
- 1当世界加速离你而去
- 2【Mac】【Git】 全局配置 忽略 .DS_Store_mac git dostore
- 3苹果PDF压缩工具:PDF Squeezer_pdf squeezer ipad
- 4clang frontEnd插件 常见Traverse函数、Visit函数 例子
- 5pyspark连接MySQL出错 java.sql.SQLException: No suitable driver_pyspark : java.sql.sqlexception: no suitable drive
- 6数据结构笔记1 线性表-顺序表示_!l.elem什么意思
- 7web对象page、request、session、application的生命周期_request,session,cookie,application生命周期区别
- 8文心一言 VS 讯飞星火 VS chatgpt (71)-- 算法导论7.1 1题
- 9SpringCloud--LoadBalancer负载均衡服务调用
- 10minio最新版本(2022.10.31)简易集群搭建(详细到爆)
Transformer详解+Transformer李沫视频笔记_为什么transformer除以根号dk
赞
踩
李沫视频学习笔记

Transformer是继mlp、cnn、rnn后的第四大模型
在主流的序列转录模型(给一个序列,生成另一个序列)中,依赖于比较复杂的循环或者卷积神经网络,用encoder-decoder架构
模型取名字,如果是熟知的单词比如transformer,如果文章没火那么很难搜索到这个文章,可能搜到的是变形金刚
transformer仅仅依赖注意力机制,并行度更高,使用更少时间训练。做了两个实验,在英语-德语上到28BLUE SCORE,在英语-法语上达到41.8BLUE SCORE(8个GPU训练3.5天)
代码放在t https://github.com/ tensorflow/tensor2tensor.
第t个词由前面学到的的隐藏状态ht-1和第t个输入决定
缺点:
1.无法并行,算第t个词时候必须保证前t-1个词输入完了,主流的GPU、TPU都是成千上万进程,无法并行的话计算性能差
2.历史信息一步一步往后传,如果序列比较长,早期的信息到后面可能会丢掉,如果不想丢掉,ht要比较大,在每个时间步都得存ht,导致内存开销大
卷积缺点对长的序列难以建模,离得远的像素需要经过很多层才能融合起来,而transformer一次就可以看到整个序列。卷积优点有多个输出通道,去识别不同的模式,transformer多头注意力来实现这一点。
相关工作部分应该讲清楚和你的论文相关的是谁,联系是什么,区别是什么
编码器encoder将输入x=(x1,x2...xn)(词)映射到序列z=(z1,z2...zn)(向量),然后解码器产生输出序列(y1,y2...ym)(目标词)
自回归:在过去时刻的输出作为当前时刻的输入。
前馈神经网络类似于mlp
LayerNorm(x+dropout(Sublayer(x)))
d_model=512 n=6
LayerNorm在每个样本内归一化(黄色) VS batchnorm在不同样本间归一化(蓝色)
二维:
三维: 求均值的切面:
求均值的切面:
batchnorm当样本长度变化大的时候,且小批量batch时候,每个batch均值方差抖动比较大。预测时候需要利用训练时候batch的均值和方差来计算预测时候的均值和方差,假如碰到特别长的样本,那么之前算的均值和方差就不好用了,所以在变长的应用中不使用batchnorm
而layernorm假如碰到特别长的样本,他通过预测的样本本身就能计算均值和方差,与之前训练batch无关,稳定一些


query*key->weight weight*value->output
相似度:query key做内积,内积值越大表示这两个向量相似度越高,越小表示相似度越低(类似于余弦相似度,比如说内极为0 就是两个向量正交)其实就是算各个向量间的相似度
加性注意力机制,处理query和key不等长的情况
点积注意力机制与transformer中除了除以根号dk其他相同
为什么除以根号dk:dk小的时候除不除都无所谓,大的时候会导致点积后矩阵中的值差距比较大,然后通过softmax函数,接近一的值就会更加接近1,其余会更加接近0,值向两端靠拢,梯度变小,跑不动(softmax函数会使大的更大小的更小,如果值向两端靠拢非常接近0和1了,那么相当于网络收敛了,梯度就变小了)

Q K V先通过三个线性层投影到低的维度,最初是d_model=512维,投影到64维,最后拼接8个64维。8个注意力头匹配不同的模式,W可学习

在此文中query=key=value
解码器中第二个子层的key和value来自于编码器,query来自于第一个子层
解码器query: 编码器key和value:
编码器key和value:
解码器会根据query从编码器中去挑自己感兴趣的向量,比如说你好都给hello一个比较大的权重,世给world一个比较大的权重
position-wise:每个词是一个position,把mlp对每个词单独作用,即作用在最后一个维度

用w1投影到2048维,再用w2投影回512维
attention就是抓取序列中的重要信息然后汇聚,然后通过mlp映射到想要的语意空间

关注点都是在于如何有效的去利用你的序列信息
在两个embedding层和softmax前的线性层中共享权重矩阵,这样训练起来会简单点。把权重乘根号d_model,因为学习embedding时候可能把每个向量的l2norm学的相对比较小,如果维度比较大,学到的权重值就会比较小,乘根号d_model放大后与position embedding相加时 二者在scale上差不多
attention没时序信息,权重weight是query和key之间的距离(相似度),与key value在序列中的位置无关。假如给出一句话,任意打乱位置,最后抓取出的东西都是一样的。所以要用position embedding


sequential operations:下一步的计算必须要等前面多少步计算完成
maximum path length:信息从一个数据点走到另一个数据点要走多远(得到两个位置间关系需要的计算量)
self-attention每层复杂度:n*n*d 即矩阵(n*d)*(d*n)
recurrent每层复杂度:n*d*d (n个token,每个长度d,在每个时间步token(维度d)*矩阵(维度d*d)=d*d)
convolutional每层复杂度:k*n*d*d 一维卷积 k:卷积核大小 n:长度 d:输入输出通道数(不太懂)
self-attention(restricted)每层复杂度r*n*d 每个query只和最近的r个key做运算
RNN不能处理长期依赖也不能并行,GRU、LSTM能处理长期依赖不能并行,transformer既能处理长期依赖也能并行
使用标准的2014年WMT英语-德语数据集进行训练,该数据集包含约450万句对。句子使用字节对编码进行编码,该编码具有约37000个token的共享源目标词汇。对于英语-法语,我们使用了更大的2014年WMT英语-法语数据集,该数据集包含3600万句子,并将token拆分为32000个词块词汇。
将句子对按照大致的序列长度一起进行批处理。每个训练批次包含一组句子对,包含约25000个源token和25000个目标token。
我们在一台配备8个NVIDIA P100 GPU的机器上训练了我们的模型。对于我们使用本文中描述的超参数的基本模型,每个训练步骤大约需要0.4秒。我们总共训练了10万步或12小时的基本模型。对于我们的大型模型,步长时间为1.0秒。大型模型训练了30万步(3.5天)。
我们使用了Adam优化器,其中:α=0.9、β1=0.9、β2=0.98、ϵ=10−9。在训练过程中,我们根据以下公式调整学习率:
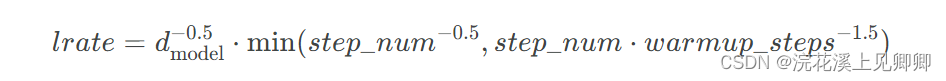
这与在第一个 warmup_steps(预热步数)训练步骤中学习率将线性增加,此后按步骤数的倒数的平方根成比例降低。我们使用 warmup_steps=4000。
每个子层在进入残差连接和layernorm之前,使用dropout=0.1 ,即10%元素置为0,90%元素*(1+dropout),在embedding+positional encoding后也使用dropout
label smoothing 让真实标签表示为0.1就行了不表示成1 不太懂
个人记录笔记
1.简介
总体结构:

编码器encoder:

解码器decoder结构:

将 Encoder输出的编码信息矩阵C传递到Decoder中,Decoder依次会根据当前翻译过的单词1~ i 翻译下一个单词 i+1。在使用的过程中,翻译到单词 i+1 的时候需要Mask遮盖住i+1之后的单词。上图Decoder接收了Encoder的编码矩阵C,然后首先输入一个翻译开始符<Begin>,预测第一个单词 “I”;然后输入翻译开始符<Begin>和单词 “I”,预测单词 “have”,以此类推。
编码器的自注意力层及前馈层均有残差连接以及正则化层:

2.编码器encoder
输入:[批处理大小,最大输入句子长度] -——>输出:[批处理大小,最大输入句子长度,512]
细节:(先忽略batch)
2.1词嵌入input embedding
单词+embedding算法->input embedding [句子长度,512]
imput embedding可以采用 Word2Vec、Glove 等算法预训练得到
2.2位置嵌入positional embedding

位置编码positional embedding:ransformer缺少了单词输入的顺序信息,所以需要位置编码来标记各个字之间的时序关系或者位置关系。pos为位置,i为第i位。
注:如果不加位置编码,打乱一句话中词语的位置,句意改变了,但是每个词还是能与其他词之间计算attention值,计算出的attention值却不变。
举例:我是中国人
我 [sin1a cos1a sin2a cos2a ,…,cosna]
是[sin1b cos1b sin2b cos2b,…,cosna]
中[sin1c cos1c sin2c cos2c,…,cosnb]
国 [sin1d cos1d sin2d cos2d,…,cosnd]
人[sin1e cod1e sin2e cos2e,…,cosne]
input embedding+positional embedding->input [句子长度,512]

2.3多头注意力机制
对同一句子中每个单词与其他单词之间的关系进行打分
例如,ball 与 blue 、 hold 密切相关。另一方面,boy 与 blue 没有关系。

input复制三份->Q、K、V [句子长度,512]
拆分成八个头后,Q、K、V [句子长度,64]
Wq,Wk,Wv [64,64] (h=8分成8组,共24个权重矩阵,参数可训练,提高模型的拟合能力)
QWq、KWk、VWv [句子长度,64]
head1、head2...head8:[句子长度,64]

concat( head1、head2...head8):[句子长度,512]
Wo [512,512]
多头注意力机制完整示意图:

除以根号dk原因:Q*K得到的值可能会很大,softmax在x较大处的梯度很小,如下图所示。如果网络层次较深的话,在反向传播时容易造成梯度消失,除以根号dk让值变小。

2.4残差连接层归一化:

其中 X表示 Multi-Head Attention 或者 Feed Forward 的输入
X [句子长度,512]
MultiHeadAttention(X) [句子长度,512]
X=LayerNorm(X+MultiHeadAttention(X))[句子长度,512]
FeedForward(X)=Linear(ReLU(Linear(X) [句子长度,512] 前馈神经网络
Z1=LayerNorm(X+FeedForward(X))[句子长度,512]
编码器第一层输出Z1(即第二层的输入input) 最后一层输出Zn
最后一层输出的Zn,初始化一个新的Wk和Wv,ZnWk、ZnWv即为解码器的输入K、V
总结一下,假如该transformer的编码部分有6层encoder,每层encoder有8个“头”,那么编码部分一共初始化了多少个Wq、Wk、Wv权重矩阵?
答:Wk、Wv都是6×8+1个,Wq有6×8个
2.5为什么残差连接
随着网络层数的增加,梯度在反向传播过程中会逐渐减小,从而导致模型训练困难。残差连接使梯度更容易传递给前一层,减小了梯度消失的影响。加入残差连接,就能保证层次很深的模型不会出现梯度消失的现象。
例如:


假如不添加残差结构,3个偏导数的乘积随着网络层次的加深会非常小:

假如添加残差结构,+1使梯度值大大增加:

2.6为什么层归一化
Normalization的目的Normalization的目的:
在深层网络中,输入数据的特征分布会随着网络深度的增加而发生变化。为了维持数据特征分布的稳定性,通常会引入Normalization。简而言之,Normalization的主要作用是在特征输入激活函数之前进行标准化处理,将数据转换为均值为0、方差为1的分布。这一处理避免了数据落入激活函数的饱和区,从而降低了梯度消失问题的风险。
BatchNorm:

LayerNorm:


为什么BN训练和测试时有区别,而LN没区别?
BatchNorm的统计量(均值方差)是一个batch算出来的,测试时只有一个样本,无法计算。所以在训练的时候要记录统计量running mean和running var,作为预测时的均值和方差。
而LayerNorm训练和测试的时候不需要model.train()和model.eval(),是因为它只针对一个样本(即一个单词),不是针对一个batch,所以LayerNorm只有参数gamma和beta,没有统计量,因此LN训练和预测没有区别。
3.解码器decoder
训练期间
输入:
1、目标句子向右移动一个时间步长(即在序列的开头插入一个序列开始令牌)。
[批处理大小,1+最大输出句子长度,512]
2、编码器的输出
输出:每个时间步长输出每个可能的下一个单词的概率
[批处理大小,最大输出句子长度,词汇表长度]
推理期间
输入:
因无法向解码器提供目标值,因此改为提供先前输出的单词(从序列开始令牌开始)。
[批处理大小,当前时间步,512]
输出:
每个时间步长输出每个可能的下一个单词的概率(在下一 回合中将其馈送到解码器,直到输出序列结束令牌)。
[批处理大小,当前时间步,词汇表长度]


3.1第一层,带masked的多头注意力
在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。

Mask QK^T之后在 Mask QK^T上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。

使用 Mask QK^T与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 [公式] 是只包含单词 1 信息的

3.2第二层,decoder里的多头注意力机制
区别主要在于其中 Self-Attention 的 K, V矩阵是Encoder输出的编码信息矩阵C
这样做好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息
3.3第三层,前馈神经网络 Feed Forward
3.4最后的线性层和softmax
线性层将解码器产生的向量投影到一个更高维度的向量(logits)上
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下:


参考:transformer通俗理解_transformer介绍-CSDN博客
机器学习实战(第二版)读书笔记(5)——通俗易懂Transformer_爱晒太阳的胖子的博客-CSDN博客
transformer的简要解读(应该都能看懂)_transformer详解-CSDN博客
Transformer模型详解(图解最完整版)_transformer模型结构层visual.conv1.out_channels_初识-CV的博客-CSDN博客https://blog.csdn.net/dongjinkun/article/details/124146439?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170161071516800211527554%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=170161071516800211527554&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-124146439-null-null.142^v96^pc_search_result_base9&utm_term=%E6%AE%8B%E5%B7%AE%E8%BF%9E%E6%8E%A5%E7%9A%84%E5%A5%BD%E5%A4%84&spm=1018.2226.3001.4187 深入理解NLP中LayerNorm的原理以及LN的代码详解_捡起一束光的博客-CSDN博客

