
- 1mysql如何获取慢SQL,以及慢查询的解决方式_mysql捕捉慢sql
- 2Docker安装教程
- 3【漏洞通知】JeecgBoot 修复 Freemarker 模板注入漏洞, 漏洞危害等级:高危_jeecg freemarker
- 4Oracle获取当前毫秒级时间_oracle获取当前时间毫秒
- 5企业数据挖掘利器:企业工商相关信息API接口集合_工商信息接口
- 6LCD彩屏显示方案选型攻略:从接口到GUI开发工具的全面评估
- 7Android基于opencv4.6.0实现人脸识别功能_android opencv 人脸对比 github
- 8C#.net6.0医院手术麻醉系统源码,使用前后端分离技术架构 实现患者数据的自动采集和医疗文书自动生成
- 9S3C2440 蜂鸣器 汇编语言,S3C2440的基础功能模块实现过程
- 10标准的弯腿90度图片_机械图纸·每日一符:垂直度
十二、Transformer
赞
踩
参考Transformer详解 和 Transforner模型详解
1 Transformer 整体结构
Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。

2 Transformer 局部结构
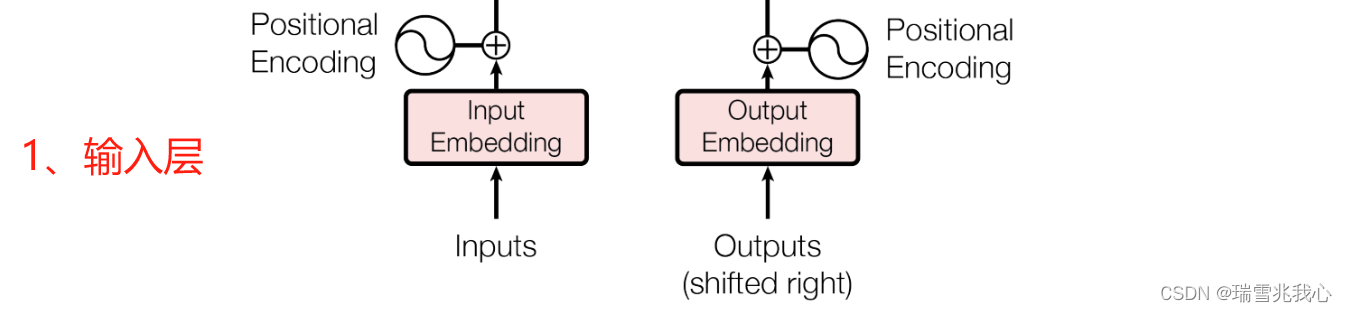
2.1 输入层
Transformer 中的输入层是由单词的 Word Embedding 和 Positional Embedding 相加得到。
以"I Really Love You" 翻译成中文 "我真地爱你" 为例:参考Transformer代码讲解

- Word Embedding 表示将输入的单词 "I", "Really", "Love", "You" ,每一个都用 One-Hot 独热编码、Word2Vec 或 GloVe 等形式的词向量表示,一个句子就可以用一个矩阵来表示。
- Positional Embedding 表示保存输入的单词"I", "Really", "Love", "You" 出现在序列中的相对或绝对位置(一句话中词语出现位置不同,意思可能发生翻天覆地的变化)。
- 编码层 Encoder 的输入则需要将每个单词的 Word Embedding 与位置编码 Positional Encoding 相加得到
- Output Embedding 与输入 Input Embedding 的处理方法步骤一样,输入 Input Embedding 接收的是 source 数据,输出 Output Embedding 接收的是 target 数据(例如:输入 Input Embedding 接收 "I Love You" 分词后的词向量 Word Embedding;输出 Output Embedding 接收 “我爱你” 分词后的词向量 Word Embedding)
- 注意:只是在有 target 数据时也就是在进行有监督训练时才会接收 Outputs Embedding,进行预测时则不会接收。
Q1:Positional Encoding 如何获取?
通过数据训练学习得到 Positional Encoding ,类似于训练学习词向量。
Q2:有监督训练和无监督训练是什么,二者有什么区别?参考有监督学习与无监督学习的区别
- 有监督学习 Supervised Learning 方法必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。(即通过已有的训练样本(即已知数据及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优表示某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据分类的能力。)而非监督学习 Unsupervised Learning 没有训练集,只有一组数据,在该组数据集内寻找规律。(即由输入数据(由输入的特征值组成,没有被标记,也没有确定的结果)学到或建立一个模型,并依此模式推测新的结果)。
- 有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而非监督学习方法在寻找数据集中的规律性,只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
2.2 编码层
输入层最终得到的字向量 a(i) 作为多头自注意力机制(Self Attention Mechanism)的输入。
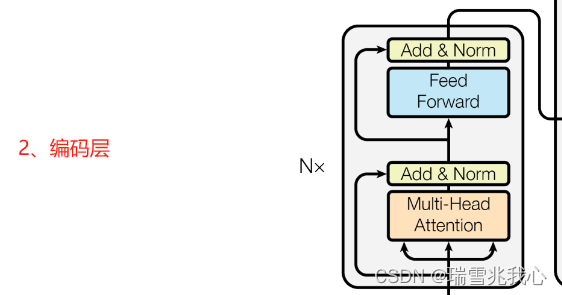
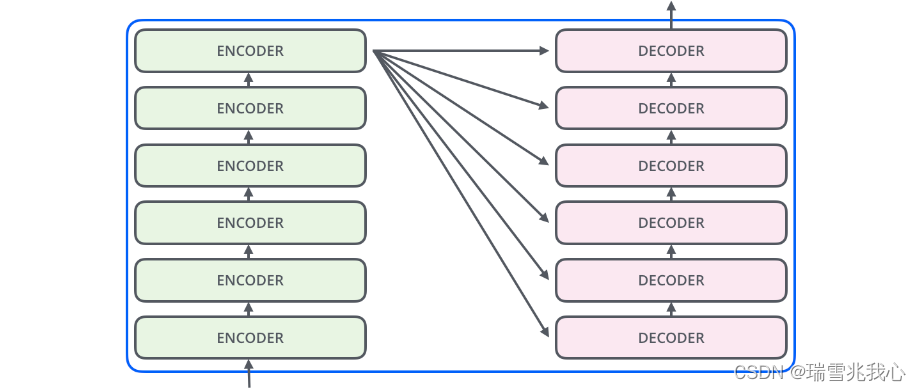
编码层由 6 层编码器首位相连堆叠而成,解码器也是六层解码器堆成的(每层的编码器和解码器自身结构是完全相同的,但是并不共享参数)。第一层编码器的输入为句子单词的表示向量矩阵,后续编码器的输入是前一个编码层的输出,最后一个编码器输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到解码层中。
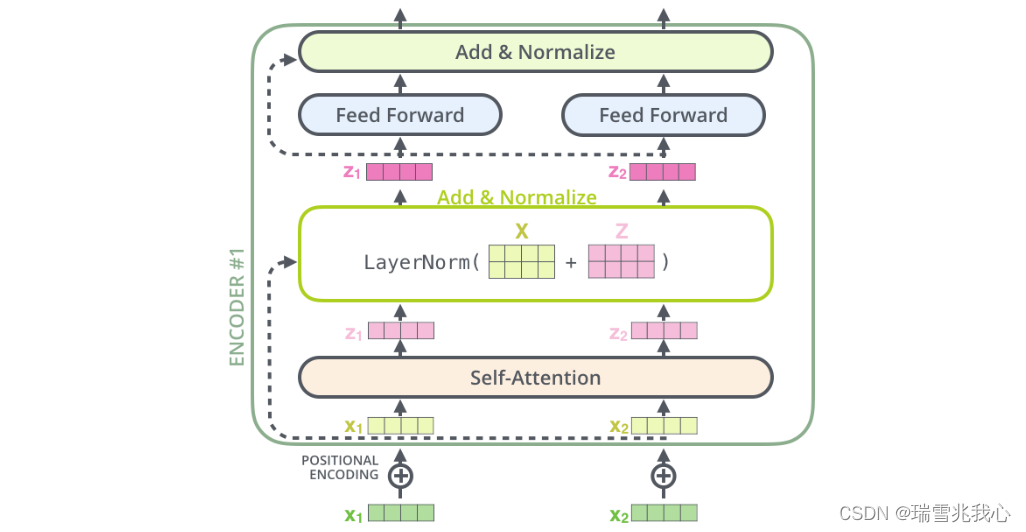
一个编码器和解码器的内部结构由 Multi-Head Attention、Add & Norm 和全连接神经网络 Feed Forward Network 构成。
2.2.1 多头自注意力(Multi-head Self-Attention)
多头自注意力理论过程:参考注意力机制
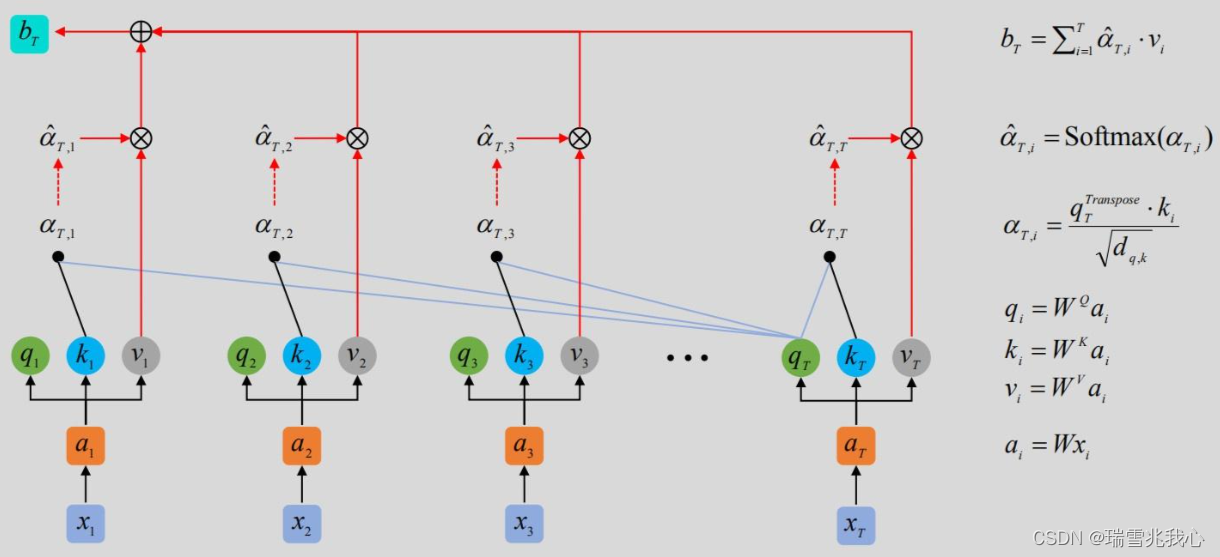
多头注意力计算过程:
参考Transformer模型详解 3.2 Q, K, V的计算和 3.3 Self-Attention输出和 3.4 Multi-Head Attention
2.2.2 残差连接和层归一化函数(Add & Norm)
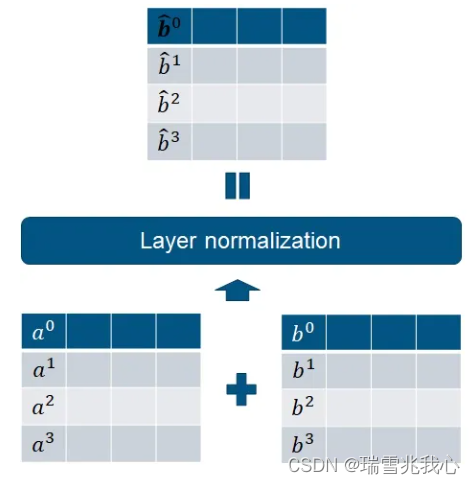
Q1:Add 是什么?
Add 指的是将不同层的输出相加(残差连接(Residual Connection)),指的是在 Z 的基础上加了一个残差块 X,加入残差块 X 的目的是为了防止在深度神经网络训练中发生退化问题(退化:深度神经网络通过增加网络的层数,Loss 逐渐减小,然后趋于稳定达到饱和,接着再继续增加网络层数,Loss 反而增大)。
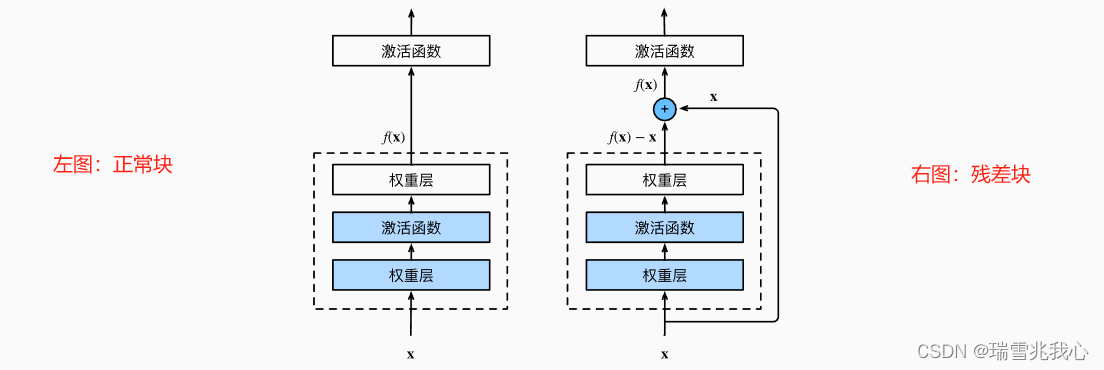
Q2:残差块 X 是什么,又是如何解决退化问题的?参考残差神经网络的介绍
为了解决深层网络中的退化问题(随着网络层数的增加,在训练集上的准确率趋于饱和甚至下降了。这个不能解释为 overfitting(过拟合)问题,因为 overfitting 应该表现为在训练集上表现更好才对),可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为残差网络(ResNet)。
“残差块”(residual block)是残差网络的的核心思想,发现了“退化(Degradation)现象”,并针对退化现象发明了 “快捷连接(Shortcut Connection)”,使网络能够保证训练出来的参数能够很精确的完成 f(x) = x 恒等映射(identity mapping),极大的消除了深度过大的神经网络训练困难问题。
Q3:Norm 是什么?
Norm 主要有 BatchNorm(BN) 和 LayerNorm (LN) 两种归一化函数:参考层归一化
- BatchNorm 是对一个 batch 下的不同样本之间的同一位置的特征(神经元)之间看成一组进行归一化),对小 batchsize 效果不好。
- LayerNorm 是对一个 batch 下的同一个样本的不同特征(不同神经元)之间进行归一化(针对所有样本)。
在 Transfomer 架构中,Norm 指的是层归一化(Layer Normalization, LN),通过对层的激活值的归一化,可以加速模型的训练过程,使其更快的收敛,提高训练的稳定性。
Q4:Norm 为什么用 LayerNorm (LN) 不用 BatchNorm(BN) ?
针对 BatchNorm(BN) 和 LayerNorm (LN) 两种归一化函数,这里的三个维度表示的信息不同:
| BatchNorm(BN) | LayerNorm (LN) | |
| N | batch_size | batch_size |
| C | channel | seq_length |
| H, W | feature map | dim |
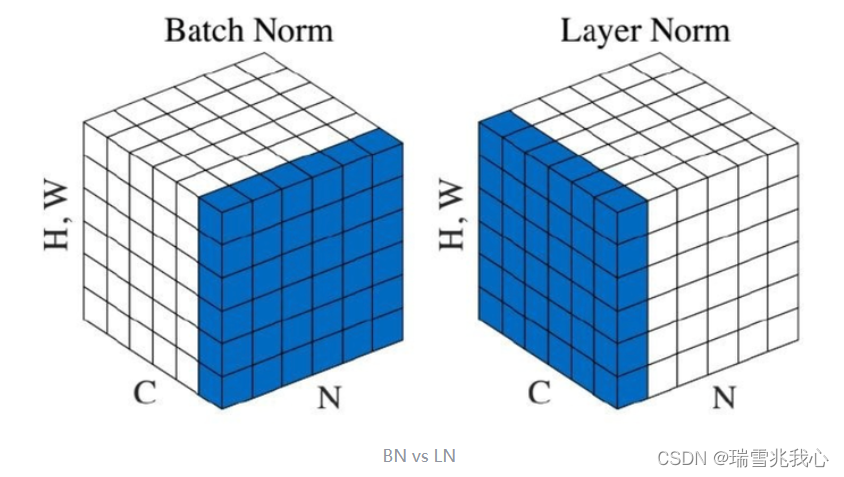
- 一般来说,如果你的特征依赖于不同样本间的统计参数,那 BN 更有效。因为它抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系。
- LN 适合抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系。(对于NLP或者序列任务来说,一条样本的不同特征,其实就是时序上的变化,这正是需要学习的东西自然不能做归一化抹杀。)参考Transformer为什么要用LayerNorm
- BN 是对于相同的维度进行归一化,但是 NLP 领域中输入的都是词向量,单独去分析它的每一维是没有意义的,在每一维上进行归一化更加适合,因此这里选用的是LN。
2.2.3 全连接前馈神经网络(Feed Forward Network)
Feed Forward Network 是将每一个神经元都与其他神经元相连接(每两个神经元之间的连接都有不同的连接权重值(connection strength),并且它们在训练过程中都是自动学习调整自身的参数(learned parameters)),每个神经元都掌握着 input 信息(补充一些对 input 有用的东西),并进行处理后将其传递下去。参考轻松理解 Transformers
全连接前馈神经网络由两个线性层(linear layers)和一个激活函数(Activation Function)组成。
激活函数(Activation Function)能够帮助我们进行非线性变换(non-linear transformation),处理非线性关系(nonlinear relationship)。(例如常见的 Softmax 激活函数可以将整数转换为0到1之间的浮点数,转换后的浮点数仍然保持了原始整数之间的相对大小关系;Tanh(双曲正切)激活函数可以将元素调整到区间(-1, 1)内;ReLU(修正线性单元)能够将任何负数转化为0,而非负数保持不变)
正则化(Regularization)是让算法仅学习不记忆的一系列技术的总称。在正则化技术中最常用的技术就是 dropout。
Dropout 是将“连接权重(connection strength)”设置为0,这意味着该连接不会产生任何影响(在每一层中使用 dropout 技术时,会随机选择一定数量的神经元(由开发者配置),并将它们与其他神经元的连接权重设为0)
在 Transformer 的架构图中,全连接前馈神经网络工作过程:
- 对输入序列的每个位置的特征向量进行逐位置的线性计算,将其映射到一个更高维的空间;
- 对线性运算的输出应用 ReLU 函数;
- 对上一步骤 ReLU 运算的输出进行再一次线性运算,将其映射回原始的特征维度。
2.3 解码层
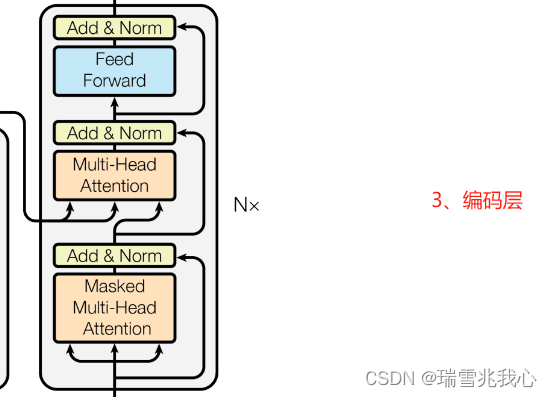
2.3.1 第一个多头自注意力
第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
Decoder 可以在训练的过程中使用 Teacher Forcing 训练,加快模型训练时间。
Teacher Forcing:是指在训练过程中每次不使用上一个 state 的输出 h(t) 作为当前 state 的输入,而是直接使用训练数据上一个标准答案 ground truth 的输出 y(t) 作为当前 state 的输入。Teacher Forcing训练机制及其缺点和解决方法
2.3.2 第二个多头注意力
第二个 Multi-Head Attention 与第一个 Multi-Head Attention 主要的区别在于其中没有采用掩码 Masked 操作而且Self-Attention 的 K, V 矩阵不是使用上一个解码层的输出计算的,而是使用编码层的编码信息矩阵 C 计算的,Q 使用上一层解码器的输出计算。
2.4 输出层
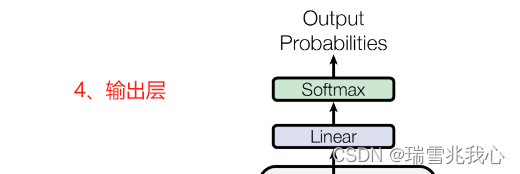
输出层首先经过一次线性变换(它可以把解码器产生的向量投射到一个比它大得多的向量里),然后利用 Softmax 得到输出的概率分布(Softmax 层会把向量变成概率),接着通过词典,输出概率最大的对应的单词作为我们的预测下一个单词的输出。

