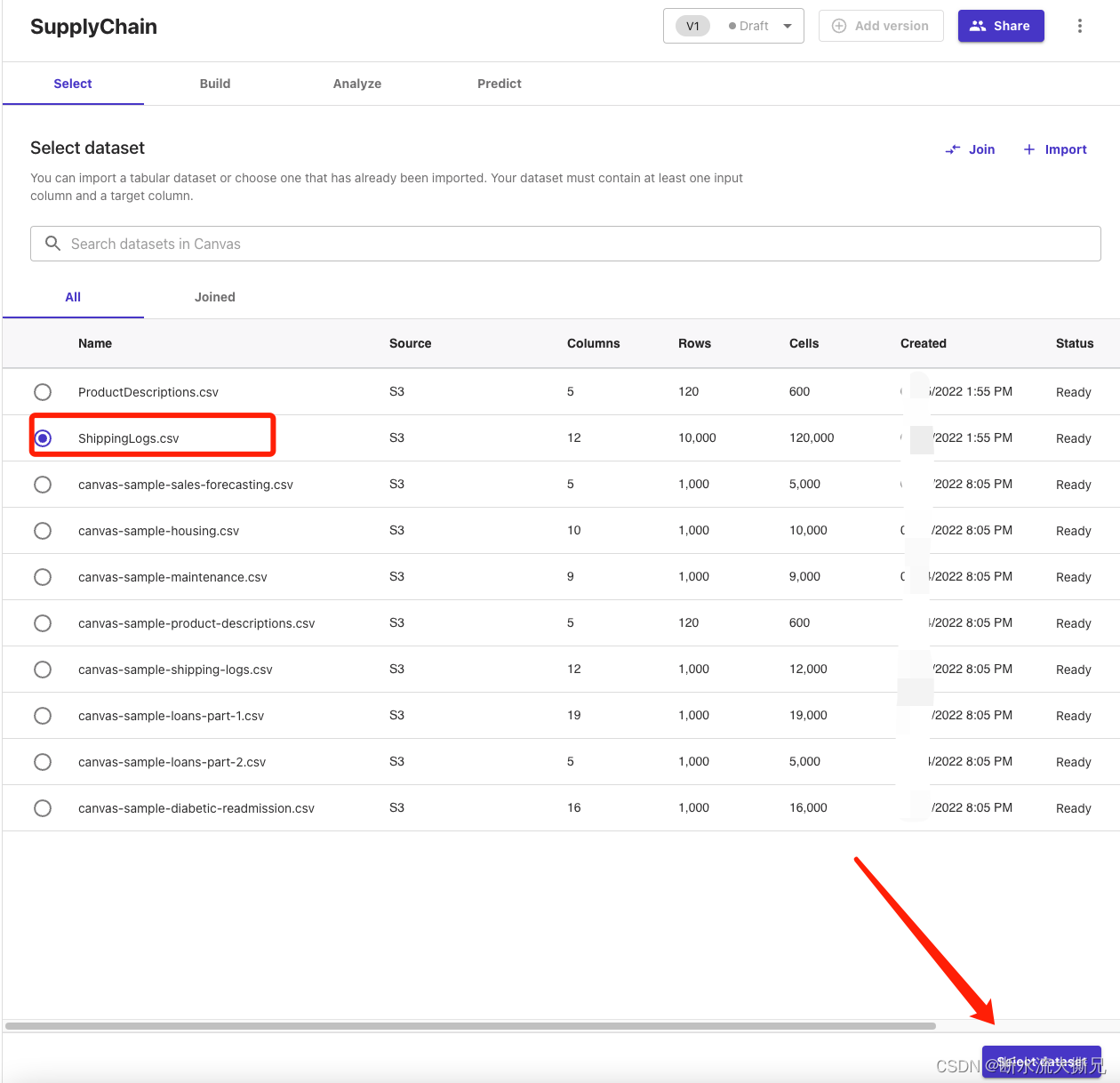
选中我们之前的日志数据,然后点击Select dataset(选择数据集)按钮。
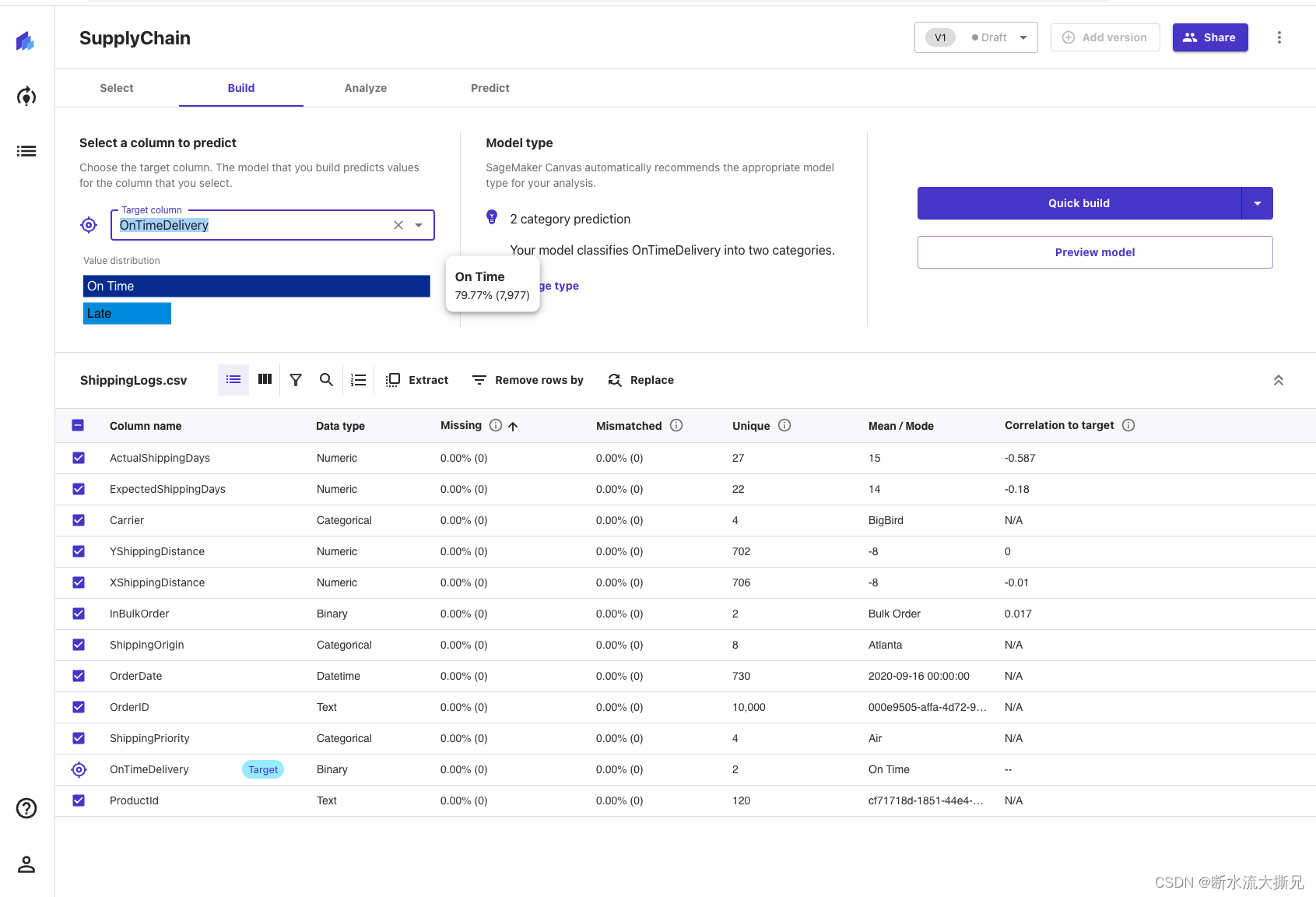
我们将进入第二个选项 Build(构建)阶段,页面中,我们可以根据各个字段来做数值预测 例如OnTimeDelivery是否准时交货、OnTimeDelivery发货地等。
在屏幕的下半部分,您可以查看数据集的一些统计数据,包括缺失值和不匹配值、唯一值、均值和中值。您可以查看如下一些统计数据和信息:
- Column View(列视图) 提供了所有列的列表,其数据类型及其基本统计数据,包括缺失值和不匹配值、唯一值、均值和中值。这将有助于您制定策略,处理数据集中的缺失值
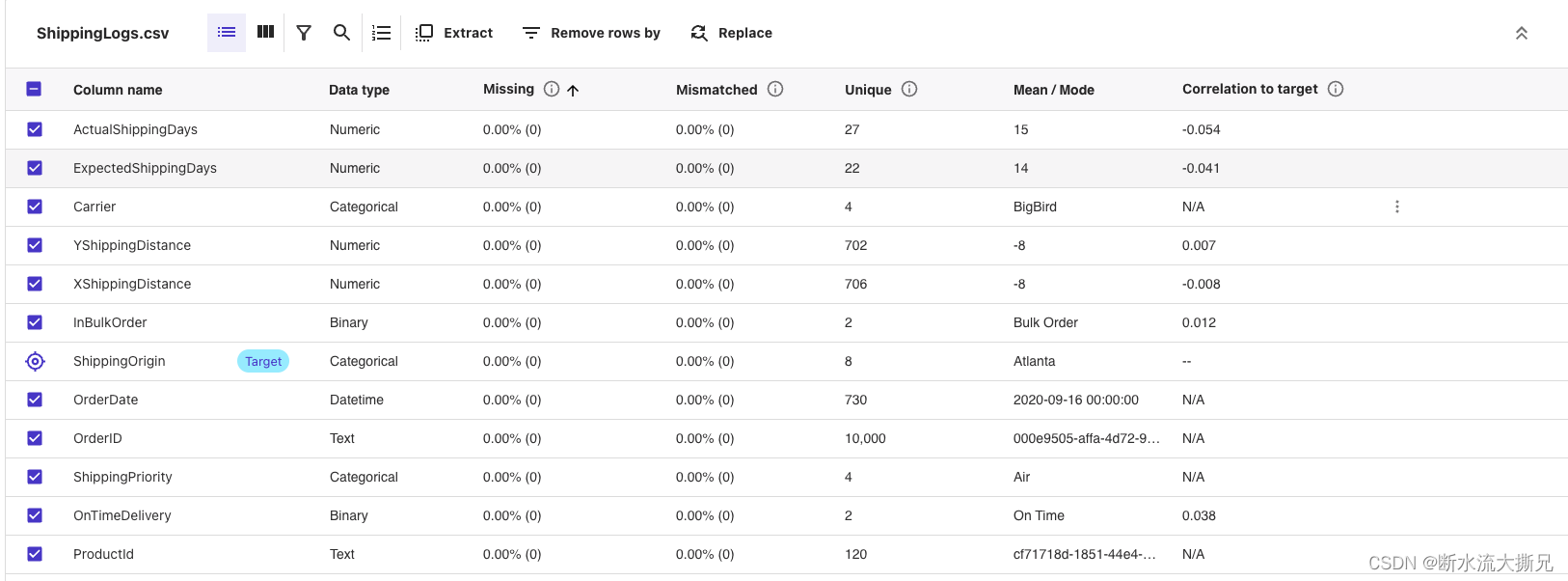
- Grid View(网格视图) 提供各列和样本数据的数值分布图。您可以开始推断用于训练模型的相关列
探索过这里后,就到了最终训练模型的时候了!在构建完整的模型之前,通过训练一个Quick Model(快速模型),从而对我们的模型性能有一个大致了解,不失为一种很好的做法。为优先考虑速度而非准确性,快速模型所训练的模型和超参数组合较少,特别是在像我们这样想证明ML模型训练在我们用例之中的价值情况下。请注意,快速构建不能用于超过5万行的模型。让我们继续并点击Quick build(快速构建)。
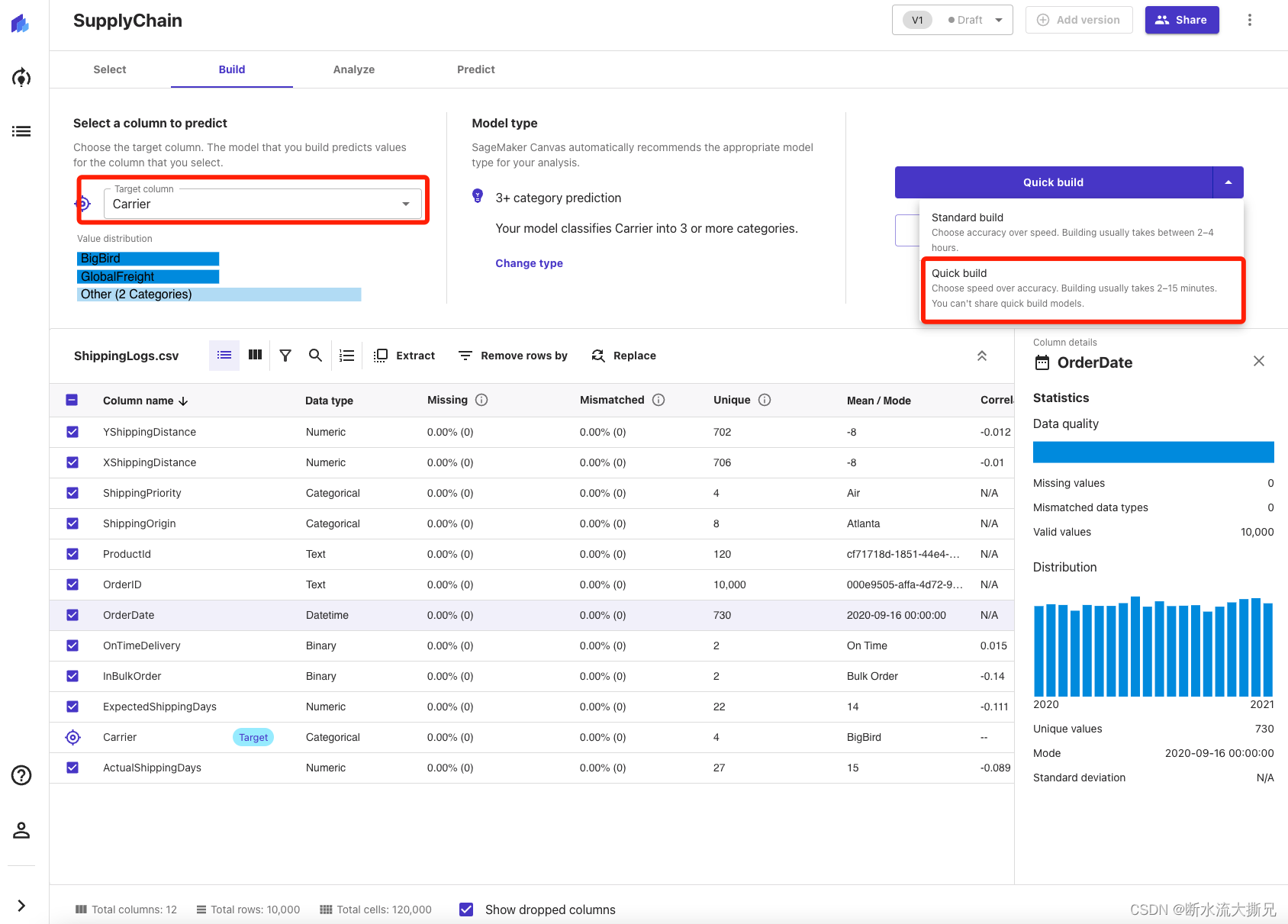
这一步大概等待2-15分钟,让Quick build(快速构建)完成模型训练。
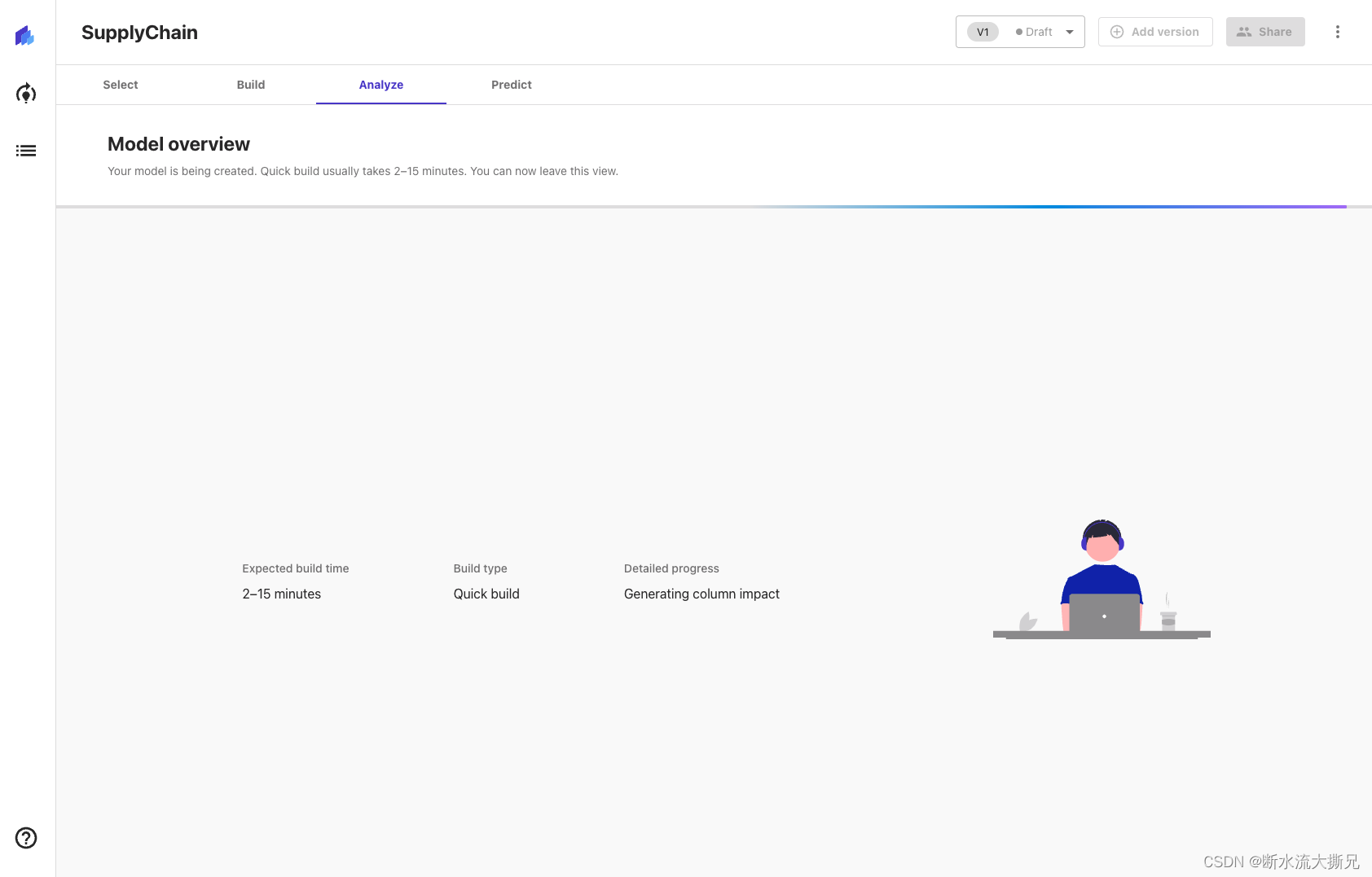
训练模型构建好了之后,会是这样的页面,有一个弹窗让你选择使用体验
如果以下各图中的数字与你的数字不同,不必担心。机器学习在模型训练过程中加入了一些随机性,可能导致不同的构建所生成的结果不同。
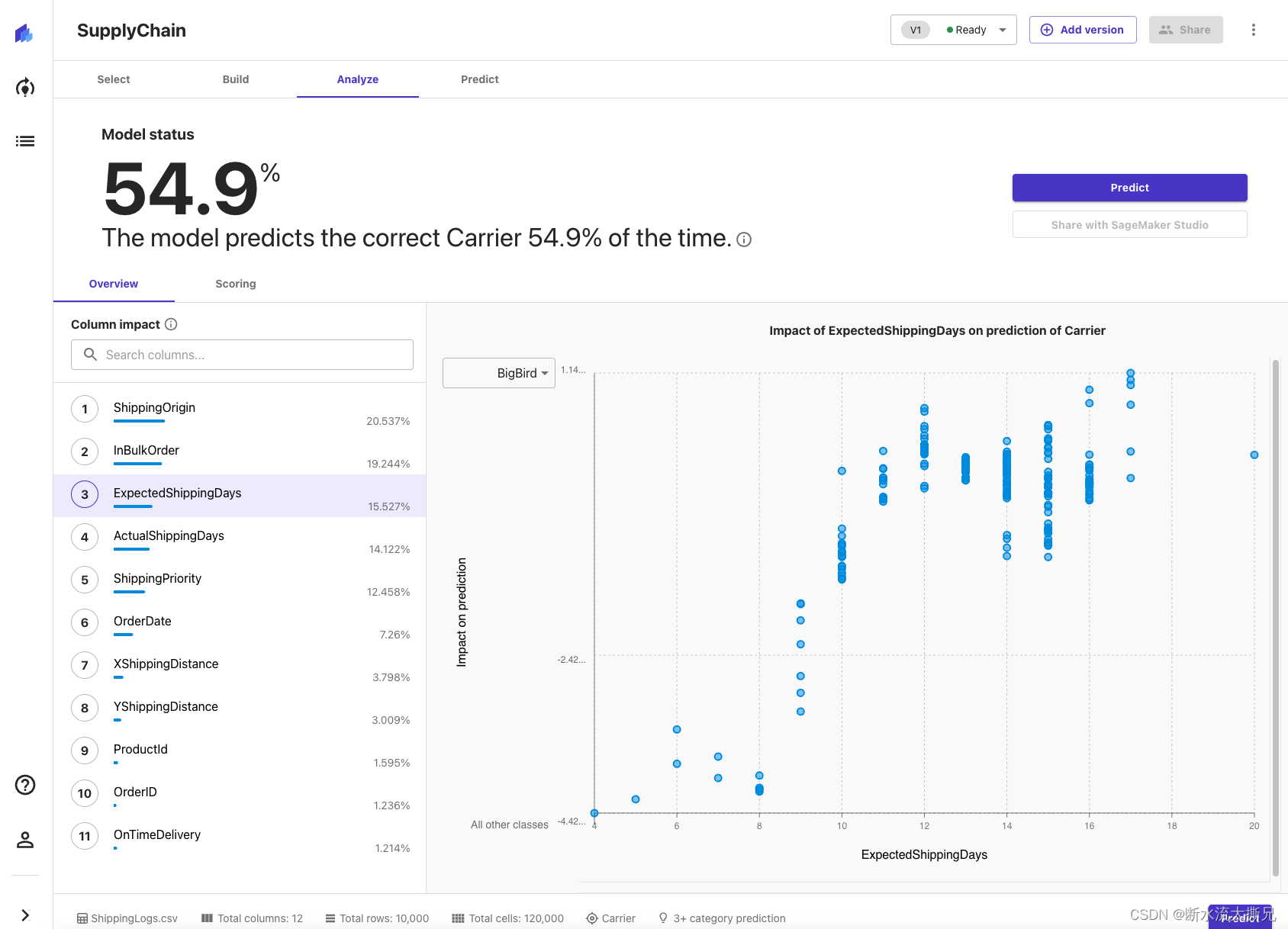
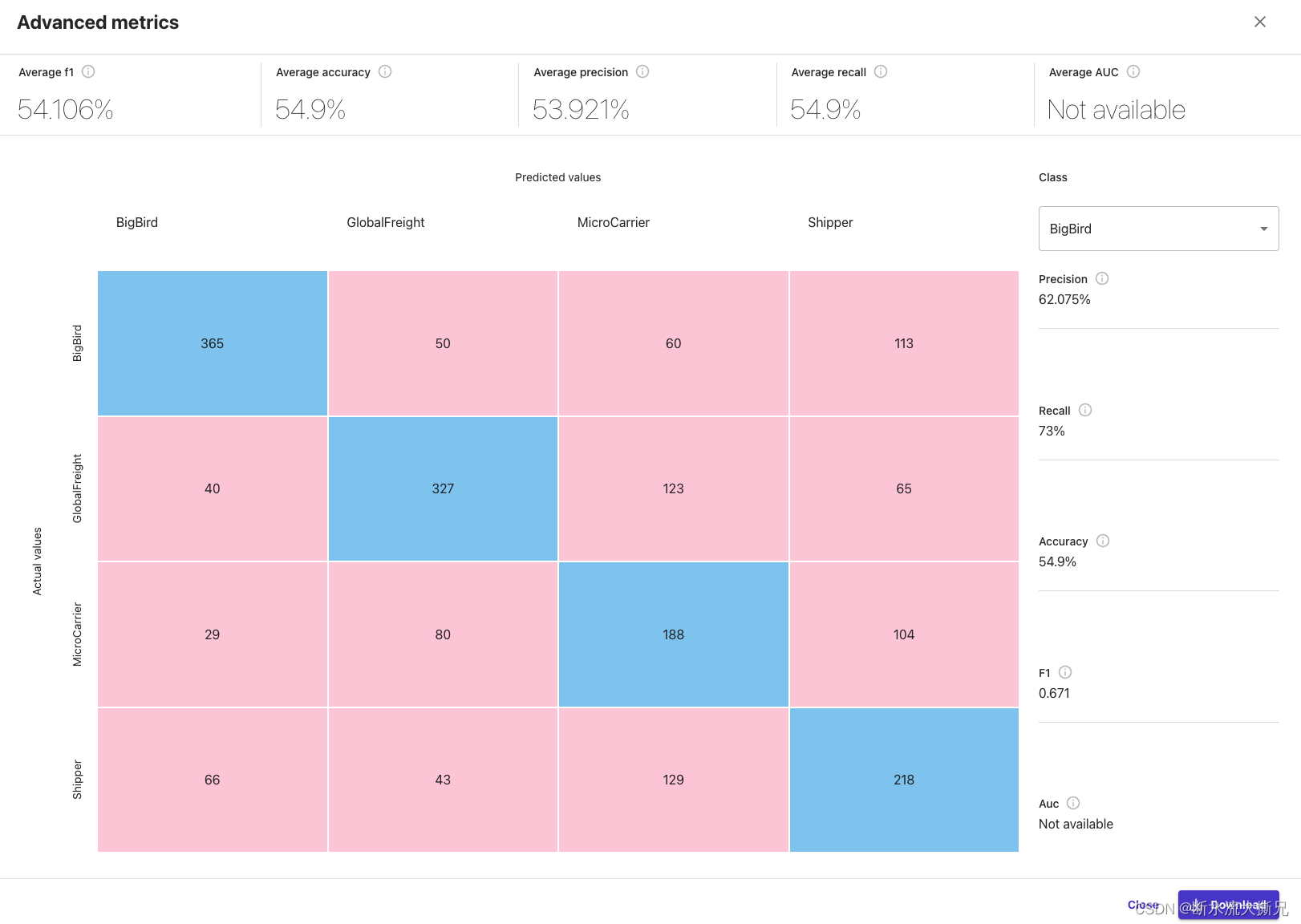
现在,我们来看一下第一个选项卡: Overview(概览)。该选项卡向我们展示了 Column impact(列影响),也就是每一列在预测目标列中的大致重要性。在该示例中,ExpectedShippingDays列在我们的预测方面具有最大影响。
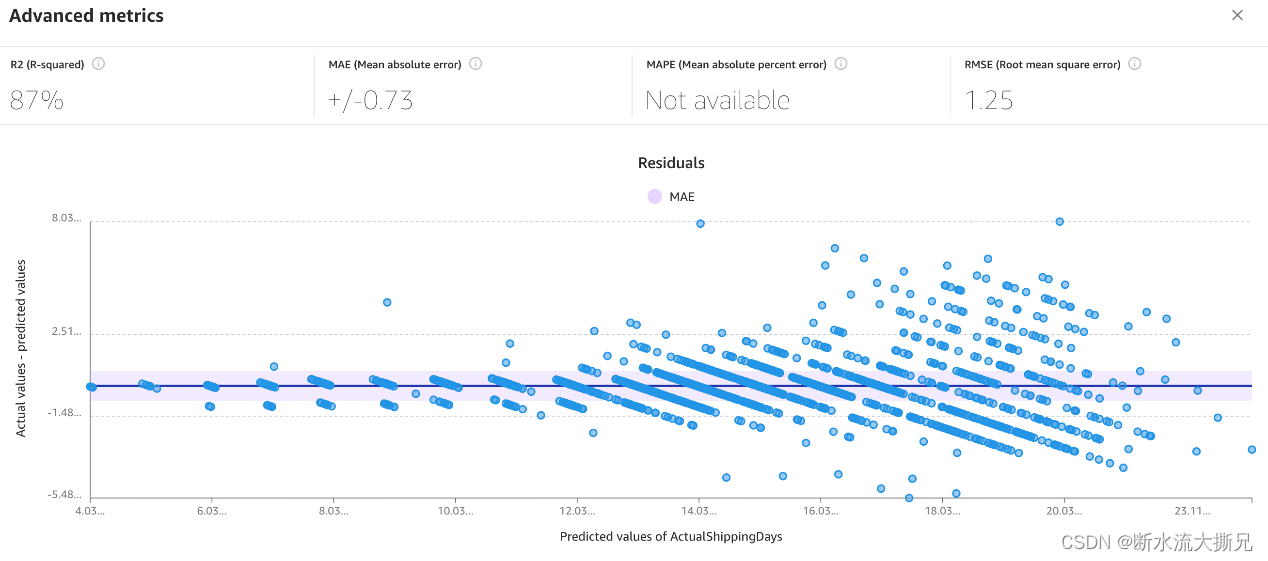
advanced metrics(高级指标)包含的信息供希望更深入了解其模型性能的用户使用。以下定义了Amazon SageMaker Canvas中数字预测的高级指标,并为您提供了高级指标使用方法的相关信息。
- R2 – 目标列内差异百分比,可通过输入列阐明。
- MAE – 平均绝对误差。平均而言,对目标列的预测与实际值相差+/- {MAE}。
- MAPE –平均绝对百分比误差。平均而言,对目标列的预测与实际值相差+/- {MAPE}%。
- RMSE – 均方根误差。误差的标准偏差。
- 下图为残差或误差图。水平线表示误差为0或完美预测。蓝点代表误差。这些蓝点与水平线的距离代表误差大小。
五、使用该模型预测结果
现在,模型已经训练完毕,让我们用其进行一些预测。请在Analyze(分析)页面底部选择Predict(预测),或者选择Predict(预测)选项卡。
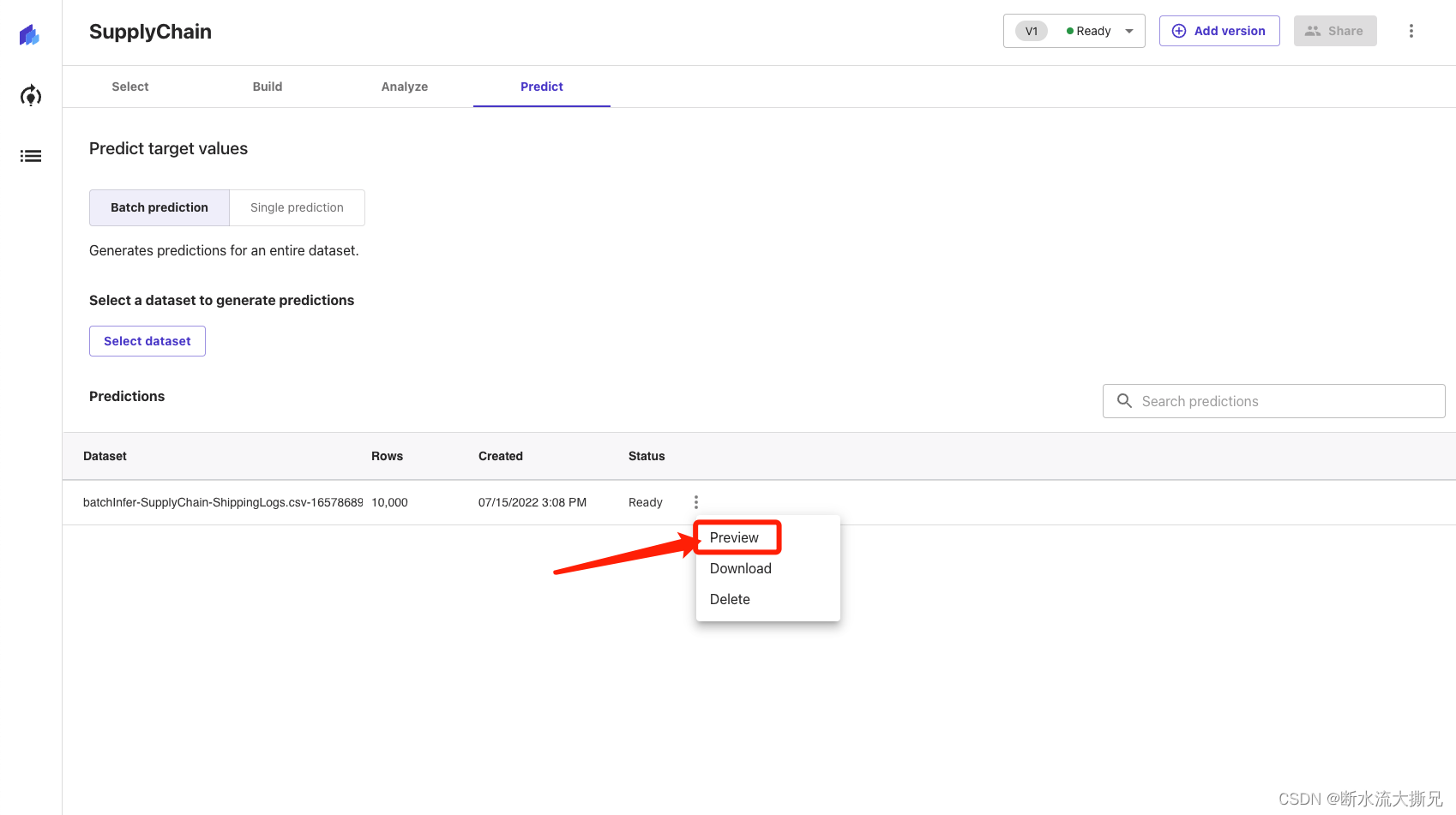
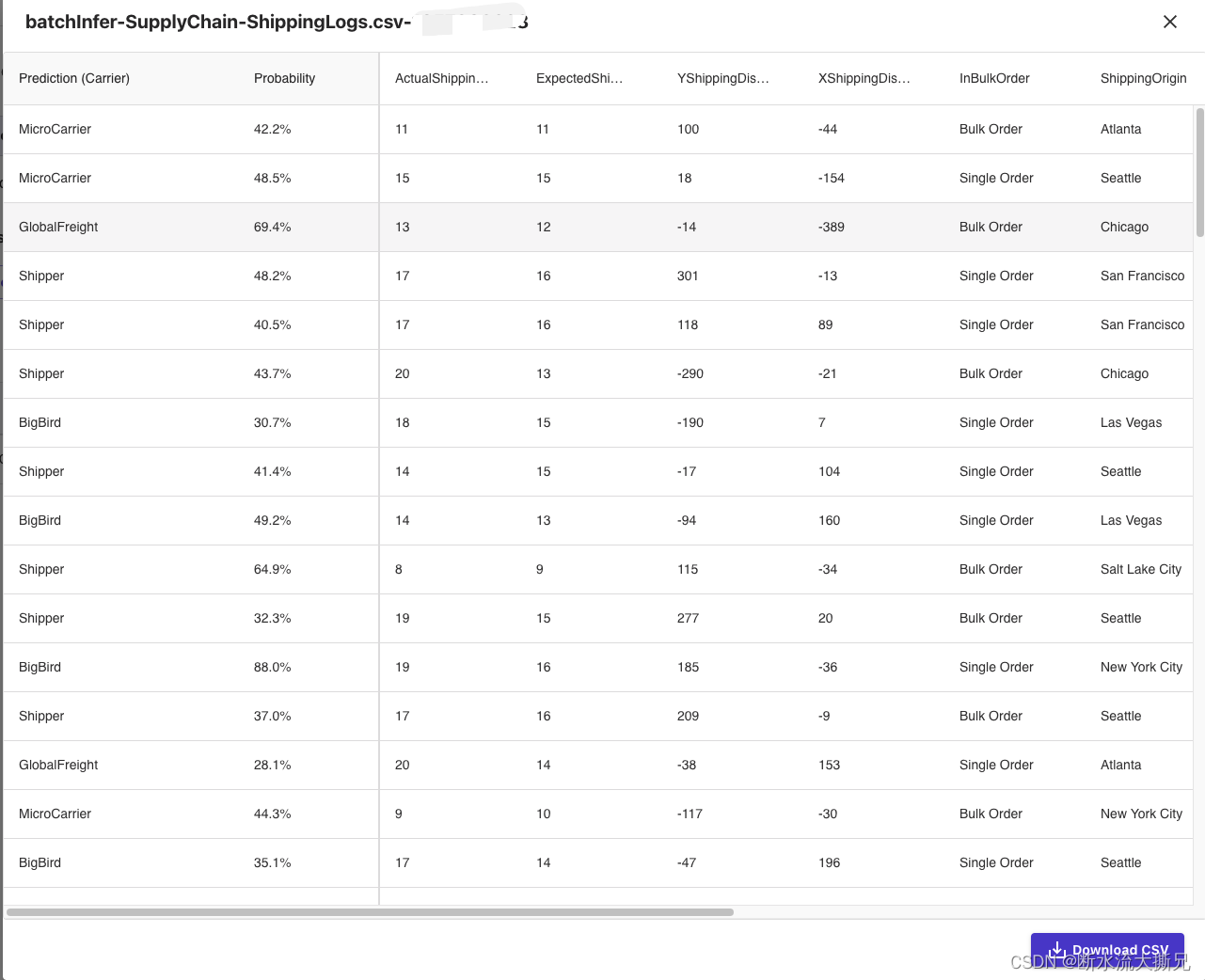
点击Batch prediction(批量预测)。现在,请选择Select dataset(选择数据集),并选择日志那个数据集。Canvas将使用该数据集来生成预测结果。一般而言,虽然不建议使用相同的数据集进行训练和测试,但为了简单起见,我们使用的是同一个数据集。如果您愿意的话,您也可以在选择视图中导入另一个数据集。几秒后,预测完成,您可以点击眼睛图标,查看预测结果预览,或者点击下载按钮,下载包含完整输出的CSV文件。
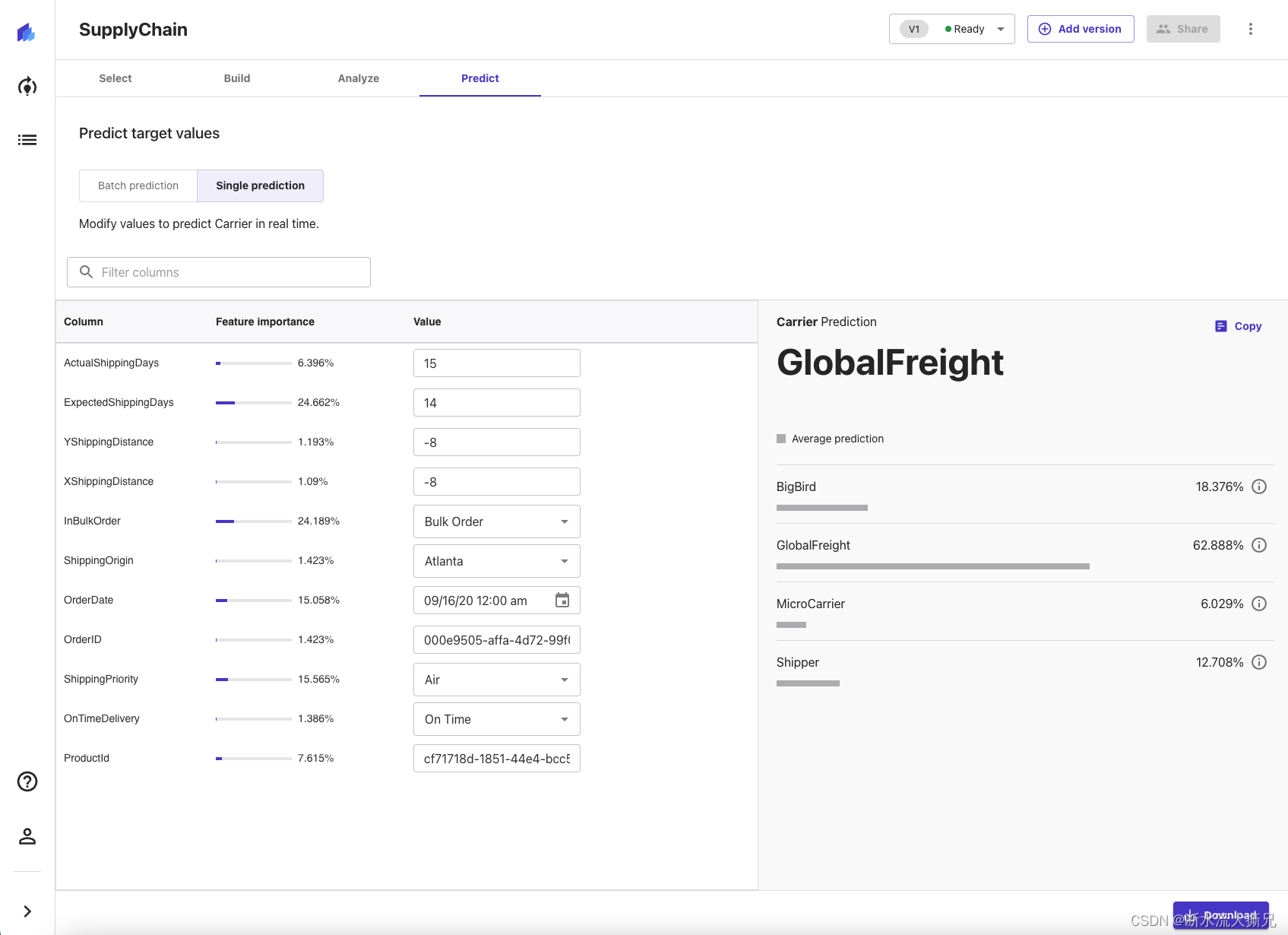
您也可以选择Single prediction(单次预测)而非批量预测,逐一预测数值。Canvas会显示一个供您为各特性手动输入数值的视图,并生成预测。
到此,恭喜你,完成了该实验。接下来你可以针对其他数据集完成其他的模型训练。
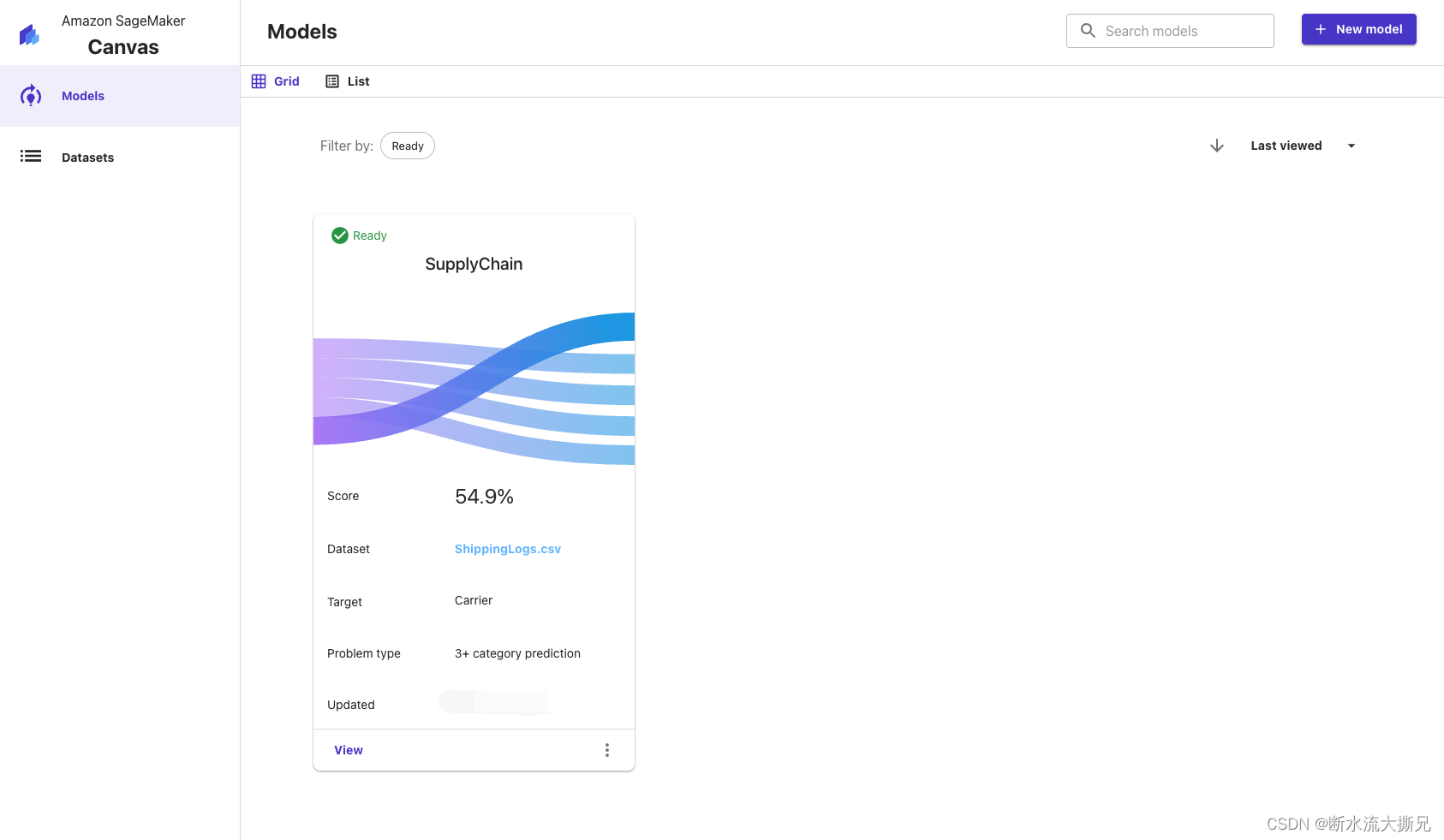
回到模型首页,我们可以看到已经完成的模型。
官方手册链接地址:
https://aws.amazon.com/cn/getting-started/hands-on/sagemaker-canvas/supply-chain-delivery-on-time/
里面包含了7种推荐场景的动手实验。
如需转载,请注明来处。


